Ch3 p.91에서 교차 검증을 하는 방법으로 (StratifiedKFold+추가 코드)와 cross_val_score, cross_val_predict에 대해 언급했는데, 각각의 기능과 차이에 대해 정리하고 싶었음
scikit-learn의 cross validation을 위한 클래스들
- KFold
- StratifiedKFold
- cross_val_score
- cross_validate
- cross_predict
- GroupKFold
- TimeSeriesSplit
(위 5개만 다룰 거지만 다른 클래스도 있다는 점 알아두기)
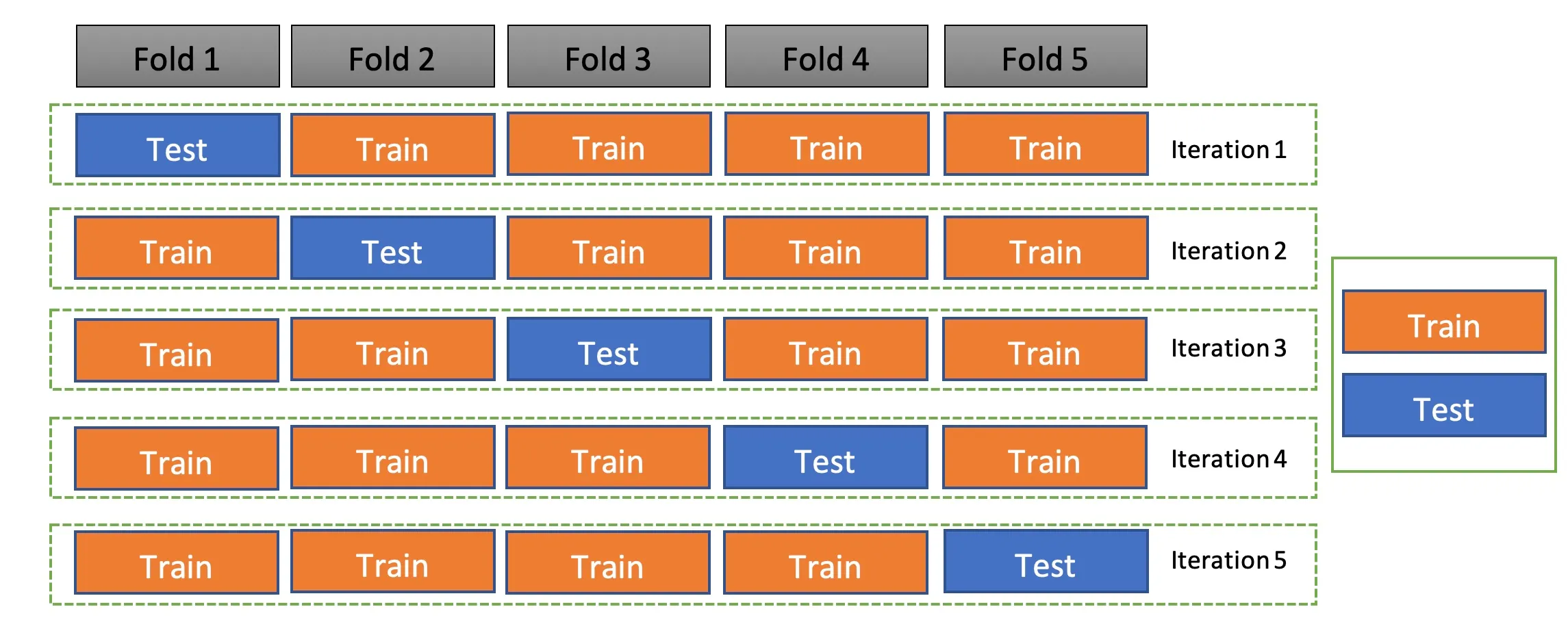
KFold와 StratifiedKFold는 데이터 분할 방식을 정의하고, cross_val_score는 데이터 분할 방식을 사용하여 모델의 성능을 평가한다.
1) KFold
데이터를 k개의 fold로 나누어 교차 검증을 수행하기 위한 클래스. split 메서드를 사용하여 각 fold를 생성할 수 있다.
from sklearn.model_selection import KFold
# KFold 객체를 생성한다. n_splits로 fold의 수를 지정한다.
kf = KFold(n_splits=5)
# kf.split(X)는 데이터셋 X에 대하여 각 fold의 훈련 인덱스와 검증 인덱스를 생성한다.
# kf.split(X)는 fold의 수만큼 반복되며 각 반복에서 훈련 인덱스와 검증 인덱스를 반환한다.
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 만약 cross_val_score와 같은 기능을 하고 싶다면
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
n_correct = sum(y_pred == y_test)
print(n_correct / len(y_pred))2) StratifiedKFold
KFold와 유사하지만, 각 fold가 원본 데이터의 클래스 분포를 유지하도록 하기 때문에 classification 문제에서 유용하다.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5)KFold와 StratifiedKFold는 데이터 분할 방식을 정의하고, cross_val_score는 데이터 분할 방식을 사용하여 모델의 성능을 평가한다.
3) cross_val_score
주어진 데이터와 모델에 대해 교차 검증을 수행하고 각 fold의 점수를 반환한다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)
# cv: 교차 검증을 수행하는 방식 정의
scores = cross_val_score(model, X, y, cv=StratifiedKFold(n_splits=5))4) cross_validate
cross_val_score과 비슷하지만, 모델의 학습 시간과 평가 지표 등을 포함한 더 많은 정보를 반환한다.
from sklearn.model_selection import cross_validate
results = cross_validate(model, X, y, cv=5, return_train_score=True)5) cross_val_predict
cross_val_score과 비슷하지만, 모델의 예측 결과를 평가(-> 점수)하는 대신 실제 예측값을 반환한다.
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(model, X, y, cv=5)