Ian Goodfellow의 Deep Learning을 보고 정리한 글
Introduction
"Inventors have long dreamed of creating machines that think."
AI에게 가장 큰 어려움은 사람들이 무의식적으로 쉽게 행하지만 설명하기는 어려운 것을을 해내는 것이다. (말을 알아듣거나 얼굴을 알아보거나)
이러한 직관적인 문제를 해결하기 위해 컴퓨터로 하여금 실제 세상의 데이터로부터 어떠한 개념을 배우도록 하려고 한다. 이때 어떠한 개념들의 체계는 또 다른 쉬운 개념들로 이루어져 있고, 이를 graph로 나타내면 아주 복잡하고 깊은 구조일 것이다. -> 우리는 이것을 Deep Learning이라고 부른다.
AI시스템은 raw data로부터 패턴을 추출하고 이 지식을 습득할 수 있어야 하는데, 이를 machine learning이라고 한다. 초기 machine learning은 real world data의 지식으로부터 어떠한 결정을 내릴 수 있었다. (e.g. logistic regression, naive Bayes)
이러한 machine learning algorithm들의 성능은 data의 representation에 아주 큰 영향을 받는데, 이러한 representation을 우리는 feature라고 한다. feature가 어떻게 정해지느냐에 따라 task의 가능 여부가 정해지기도 한다.
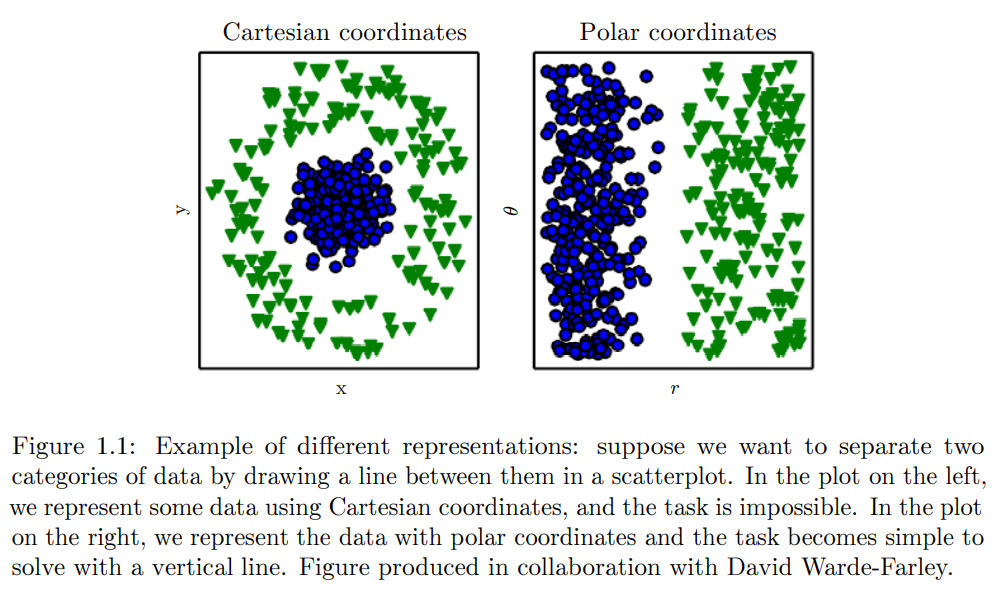
그러나 많은 경우, 어떠한 feature가 추출되어야할지 정하는 것은 어려운 일이다. 예를 들어 한 이미지 내부에서 차를 구분해낸다고 했을 때, 우리는 바퀴를 생각할 수 있다. 그런데 이 바퀴를 pixel value 입장에서 어떻게 설명할지는 참 어려운 일이다.
하나의 방법으로는 machine learning을 가지고 representation을 통해 output을 내는 것 뿐만 아니라 representation까지 배우도록 할 수 있다. 이를 우리는 representation learning이라고 한다.
Autoencoder가 하나의 예시로, encoder는 input data를 서로 다른 representation으로 변환시키고, decoder는 원본 이미지로 복구시키는 구조인데, 이 encoder는 최대한 많은 정보를 포함하는 representation을 배우게 된다.
feature를 설계하거나 feature를 배우는 알고리즘을 설계할 때, 가장 중요한 것은 관측된 데이터를 설명할 factors of variation을 잘 구분하는 것이다. 예를 들어 차 이미지를 분석할 때, factors of variation은 차의 위치, 색깔, 각도, 태양의 비침 정도가 될 수 있을 것이다. 중요한 feature를 구분해서 찾아내고, 의미없는 feature를 버리는 일이 필요할 것이다.
Deep learning은 좀 더 간단한 representation들로 이루어진 representation들을 이용해 이러한 문제를 해결한다. 아래의 예시는 사람이라는 개념을 좀 더 작은 단위의 개념(edges, corners, contours)을 이용해 표현하는 과정을 보여준다.
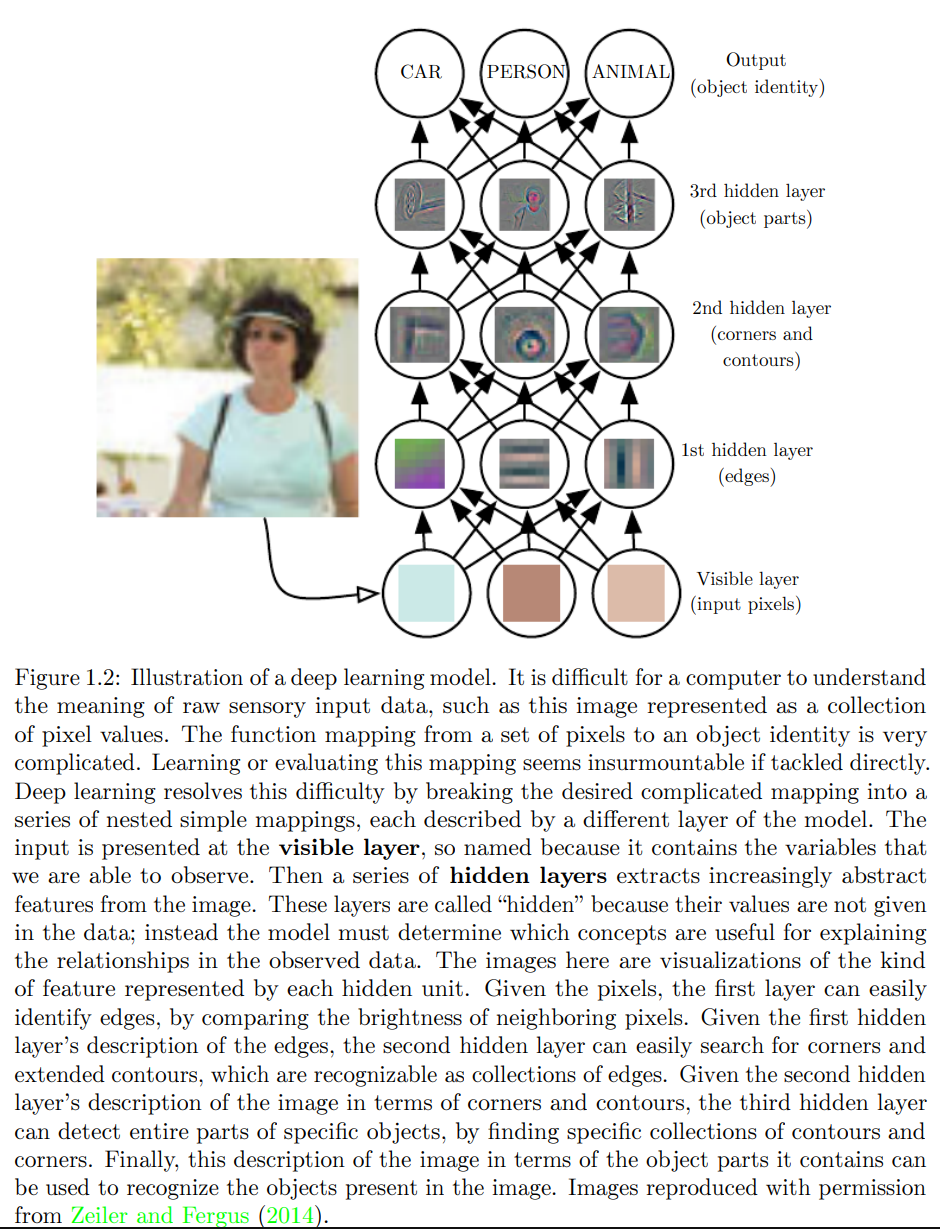
deep learning model의 가장 대표적인 예시가 바로 multilayer perceptron(MLP)이다. MLP는 단순히 input value를 output value로 mapping해주는 mathematical function이다. 이 simple function의 연속으로 새로운 representation을 제공해낼 수 있다.
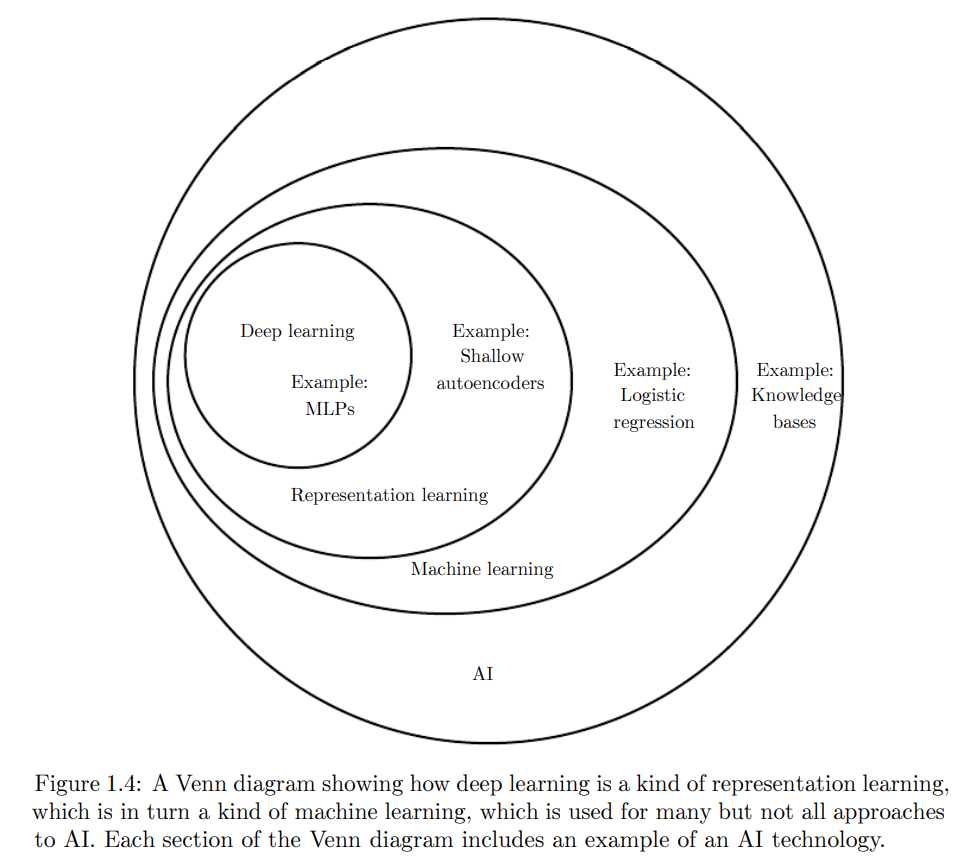
정리하자면, deep learning은 AI 분야에서 하나의 접근법이다. 이는 machine learning의 한 종류이며, data를 이용해 스스로 성장한다. deep learning은 아주 복잡하게 이어진 (하지만 간단한 개념들로 이루어진) 개념 체계를 이용해 (덜 추상적인 것들을 이용한 더욱 추상적인 representation을 이용하는) real world를 표현할 수 있는 강력한 메소드이다.