Paper : 3D Gaussian Splatting for Real-Time Radiance Field Rendering (Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis / arxiv 2023)
Paper2 : A Survey on 3D Gaussian Splatting (Guikun Chen, Wenguan Wang / arxiv 2024)
Project Page : https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
3D scene representation 분야에서 NeRF의 성능을 뛰어넘는 새로운 방법인 Gaussian splatting이 제시되어 공부해보려 한다.
2분만에 이해하기 : https://www.youtube.com/watch?v=HVv_IQKlafQ
Gaussian splatting tool : https://www.jawset.com/
: 직접 찍은 사진과 영상으로 Gaussian splatting recon 해볼 수 있는 툴. 사용법이 매우 쉬우므로 instruction보면 쉽게 할 수 있음
Short Summary
-
3DGS는 explicit 3D scene representation 방법 (point cloud의 형태) -
각 3D 가우시안은 covariance matrix 와 center point 로 표현되며, 3D 상 어떤 위치 에 대해 아래와 같이 그 밀도를 표현
-
그래서 이 를 최적화해서 scene representation을 수행하는 것
-
Differentiable optimization을 위해 를 rotation matrix 과 scaling matrix 로 분리
-
정리하자면 각 3D Gaussian은 아래와 같은 값들을 가지고 있음.
- position
- SH 계수로 표현된 color
- opacity
- rotation factor
- scaling factor
-
Novel view rendering할 때에는
differentiable splatting활용. -
3D 공간의 가우시안을 camera coordinate로 가져와야하고, 그러면 2d gaussian의 covariance는 아래와 같이 계산됨. (: viewing transformation, : perspective projection → 원래 비선형인데 선형 가정)
⇒ 이미지 픽셀에 어떤 가우시안들이 영향을 주는지 계산하는 부분
-
3D gaussian들을 2d에 splat하면 여러 gaussian들이 하나의 pixel에 겹쳐지게 되는데, 이 개의 겹쳐진 point들에 대한 blending은 아래와 같이 수행한다.
⇒ 이미지 픽셀의 실제 색이 어떠해야 하는지 계산하는 부분
-
여기서 랑 는 3D gaussian 에 따라서 구해지는 값 → 가우시안 중심일수록 그 3d gaussian의 특성을 그대로 따라가고 외각일수록 덜 따라가도록 계산
-
그러니까 더 정확하게는
Highlights
- 3D gaussian을 사용하여 3D scene을 represent
- 기존의 NeRF 기반 방법들보다 더 좋은 성능을 보여주며, 특히 rendering speed가 real-time으로 수행될 수 있을만큼 빠르다.
Introduction
Rasterization vs. Ray-marching
읽어볼만한 https://blogs.nvidia.com/blog/whats-difference-between-ray-tracing-rasterization/
기존의 3D data representation 방법들은 mesh나 point를 주로 이용하였는데, 이는 3D 공간을 explicit하게 표현하는 것으로, GPU/CUDA 기반의 빠른 rasterization (=3D object 형태를 2D pixel grid로 변환)에 잘 맞기 때문에 활발하게 연구되었다.
What is ..
기본적으로, 3d rendering은 아래 두 단계로 나누어 생각해볼 수 있다.
(1) 3차원 공간 표현 -> CPU의 역할
- 기존 방식은 3D 공간에 물체를 triangle이나 polygon의 mesh로 근사해서 표현한다. (각 triangle/polygon mesh는 corner (=vertices)로 이루어져 있음)
- 각 vertex에 3D 공간에서 position, color, texture와 normal vector 등의 정보가 저장되어있다.
- 이 단계는 우리가 직접 눈으로 보는게 아니고, 단지 3d 공간에 저장된 데이터일 뿐.
(2) 시각화 과정 (랜더링) -> GPU의 역할
- 임의의 카메라 시점 (내가 보고자 하는)을 정의한다.
- Projection : 3D 좌표계를 2D 화면 좌표계로 변환하여 각 mesh들을 projection해준다. (아직 픽셀값이 아님!)
- Rasterize : 화면 위로 projection된 mesh 영역을 픽셀 단위로 쪼개준다. 각 픽셀이 해당 삼각형 안에 들어왔는지를 검사하고, 깊이를 고려하여 표시할 색상 후보 데이터를 만든다.
- Shading : 광원의 방향, 재질 속성, 등을 고려해서 해당 픽셀의 최종 색을 계산한다.
이렇게 하면 우리가 2D computer screen으로 볼 수 있게 되는 것
많은 연구들은, 이 공간 표현 방식과 시각화 방식을 발전시키려고 하는 것이고.
Rasterization 기반 방법들은 각 point들을 최대한 한꺼번에 작업하려고 하기 때문에 속도가 빠르다는 장점이 있다. 반면에 이 픽셀끼리 독립적으로 연산이 수행되므로 투명한 물체의 표현이나 겹친 부분 등을 표현할 수 없다.
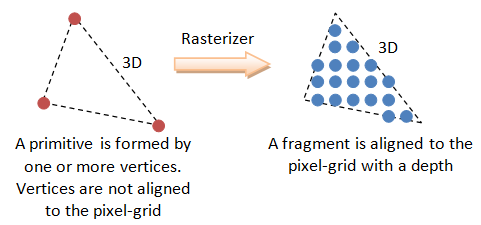
그림 출처: https://blog.naver.com/skkim12345/221351312903
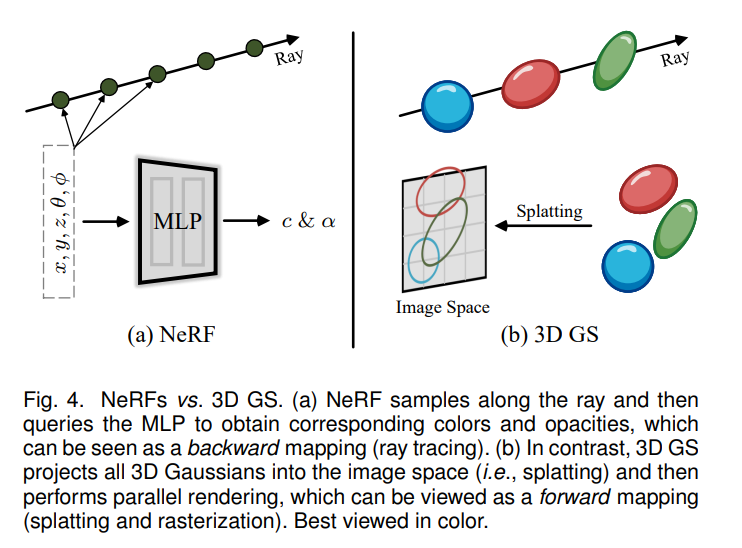
반면에 NeRF는 3D scene을 continuous scene으로 표현하였으며, volumetric ray-marching을 활용하여 MLP를 학습함으로써 3D 공간을 implicit하게 표현한다.
NeRF는 기본적으로 physics 기반의 방법으로, 현실에서 물체에 비친 ray를 통해 눈에 상이 맺히는 과정을 묘사하여 3D scene을 최적화한다. 특히 continuous representation의 가정은 이러한 optimization에 큰 도움이 된다.
가장 최신의 NeRF 모델들은 이러한 continuous representation을 위해, voxel grid (Plenoxels)나 hash grid (InstantNGP) 혹은 point 내에서 정의된 feature들을 interpolation하는 방식을 사용하곤 한다.
하지만 NeRF는 rendering시 각 ray마다 3D point를 stochastic하게 sampling하는 과정이 매번 필요해서 training 및 rendering time cost가 크며 noise도 생기기가 쉽다.
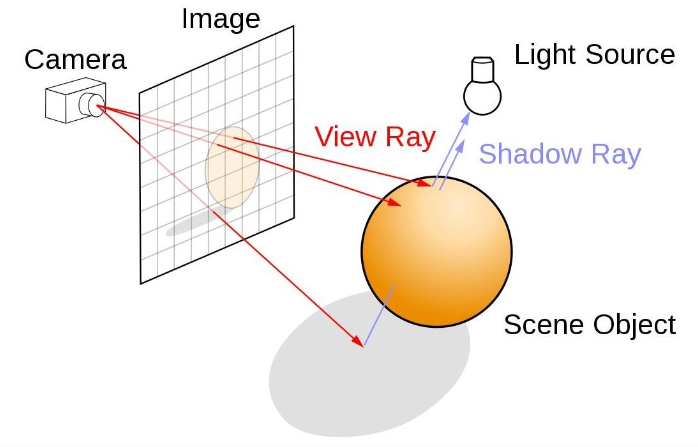
그림출처 https://developer.nvidia.com/discover/ray-tracing
Plenoxel이나 InstantNGP와 같은 최근 NeRF 모델들은 빠른 학습이 가능했지만 SOTA의 성능을 보여주지는 못했으며, MipNeRF360과 같은 SOTA 모델들은 학습속도가 매우 느렸다.
특히 real-time으로 scene을 고화질로 rendering할 수 있는 방법론은 아직 없었다.
3D gaussian representation
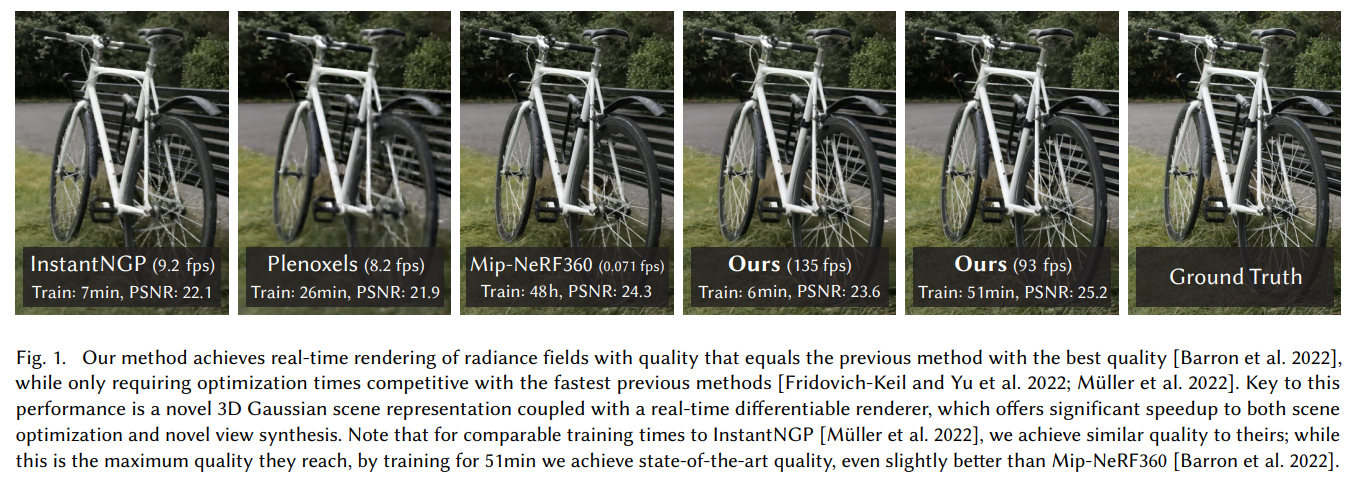
저자들은 위의 Rasterization과 Ray-Marching의 장점을 모두 가지는 3D gaussian 기반의 모델을 제안한다.
3D gaussian representation를 통해 SOTA visual quality와 reduced training time을 달성할 수 있었고, Tile-based splatting solution을 통해 고화질에서 real-time rendering을 수행할 수 있었다고 한다.
이 논문의 방법론은 3가지 main component로 구성된다.
-
3D gaussian을 통한 scene representation
- SfM process에서 추출된 point cloud를 초기 initial set으로 활용
- 3D gaussian은 differentiable volumetric representation이 가능
- -blending을 통해 NeRF와 비슷한 image formation model을 활용하여 3D to 2D projection을 효율적으로 수행 가능
-
3D gaussian properties의 최적화
- 이 방법에서 최적화는 3D gaussian의 3D position, opacity , anisotropic covariance (gaussian의 shape와 spread), spherical harmonic coefficient (lightening과 shading)에 대한 최적화를 포함
- 위의 특성들을 최적화할때, adaptive density control을 사용하여 gaussian을 추가하거나 제거하는 과정을 거치는데, 이를 통해 compact하고 precise한 representation을 수행 가능
-
Real-time rendering
- GPU sorting algorithm과 tile-based rasterization을 활용
- Tile-based rasterization은 이미지를 몇 개의 tile block으로 나누어 각 tile을 독립적으로 rendering하여 속도가 빠름
- 3D gaussian representation의 특성 덕분에 각 splat (=gaussian)이 어떤 방향성을 가지게 되는데 (anisotropic splatting), 이러한 3D gaussian들의 shape와 orientation이 2D screen으로 projection될 때 반영되기 때문에, 더욱 현실적인 표현이 가능해지고, fast/accurate backward pass가 가능
Overview
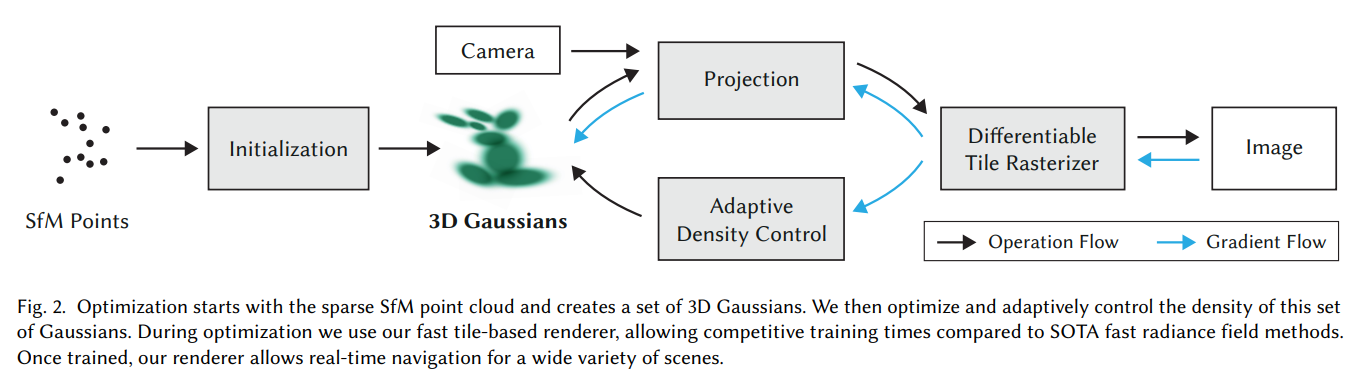
Gaussian Splatting 방법의 input은 static scene의 image set과 SfM의 byproduct로써 얻어진 point cloud이다. SfM 간단히 설명한 글
그리고 이 point로부터 3D Gaussian을 정의하는데, 이는 아래와 같이 구성된다.
- Position (mean): 3D space에서 gaussian의 center point를 의미
- Covariance matrix: Gaussian의 spread를 의미하며, shape을 결정
- Opacity : Gaussian의 투명도를 결정
이때 각 gaussian의 directional appearance (color)는 spherical harmonics (SH)를 통해 표현된다.
Spherical harmonics ?
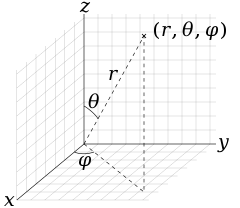
https://en.wikipedia.org/wiki/Spherical_coordinate_system
https://en.wikipedia.org/wiki/Table_of_spherical_harmonics#Visualization_of_complex_spherical_harmonics
Spherical harmonics는 원래 양자역학에서 주로 사용되는 방법이고, Computer graphics 분야에서는 directional appearance (color) 값을 계산할 때 자주 사용되는 방법이다.
이는 구면 좌표계에서 laplace equation의 해를 표현하는 방법으로, 구의 표면에서 polar angle 와 azimuthal angle 로 정의되는 함수이다.
조금 더 부연 설명을 하자면, Laplace equation 는 spherical coordinate에서 아래와 같이 정의되는데,
이에 대한 solution이 spherical harmonics로 표현될 수 있다. 즉, spherical harmonics ()가 solution의 basis역할을 수행하게 된다. 이때, 은 degree, 은 order로, 를 만족한다.
이때 이 spherical harmonics를 서로 다른 degree에 대해서 visualize하면 아래와 그림과 같다. 구의 표면에 다양한 intensity와 direction을 가지는 pattern으로 표현된다.

fourier series representation과 마찬가지로, spherical harmonics는 서로 orthogonal하며, 구의 표면에서 정의된 어떤 함수도 unique하게 표현할 수 있다. (-> light distribution의 복잡한 shape과 pattern을 finite term으로 쉽게 표현할 수 있다)
이러한 이유로 최근에는 많은 연구가 이러한 개념을 사용하여 서로 다른 각도에서 light interaction을 고려한 color를 표현하고 있으며, 이번 논문도 이 개념을 차용한다.
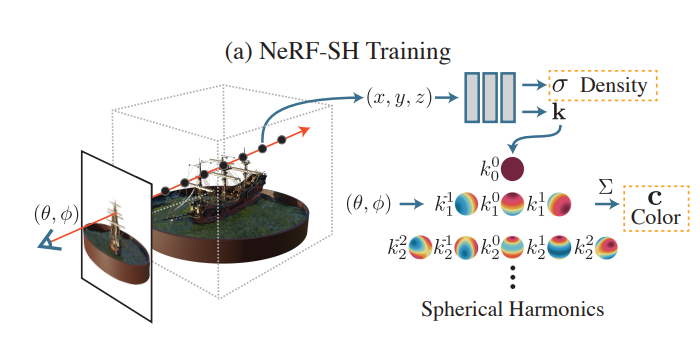
그림 출처: PlenOctrees for Real-time Rendering of Neural Radiance Fields
최종적으로 3D gaussian 알고리즘은 이렇게 정의된 3D gaussian parameter (position / covariance / / SH coefficient)를 optimize하게 된다.
Differentible 3D Gaussian Splatting
본 논문의 저자들은 미분 가능하고, 쉽게 2D projection이 가능한 3D gaussian을 선택하여 blending을 이용한 빠른 rendering을 가능하게 하였다.
또한, 이전의 방법들이 어떤 planar circle과 normal vector로 2D point를 모델링한 것과 다르게 3D gaussian은 normal vector를 필요로 하지 않기 때문에, sparse한 SfM point로부터 어려운 task인 normal estimation을 하지 않아도 된다.
3D Gaussian Define
각 3D gaussian은 world space에서 covariance matrix 로 정의되며, mean 를 center point로 갖는다.
이 gaussian은 blending 과정에서 가 곱해진다.
Rendering을 위해서는 이 3D gaussian을 2D로 projection 시켜야하는데, 아래와 같이 viewing transformation 를 통해 camera coordinate에서 2D covariance matrix 를 얻게 된다.
이때, 는 projective transformation의 affine approximation의 Jacobian 행렬이다.
Optimization Challenge and Strategy
이제 를 optimize하면 radiance field를 recon할 수 있게 된다. 하지만 covariance는 positive semi-definite한 행렬일 경우에만 물리적인 의미를 갖기 때문에, 직접적으로 gradient descent방식으로 학습하는 것은 매우 어렵다.
이러한 문제를 해결하기 위해 저자들은 이 covariance matrix의 표현을 바꿔주는 방식을 택했는데,
scaling과 rotation을 독립적으로 optimization하여 covariance matrix가 유효하도록 만들어 주었다. 이때 scaling factor는 3D vector 로 저장되고, rotation은 quaternion 로 표현되어 저장된다.
이렇게 Gaussian splatting 방법은 anisotropic covariance를 통해 scene을 표현하는데, 각 gaussian이 uniform한 구형이 아니고 서로 다른 spread와 direction을 가지고 있으므로 더욱 복잡한 geomery를 정확하게 표현할 수 있게 된다.

위의 그림에서 가장 오른쪽 shrunken gaussians는 각 gaussian의 크기를 줄여서 overlap 없이 보여준 것으로, 각 gaussian이 서로 다른 shape과 orientation을 가지도록 최적화 됬다는 것을 보여주고 있다.
Optimization with Adaptive Density Control of 3D Gaussians
저자들은 optimization step이 이 방법의 core라고 한다.
최적화하려는 parameter로는 gaussian의 position , , , 그리고 각 gaussian의 color를 표현하는 SH 계수가 있다.
이러한 parameter들의 최적화 과정에서 gaussian의 density control 과정이 포함되며, 이는 scene을 더욱 효율적으로 잘 표현할 수 있도록 도와준다.
Optimization

위 algorithm은 Gaussian Splitting optimization의 전체 과정을 보여주고 있다.
Optimization은 rendering & comparing의 iteration으로 이루어지며, rendered image를 training dataset의 captured view와 비교하여 이를 기반으로 학습이 된다.
먼저 SfM point로부터 3D gaussian을 만들고, 초기 covariance matrix를 가까운 세 점으로부터 평균 거리 값으로 초기화한다.
Loss는 아래와 같이 정의하여, render image와 GT를 비교한다.
하지만 3D geometry의 2D projection의 모호함 때문에, geometry가 잘못 위치한 경우 이 geometry를 파괴하거나 움직일 수도 있어야 하는데, 이 부분이 Adaptive Control of Gaussian이다.
Adaptive Control of Gaussians
처음 sparse SfM point set로부터 시작해서 더욱 정확한 parameter을 가지는 denser set을 통해 더 scene을 잘 표현하기 위해, Gaussian의 갯수와 unit volume 당 density를 조정한다. (여기서 density는 NeRF에서의 density와는 다른 것)
Warmup phase가 끝나면 매 100 iteration마다 gaussian의 분포를 densify한다.
- Pruning
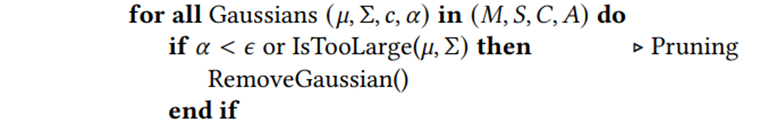
먼저 scene에 대한 기여도가 적은 gaussian들을 없앤다. (여기서 기여도라 함은 특정 threshold보다 가 작은 경우)
- Densification

Transparent gaussian에 대한 removal 후에는 improvement가 필요한 영역을 찾아서 gaussian을 split/clone 시켜준다.
이러한 영역들은 Geometric feature를 파악하지 못한 "under-reconstruction" 영역과 scene의 큰 영역을 cover하는 "over-reconstruction" 영역으로 볼 수 있는데, 이 영역들은 둘 다 position에 대해서 큰 gradient를 가지기 때문에, 이 값이 특정 threshold보다 높으면 처리해준다.
저자들은 이러한 영역이 position에 대해 큰 gradient를 가지는 이유는 이러한 영역은 아직 잘 reconstruction이 되지 않은 영역이라서 optimization이 이를 해결하기 위해 gaussian을 옮기려고 하기 때문일 것이라고 했다.
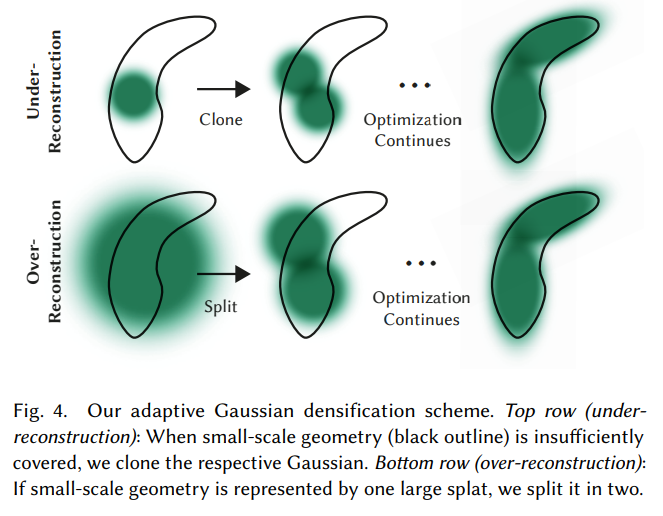
위 그림은 densification process를 보여주고 있다.
-
Clone Gaussian
- under-reconstructed region에서 작은 gaussian들에 대해서는 새로운 gaussian을 만들어서 geometry를 cover해주어야 한다.
- 이를 위해서 gaussian들을 clone하는 방식을 사용하였는데, 간단하게 같은 크기의 gaussian을 복사하고 positional gradient의 방향으로 그 gaussian을 옮겨주었다.
-
Split Gaussian
- over-reconstructed region에서 높은 variance를 갖는 큰 gaussian에 대해서는 그 gaussian을 split해주었다.
- 이를 위해서 해당 gaussian을 더 작은 gaussian 두 개로 나누고, 위치는 원래의 gaussian의 PDF에 따라 초기화된다.
Clone의 경우 system의 총 volume과 gaussian의 갯수가 둘 다 증가하는 반면, split은 총 volume은 유지한 체 gaussian의 갯수만 늘어난다. Optimization이 진행되면서 camera와 가까운 영역에 floater로 인해 gaussian의 갯수가 계속해서 늘어나게 된다.
이러한 현상을 막기 위해서 매 3000 iteration마다 를 0에 가까운 값으로 초기화해준다. 이렇게 하면 다음 100 iteration 후 pruning을 통해 필요없는 gaussian들을 다시 제거할 수 있으며, 너무 큰 gaussian들이 중첩되는 경우도 잘 제거해줌으로써 전체 gaussian의 갯수를 잘 조절할 수 있게 된다.
Fast Differentible Rasterizer For Gaussians

위 알고리즘은 Rasterization 과정을 보여준다.
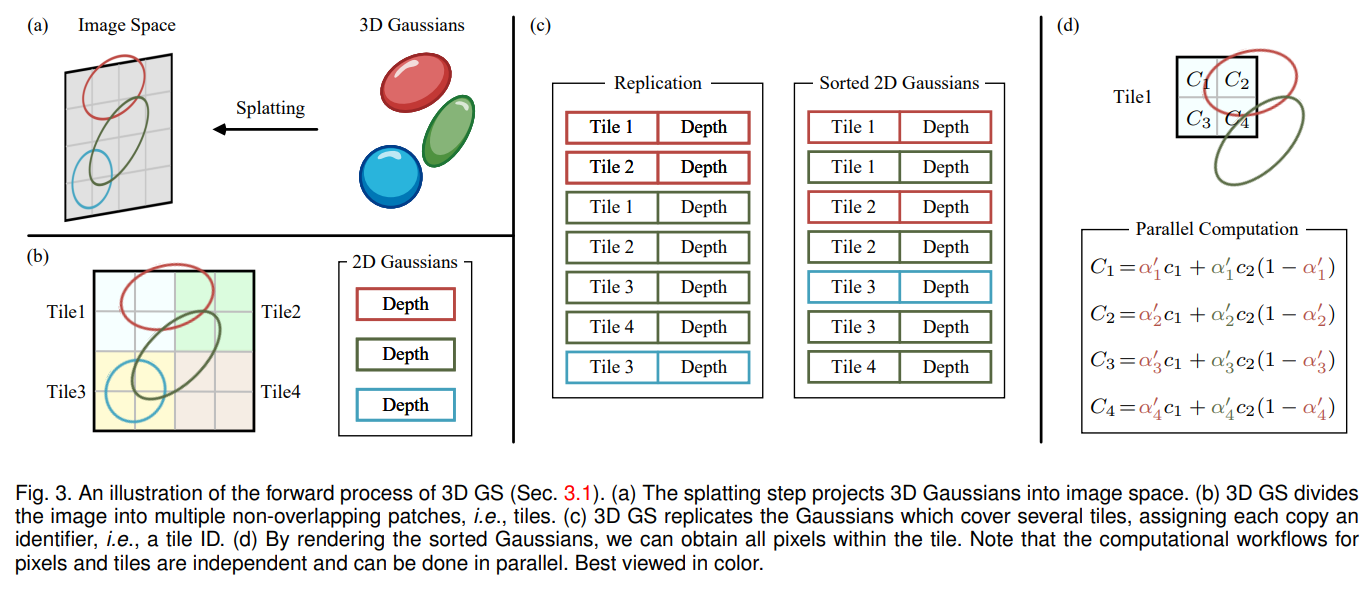
그리고 위는 이를 잘 도식화한 그림이다. 이를 그림을 바탕으로 좀 이해해보자.
빠른 rendering과 -blending을 가능케하는 sorting을 수행하기 위해서 저자들은 tile-based rasterizer를 제안하였다.
- Splatting (그림 (a) 참고)
Gaussian을 screen으로 splat한다. 여기서 "splat"이라 함은 3D 공간에 있는 gaussian을 2D screen으로 흩뿌려서 rasterize한다고 생각하면 될 듯 하다. 그리고 이 process는 기본적으로 NeRF에서 ray를 따라 point를 sampling하는 방법되는 다르다.
- Frustum Culling
- view frustum안에 들어오는 gaussian만을 남기고 나머지는 사용하지 않음
- 추가적으로 카메라와 너무 가까이 있거나 멀리 있는 gaussian을 제거
- Create Tiles (그림 (b) 참고)
- Screen (image space)을 16x16 tile로 나눔
- 이는 scene의 특정 부분들을 독립적으로 처리하여 한 이미지를 한번에 처리하는 것보다 빠르게 처리할 수 있도록 해줌
- 하나의 gaussian은 여러 tile에 속할 수 있음
- Key-based Sorting with Radix Sort (그림 (c) 참고)
- 각각의 gaussian들은 depth와 tile ID을 기반으로 하는 key를 부여받음
- 특히, 여러 tile에 속한 gaussian은 그 갯수만큼 복제
- GPU Radix Sort 방법을 이용해 sorting
- 각 tile마다 depth별로 sorting된 gaussian들의 list를 얻음
- Alpha Blending (그림 (d) 참고)
- Sorted gaussian list ()의 color와 alpha를 accumulate하여 pixel값을 계산 (front-to-back)
- 이 pixel의 최종 값은 아래와 같이 계산
- 이때 는 학습된 color이며, 최종 opacity 는 학습된 opacity 와 gaussian의 곱으로 표현 (projected space에서의 gaussian)
- Alpha blending의 경우 값이 1로 saturation되면 마무리 한다. 즉, 2D screen에서 color를 계산할 때, gaussian list에서 가까운 순서대로 계속 들어올텐데, 어느 순간부터는 새로운 gaussian이 들어오더라도 픽셀 값이 변하지 않을 때가 있는데, 이 때가 accumulated transparency ()가 0이 될 때이고, 그러면
여기서 중요한 점은 Rasterization을 수행할 때, 각 tile에 thread에 launching 되며, 이 thread들이 공유 메모리 상에 있는 gaussian에 접근하여 병렬적으로 연산하므로 연산 속도가 매우 빠르고 효율적이다.
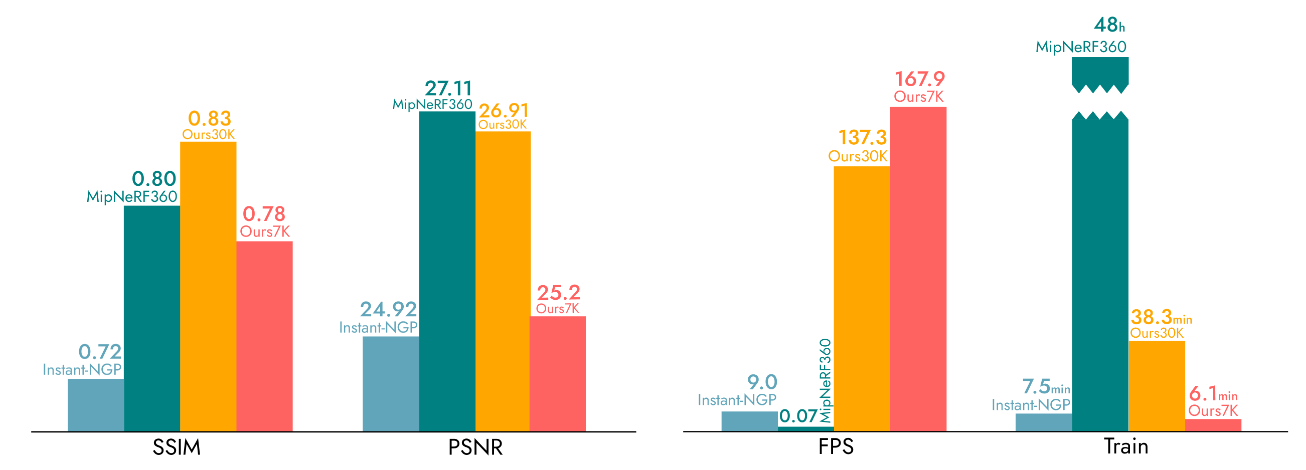
Results
Implementation과 result는 자세히 다루지 않는 것으로 한다.
paper와 project page에 다양한 영상 예시가 있으니 참고하는 것으로..
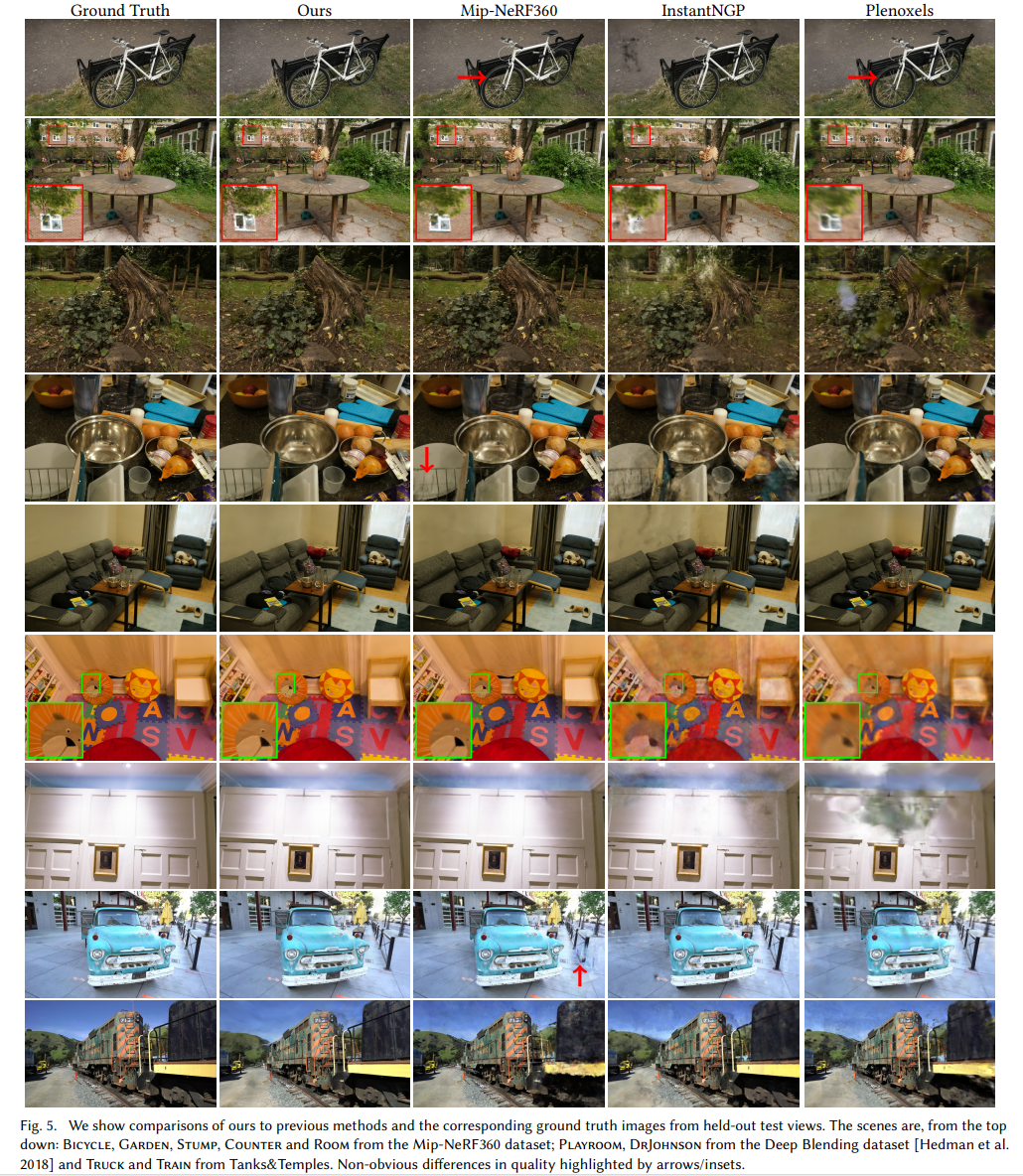
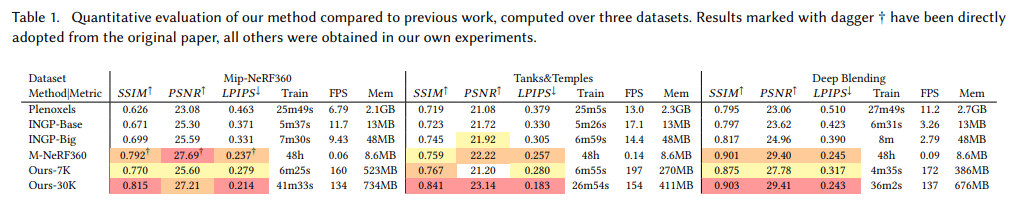
기존의 SOTA 모델들에 비해서 성능이 매우 뛰어나다.
특히 FPS는 비교가 안될 정도로 대단하다.
Discussion
Radiance Field Rendering 분야에서 또 하나의 게임체인저가 나온 것 같다. 고화질 영상을 100 FPS가 넘는 속도로 rendering한다는 게 참 대단하다고 느껴졌다.
Computer graphics 분야에 배경지식이 많지 않아 이해하는데 어려움도 있었다. Rasterization이나 Spherical harmonics의 개념을 공부해볼 수 있어서 좋았다. (InstantNGP에서도 사용된 개념이였는데 그것도 잘 모르고 논문을 읽었었다..) NeRF로부터 처음 이 분야를 접해서, 기본적인 내용을 잘 이해하지 못하는 것도 많다는 것을 실감했다. 기존의 Rendering 방법론들에 대한 공부가 훨씬 더 많이 필요할 것으로 보인다.
3D Gaussian Splatting은 엄청나게 떠오르는 방법론이다. 발표된지 1년도 넘지 않은 상황에서 관련 연구들이 쏟아져 나오고 있다.
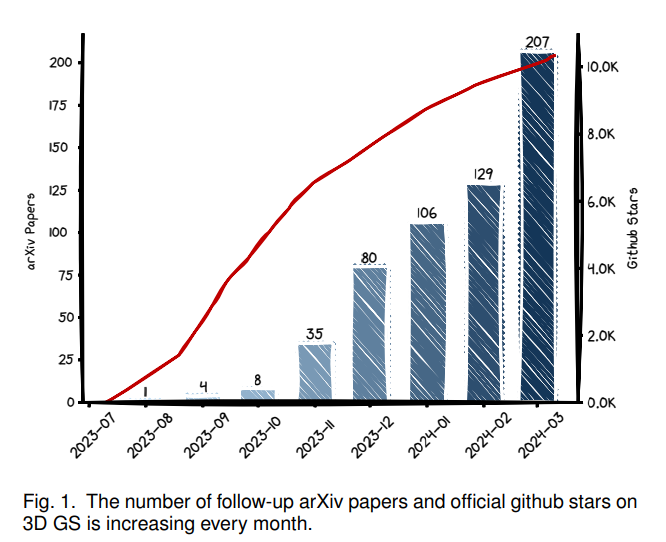
아직은 더 발전시킬 여지가 많아보이긴 하다. 이 분야에서 기본적으로 풀고자하는 sparse view에 대해서도 많은 연구가 진행될 것으로 보이고, 더 빠른 속도로 정확한 rendering을 수행하는 연구들이 차차 나올 것으로 기대된다.
바로 이어서 4D gaussian splatting 연구들도 진행되고 있다. Dynamic scene을 real-time으로 rendering하는 것이다. 옛날부터 상상했던 것들인데, 이제는 현실이 되고 있다.
