Paper : TCTrack: Temporal Contexts for Aerial Tracking (Ziang Cao, Ziyuan Huang, Liang Pan, Shiwei Zhang, Ziwei Liu, Changhong Fu / CVPR 2022)
Highlights
- 연속되는 frame에 대한 temporal context를 고려한 Visual tracker 제시
- Feature extraction에서 활용되는
online temporal adaptive convolution은 이전 frame의 정보를 통해 convolution weight를 매번 조정하여, 이전 프레임의 정보를 활용해 현재 프레임을 강화 - Similarity Map Refinement에서 활용되는
adaptive temporal transformer는 이전 프레임에서 temporal knowledge를 효율적으로 encoding하여, target object와 현재 frame이 얼마나 matching되는지를 나타내는 similarity map을 refine
** Temporal Context
- Visual tracking에서
Temporal Context란 시간에 따른 frame으로부터 추출되는 정보나 관계를 의미 → 연속되는 frame에서의 변화나 패턴을 활용하여 tracking 정확도 및 robustness를 향상시키기 위함 → 여기서 변화나 패턴이라 함은 아래의 내용들을 의미- Motion patterns : 하나의 frame에서 다음 frame으로 object가 어떻게 움직이는지 이해하는 것
- Appearance changes : 시간에 따른 light condition이나 occlusion의 변화를 이해하는 것
- Spatial-Temporal relationships : frame 내에서 object와 주변 환경 사이의 관계를 이해하는 것
Introduction
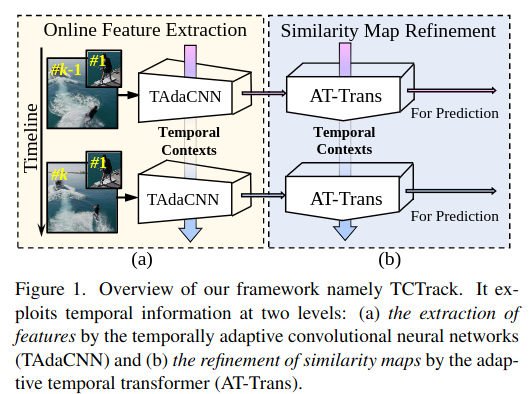
Temporal Contexts for Aerial Tracking
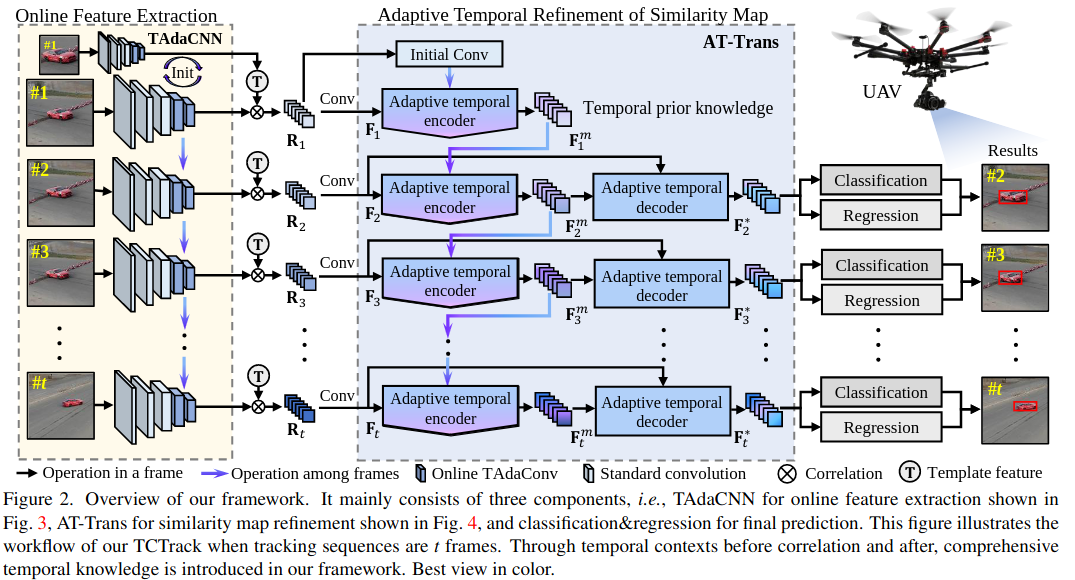
Feature extraction with online TAdaConv
TAdaConv (Temporal adaptive convolution)에서는 temporal context를 고려하여 feature를 추출한다.
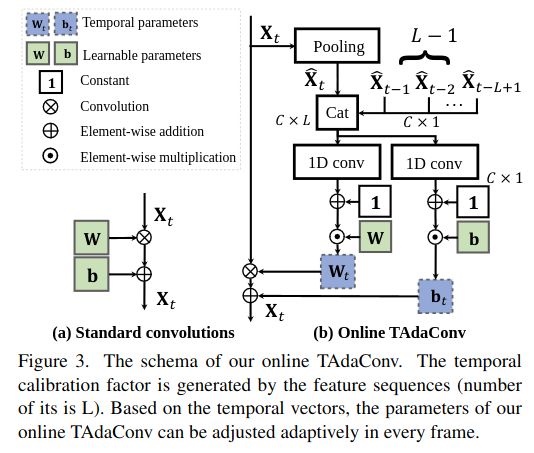
- 기본적으로, 번째 frame의 input feature 가 주어졌을 때,
TAdaConv의 output은 아래와 같다.
- 여기서 , 는 temporal weight와 bias인데,
standard conv가 학습된 파라미터를 모든 tracking sequence에 똑같이 적용하는 것과 다르게,online conv layer에서는 학습된 파라미터 ()와 각 frame마다 다른 calibration factor를 이용하여 파라미터를 재계산한다.
- 이때, 현재 frame을 포함해 개의 이전 frame descriptor 를 포함하는
temporal context queue를 계속해서 keep하며, 이를 통해 past time의 temporal context를 고려 - 각 frame descriptor는 각 frame의 feature를 GAP하여 얻어짐
Calibration factor를 생성하기 위해서 temporal context queue 에 두 번의 conv ()를 적용- Temporal context queue가 이전 frame이 충분하지 않은 (i.e., )에서는 첫번째 frame descriptor로 채워넣음 (실험에서는 사용)
- 이렇게, feature extraction process에서 temporal context를 고려한 backbone 가 주어졌을 때, 번째 frame에 대한
similarity map를 구할 수 있다.
- 여기서 는 template (template은 우리가 track하고자 하는 물체를 의미하는 것 같음 overview figure에서 확인 )을 의미하고, 연산은 depth-wise correlation을 의미
- 이후 한번 더 conv layer를 거쳐 를 얻을 수 있다.
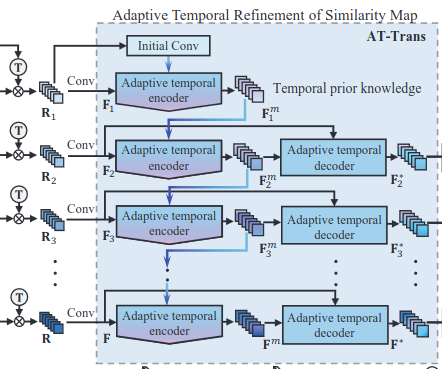
Similarity Refinement with AT-Trans
AT-Trans는 temporal context를 고려하여 feature extraction process에서 얻어진 similarity map을 refinement
AT-Trans는 encoder-decoder 구조- Encoder는 temporal knowledge를 결합하는 데 집중하고, Decoder는 similarity를 refine하는데 집중
Multi-head attention revisited
-
d는 scale factor
-
-
N은 head 수 (AT-Trans에서는 6)
-
-
Transformer는 CNN에 비해서 global context 정보를 더욱 효율적으로 encoding할 수 있음
-
특히 AT-Trans에서는 temporal knowledge의 online update strategy를 사용하여 불필요한 연산을 제거
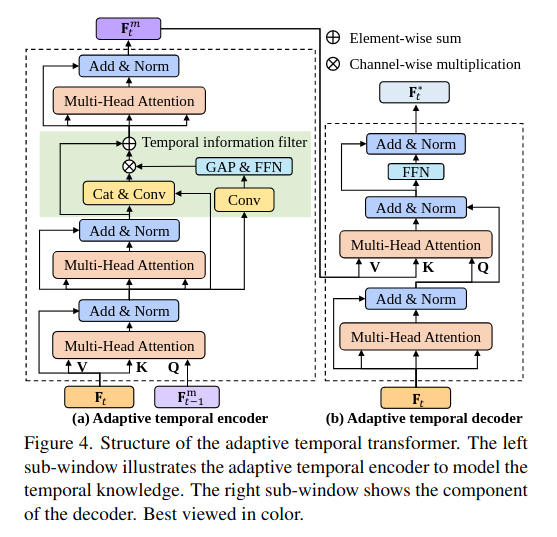
Transformer Encoder
-
AT-Trans의 encoder는
current similarity map와이전 knowledge를 결합하여temporal prior knowledge를 생성 -
두 번의
MHA,Temporal information filter, 그리고 한번의MHA를 더 거쳐서 생성 -
temporal prior knowledge을 query로,current similarity map를 value로 사용해 attention block에 대입→
current similarity map에 더욱 중요도를 부여한다고 함
-
즉, 번째 frame의
stacked MHA layeroutput 는 아래와 같이 구해진다.
- 다음으로, aerial tracking은 motion blur나 occlusion때문에 덜 중요한 정보들이 포함되는 경우가 많으므로, 이러한 정보를 filtering해주기 위해
feed-forward network를 활용한다.
- 마지막으로
MHA를 한번 더 적용해서 번째 frame의temporal knowledge를 구할 수 있다.
-
이렇게하면, temporal knowledge를 모두 저장하지 않고, 각 frame마다 매번 update할 수 있고, memory를 절약할 수 있다.
-
추가적으로, tracking sequence의 첫번째 frame의 similarity map은 target object의 semantic feature에 대한 정보를 잘 담고 있을 것이라는 가정 하에,
initial temporal prior는initial similarity map에 conv를 적용하여 구한다.
Transformer Decoder
-
Decoder는 temporal prior knowledge를 가지고, similarity map을 정제한다.
-
현재 spatial feature 와 prior knowledge 의 interrelation을 고려하기 위해서 2개의
MHA와FFN을 활용 -
Attention을 통해 prior knowledge에서 유용한 정보만을 추출해서 similarity map을 정제할 수 있음
-
그러면 최종 output은 아래와 같이 구할 수 있다
- AT-Trans의 encoder-decoder 구조는 temporal context가 더욱 효율적으로 활용될 수 있도록하여 similarity map을 더 robust하고 accurate하게 만들어 준다.
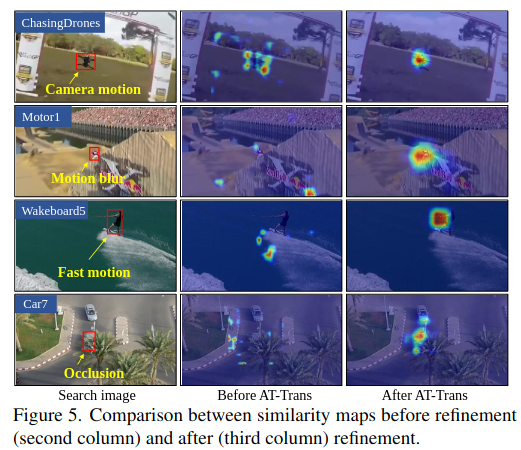
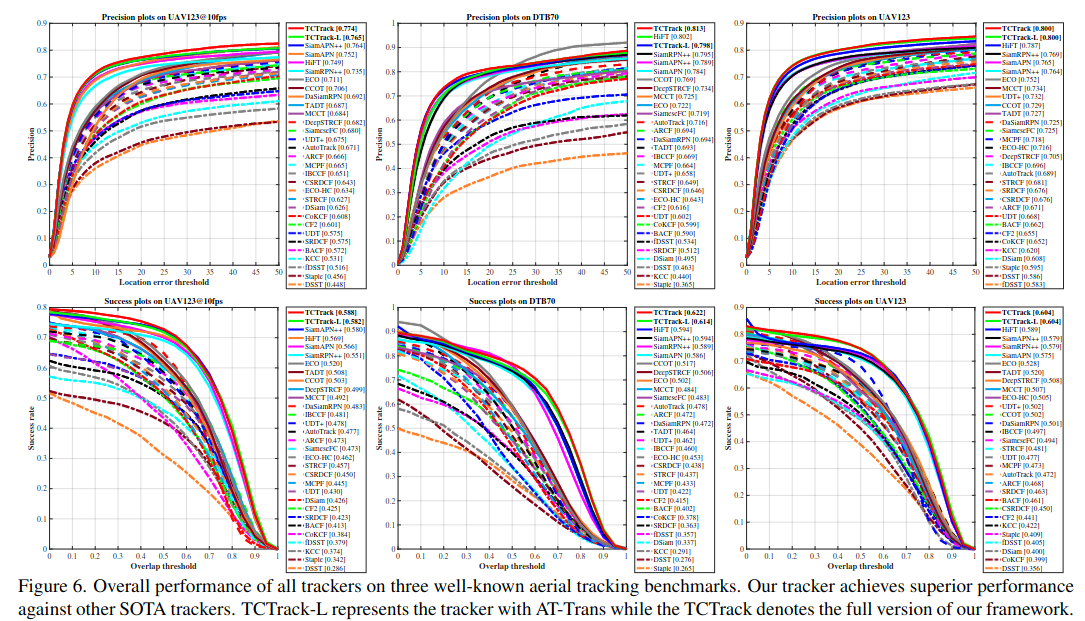
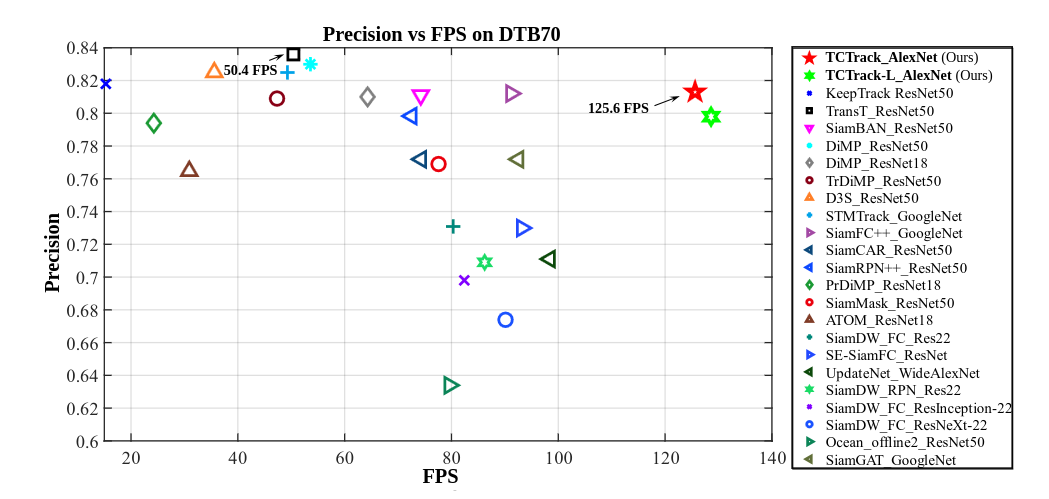
Result

Real-world Tests
- NVIDIA Jetson AGX Xavier + Pixhawk
- RAM Usage : 15.29%
- GPU VRAM usage : 3 %
- utilization of GPU : 46%
- utilization of CPU : 12.43%
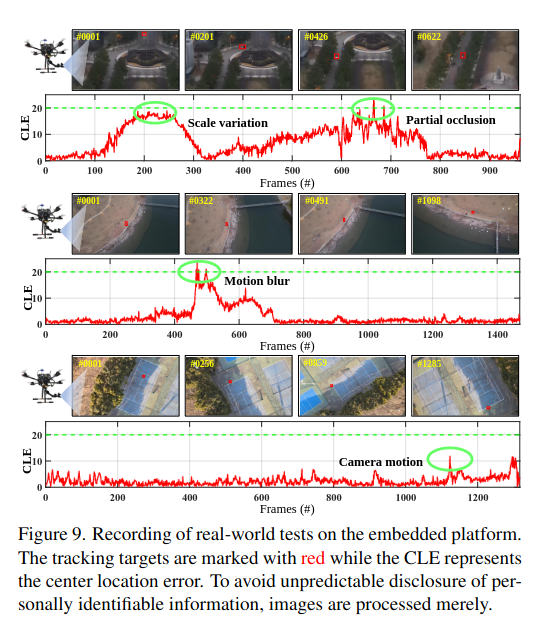
- Real-world test에서 challenges
- illumination
- scale variation
- occlusion
- motion blur
- low-resolution scenes
→ TCTracker는 다양한 문제에 대해서 robust
→ 27 FPS로 작동
Discussion
- Tracking sequence frame들의 temporal context를 활용한다는 점이 매우 자연스럽게 느껴지고, 이러한 context를 활용하여 conv weight를 online으로 calibration하는 것과 attention을 활용해 target object에 대한 similarity map을 refine 한다는 점에서 novelty가 있다.
- 특히 real-time으로 작동한다는 점이 가장 큰 장점 중 하나인데, 성능이 더 좋은 detection backbone을 사용했을 때도 real-time으로 작동할 수 있는지 확인이 필요할 것 같다.
- Similarity map을 구하는데 사용되는 template feature는 target object image의 feature로 initialize되는데, 이 target object의 template feature를 어떻게 설정하는 가에 따라서도 성능 차이가 많이 날 것 같다. (→ 이 부분은 자세하게 설명이 되어있는 것 같지는 않아서 코드 조금 확인)
Code analysis
- 이해를 조금 더 보충하기 위해 코드 확인
Initialization of tracker
for idx, (img, gt_bbox) in enumerate(video):
tic = cv2.getTickCount()
if idx == 0:
cx, cy, w, h = get_axis_aligned_bbox(np.array(gt_bbox))
gt_bbox_ = [cx-(w-1)/2, cy-(h-1)/2, w, h]
tracker.init(img, gt_bbox_)
pred_bbox = gt_bbox_
scores.append(None)
if 'VOT2018-LT' == args.dataset:
pred_bboxes.append([1])
else:
pred_bboxes.append(pred_bbox)
else:
outputs = tracker.track(img,hp)
pred_bbox = outputs['bbox']
pred_bboxes.append(pred_bbox)
scores.append(outputs['best_score'])- 영상에서 첫번째 frame의 img와 이때 gt bounding box를 활용해서 tracker를 initialize
tracker.init(img, gt_bbox_)tracker.init에서는 bounding box 좌표를 활용해 image의 target object 부분을 crop하고 model의 template으로 등록
def init(self, img, bbox):
"""
args:
img(np.ndarray): BGR image
bbox: (x, y, w, h) bbox
"""
self.image=img
self.center_pos = np.array([bbox[0]+(bbox[2]-1)/2,
bbox[1]+(bbox[3]-1)/2])
self.size = np.array([bbox[2], bbox[3]])
# calculate z crop size
w_z = self.size[0] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
h_z = self.size[1] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
s_z = round(np.sqrt(w_z * h_z))
self.scaleaa=s_z
# calculate channle average
self.channel_average = np.mean(img, axis=(0, 1))
# get crop
z_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.EXEMPLAR_SIZE,
s_z, self.channel_average)
self.template=z_crop
s_x = s_z * (cfg.TRACK.INSTANCE_SIZE / cfg.TRACK.EXEMPLAR_SIZE)
x_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.INSTANCE_SIZE,
round(s_x), self.channel_average)
self.model.template(z_crop,x_crop)-
z_crop: target object의 reference template을 의미 -
x_crop: network의 search region을 의미 -
self.model.template에서는 backbone으로부터 feature를 추출하고, 이를 template으로 등록
def template(self, z,x):
with t.no_grad():
zf,_,_ = self.backbone.init(z)
self.zf=zf
xf,xfeat1,xfeat2 = self.backbone.init(x)
ppres=self.grader.conv1(self.xcorr_depthwise(xf,zf))
self.memory=ppres
self.featset1=xfeat1
self.featset2=xfeat2Initial temporal prior는initial similarity map에 conv를 수행하여 도출
ppres=self.grader.conv1(self.xcorr_depthwise(xf,zf))-
self.memory가 temporal prior knowledge를 의미 -
self.backbone.init은 backbone network로부터 feature 뽑는 것 -
self.temporalconvlayer는TAdaConvlayer로, 두번째 인자로 추출되는feat은calibration weight, bias정보를 포함
def init(self, xset):
xset = self.block1(xset)
xset = self.block2(xset)
xset = self.block3(xset)
xset=xset.unsqueeze(1)
xset,feat1 = self.temporalconv1.initset(xset)
xset = self.b_f1(xset)
xset=xset.unsqueeze(1)
xset,feat2 = self.temporalconv2.initset(xset)
xset = self.b_f2(xset)
return xset,feat1,feat2 Inference flow
tctrackplus_tracker.py- input image에서 이전
center_pos기준으로Instance_size만큼 crop한x_crop이 실제 network input x_crop으로부터 bbox를 예측하고 원본 이미지에서 bbox를 다시 계산center_pose및size를 업데이트
- input image에서 이전
def track(self, img,hp):
"""
args:
img(np.ndarray): BGR image
return:
bbox(list):[x, y, width, height]
"""
## -->
# img로 부터 x_crop 추출
###
...
x_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.INSTANCE_SIZE,
round(s_x), self.channel_average)
##
# track inference
###
outputs = self.model.track(x_crop)
##
# 결과 추출 및 post-processing
###
...
cx = bbox[0] + self.center_pos[0]
cy = bbox[1] + self.center_pos[1]
...
##
# udpate state
###
self.center_pos = np.array([cx, cy])
self.size = np.array([width, height])
bbox = [cx - width / 2,
cy - height / 2,
width,
height]
best_score = score[best_idx]
return {
'bbox': bbox,
'best_score': best_score,
}self.model.track()→model_builder.py
def track(self, x):
with t.no_grad():
xf,xfeat1,xfeat2 = self.backbone.eachtest(x,self.featset1,self.featset2)
loc,cls2,cls3,memory=self.grader(xf,self.zf,self.memory)
self.memory=memory
self.featset1=xfeat1
self.featset2=xfeat2
return {
'cls2': cls2,
'cls3': cls3,
'loc': loc
}-
backbone으로부터 feature 추출
-
self.grader로 output 추출 -
self.memory,self.featuresetupdate -
self.grader()→utile.py(AT-Trans 부분인 듯)
def forward(self,x,z,ppres):
res3=self.conv2(self.xcorr_depthwise(x,z))
b,c,w,h=res3.size()
memory,res=self.transformer((res3).view(b,c,-1).permute(2, 0, 1),\
(ppres).view(b,c,-1).permute(2, 0, 1),\
res3.view(b,c,-1).permute(2, 0, 1))
res=res.permute(1,2,0).view(b,c,w,h)
loc=self.convloc(res)
acls=self.convcls(res)
cls1=self.cls1(acls)
cls2=self.cls2(acls)
return loc,cls1,cls2,memory
- 해당 frame의 feature x와 z의 correlation 후 () conv → similiarity map
ppres는 memory = temporal prior knowledge- similiarity map과와 memory를 transformer에 입력하여 다음 memory와 final feature 추출 (memory는 encoder에서 나오고, feature는 decoder에서 나옴)
- final feature를 최종 loc, cls conv에 넣어 output 추출
