Paper : D-NeRF: Neural Radiance Fields for Dynamic Scenes (Albert Pumarola, Enric Corona, Gerard Pons-Moll, Francesc Moreno-Noguer / CVPR 2021)
- Motivation : Dynamic scene rendering은 어떻게하는지 궁금해서 공부
Short Summary
- Dynamic domain에서 neural radiance field를 적용
- Single camera로 얻은 image를 통해 object movement를 rendering
- Time을 추가적인 input으로 사용
- 학습 과정을 Canonical space rendering과 deformation으로 나누어 효율적으로 rendering
Introduction
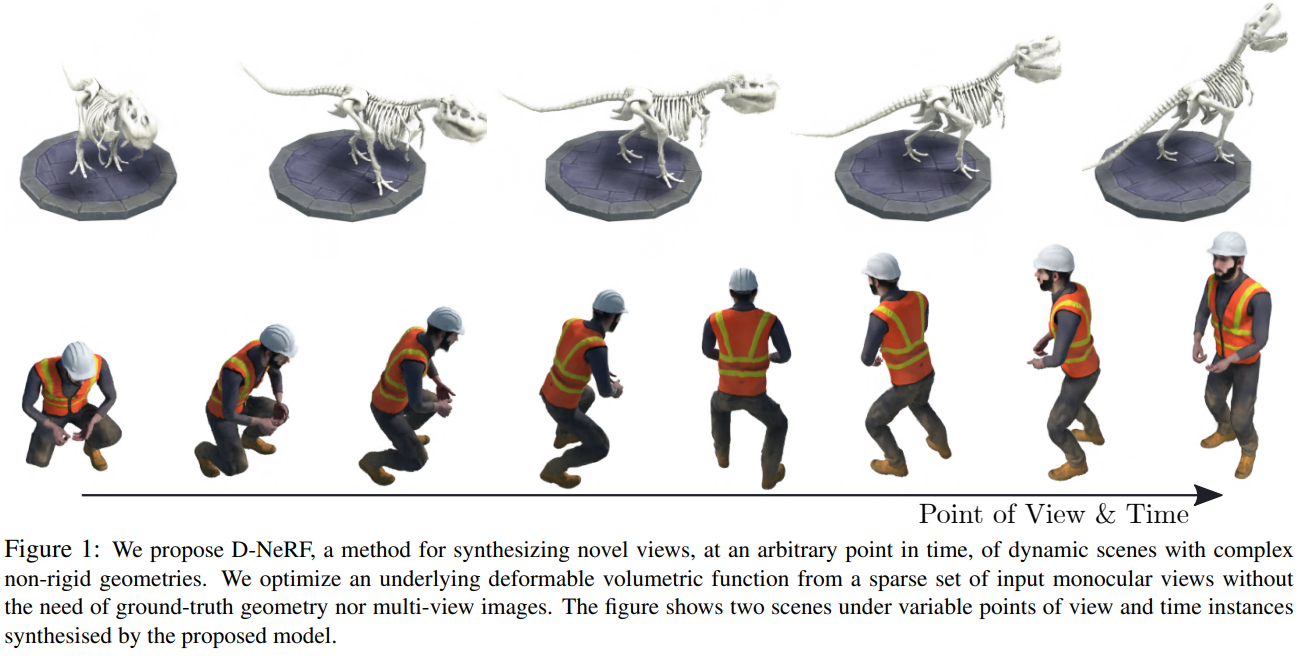
NeRF는 novel view synthesis rendering의 한 방법으로, 5D inputs (spatial locations & camera views)로부터 radiance와 volume density를 얻어내는 mapping을 encoding하는 방법이다.
하지만 이러한 방식들은 static scene만을 다뤄왔고, moving object를 rendering하지는 못한다. 이번 논문은 moving object scene을 rendering하는 것을 목표로 한다.
Core idea는 5D input에서 time component를 추가하여 6D input을 이용하는 것으로, 6D input을 바로 network에 넣는 방식이 아니라, 두 가지의 module로 나누어서 첫번째로는 시간 t일 때의 point와 canonical scene configuration의 point사이의 mapping을 학습하는 파트와 두번째로는 canonical scene에서 radiance와 volume density를 구하는 파트로 나누어 학습을 진행한다.
** canonical scene configuration
canonical scene configuration이라는 말이 많이 나오는데, 이거는 reference scene이라고 생각하면 될 것 같고, 특별히 t=0일 때의 scene을 생각하면 된다. 즉, 위에서 point 사이의 mapping은 t=a일 때, t=0일 때의 point로부터 얼마나 transformation이 일어났는지를 measure하는 방법.
이렇게 학습을 canonical scene에 대한 학습과 scene flow에 대한 학습으로 나눈 결과 D-NeRF는 camera view와 time component (= dynamic state of the scene)를 잘 control 하면서 high-quality image를 rendering할 수 있었다고 한다.
Method
Problem definition
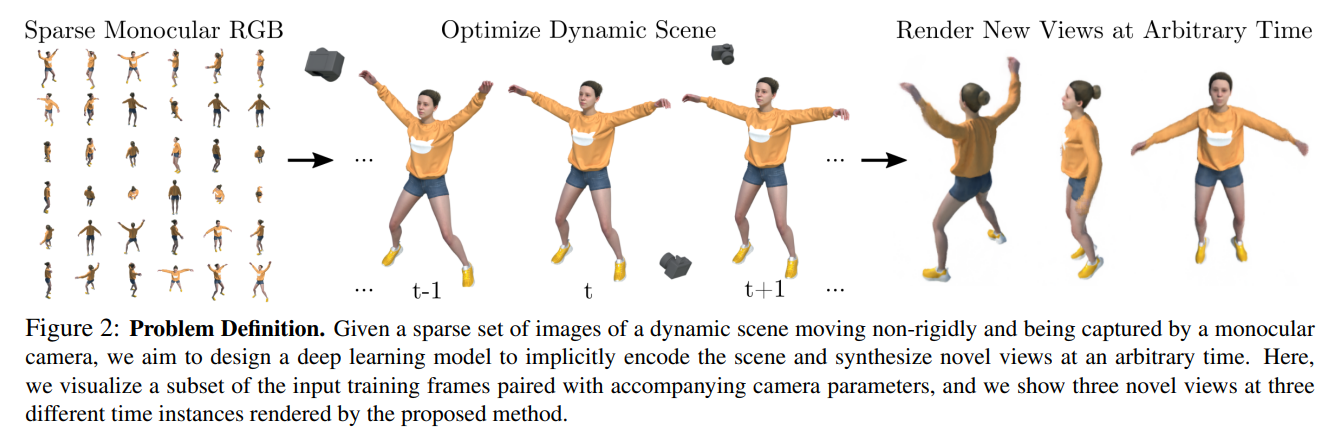
이 연구의 목적은 dynamic scene을 encoding하여 arbitrary time에서의 novel view synthesis를 생성하는 것이다. 즉, 어떤 time instant 와 view direction 의 condition에서 3D point 가 주어졌을 때, color 와 volume density 를 estimation하는 mapping 를 학습하는 것.
이를 위해서 6D space 를 직접 넣어 4D space 를 출력하는 모델을 학습하는 대신에, mapping 을 canonical configuration의 scene을 represent하는 와 time instant 에서의 scene과canonical scene사이를 mapping시키는 로 나누었다.
더 정확하게는, 어떤 임의의 time 에서 point 와 direction 가 주어졌을 때, 먼저 이 point를 canonical configuration으로의 point position으로 transform을 시킨다.
위에서 언급했듯이, canonical scene은 일 때의 scene으로 정한다.
이렇게 설계하면, 각 time instances에서의 scene들은 canonical space anchor를 통해 서로 연결되어, 더 이상 independent하지 않게 된다고 한다.
마지막으로, canonical configuration으로 transform된 point와 view direction이 에 input으로 들어가서 color와 density를 estimate하고 volume rendering하면 된다.
특히, 해당 논문에서는 일부로 time instance당 하나의 image만을 사용하는 상황을 가정하여 학습했다 (time instance 당 multiple view를 사용한다면 더 좋겠지만..).
즉, monocular camera를 이용해 찍은 T개의 RGB images 만을 사용하였다 (image acuqired under camera pose ).
** monocular camera는 각 time instance마다 single viewpoint로만 이미지를 찍는 camera로, depth information을 capture하기 어렵기 때문에, 3D object를 잘 인식하기 위해서는 다른 가정이나, technique이 필요하다. (우리 사람의 눈은 두 개의 viewpoint를 사용하는 stereo camera랑 비슷해서 한 눈에 봐도 어느 정도 깊이를 인식하는 것이 아닐까)
이제 를 Canonical Network로, 를 Deformation Network라고 하자.
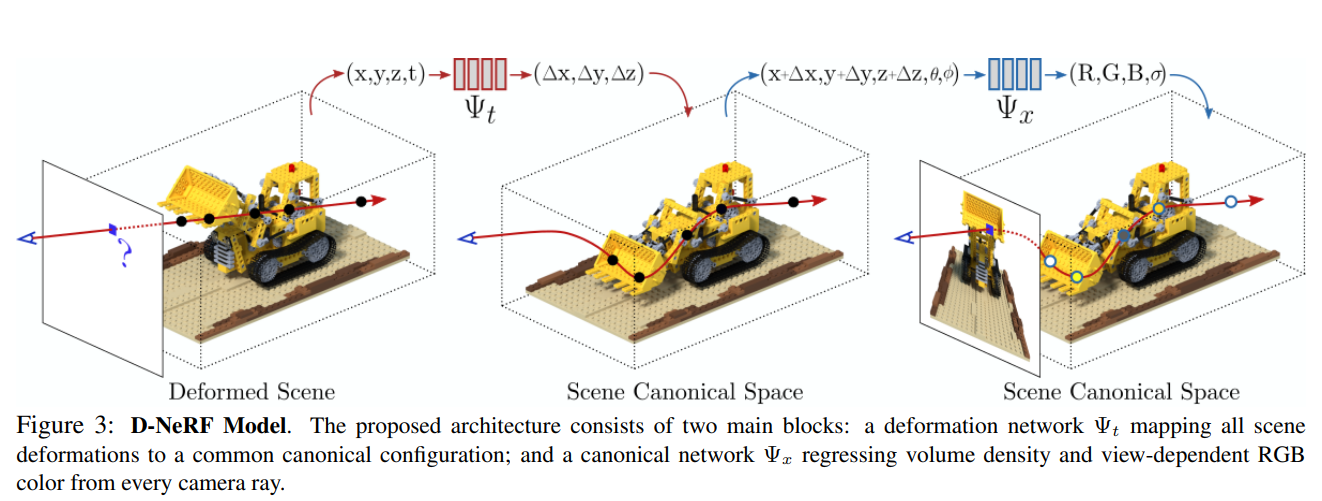
Deformation Network
Deformation Network ()도 MLP로 이루어진 network로, time 에서의 scene과 canonical configuration 사이의 transformation을 정의하는 deformation field를 encoding한다.
즉, time 에서 point 에 대해 주어진 point를 canonical space 로 transform시킬 수 있는 displacement 를 구하는 것이다.
특히, canonical scene은 일 때의 scene으로 정한다.
Canonical Network
Canonical Network ()는 MLP로 이루어진 network로, canonical configuration의 scene에 대해 volumetric density와 color를 encoding한다.(NeRF에서의 MLP와 같아보임)
Canonical configuration을 사용하게 되면, t=0에서의 scene의 어떤 point (위 그림에서 cene canonical space의 각 point)에 대해 모든 t의 서로 다른 이미지에서 해당하는 point (deformed point)의 정보를 같이 만족 시키는 representation을 학습하게 된다. 그렇게 함으로써, 특정 view point에서 부족한 정보는 서로 다른 이미지들을 연결시키는 anchor 역할을 하는 canonical configuration으로부터 얻어낼 수 있게 된다.
여기서도, canonical network와 deformation network에 들어가기 전에, 와 는 sinusoidal function을 이용해 higher dimension space로 encoding해준다고 한다.
Volume rendering
Volume rendering 방식은 기존의 NeRF와 같고, 대신에 camera ray위의 각 point가 deformation network에 의해 canonical space로 mapping된 후의 color와 density를 이용한다.
Training loss는 아래와 같다.
Experiments and Results
Dissecting the model
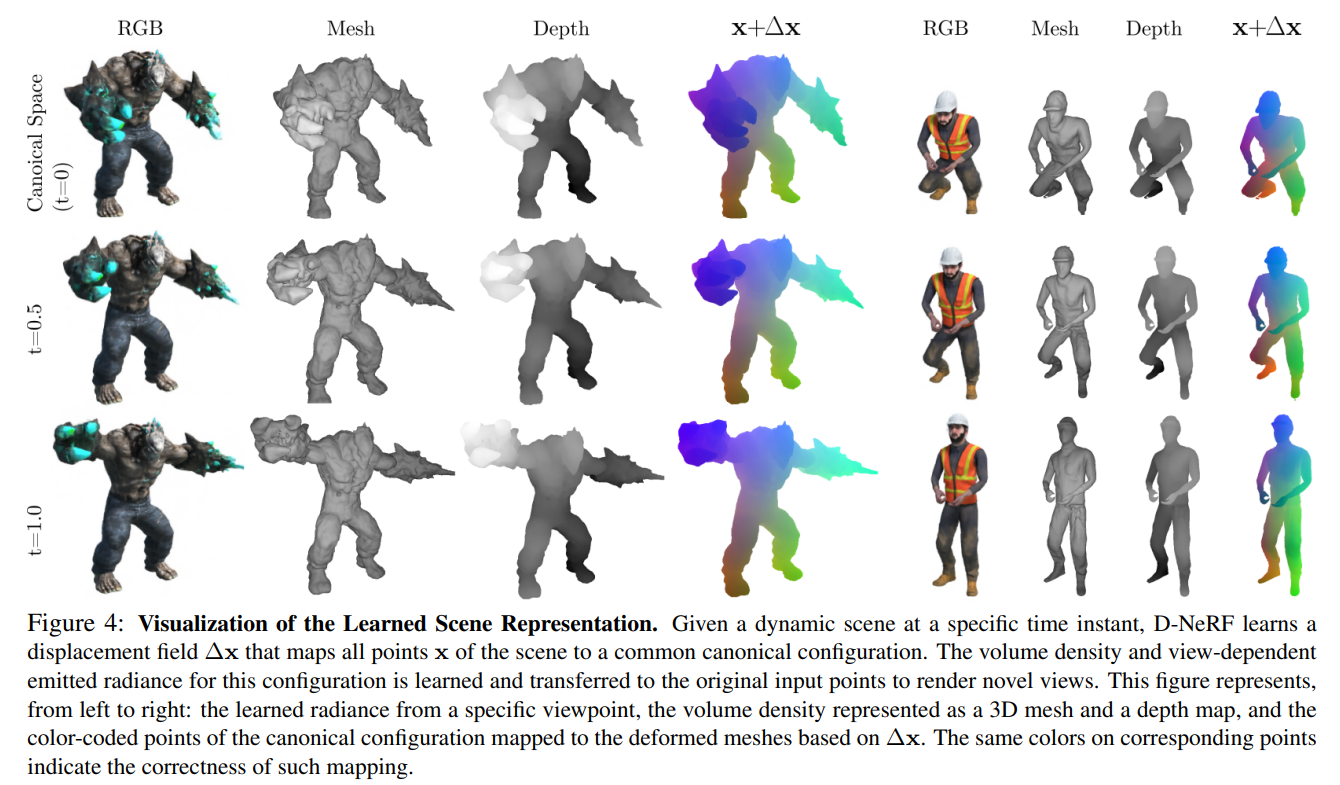
위 그림에서 두번째, 세번째 row 이미지는 에서 translation vector를 적용한 결과이다.
먼저 deformation network의 관점에서 보면, 네번째 colume은 displacement field를 visualize한 것인데, canonical shape ()에서 서로 다른 point를 color-coding으로 다르게 표현된 것이 시간이 흐르면서 같은 위치에 같은 color가 칠해진 것을 보면 물체가 움직이더라도 같은 지점을 잘 mapping할 수 있다는 것을 알 수 있다.
Canonical network의 관점에서는 1~3번째 colume을 보면 시간이 흐르더라도 geometric과 appearance detail을 잘 modeling할수 있다는 것을 보여준다.
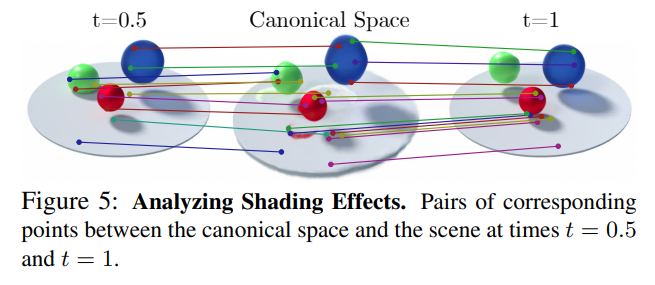
D-NeRF는 shadws/shading effect도 잘 표현할 수 있다고 한다. 이것도 마찬가지로 canonical configuration을 warping함으로써 하나의 같은 point의 시간에 따른 변화를 잘 encoding할 수 있기 때문이라고 한다.
Comparison with baseline method

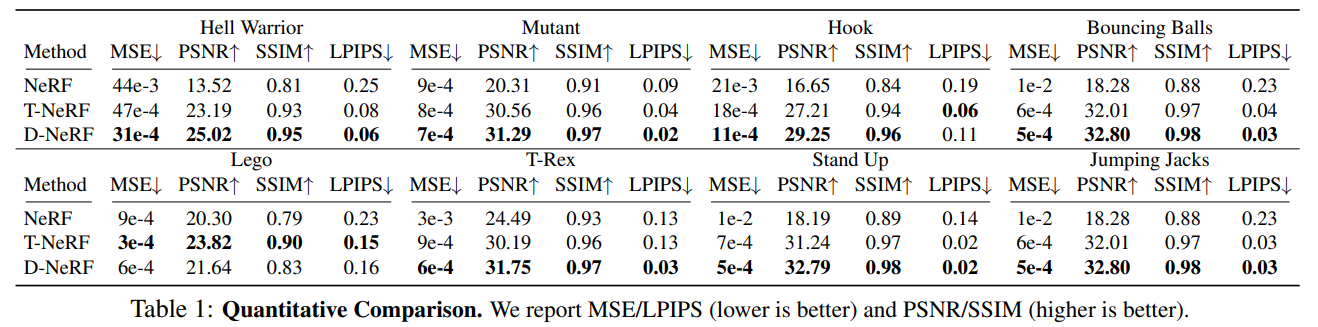
추가적으로 canonical network와 deformation network의 효용성을 알아보기 위해 baseline NeRF와 6D input을 직접 넣어주는 T-NeRF와 성능을 비교했다.
NeRF는 당연히 dynamic scene representation을 위해 설계되지 않았으므로 못하는 것이 보이고, T-NeRF는 나름 잘 하지만, high freqeucy detail을 살리지는 못한다고 한다.
Additional results

Discussion
현실 세계에서 scene rendering은 오히려 static보다 dynamic인 경우가 당연히 많기 때문에 시간을 고려한 representation이 당연히 중요해지는 것 같다.
다만 이 연구도 정해진 공간에서 잘 정의된 camera parameter와 time이 있는 데이터셋으로 진행되었기 때문에 실제로 monocular video를 촬영하고 이를 바탕으로 4D rendering을 할 수 있는 연구가 있다면 더 공부해볼 예정이다.
