df.dropna()
- 빈 값(NaN)이 있는 행을 제거한다.
concat
- 데이터프레임을 붙인다. axis=0은 위아래로, axis=1은 옆으로
pd.concat([df, df_copy], sort=False, axis=0)
- 이렇게 했을 경우, index가 순서대로 안나오고 꼬이는 경우가 있다. 이럴땐, reset_index()로 index를 초기화 할 수 있다.
- df_concat.reset_index()
- 하지만, index라는 column이 새롭게 추가 된다.
- drop = True 옵션으로 새로운 index column이 생성되지 않도록 만들어 준다.
- df_concat.reset_index(drop=True)
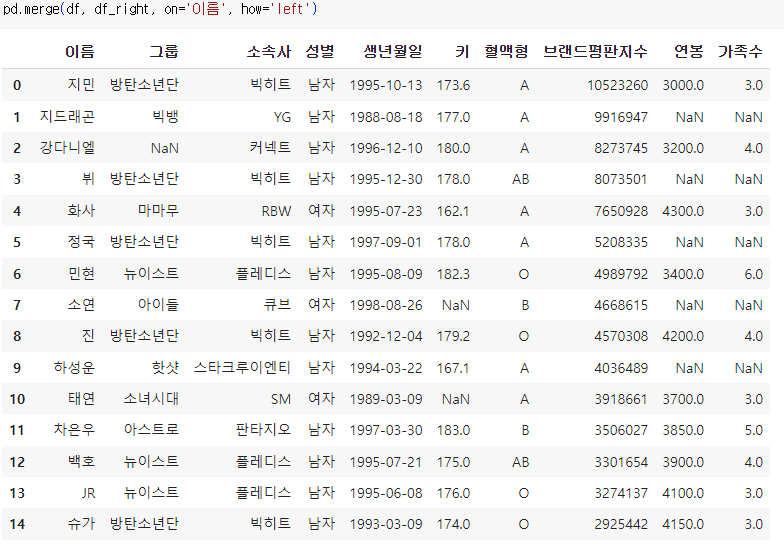
pd.merge(left, right, on='기준column', how='left')
- left와 right는 병합할 두 DataFrame을 대입합니다.
- on 에는 병합의 기준이 되는 column을 넣어 줍니다.
- how 에는 'left', 'right', 'inner', 'outer' 라는 4가지의 병합 방식중 한가지를 택합니다.
- 서로 정렬 순서가 다른 2개의 데이터프레임을 합칠때 merge()함수를 사용
- merge를 사용하면 오른쪽의 '이름' column은 삭제
- 'left' 옵션을 부여하면, left DataFrame에 키 값이 존재하면 해당 데이터를 유지하고, 병합한 right DataFrame의 값으 NaN이 대입이 됩니다.
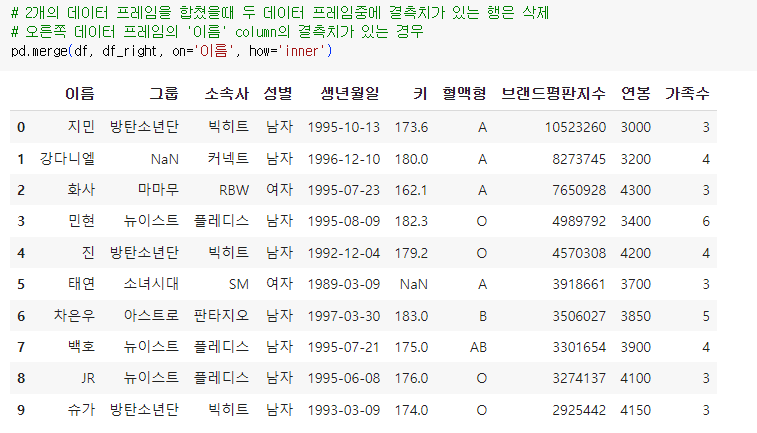
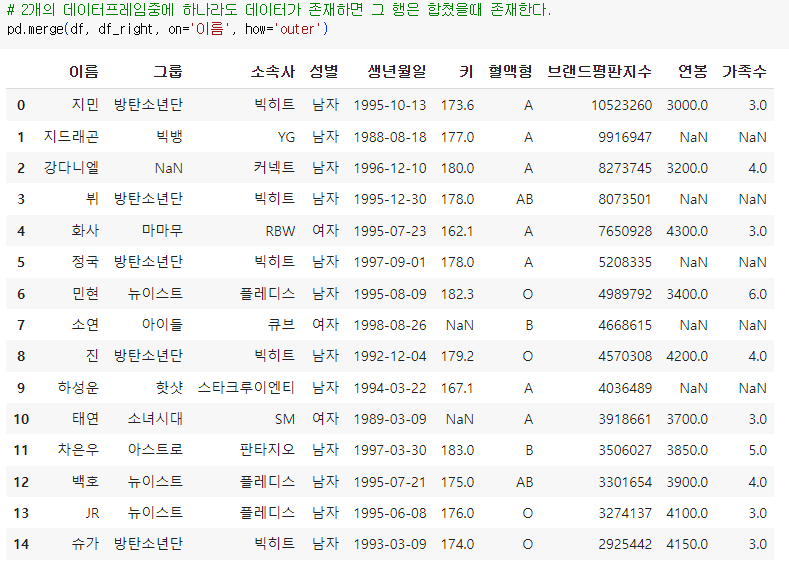
inner, outer
- inner 방식은 두 DataFrame에 모두 키 값이 존재하는 경우만 병합합니다.
- outer 방식은 하나의 DataFrame에 키 값이 존재하는 경우 모두 병합합니다.
- outer 방식에서는 없는 값은 NaN으로 대입됩니다.
- and(&&)조건으로 둘 중 모두가 존재할 때(하나라도 NaN값이 있으면 해당 행을 삭제)
- or(||)조건으로 둘 중 하나가 존재할 때

Hello!