

사전 정보 (about ASR)
ASR
- 기존 음성인식 : (Handcraft Feature Extractor ⇒) Acoustic Model

-
음성인식 성능을 올리기 위해 Acoustic Model + Language model
-
Acoustic model (AM)
-
ASR 모델은 bayes' theorem을 통해 두 가지 모델로 분리되어 이루어져 있습니다.
하나는 소리 모델 (acoustic model), 그리고 언어 모델 (language model).
-
: 소리 X 가 주어졌을 때, 텍스트 W는 무엇인가를 구해야한다.
-
이 때 확률이 가장 높은 텍스트 W를 고르기 위해서 아래 같은 식이 나온다.
분모에 들어가는 P(X)는 W와 상관이 없기 때문에 argmax에서는 버려져도 상관이 없으므로, 그 아래 사진처럼 식이 단순해진다.


-
: 텍스트 W가 주어졌을 때, 소리 X는 무엇인가.
⇒ 이 부분을 학습하고 수행하는 것이 ‘Acoustic Model(AM)’ 이라고 한다.
⇒ 즉, AM은 텍스트와 음성 간 관계를 밝히는 부분.
-
: 텍스트 W의 확률
⇒ 이후 나올 단어를 예측하게 모델링함으로써 특정 단어가 나올 확률을 도출할 수 있는 모델
-
-
-
-
(pre-trained feature extractor, Wav2Vec ⇒) Acoustic Model + Language Model
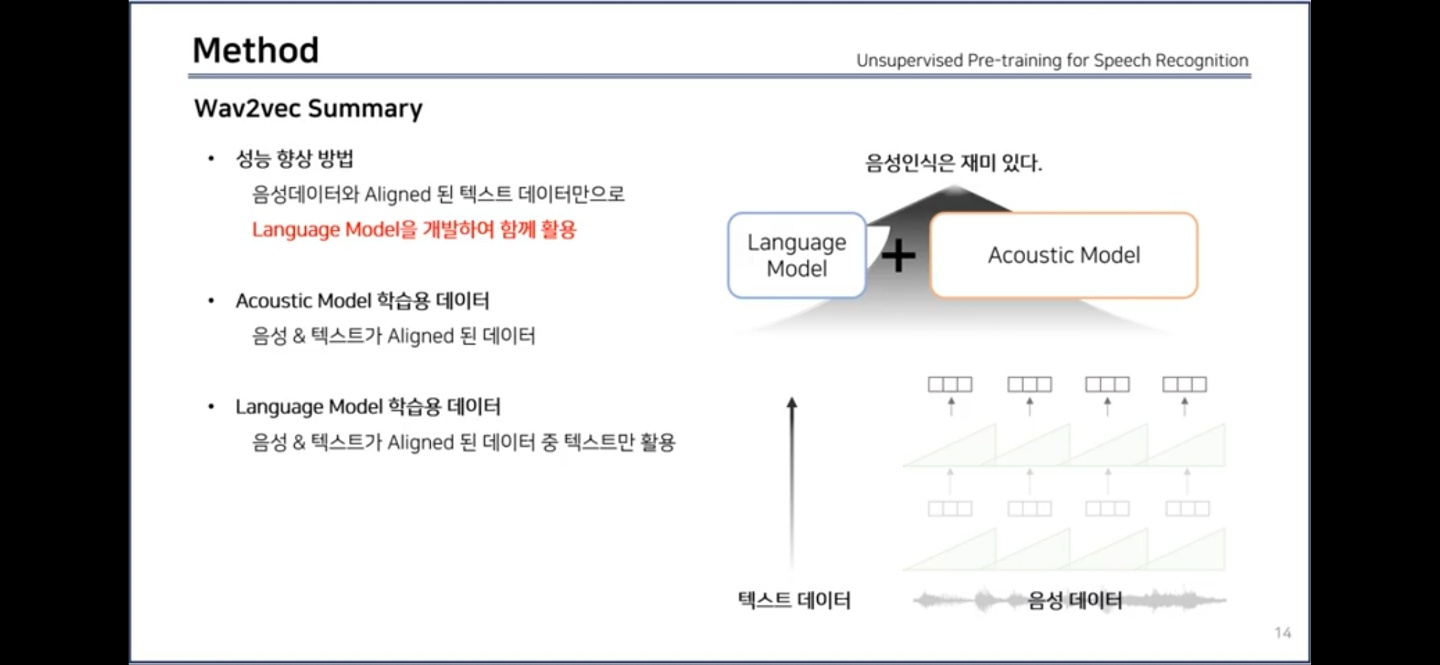
- AM training data = aligned 음성 데이터 & 전사 텍스트 데이터
- LM training data = 전사 텍스트 데이터
Wav2Vec
이전 모델
- 좋은 성능을 내기 위해서 최신 음성 인식 모델들은 너무 많은 양의 전사 오디오 데이터 (전사 텍스트(label) & 오디오 데이터)가 필요하다. (논문 발표된 19년도 기준)
- 음성 데이터 비지도 학습 연구가 있긴 했으나, 그 결과로 나온 표현 백터들을 지도 학습 음성 인식 모델을 개선하는데 사용되지 않았다.
차별점
- Wav2Vec 학습 결과로 나온 표현(벡터)들을 강력한 지도학습 ASR(Automatic Speech Recognition)을 개선하는데 사용한다.
- Wav2Vec은 fully convolutional 구조를 사용하므로, 쉽게 병렬화가 가능하기에 기존의 rnn 모델들보다 학습 시간이 적다.
- 비지도 사전 학습된 Wav2Vec을 사용해서 지도 학습 음성 인식 성능을 개선할 것.
모델 구성
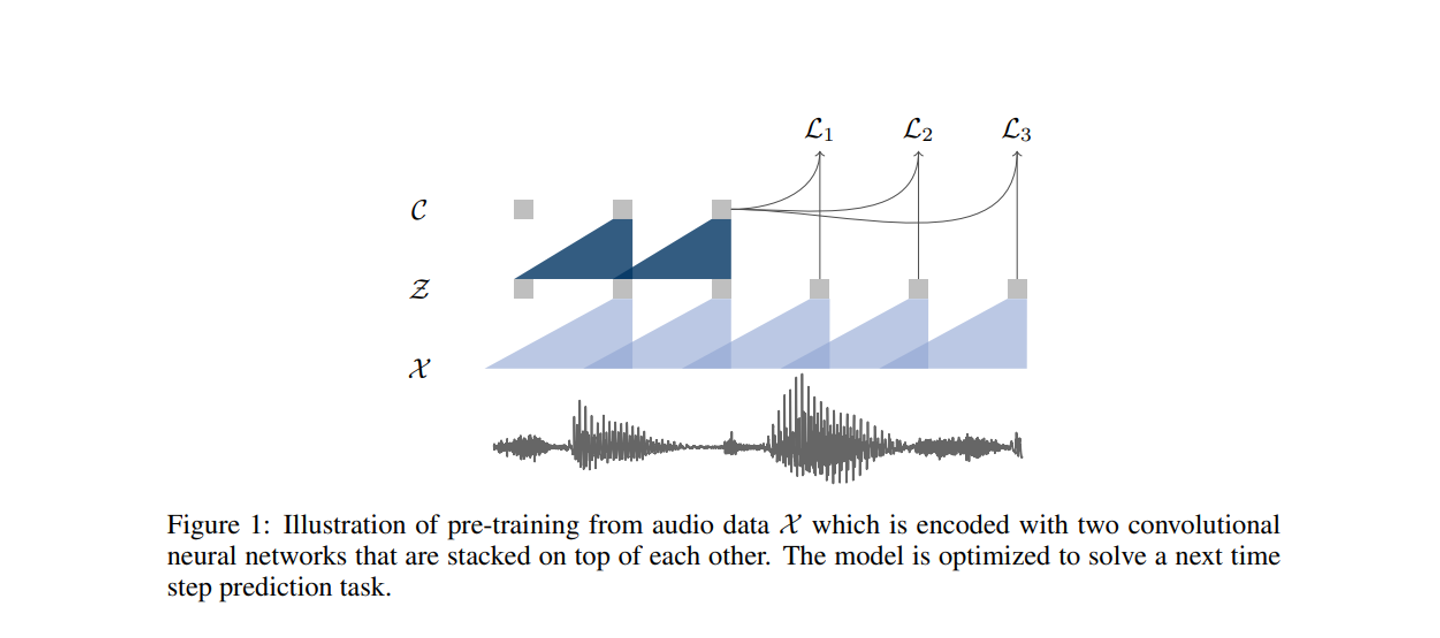
-
W2V는 원시 오디오 신호를 입력으로 받은 다음 두가지 네트워크 레이어를 가지고 있다.
-
both layers
-
The layers in both the encoder and context networks consist of a causal convolution with 512 channels, a group normalization layer and a ReLU nonlinearity.
-
causal convolution
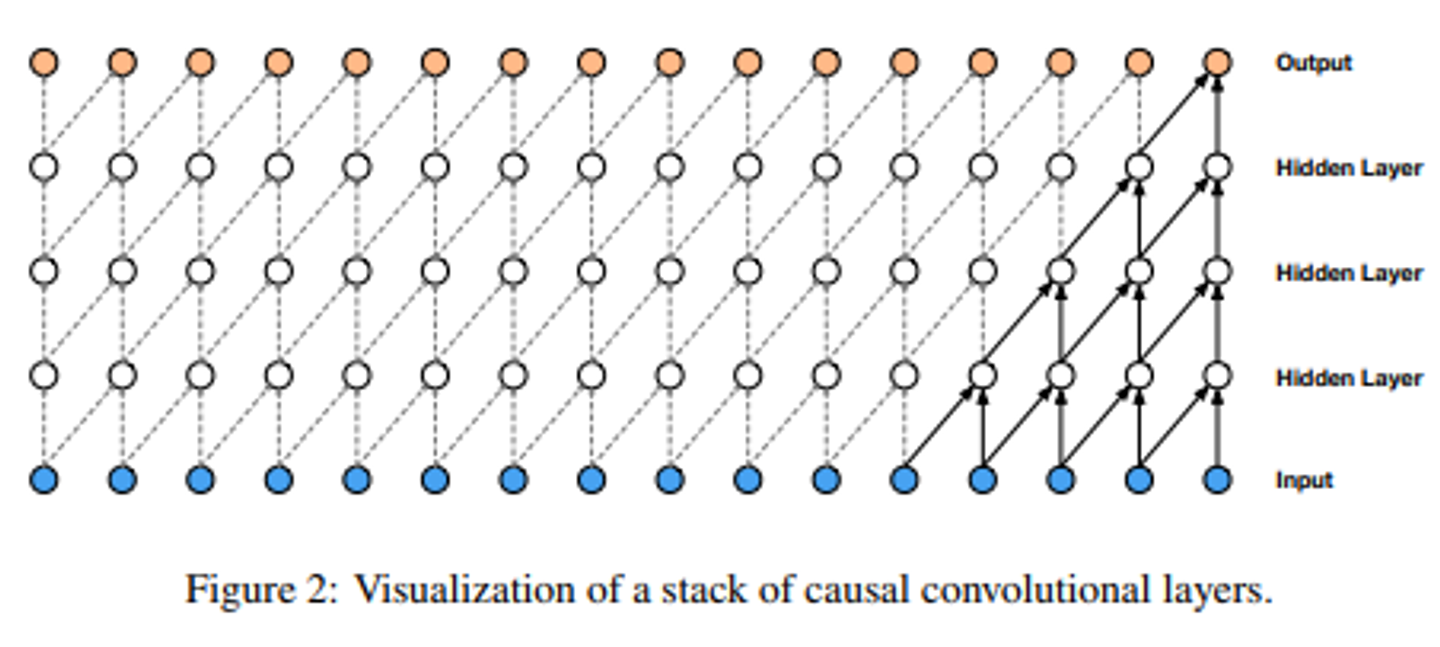
- time step t의 output을 내기 위해서 time step t까지의 input만 고려하는 방식
- 즉, convolution을 진행할 때, 매 step에서 output이 오직 현시점의 input과 과거 시점들의 데이터에만 종속되도록하는 방법.
- ex) 10번째 샘플을 생성해내기 위해 11번째 데이터를 사용하면 안된다. (10번째 데이터까지만 사용해아한다.)
- 시간, 순서를 고려할때 유용하게 사용 ⇒ 시계열 데이터인 음성 데이터
- 시간 순서 고려할 때 주로 RNN 모델 사용하지만 병렬 학습 불가로 학습 속도 늦다.
- 이를 위해서 CNN을 시계열 데이터를 다루는데 사용하게 됨.
- masked convolution에서는 필터중 일부를 0으로 masking하여 매 step에서 미래 정보를 미리 사용할 수 없게 하는데, causal convolution에서는 필터를 masking하는 대신 입력데이터에 적용하는 zero padding을 왼쪽으로만 ( filter size - 1 ) 만큼 붙여 필터가 현재와 과거의 값들에만 적용되도록 구현할 수 있다.
- time step t의 output을 내기 위해서 time step t까지의 input만 고려하는 방식
-
Group Normalization
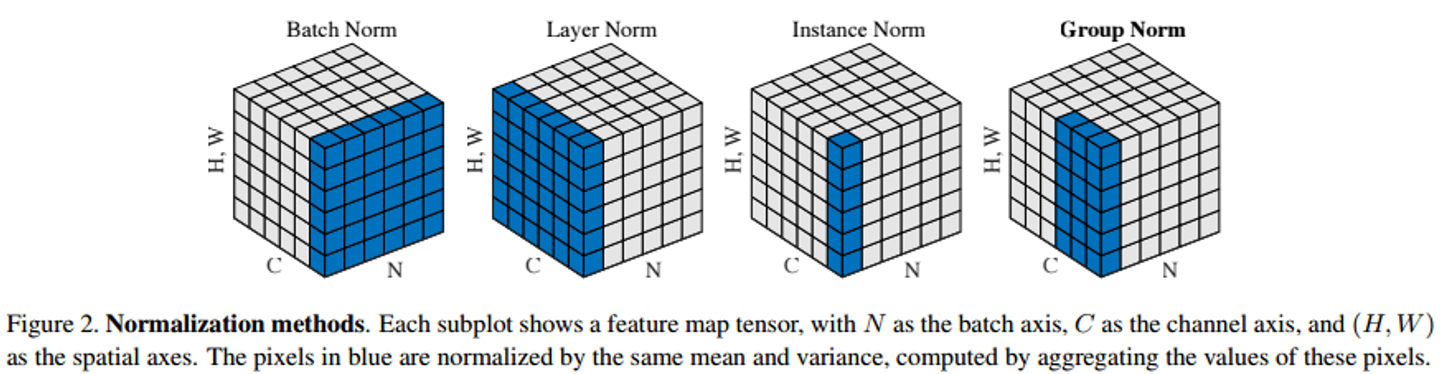
- GN은 하나의 sample이 갖고 있는 채널을 그룹지어 평균과 표준편차를 계산한 후에 normalization을 수행한다.
- GN은 하나의 N에 대하여 채널을 그룹 단위로 normalization을 한다.
- 만약에 채널(C)이 6개있고, 그룹(G)=2이면 한 그룹당 3개의 채널이 존재
- 만약 G=1이라면 이는 Layer Normalization과 동일합니다.
- G= 채널수이면 IN 입니다.
-
-
인코더 네트워크는 latent space에 오디오 신호를 포함하고 컨텍스트 네트워크는 인코더의 여러 시간 단계를 결합하여 컨텍스트화된 표현을 얻는다.
-
그런 다음 두 네트워크 모두 목적 함수를 계산하는 데 사용된다.
-
-
-
encoder layer
- The encoder network embeds the audio signal in a latent space
- 커널 크기(10, 8, 4, 4, 4), 스트라이드(5, 4, 2, 2, 2)
- a five-layer CNN
- 인코더의 출력
- low frequency(저주파) feature representation which encodes about (밀리초) of (킬로헤르츠)
- stride는 10ms마다 표현 를 생성한다.
- 인코더의 출력
-
context layer
- 커널 크기가 3, 스트라이드가 1인 9개의 계층
- context network combines multiple time-steps of the encoder to obtain contextualized representations
목적 함수
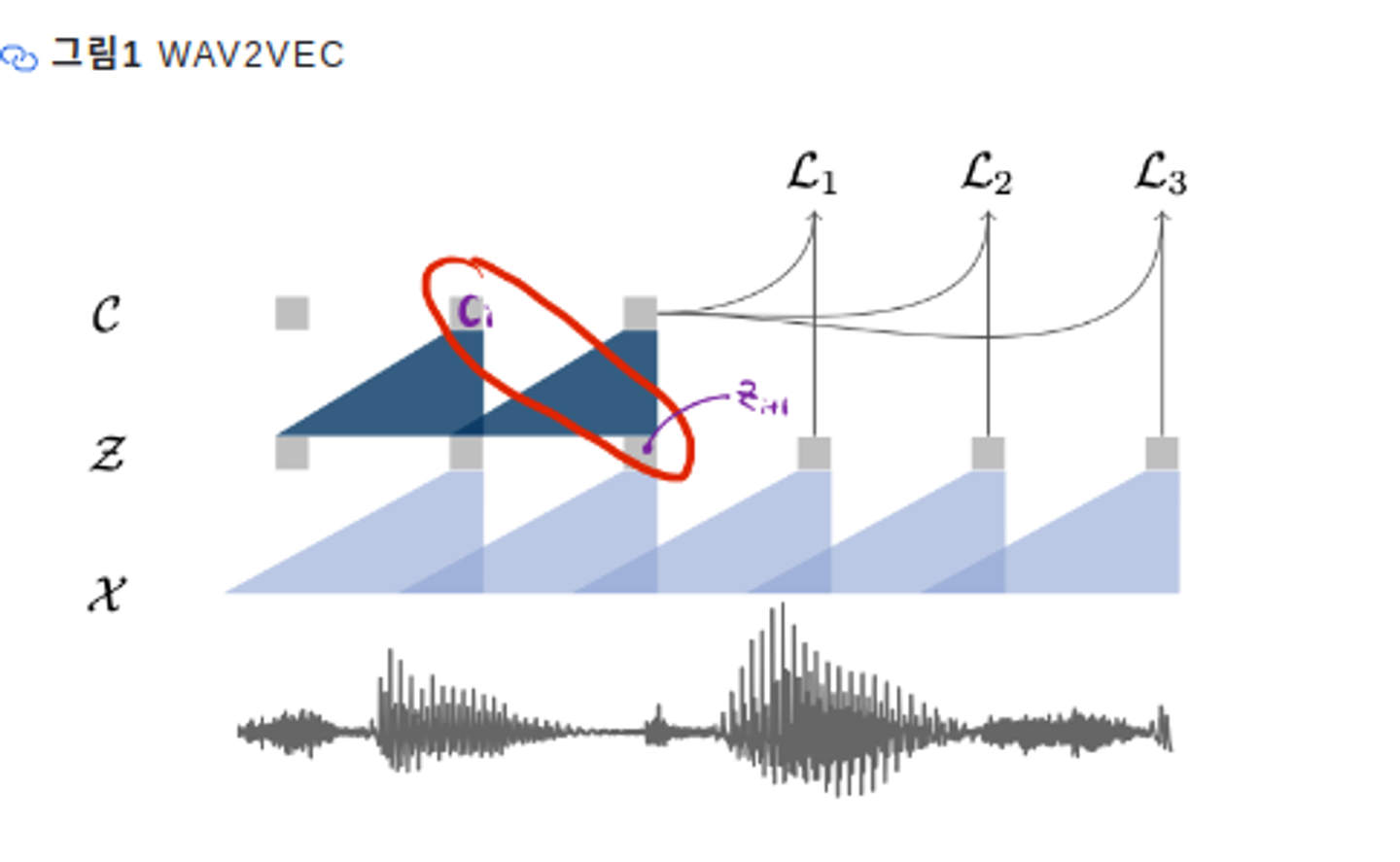
-
Wav2Vec은 Word2Vec처럼 해당 입력이 포지티브 쌍인지 네거티브 쌍인지 이진 분류(binary classification)하는 과정에서 학습됩니다.
-
negative sampling
- 포지티브 쌍은 그림1 처럼 입력 음성의 번째 context representation 와 번째 hidden representaion 입니다
- 네거티브 쌍은 입력 음성의 번째 context representation 와 현재 배치의 다른 음성의 hidden representation들 가운데 랜덤으로 추출해 만듭니다.
-
contrastive loss를 최소화하는 방향으로 최적화 ⇒ 비슷한 쌍들 간에 거리가 0에 가깝도록!
-
학습이 진행될 수록 포지티브 쌍 관계의 represenation은 벡터 공간에서 가까워지고, 네거티브 쌍은 멀어집니다.
- 즉, 학습이 진행될수록 encoder layer와 context layer는 input 음성의 다음시퀀스가 무엇일까에 대한 정보를 해당 음성 피쳐에 잘 담게 된다. (다음 시퀀스를 더 잘 예측하게 된다는 의미?)
-
After training, we input the representations produced by the context network to the acoustic model instead of log-mel filterbank features.
-
contrastive loss
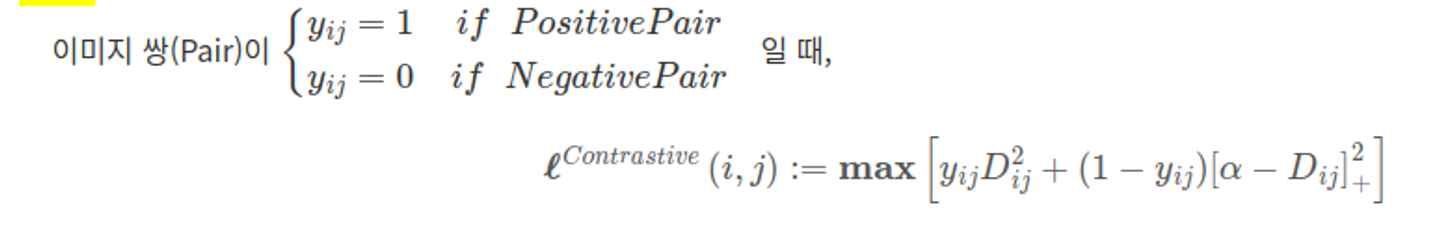
1. 같은 쌍(Pos pair)은 거리가 0 2. 다른 쌍(Neg pair)은 거리가 Margin( α : 절대적 거리) 되도록 학습한다.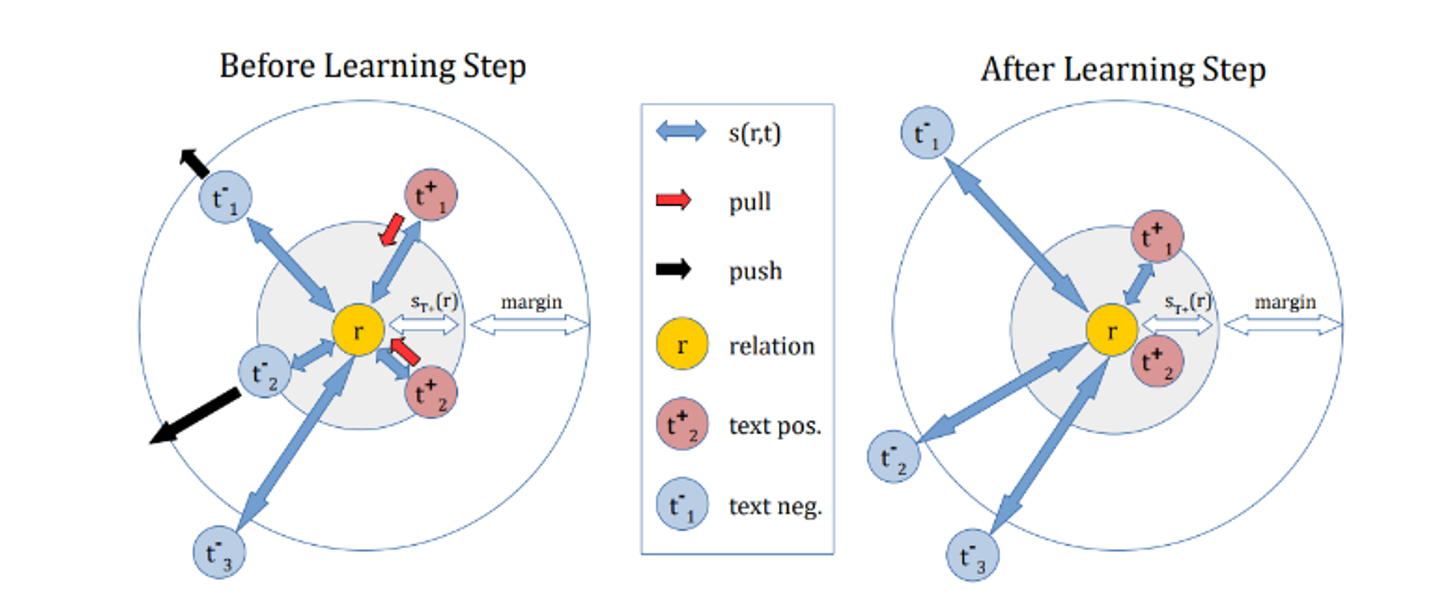
- Margin Parameter를 설정하기 어렵기 때문에, 크게 차이나는 Neg Sample이나, 적게 차이나는 Neg Sample이 동일한 Margin( α )으로 차이가 남
- cf. triplet loss는 상대적 거리 차이를 학습한다.
- Margin Parameter를 설정하기 어렵기 때문에, 크게 차이나는 Neg Sample이나, 적게 차이나는 Neg Sample이 동일한 Margin( α )으로 차이가 남
실험 (ASR with W2V)
데이터
모두 16kHz의 샘플링 레이트를 가지고 있는 영어 오디오 데이터
- TIMIT (Garofolo et al., 1993b) for phoneme recognition
- we use the standard train, dev and test split where the training data contains just over three hours of audio data.
- phoneme recognition (음소 구별) 음소는 말소리의 가장 작은 단위입니다. 우리가 읽기를 가르칠 때 우리는 아이들에게 그 소리를 나타내는 글자를 가르칩니다. 예를 들어 , 'hat'이라는 단어에는 'h' 'a'와 't'라는 3개의 음소가 있습니다.
- Wall Street Journal (WSJ; Garofolo et al. (1993a) for pre-training
- comprises about 81 hours of transcribed audio data.
- transcribed audio data
- 전사 오디오 데이터
- 오디오 데이터를 들리는대로 전사한 데이터 (오디오 + 스크립트)
- Librispeech (Panayotov et al., 2015) for pre-training
- contains a total of 960 hours of clean and noisy speech for training
평가 지표
- Final models are evaluated in terms of both word error rate (WER) and letter error rate (LER).
- WER
- common metric of the performance of an automatic speech recognition(ASR) system.
- 말한 단어 중에 몇 퍼센트의 단어를 틀리게 알아듣는가.
- ex) 10 단어를 말했을 때, 한 단어를 잘 못 알아들으면 WER는 10%로 계산
- WER
성능 향상 방법
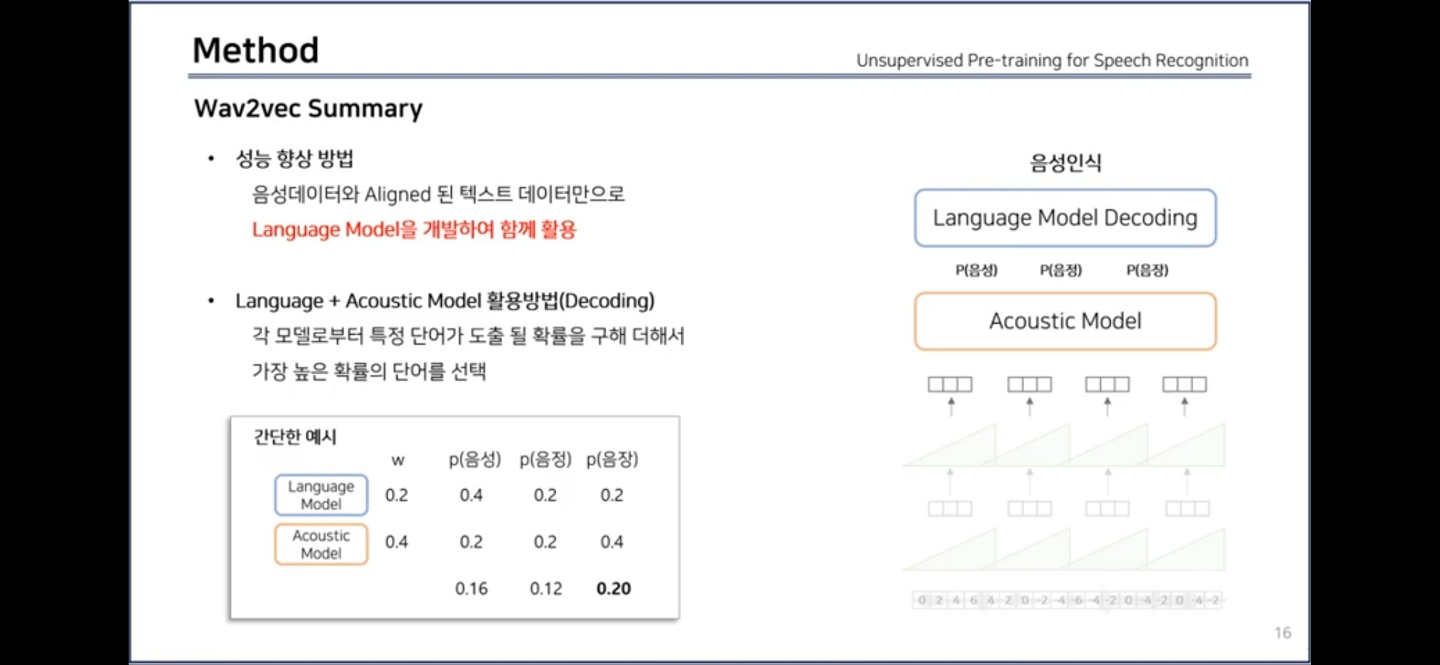
결과
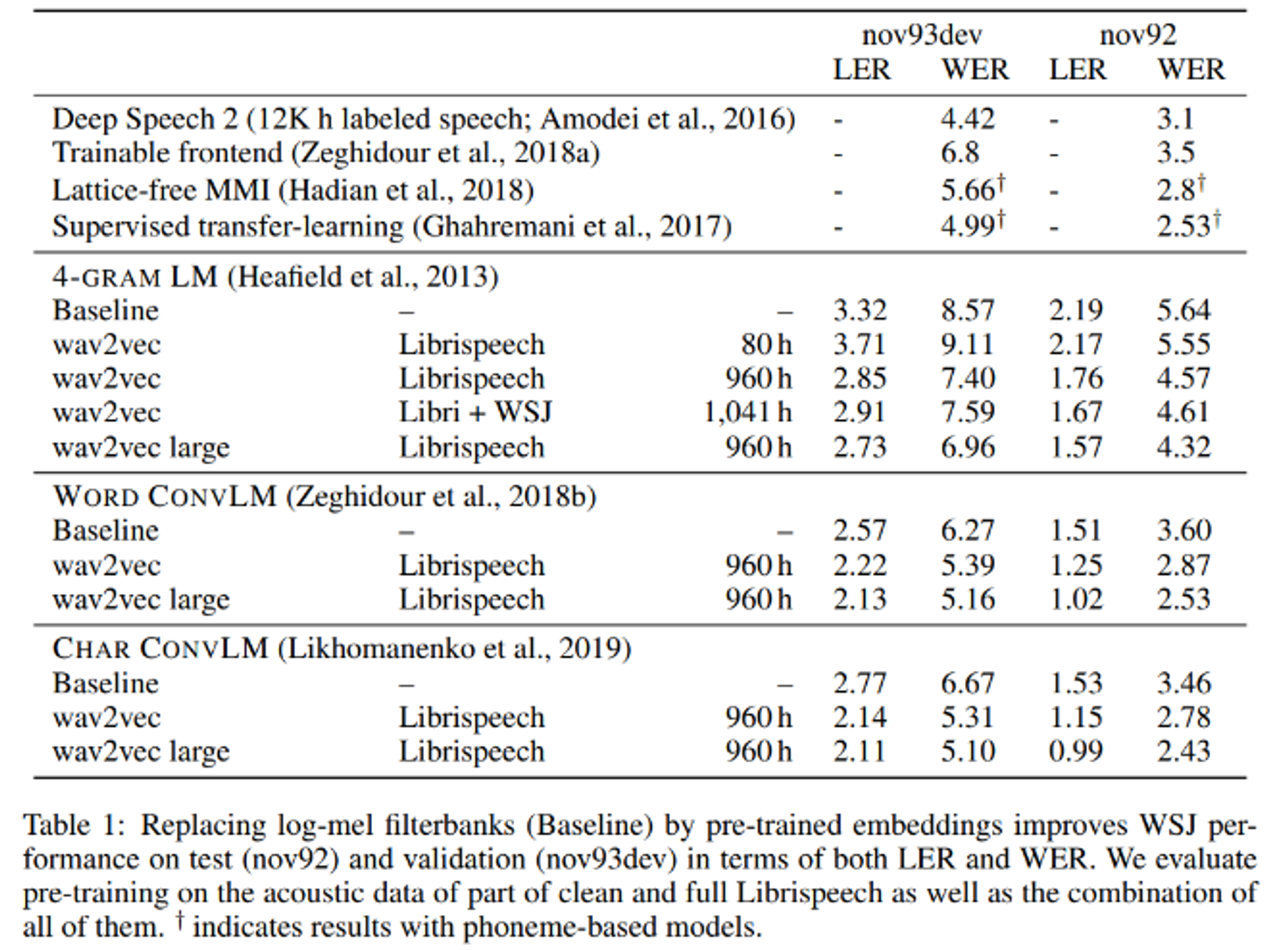
- !
- language model
- We consider a 4-gram KenLM language model (Heafield et al., 2013),
- a word-based convolutional language model (Collobert et al., 2019),
- and a character based convolutional language model (Likhomanenko et al., 2019).
- nov93dev : validation set
- nov92 : test set
- language model
Reference
- about Automatic Recognition Speech [Paper Review] Semi-Supervised Learning in Auto Speech Recognition Introduction
- causal convolution 9. CNN - Transposed, Dilated, Causal
- Group Normalization [논문 읽기] Group Normalization(2018)
- contrastive loss Have A Nice AI
- WER
- Wav2Vec 리뷰 [Paper Review] WAV2VEC: Unsupervised Pre-training for Speech Recognition Wav2Vec
- AM (Acoustic Model) AM(Acoustic Model), LM(Language Model) 이란?
