

Abstract
-
Wav2Vec 2.0
- 음성 데이터는 labeled 데이터를 구하기 매우 어려움 (음성에 대한 스크립트 텍스트)
-
사람이 들으면서 하나하나 전사해야함
-
음소 단위의 분류가 필요한 경우, 사람도 판단 기준이 애매함.
⇒ 따라서 제한된 labeld 오디오 데이터를 가지고 음성 인식을 효과적으로 하는 방법이 필요
-
- Wav2Vec 2.0의 실험 결과는 제한된 양의 레이블링된 데이터로 음성 인식의 실현 가능성을 보여준다.
- 음성 데이터는 labeled 데이터를 구하기 매우 어려움 (음성에 대한 스크립트 텍스트)
-
실험 (Automatic Speech Recognition(ASR) task에 대하여 fine-tuning)
-
Librispeech의 모든 라벨된 데이터(전사 텍스트가 있는 데이터)를 사용해 fine-tuning 했을 때,
-
test-clean/test-other dataset에 대해 WER(단어 오류율, Word Error Rate) 기준 1.8/3.3이라는 점수를 달성했다.
-
Librispeech dastaset
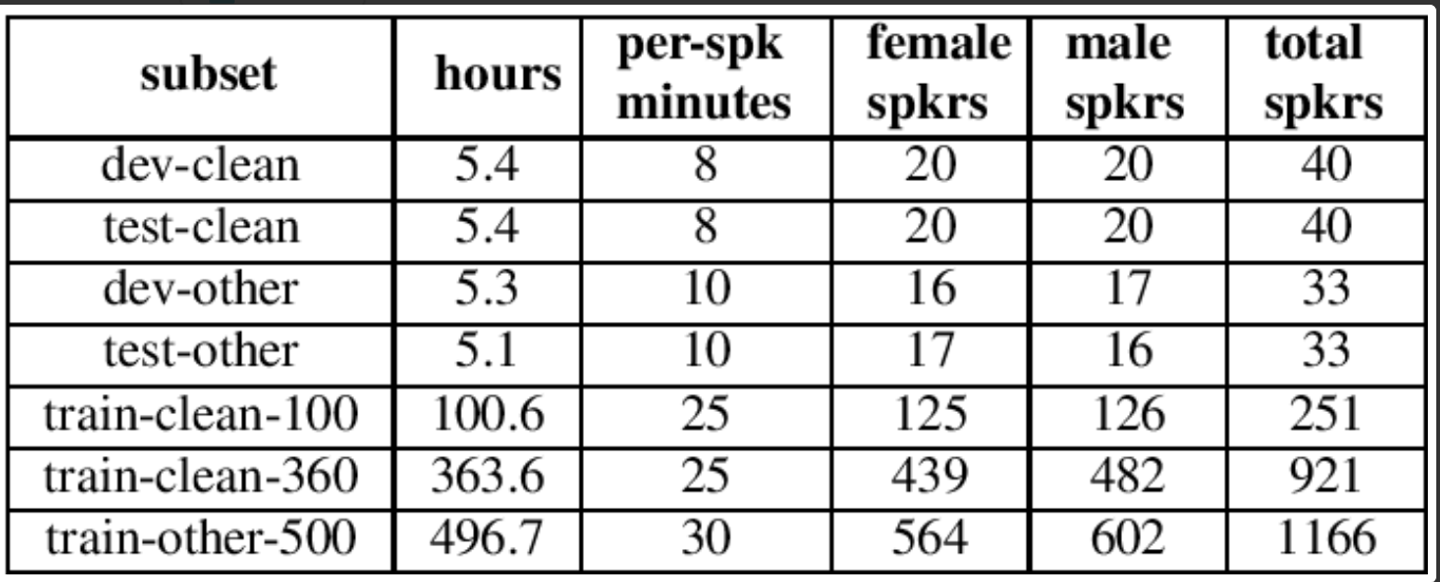
- 총 1,000시간의 오디오북의 모음
- train 데이터는 100시간/ 360시간/ 500시간 세트의 3개 파티션으로 분할
- dev 및 test 데이터는 자동 음성 인식 시스템이 얼마나 잘 수행되는지 또는 어려운지에 따라 각각 'clean' 범주 및 'other' 범주로 분할되고, 각각 약 5시간.
-
-
fine-tuning에 사용되는 labeled 데이터를 1시간짜리로 줄였을 때,
- wav2vec 2.0은 labeled 데이터를 100배 적게 사용하면서 이전 기술의 성능를 능가한다.
-
53k 시간의 unlabeled 데이터 pre-training, 10분의 labeled 데이터에 fine-tuning한 모델 또한 test-clean/test-other data set에 대해 WER 기준 4.8/8.2 를 달성했다.
-
Model
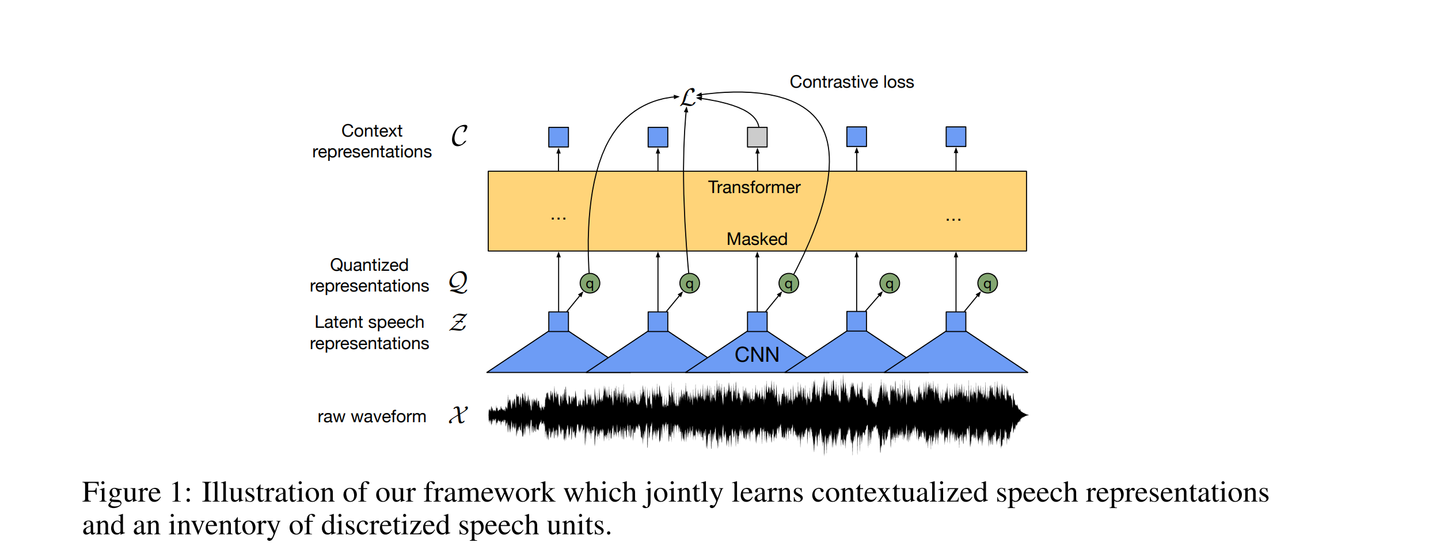
1. Multi-layer convolutional feature encoder
- raw audio input ⇒ (time-steps)마다 (latent representations)로 임베딩
- temporal convolution, 레이어 정규화, GELU 활성화 함수를 포함한 여러 블록들로 이루어져 있다.
- 인코더의 총 stride는 transformer에 input으로 들어가는 (the number of time-steps)를 결정한다. (hyperparameter)
- representations 는 quantization module과 transformer 에 공급된다.
2. Transformer
- representation 로 임베딩
- positional embedding
- transformer를 통해 전체 시퀀스에서 정보를 capture하는 Contextualized representation 산출
3. Quantization module
-
Self-supervised training을 위해서
feature encoder의 output(은 Quantization module을 통해 유한한 음성 representations인 로 이산화(discrete)된다.
⇒ 이러한 quantization 방법론의 도입은 이전 연구에서 좋은 결과를 가져왔기 때문에 그대로 차용.
-
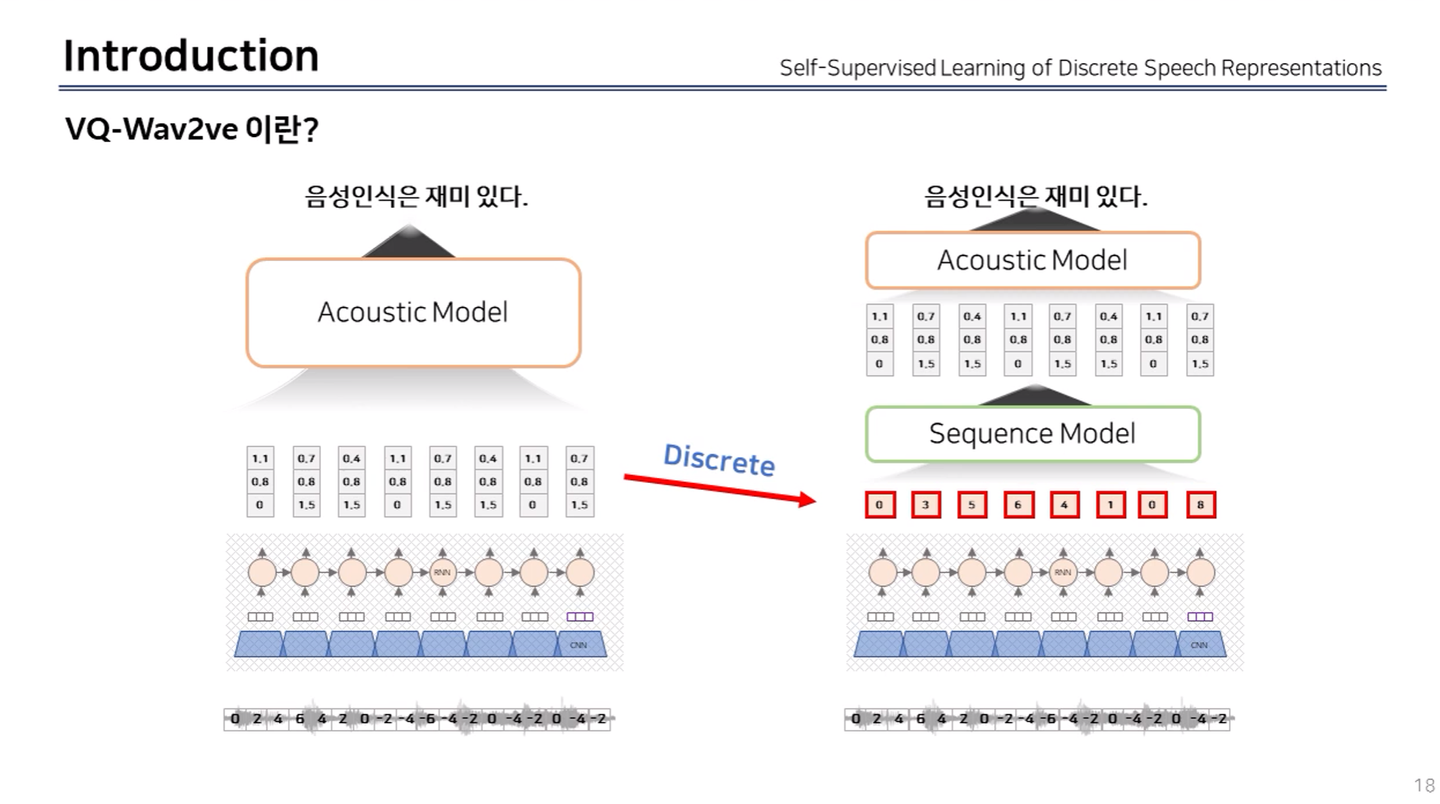
이전 연구, VQ-Wav2Vec
-
연속적인 데이터(음성)을 비연속적인 데이터로 변경하고(discrete 방법론) Self-Supervised Learning 방법론을 적용
-
Self-Supervised Learning(SSL)은 많은 양의 unlabled data로 모델을 사전학습하고, 소량의 labeled data로 모델을 fine-tuning 시키는 학습 방법.
-
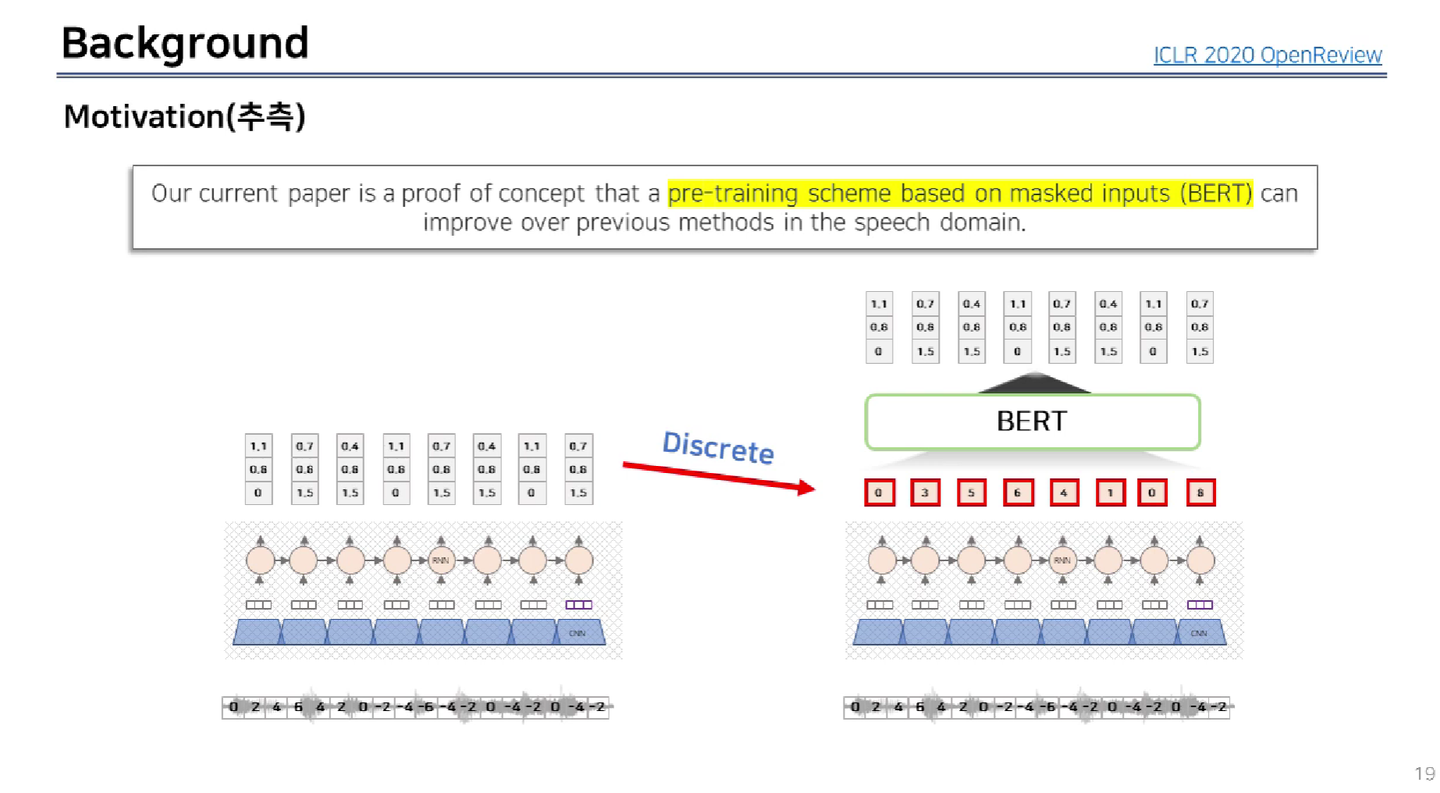
왜 갑자기 음성처리 분야에서 discrete 방법론을 도입했을까?에 대한 답변
-
BERT가 사용한 MLM(Masked Language Model) pre-trained 방법론을 도입하고 싶었기 때문이라고 답변
-
-
-
-
Quantization 방식 중에서도,
Product Quantization(PQ)수행 -
Quantization이 무엇입니까?-
간단히 말하면 가지고 있는 정보의 양을 줄여 사이즈와 레이턴시(자극과 반응 사이의 시간)를 줄이고 약간의 성능 감소를 가지는 방법을 연구하는 분야
-
모든 데이터를 다 수용할 수 없기 때문에 (기술 및 자원의 한계) 그래도 가장 데이터의 전반적인 흐름을 잘 표현하는 값을 표본으로(?) 뽑아야하는데,
- 이런 적절한 값을 뽑는 방식이
quantization이고, 이quantization값을 구하기 위해서 사용하는 게voronoi,Lloyd(k-means)알고리즘.
- 이런 적절한 값을 뽑는 방식이
-
kmeans는 k개의 클러스터의 중심을 임의로 정하고, 이 중심을 반복해서 재조정하는 과정.- 클러스터의 중심(centroid)과 클러스터 내 데이터들 간의 유클리디안 거리를 계산 ⇒ 중심점(centroid)과 그 클러스터의 속한 다른 점들과의 거리들의 합이 최소가 되도록 중심점을 재조정한다.
- 클러스터의 중심(centroid)과 클러스터 내 데이터들 간의 유클리디안 거리를 계산 ⇒ 중심점(centroid)과 그 클러스터의 속한 다른 점들과의 거리들의 합이 최소가 되도록 중심점을 재조정한다.
-
그래서 Quantization이 뭔데..?
- quantization 개념을 빗대어 표현하자면
- 세상을 구성하는 무한한 색상들⇒ RGB 채널을 이용해 $255^3$개의 색으로 세상을 표현 - -1과 1사이의 무한한 실수가 존재하지만.. ⇒ 컴퓨터는 이 모든 데이터를 표현하지 못하기 때문에, 64비트, 2비트(4개의 데이터), … 이런 식으로 그래도 최대한 -1과 1 사이의 실수들을 잘 표현할 수 있는 값들을 뽑아내야함. -
벡터 양자화란 연속 변수인 벡터를 이산 변수로 바꾸는 과정
-
관측치가 이산적(discrete)이지 않고 연속적(continuous)일 경우 은닉마코프모델에서 방출 확률(emission probability)을 계산하기가 까다롭습니다. 이산 변수의 경우라면 해당 상태에 대응하는 관측치들의 갯수를 세어서 방출확률 값을 추정하면 될텐데요. 연속 변수라면 그 갯수를 셀 수 없기 때문에 jj번째 상태일 때 tt번째 관측치가 관찰될 방출확률, 즉 P(ot|qj)P(ot|qj)을 추정하기 어렵습니다. 연속 변수에 대한 방출확률 계산을 위해 제안된 모델이 바로 가우시안 믹스처 모델(Gaussian Mixture Model)입니다.
-
연속 변수에 대한 방출확률 계산을 위해 쓸 수 있는 방법이 또 있습니다. 벡터 양자화(Vector Quantization) 기법입니다. 벡터 양자화란 연속 변수인 벡터를 이산 변수로 바꾸는 과정을 가리킵니다.
-
양자화를 수행하고 나면 연속 변수가 이산 변수로 변환된 상태가 되는데요. 이후 기존 이산 변수에 대한 방출 확률을 추정했던 것처럼 은닉마코프모델을 학습하면 됩니다.
-
-
PQ(Product Qunatizaion) 과정-
Vector Quantization의 일반화된 방식
-
기존 차원 벡터를 차원의 서브벡터 개로 나눈다는 것
ex) 1024사이즈의 벡터가 50k개 있다면 ([50k * 1024])
⇒ 8개의 [50k * 128] 서브벡터
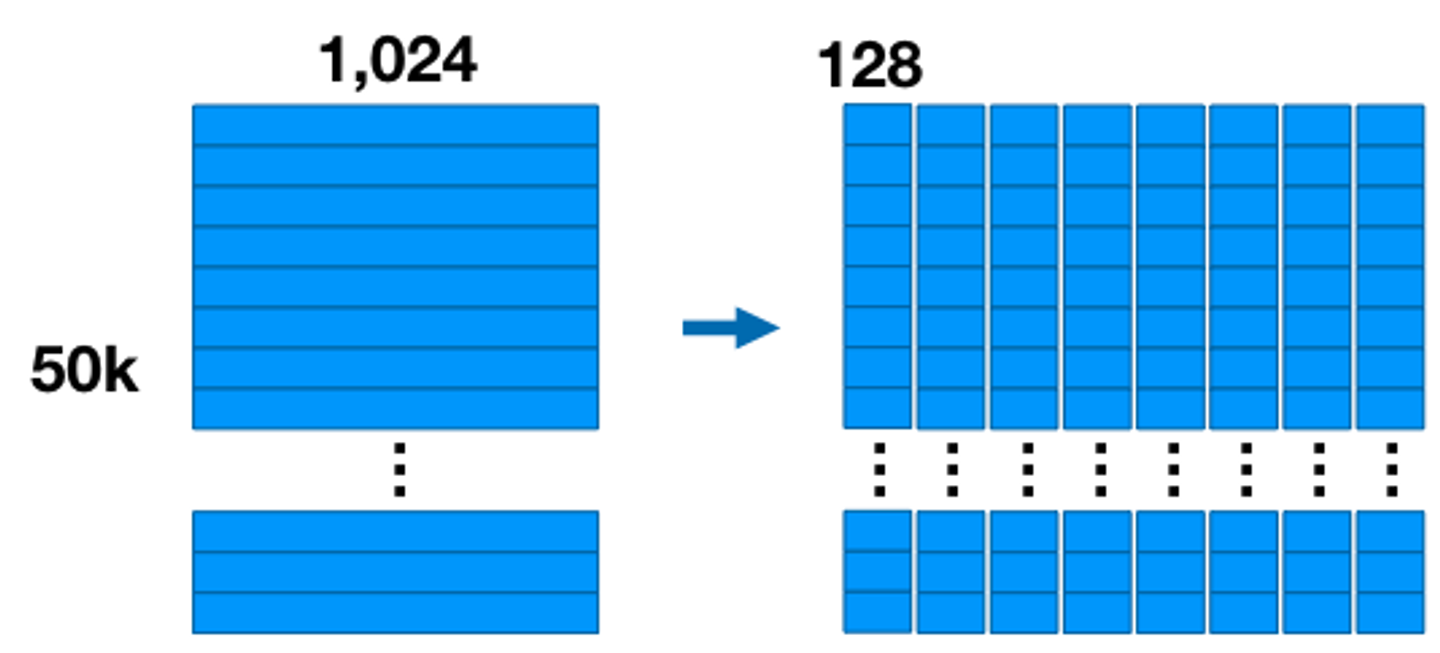
-
개의 서브벡터 각각에 Vector Quantization, 즉 KMeans clustering을 실행해줍니다. (=256)
⇒ 그럼 m개의 서브벡터 각각들이 KMeans에 의해 개의 centroid를 가진 압축된 벡터가 된다.
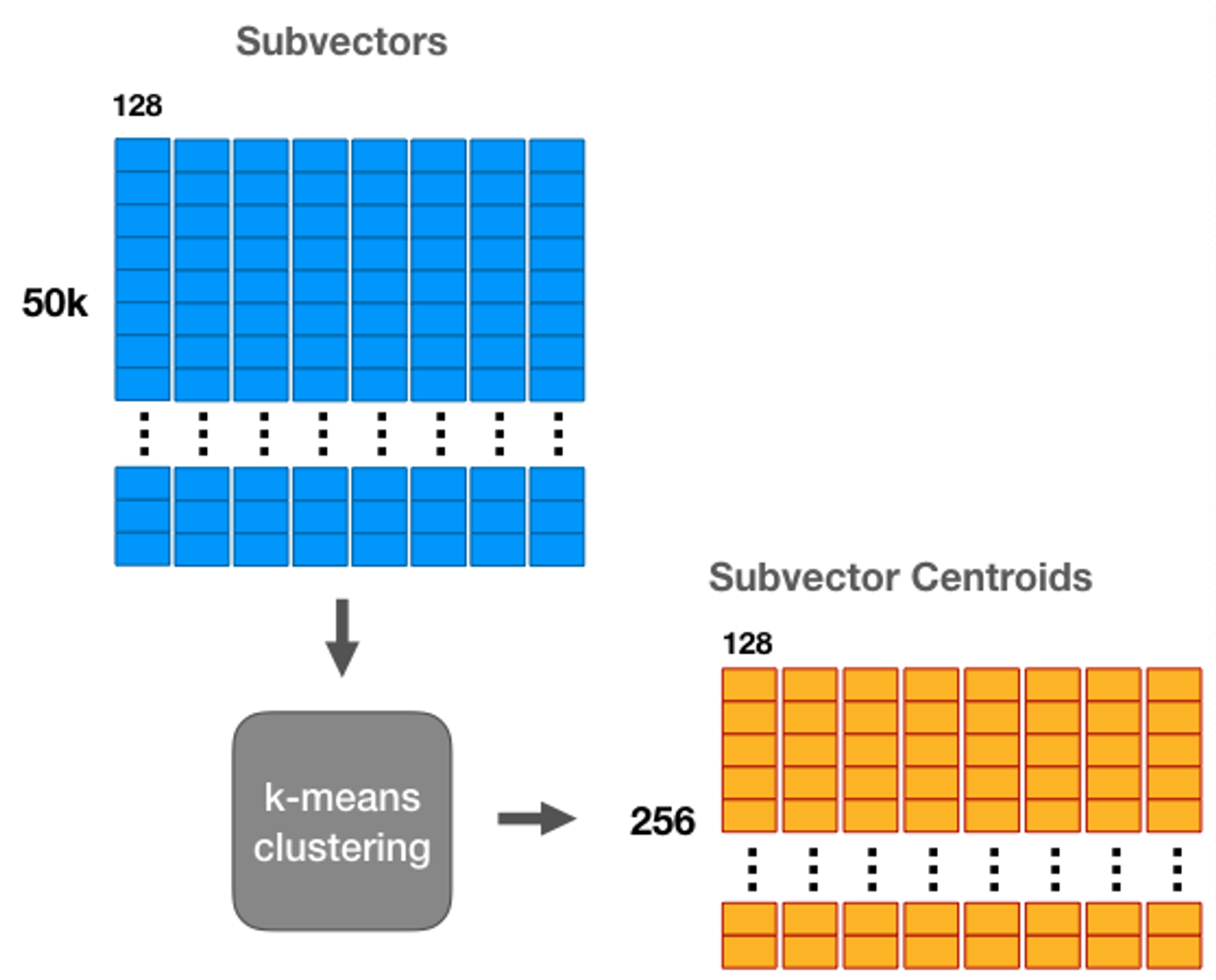
- Vector Quantization이었다면, 벡터를 쪼개는 과정이 없었을테니 256개의 centroid를 가진 하나의 codebook을 얻었을 것.
- 그러나! PQ는 256개의 centroid를 가진 codebook 8개가 생성됩니다.
-
서브 벡터 8개로 나눠줬기 때문에 ⇒ 하나의 서브 벡터마다 코드북이 한개씩 생성
⇒ 이렇게 생성된 8개의 코드북은 서로 product 결합 가능하고
⇒ 실질적으로 PQ가 표현할 수 있는 벡터는 개의 centroid를 가진 codebook을 만든 것.
⇒ centroid가 많다는 것은, 데이터를 표현하는 방법이 많아졌다는 이야기.
⇒ 그렇다면 정보손실을 최대한 줄이면서 quantization을 수행해냈다는 이야기.
-
-
Centroid는 KMeans로 나온 클러스터의 중심값
-
어떤 벡터가 id=2인 centroid에 가깝다면 그 벡터는 id=2인 centroid의 값으로 매핑 시켜버립니다
-
한 클러스터 안에 있는 모든 데이터들은 그 클러스터의 중심값과 같은 값을 가지게 하는 것
⇒ 모든 같은 값을 가진 데이터들을 굳이 사이즈가 큰 Floating Point로 저장할 필요가 없기 때문에, int8인 id로 대체
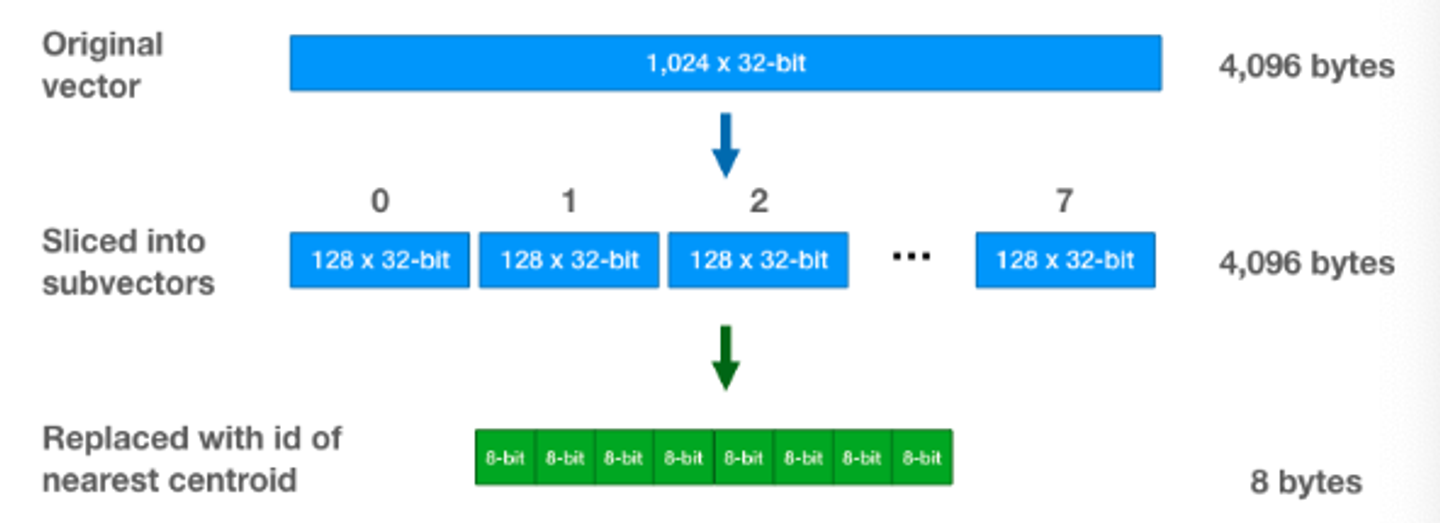
⇒ 결과적으로 1024사이즈의 FP32를 저장하고 있던 벡터는 PQ를 통해 8개의 서브벡터로 쪼개진 후 각 KMeans를 통한 각각의 서브벡터는 INT8을 저장하는 벡터로 바뀌게 됩니다. 4096바이트가 8바이트가 된거죠.
⇒데이터를 압축하고 검색 속도를 향상하기 위해 쓰이기도 합니다
-
-
-
코드북(codebook)이란..?
-
Embedding Table
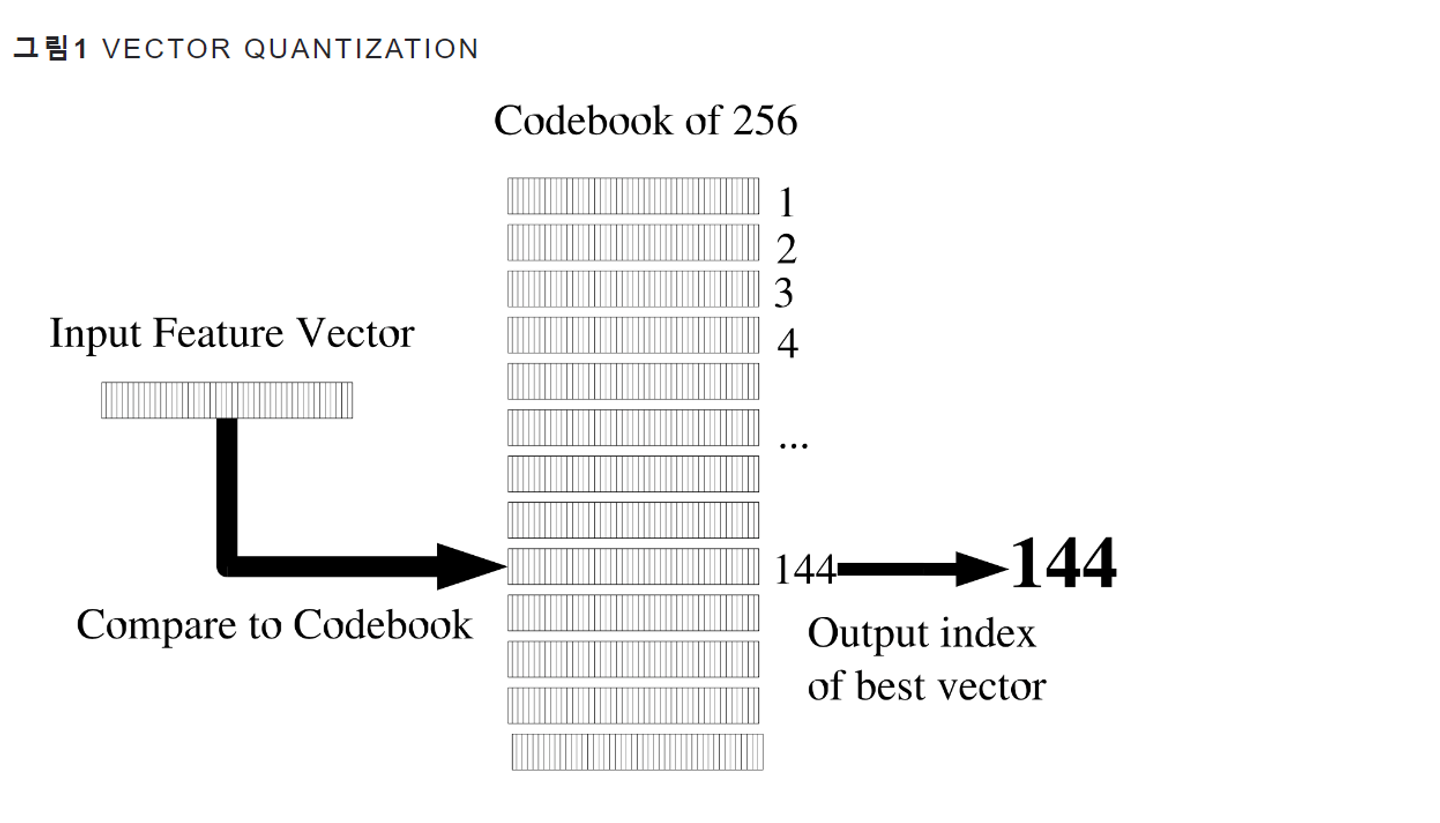
-
- Codeword이란 비교 대상이 되는 벡터
- 이들 Codeword를 모두 모은 집합을 Codebook
- 그림1의 경우 Codebook은 256개의 Codeword들로 구성
- 이처럼 벡터 양자화를 수행한다면 모든 입력 벡터를 0~255의 정수로 양자화(8-bit)할 수 있다.
- 입력 피처 벡터(Input Feature Vector)가 들어왔을 때 각각의 Codeword와 거리(distance)를 계산합니다.
- 예컨대 이 입력벡터가 144번째 Codebook와 거리가 가장 가까웠다고 가정해 봅시다. 그러면 벡터 양자화의 결과는 해당 odebook의 인덱스(144)가 됩니다.- Product quantization (PQ)의 서브벡터(codebook)의 개수를 라고 하고, (⇒ 아래 그림에서는 8)
-
CNN(feature encoder)을 통과한 임베딩 벡터 라고 가정
- 는 raw audio data를 나누는 time step 수 (stride를 몇으로 지정하냐에 따라 달라진다.)
- 는 CNN을 통과한 embedding 벡터의 크기 (ex. 1024)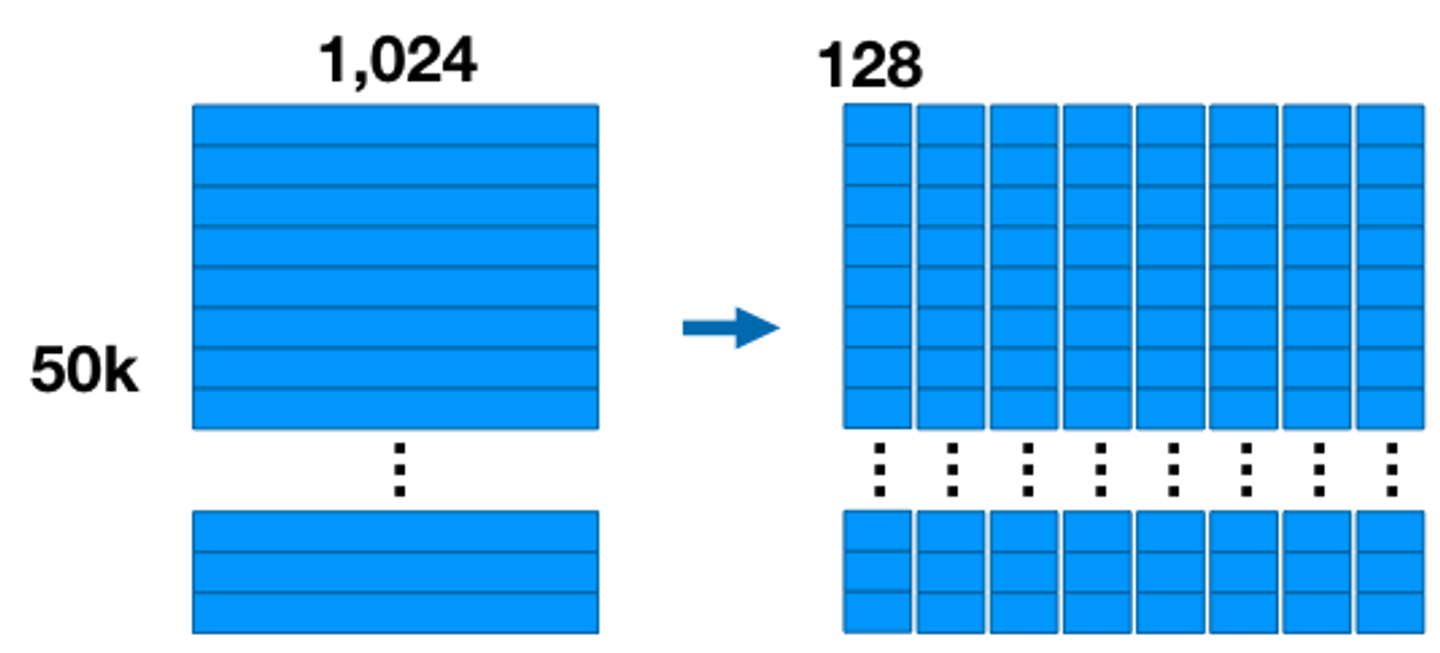
-
- 로부터 크기가 인 개의 서브벡터를 만들고, PQ를 수행하여 각 서브벡터의 데이터들을 클러스터링함 (ex. G=8 ⇒ 1024/8=128)
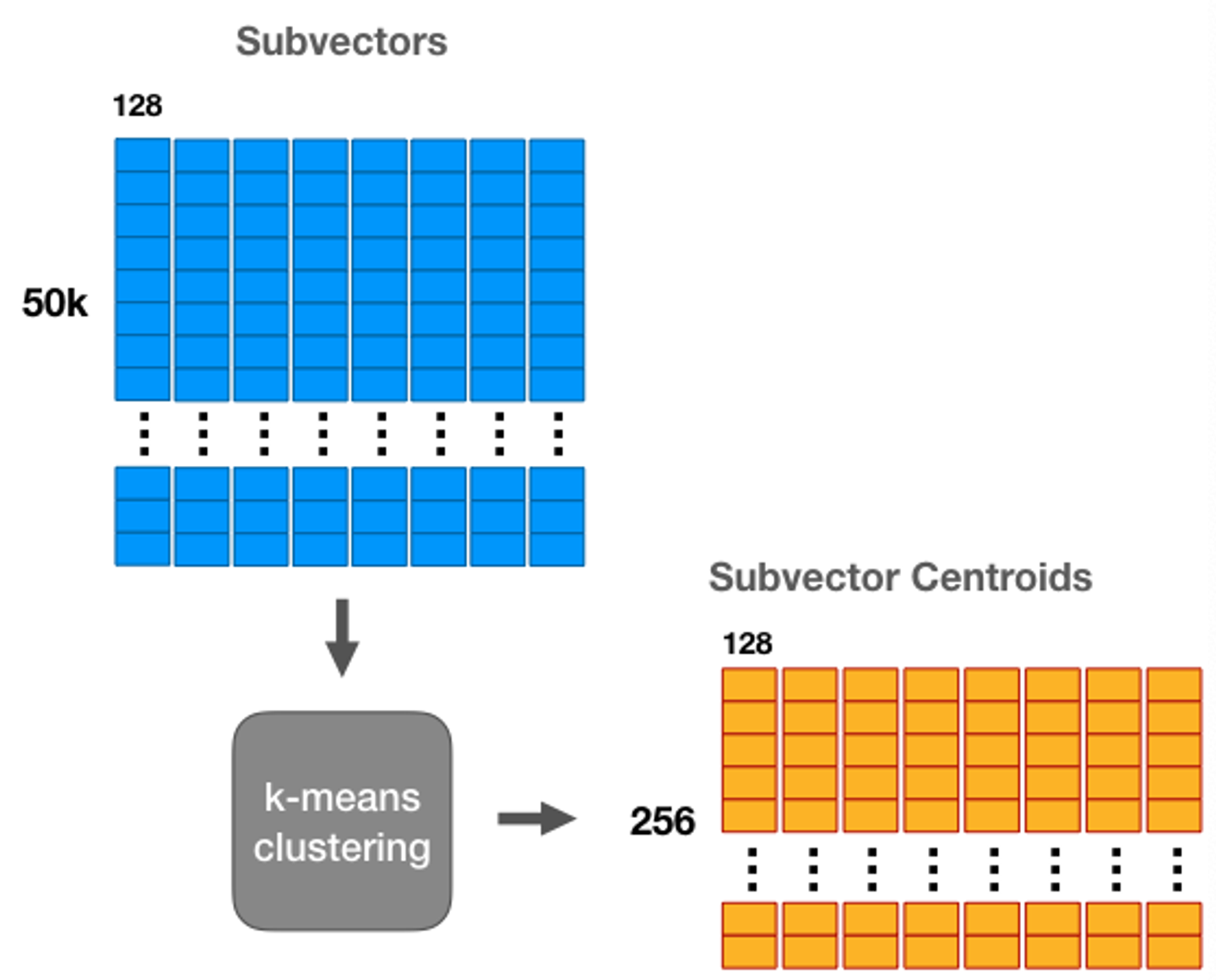
- 각 서브벡터에 PQ를 수행할 때, 서브벡터의 entry들이 codebook 내에서 정의된 centroid중 가장 가까운 centroid의 data로 변환됨.
- 가장 가까운 centroid를 찾는 과정은 gumbel softmax를 통해서 수행
- Quantization module을 거친 quantized representative인 를 활용해서 loss 계산 및 역전파를 해야하는데, ⇒ codebook 내의 가장 가까운 centroid의 index로 변환하는 과정이 discrete하고, 미분불가능.
- gumbel softmax는 이러한 미분불가능한 작업을 역전파가 가능하게끔 미분가능하게 만들어주는 activation function
- Quantization module을 거친 quantized representative인 를 활용해서 loss 계산 및 역전파를 해야하는데, ⇒ codebook 내의 가장 가까운 centroid의 index로 변환하는 과정이 discrete하고, 미분불가능.
- 클러스터링 후, entries ()와 개의 코드북이 주어졌을 때,
- 각 코드북으로부터 하나의 entry를 선택해 concatenate해서 결과 벡터들( )을 구하고,
- 크기가 인 벡터로 변환하고, 단순 linear transformation 를 적용하여 를 얻음
- forward propagation에서는 가장 가까운 centroid를 찾는 argmax 함수를 활용하고, backward propagation에서는 gumbel softmax로 진행
Training
pre-train
-
unlabeled dataset 이용
-
일정 비율의 time-steps를 latent feature encoder의 output인 를 마스킹(BERT에서의 MLM과 비슷)
-
그러나 quantization module로 들어가는 input은 마스킹하지 않는다! 오직 transformer에 들어가는 z만 마스킹.
-
latent representations 의 절반은 트랜스포머에 입력되기 전 마스킹된다.
-
마스킹되지 않은 나머지 부분들 만들어진 Contextualized representations로 마스킹된 time step의 positive Quantized representation()을 유추하는 방식으로 pre-training을 진행한다.
-
전체 오디오 구간 중 0.065 를 랜덤하게 고르고 선택된 zt 에서 z(t+10) 만큼 마스킹 - 전체 T 의 49% 가 평균 span length 인 299ms 로 마스킹
fine-tuning
- labeled dataset
objective
- 손실함수 : 여기서 은 contrastive loss, 는 diversity loss, 는 하이퍼파라미터
-
Contrastive Loss
- 은 마스킹된 time step의 Quantized representation을 유추할 때 활용하는 Loss
- Transformer를 통과한 벡터 가 Quantized vector 와 잘 일치하면 Loss 함수값이 감소하는 형태

- 여기서 은 cosine similarity 함수
-
Diversity Loss
- Codebook의 entry들이 균일하게 활용될수록 Loss 함수값이 감소하는 형태
- Quantized representation의 softmax를 씌운 것
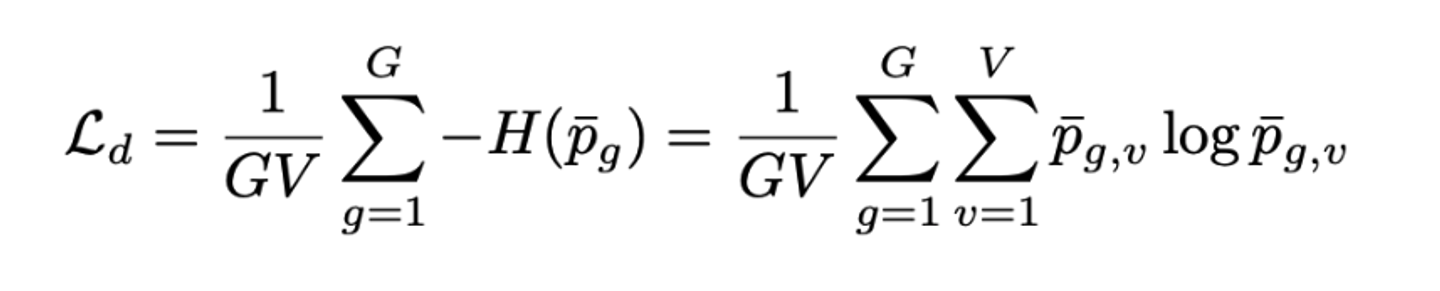
Fine-tuning
- 위의 과정으로 pre-train된 모델에 추가적인 Linear layer를 Context network위에 붙이는 등 원하는 작업을 수행하도록 모델을 구성
- 이후 labeled dataset으로 fine-tuning
Reference
- Wav2Vec 2.0 리뷰 [논문리뷰/설명] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations wav2vec 2.0 리뷰
- VQ-Wav2Vec 리뷰 [Paper Review] Vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
- Quantization quantization | DataCrew
- 코드북 Training Technics
- Self-Supervised Learning Self-Supervised Learning
