![]()
Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
📌Sequence Problems
- Sequence Problem 종류
- one-to-many: input -> single value, output -> sequence인 경우
- many-to-one: input -> sequence, output -> single value인 경우
-many-to-many: input -> sequence, output -> sequence인 경우
![]()
-
Sequence Problem 예시
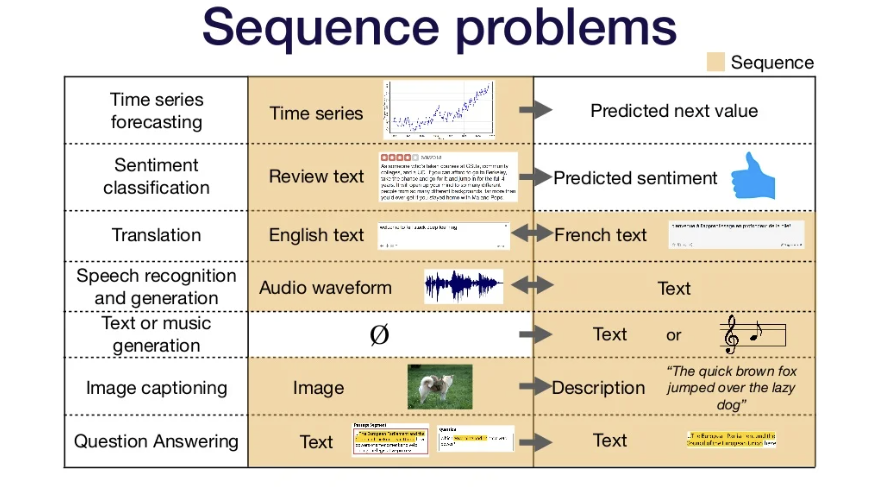
-
Why not use feedforward networks instead?
-
Problem 1: Variable Length Inputs
- 모든 sequence에 padding을 추가해 max length와 동일한 크기를 갖도록 하여 해결할 수 있다.
-
Problem 2: Memory Scaling
- Memory requirement scales lineraly in number of timesteps
-
Problem 3: Overkill
- Model needs to learn patterns everywhere in the sequence -> data inefficient!
- This ignores the nature of the problem that patterns repeat themselves over time.
-
📌RNNs
- Instead of having a single massive matrix(one that has independent weights for every position in the sequence), does stateful computation.
- Stateful Computation:
- output of model depends on the input at the current timestep in the sequence & some state the model maintains over time.
- For every input in a particular timestep, the model produces the output as well as the next hidden state for the model.
- 아래 그림처럼 처음에 h0와 x1이 주어지면 output인 y1뿐 아니라 next state인 h1까지 계산한다. 같은 과정(weight)으로 이후 step들도 계산함.
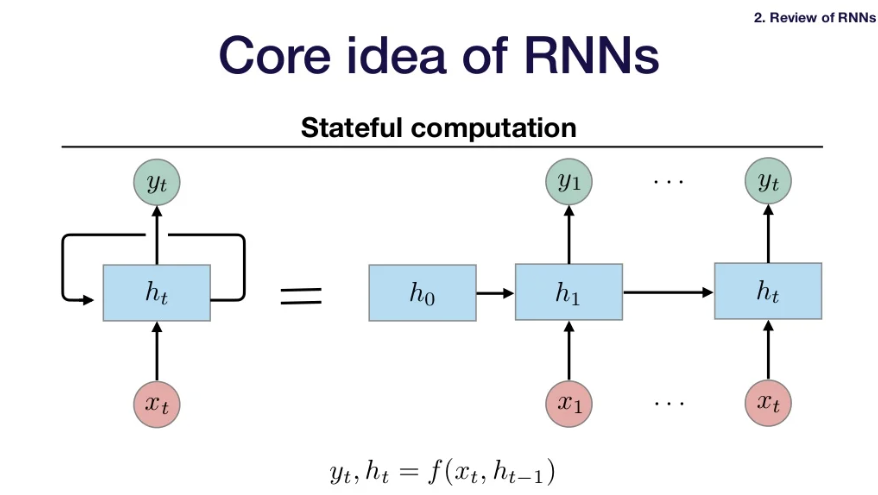

- RNN에선 input이 있을 때마다 step function을 사용하고, output을 생성한다. -> many-to-many problem일때는 잘 적용됨.
- 그치만 many-to-one problem인 경우에는 어떻게 해결하는가?
- 가장 마지막 timestep의 output인 yt를 가지고 전체 sequence값을 계산한다. (yt값을 classifier가 전달받아 결과값을 출력한다.)- Encoder-decoder architecture
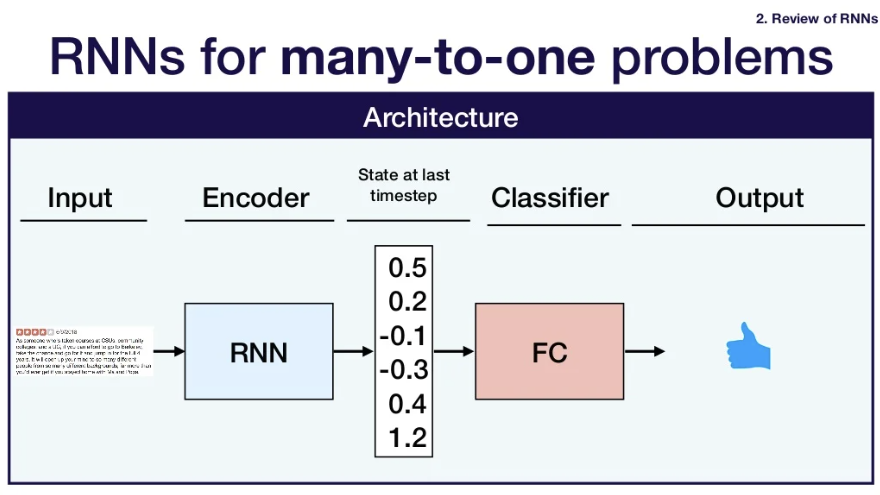
- Encoder-decoder architecture
- one-to-many problem의 경우에는 어떻게 해결하는가?
- convnet을 사용해 image classification까지의 전체 과정을 수행하는 방법 대신 fully-connected layer의 마지막 단계 vector들을 RNN의 inital hidden state로 사용한다.
- Encoder-decoder architecture
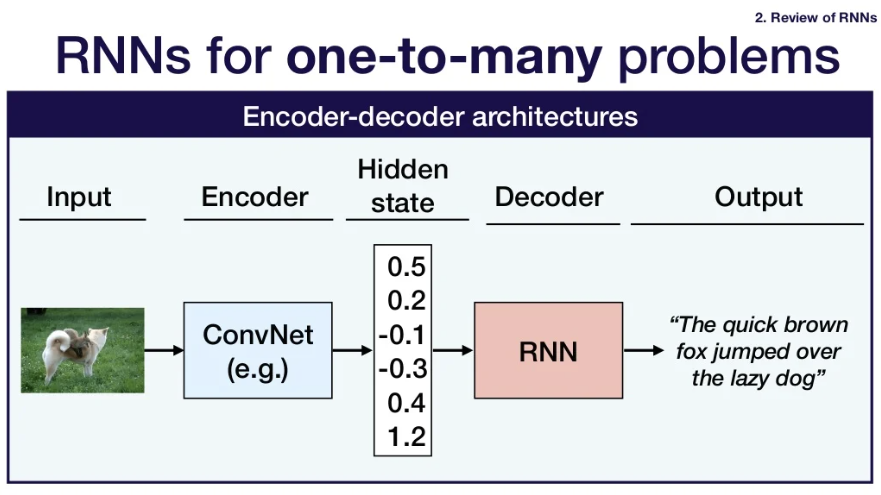
- 💡disclaimer : thinking of encoder and decoder as separate networks is just a mental heuristic for understanding - they aren't separate in any meaningful sense!(They are connected during back propagation.)
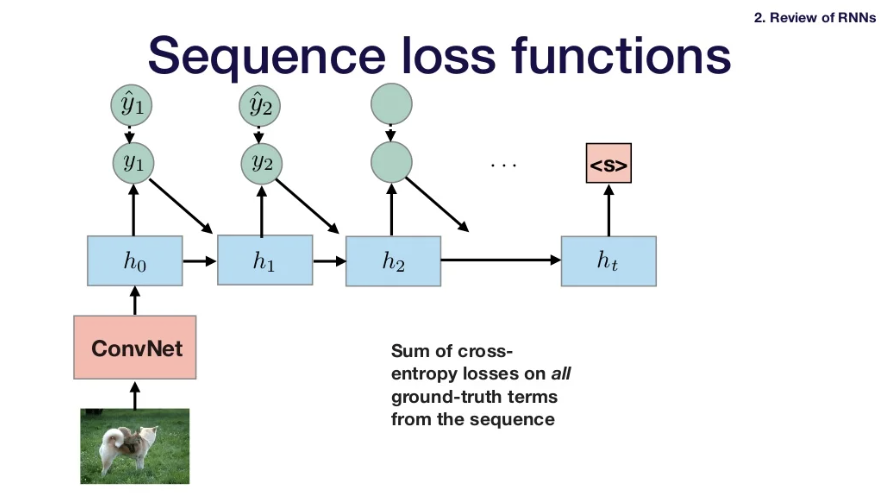
- 여기서 input은 이전 timestep의 output임.
- 그렇다면 언제 input을 멈춰야할지 알 수 있을까?
(이전 단계의 output이 이번 단계의 input이면 계속 input이 존재할 것이므로)
-> special character를 사용. (tells the architecture when to stop.) - many-to-many problem에서는 어떻게 해결하는가?
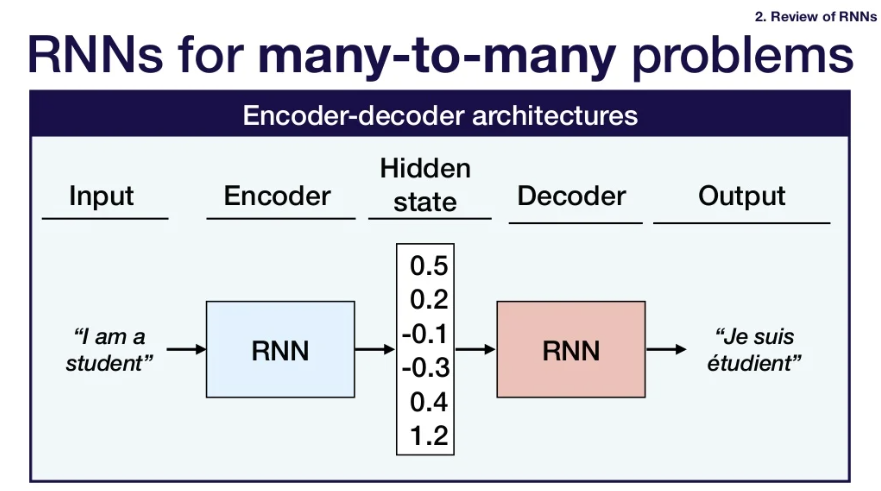
- 마찬가지로 encoder-decoder architecture 사용.
- encoder와 decoder 모두 RNN임.
- most common case
- used for machine translation
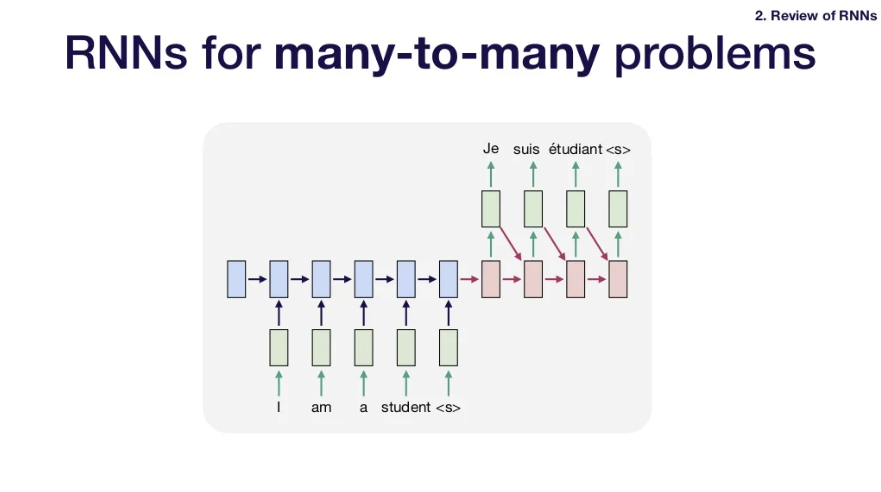
- one-to-many problem처럼 이전 단계의 output을 이번 단계의 input으로 사용하고 special character을 만나면 input 멈춤. encoder로 구한 output을 decoder의 inital input으로 사용하고 같은 과정을 반복한다.
- 입력문장의 모든 정보들은 encoder RNN을 통해 하나의 hidden state vector로 압축된다. -> 이후 decoder RNN의 inital state vector로 사용.
📌Vanishing gradients issue
- RNN Desiderata
- Goal: handle long sequences- Connect events from the past to outcomes in the future
- i.e., Long-term dependencies
- e.g., remember the name of a character from the last sentence
- Connect events from the past to outcomes in the future
- Vanilla RNNs: the reality
- Can't hadle more than 10-20 timesteps- Longer-term dependenicies get lost
- Why? Vanishing gradients
- sigmoid와 tanh는 input값이 커지면 derivative값이 0에 매우 가까워짐
- tanh primes multiplied by each other eventually hits zero in numerical precision
- After enough steps, gradients are too small
- ReLu는 위의 문제에 해당되지 않는데?
- ReLu RNNs in practice often have the opposite problem which is exploding gradients.(gradients tend to get too big)
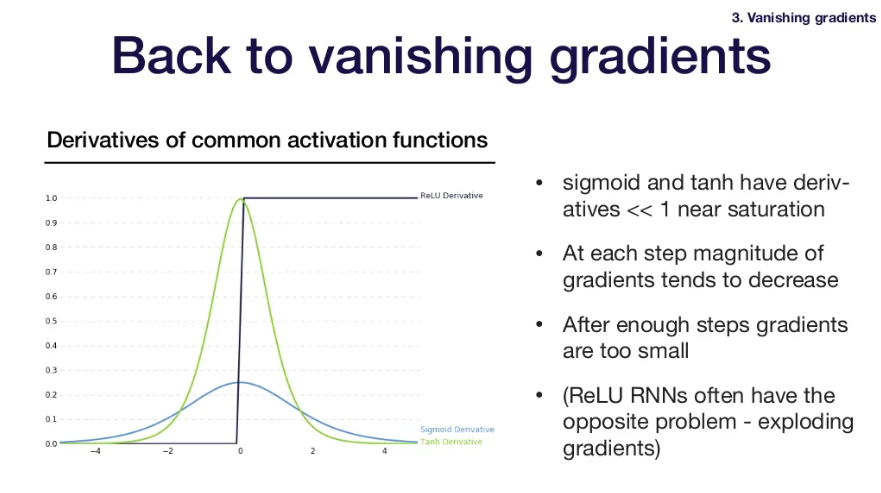
- ReLu RNNs in practice often have the opposite problem which is exploding gradients.(gradients tend to get too big)
📌LSTMs
-
목적: use a compute_next_h function that preserves gradients -> vanishing gradients issue를 해결하고자 함.

-
Main idea: introduce a new "cell state" channel
- In addition to hidden states that get updated every time step, update "cell states".
- Cell states have very particular rules about how it gets updated. 이때 규칙은 hidden state와 cell state간의 interaction에 따라 세가지 step으로 나뉜다.
- Forget gate: decide what parts of old cell state to forget. Previous hidden state를 input과 합쳐 sigmoid에 입력함. Sigmoid output값과 cell state를 multiply -> gets rid of old info that no longer needs to be in the cell state
- Input gate: decide how to incorporate new information into the cell state
- final gate: decide how to produce the output as hidden state
-
What about other RNNs like GRUs?
- LSTMs work well for most tasks.
- Try GRUs if LSTMs are not performing well.
📌Case Study: Machine Translation (Bidirectionality and Attention)
-
Key questions for machine learning applications papers
- What problem are they trying to solve?
- What model architecture was used?
- What dataset was it trained on?
- How did they do training?
- What tricks were needed for inference in deployment?
-
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation(Wu et al.,2016)
- 1) What problem are they trying to solve?
-
2) What model architecture was used?
-
Encoder와 decoder이 모두 RNN인 Encoder-decoder architecture
-
Problem 1: using single layer will underfit the task
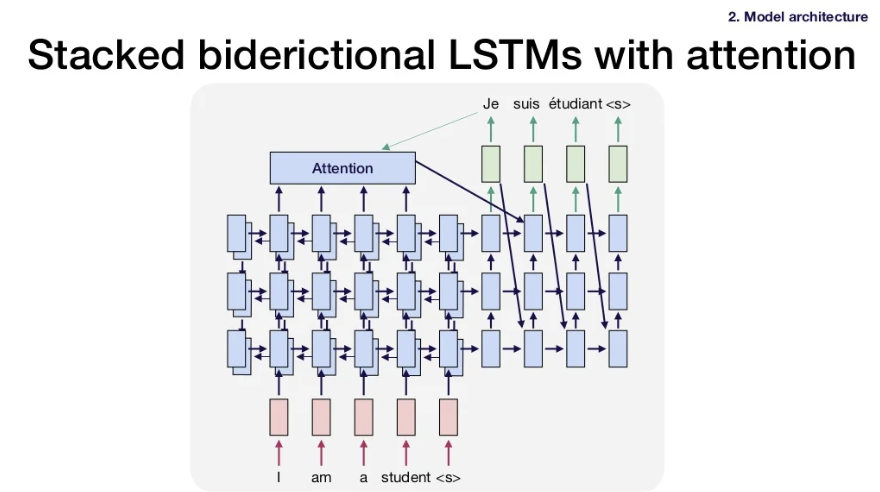
- Solution 1: stack LSTM layers
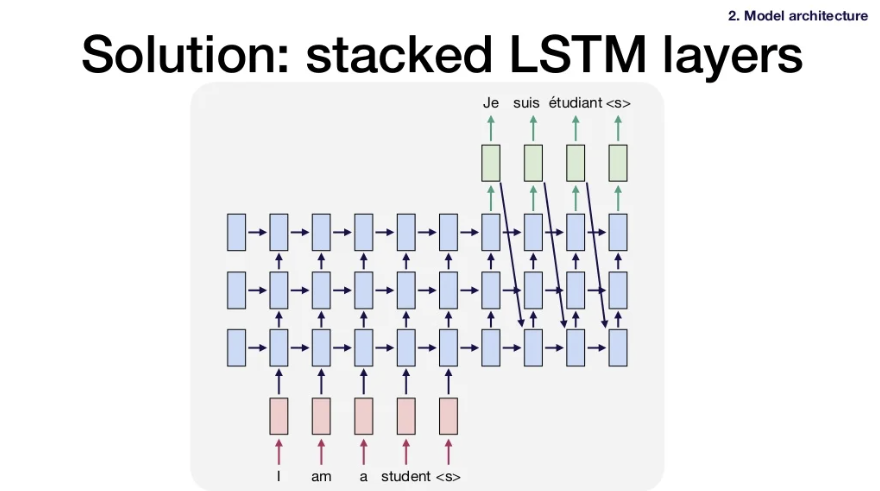
-
Problem 2: Stacked LSTMs are hard to train. They barely work with more than 6 layers.
-
Solution 2: add residual connections(ResNet처럼). LSTM의 layer 사이에 skip function을 둔다.
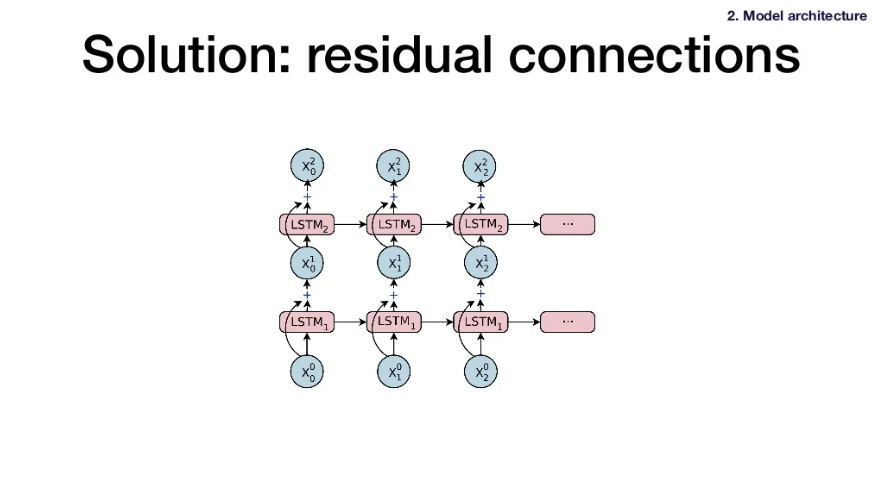
-
Problem 3: bottleneck between the encoder and decoder when dealing with large information
-
Solution 3: Attention(Attention에 대해서는 다음주에 더 자세히 다룸.)

Idea: 각 언어의 어순을 고려해 번역하려는 단어마다 관련 있는 문장의 영역에 집중한다.
How: Relevance score을 사용해 문장 속 각 단어들에 대한 attention value를 계산. Input sentence의 모든 단어들이 output sentence의 특정 단어와 얼마나 관련있는지 구한다.
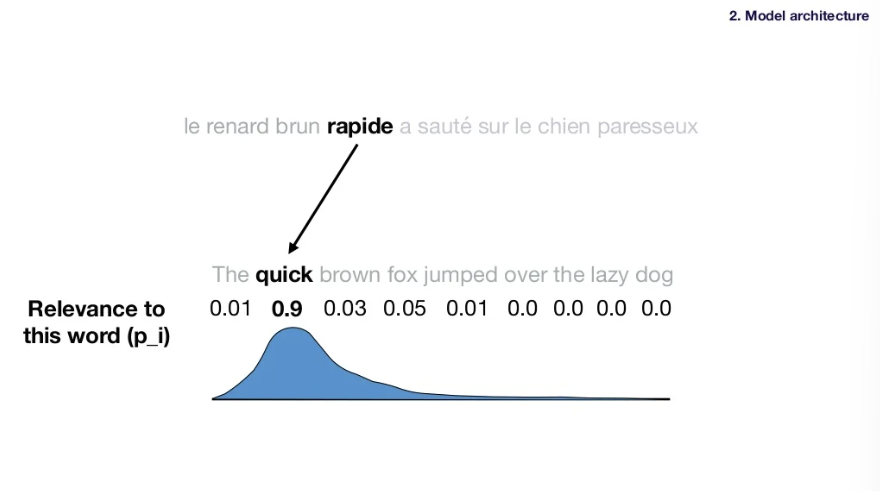
-
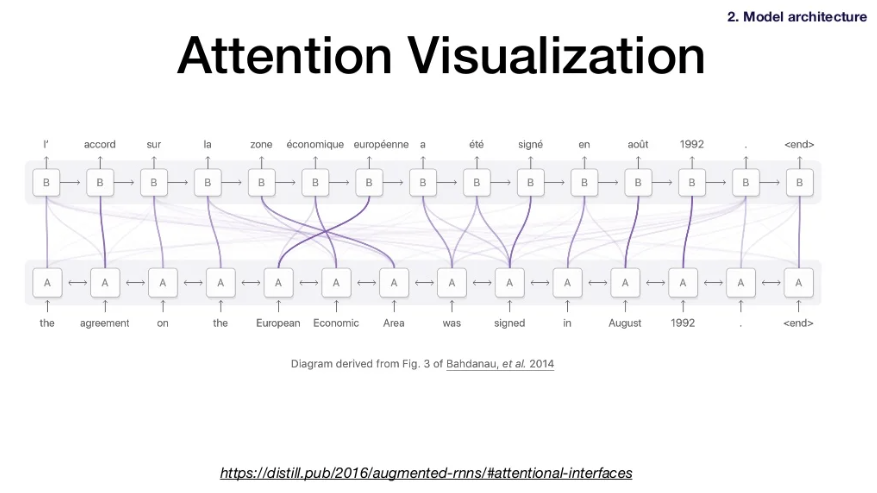
Attention은 번역 외에 다양한 분야에도 쓰인다. (음성인식이나 img model에도 쓰임)- Problem 4: LSTMs only consider backward context. 하지만 단어의 뜻은 문맥에 따라 달라지므로 문장 전체에 대해 이해하는 것이 단어의 올바른 뜻을 찾는데 효과적이다.
- Solution 4: Bidirectional LSTM -> Use one LSTM to process the sequence in forward order and the other in backward order. Then you concatenate those two outputs and pass it on to the next layer.
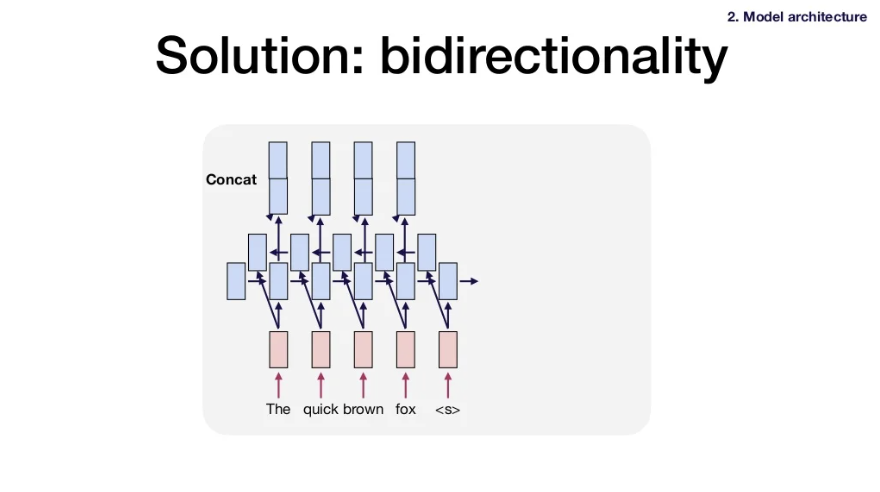
-
-
Summary of GNMT approach
- Stacked LSTM encoder-decoder architecture with residual connections
- Attention enables longer-term connections
- Bidirectional LSTM to encode future information
- Train using standard cross-entropy
- Speed up inference with quantization of weights
📌CTC loss
- Goal:

- Convnet window를 손글씨 이미지 위에서 sliding하면서 convnet output을 LSTM에서 이전 단계의 hidden state와 combine.

- Problem: What if an input is scaled differently? (window하나의 크기보다 알파벳 하나의 크기가 더 큰 경우. 같은 글자를 여러번 출력하는 오류 발생)
- Solution: 같은 알파벳이 연속되어 출력되면 같은 알파벳이라고 예상한다. -> Combine subsequent characters that have the same value
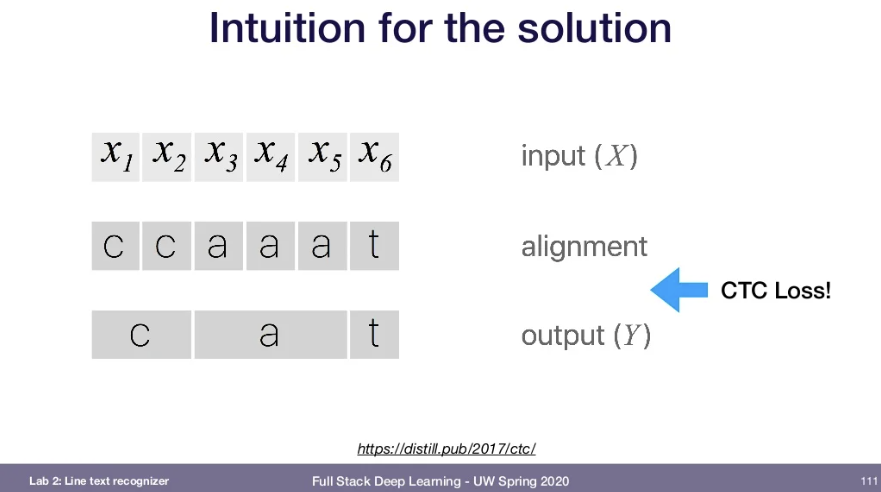
- 실제로 같은 알파벳이 여러번 존재하는 단어의 경우 어떻게 해결해야하는가?
- Add extra epsilon tokens -> 정해진 규칙에 따라 token들을 알파벳과 merge할지 결정. -> final output sentence
- 규칙:

📌Pros and Cons(of RNN architecture)
- Pros
- Encoder/decoder LSTM architectures are very flexible
(works for one-to-many, many-to-one, many-to-many sequence problems) - Has a history of many successes in NLP and other applications
- Encoder/decoder LSTM architectures are very flexible
- Cons
- Recurrent network training is not as parallelizable as FC or CNN, due to the need to go in sequence(이전 단계를 계산해야만 다음 단계가 진행되므로..)
- Therefore much slower!
- Can be finicky to train
📌A preview of non-recurrent sequence models
-
Sequence data does not require recurrent models!
-
Hence, convolutional approach can be used for sequence data modeling
-
WaveNet: A Generative Model for Raw Audio(van den Oord et al, 2016)
-
used in Google Assistant and Google Cloud Text to Speech(e.g., for call centers)
-
Main idea: convolutional sequence models
-
1) What problem are they trying to solve?

-
2) What model architecture was used?
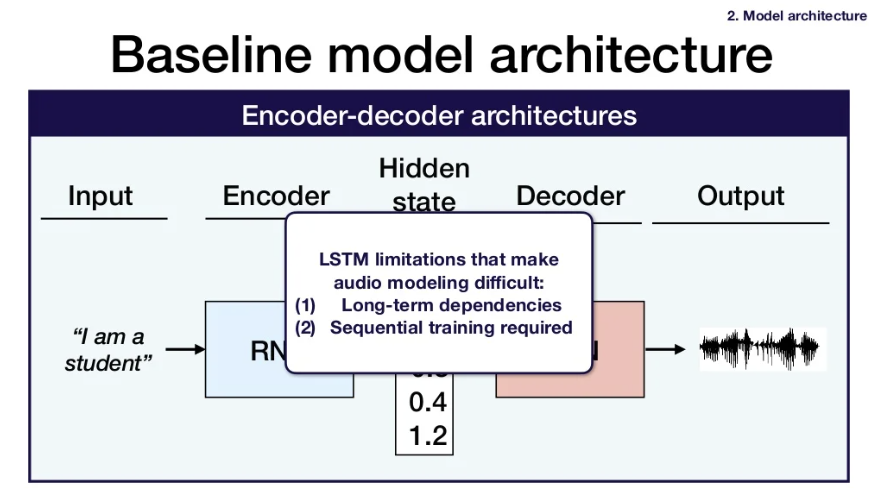
-
3) Insights of solution
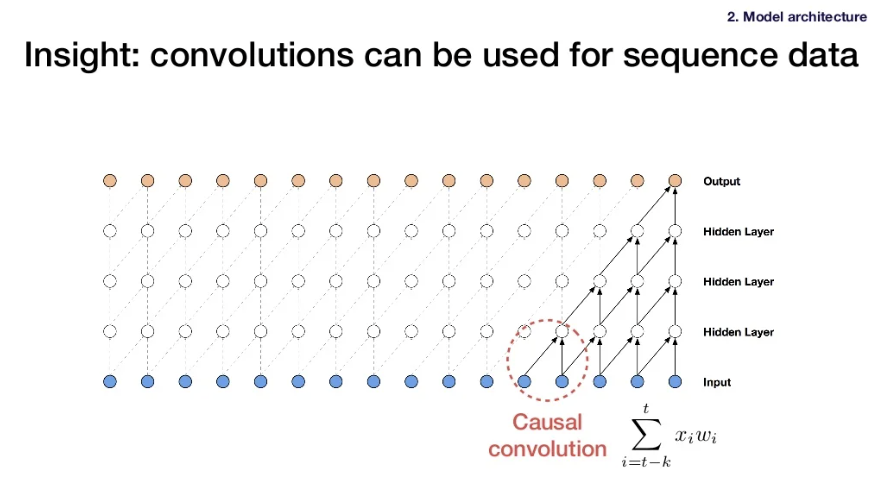
-
An output is produced by looking at the window of previous hidden layers, and those inputs from the previous hidden layer is produced from a window of inputs of the layer before that.
-
Causal convolution: the entire window is from the past. You don't look at any future data layers to get the output.
-
4) Challenge of the solution : getting a large receptive field
-
5) Solution of the challenge : dilated convolutions
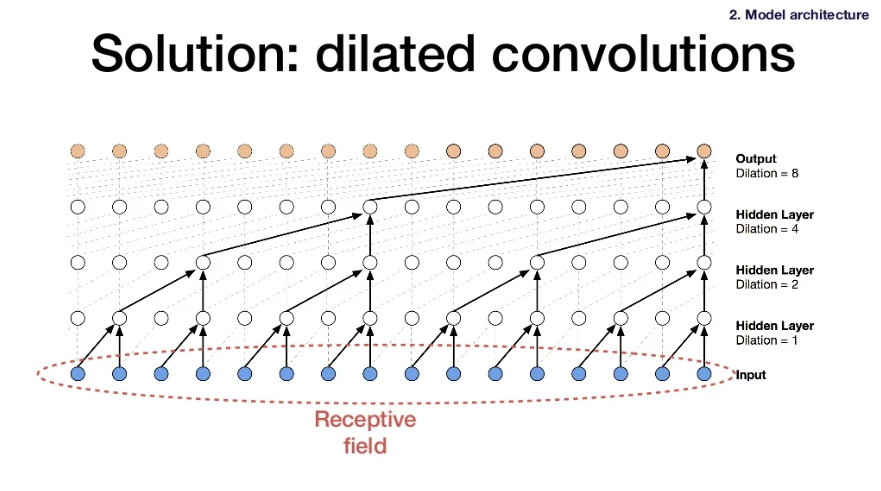
-
6) What model architecture was used?

-
7) What dataset was it trained on?
- Internal Google datasets (24.6 hours of speech in North American English, 34.8 hours of speech in Mandarin Chinese, ~16,000 samples per second)
-
8) How was it trained?
- 병렬처리가 가능해서 따로 train을 하는 trick이 필요하지 않음
-
9) What tricks were needed for inference in deployment?
- Training(parallel)은 쉬우나 inference(serial)는 복잡함.
-
💡READING