지하철 자료를 분석해보자!
사용할 모듈을 import 한다.
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import os import numpy as np
활용할 데이터를 연결시켜준다.
- pandas로 csv 파일을 읽어오면 인덱스 열이 맨 첫번째 컬럼으로 들어간다. 하지만 read_csv를 할 때, index_col = False을 해주면 csv의 인덱스 컬럼을 제거할 수 있다.
csvPath = '/content/drive/MyDrive/.../CARD_SUBWAY_MONTH.csv' df = pd.read_csv(csvPath, index_col = False) df.head()
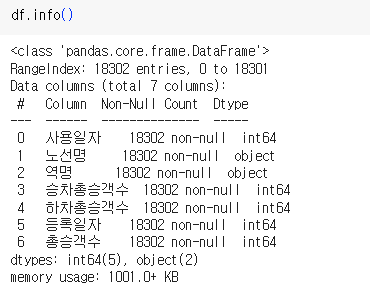
- RangeIndex : 18302를 보며 총 index갯수를 확인하고
비워져있는 값(결측치를 넣어야 할 값)이 있는지 확인한다.- DataType이 무엇인지 확인한다.
5호선만 데이터만 뽑아서 확인해본다.
line5 = df[df['노선명'] == '5호선']
'총승객수'컬럼을 만들어서 승객들을 확인한다.
df['총승객수'] = df['승차총승객수'] + df['하차총승객수']
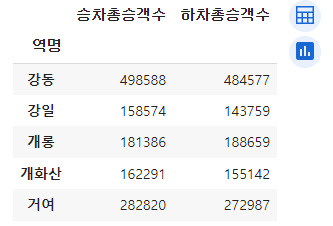
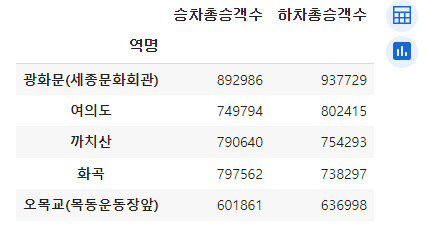
5호선의 승객수들 중 승하차수 Top5를 확인한다.
line5_station_total_df = line5.groupby(by='역명')[['승차총승객수', '하차총승객수']].sum()
# 5호선 승차 인원이 가장 많은 역 상위 5개 line5_top5_station_in = line5_station_total_df.sort_values(by='승차총승객수', ascending=False).head()# 5호선 하차 인원이 가장 많은 역 상위 5개 line5_top5_station_out = line5_station_total_df.sort_values(by='하차총승객수', ascending=False).head()

Hello!