Paper : EfficientDet: Scalable and Efficient Object Detection (Mingxing Tan, Ruoming Pang, Quoc V. Le / CVPR 2020)
EfficientDet은 EfficientNet을 기반으로 설계된 Object Detection 네트워크로, 모델의 효율성에 가장 큰 초점을 두었다.
속도와 성능 측면에서 아주 좋은 모습을 보이며 오랫동안 SOTA를 달성하였다.
Highlights
- YOLO v2를 발전시킨 새로운 버전의 YOLO 모델 제안
- Bounding box prediction / Class prediction 방식에 변화
- Multi-scale feature의 활용
Introduction
Object detection 모델들은 정확도를 높이기 위해 더욱 커지고 연산량도 많아 real-world application에 적용되기 어렵다는 단점을 가지고 있다.
이러한 문제를 해결하기 위해 one-stage detector (YOLO, RetinaNet, SSD)나 anchor-free detector (CornerNet, Fcos)가 제안되었지만, 항상 trade-off가 있었다.
이 논문은 accuracy와 efficiency의 관점에서 두 마리의 토끼를 다 잡으려는 시도를 하였고, one-stage detector paradigm을 기반으로 아래 두 문제를 해결하여 좋은 성능을 보여줬다.
1) Efficient multi-scale feature fusion
Object detection 모델들은 이전부터 다양한 크기의 object를 탐지하기 위해 multi-scale feature를 활용하는 방법을 연구하였는데, FPN 방식이 주로 활용되었다.
이 논문에서는 weighted bi-directional feature pyramid network (BiFPN)을 제안하여, learnable parameter를 이용하여 서로 다른 resolution의 feature의 중요도를 고려하여 fusion하였다.
2) Model scaling
이전의 많은 연구들은 성능 향상을 위해 backbone network의 크기를 키우거나 input size를 늘리는 방식을 택했는데, 이러한 방식은 항상 accuracy와 efficiency의 trade-off가 존재했다.
이 논문에서는 같은 저자의 연구인 EfficientNet과 같은 compound scaling 방법을 제안하여 더욱 적은 FLOP과 parameter 수로 더욱 좋은 accuracy를 달성하는 EfficientDet Family를 제안한다.
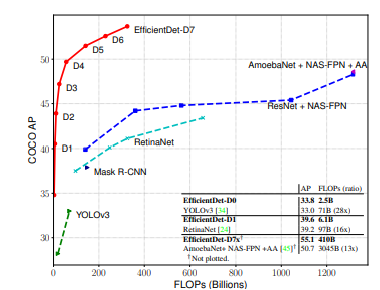
이전의 많은 모델들과 비교해서 더 적은 FLOP (연산량) 수를 통해 훨씬 높은 detection 성능을 달성한 것을 확인할 수 있다.
Background
1 Stage vs. 2 Stage detector
Object detection 모델은 크게 1 stage detector와 2 stage detector로 나뉠 수 있다.
-
2 Stage detector

2 Stage detector의 경우, Region Proposal Network (RPN)이 존재해서, Propose된 후보 영역을 바탕으로 classification과 box regression을 진행한다.
(예) Faster R-CNN, Mask R-CNN, 등 -
1 Stage detector

1 Stage detector의 경우, RPN 없이 feature map을 통해 각 grid나 사전 정의된 location에 대해 classification과 box regression을 진행한다. 이때, 양질의 feature map을 얻기 위해 다양한 feature fusion 방식이 활용되곤 한다.
(예) YOLO, RetinaNet, 등
1 Stage detector는 simple하고 efficient하다는 장점이 있고, 2 Stage detector는 flexible하고 accurate한 장점이 있다.
EfficientDet은 1 Stage detector에 속하며, accuracy까지 잡기 위해 노력했다.
Multi-Scale Feature Representations
Object detection 에서 다양한 크기의 객체를 잘 탐지하기 위해서는 multi-scale feature를 잘 활용하는 것이 중요하다.
Multi-scale feature을 활용한 object detection은 보통 backbone network로부터 추출된 pyramidal feature hierarchy를 기반으로 하는 prediction 방식으로 발전해왔다.
가장 대표적인 연구로, multi-scale feature를 combine하는 top-down pathway를 제안한 feature pyramid network (FPN)를 시작으로, PANet, M2det, NAS-FPN 등의 연구가 있었다.
Model Scaling
모델의 accuracy를 향상시키기 위해서 baseline detector를 scaling하는 연구가 많이 진행되었고, 보통 1) backbone network의 크기를 키우거나 2) input 이미지 크기를 키우거나, 3) feature channel size를 키우거나, feature network를 반복하는 등의 방식을 채택했다.
하지만 이러한 scaling 방법론은 하나의 dimension에 집중하였는데, 같은 저자의 연구인 EfficientNet에서는 네트워크의 width, depth, input image resolution의 세 가지 scaling factor는 독립적이지 않고, 함께 scaling해주어야 한다는 사실을 발견하였고, 이러한 scaling factor들을 함께 scaling할 수 있는 compound scaling 기법을 제안하여 accuracy와 efficiency를 함께 향상시킬 수 있었다.
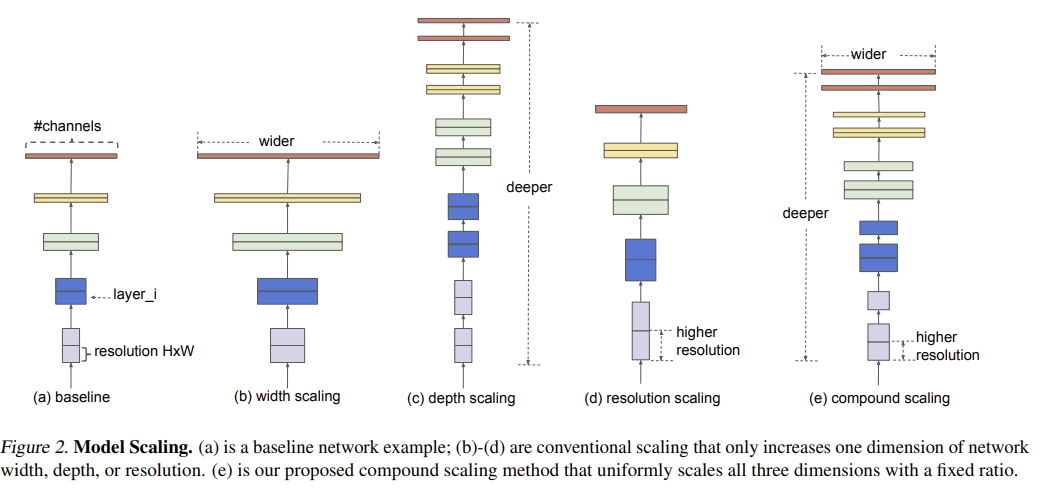
Method
BiFPN
BiFPN은 multi-scale feature를 fusion하는 방법으로, bidirectional cross-scale connection과 weighted feature fusion 방식을 이용하여 효율적으로 feature 정보를 합쳤다.
1) Problem formulation
Multi-scale feature fusion은 서로 다른 resolution의 feature를 잘 aggregate하는 것을 목표로 하며, input feature list ()를 받아 서로 다른 feature를 fusion하여 새로운 feature list ()을 얻을 수 있는 transformation 를 찾는 것이다.
-
Input
-
Output
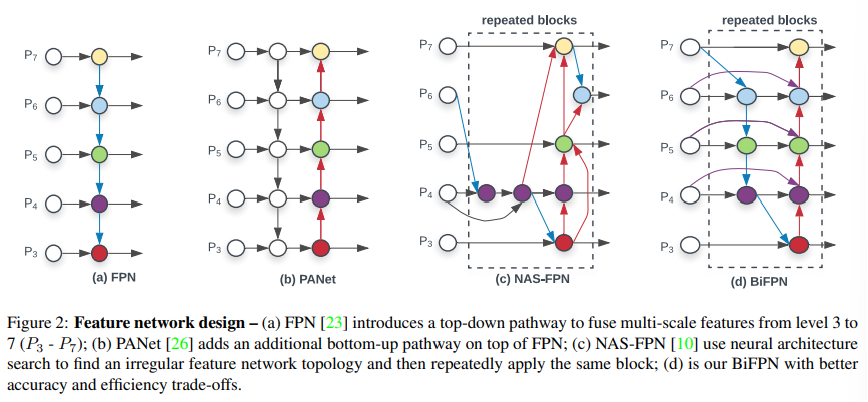
위의 figure는 다양한 feature fusion 방식을 보여주고있다.
먼저 (a) FPN은 conventional한 top-down 방식의 fusion이며, level 3~7의 feature ()를 input으로 한다.
(이때, list의 각 element는 input image resolution이 절반이 되는 때의 feature이다.)
FPN은 input feature들을 top-down 방식으로 aggregate한다.
(여기서, resize는 resolution matching을 위한 upsampling 혹은 downsampling을 의미)
2) Cross-Scale Connections
Conventional FPN은 정보가 한 방향으로만 흐르도록 설계가 되었는데, 이를 해결하기 위해서 (b) PANet은 추가적인 bottom-up path를 더해 cross-scale conection을 시도하였다. 그 후의 연구인 (c) NAS-FPN는 neural architecture search를 이용해 더 나은 cross-scale feature network를 설계하고자 하였으나, architecture searching을 위한 비용 등으로 인해 효율성이 떨어졌다.
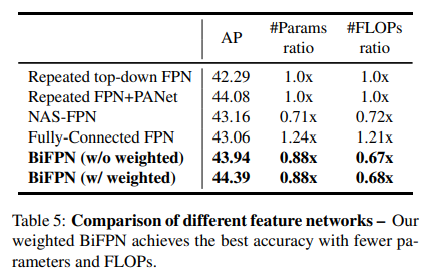
저자들은 위의 (a)~(c) 네트워크의 성능에 대해 조사하였을 때, PANet이 가장 좋은 accuracy를 보였으나, parameter와 computation cost가 가장 높았다고 한다.
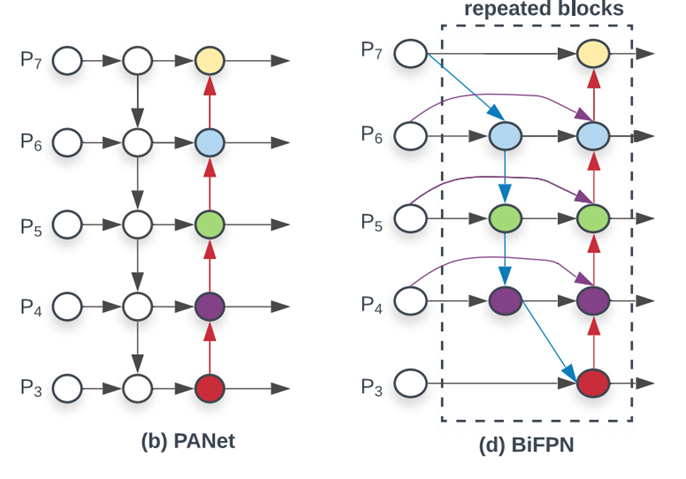
EfficientDet은 PANet으로부터 시작해서, cost를 줄이면서 accuracy를 높일 수 있는 feature aggregation 방법으로 아래의 세 가지를 제시하였다.
-
하나의 input edge만을 가지는 node를 삭제
하나의 input edge만을 가지는 node에서는 feature fusion이 일어나지 않으며. 더욱 적은 contribution을 가질 것 -
같은 level에 있는 input node와 output node를 연결하는 추가적인 edge 설치
많은 cost를 사용하지 않으면서 더욱 많은 정보를 전달하기 위해 -
하나의 bidirectional path (하나의 top-down과 bottom-up path)를 가지는 PANet과 다르게, 이 bidirectional path를 하나의 feature network layer로 생각하여, 같은 layer를 여러번 반복
더 높은 수준의 feature fusion을 가능토록
3) Weighted Feature Fusion
서로 다른 resolution의 feature를 fusing할 때, 보통은 두 feature를 같은 resolution으로 resize하고 더한다.
저자들은 서로 다른 input feature는 서로 다른 resolution을 가지므로, output feature에 unequally contribute한다는 것을 확인하였다.
이러한 문제를 해결하기 위해 각 input에 추가적인 learnable weight를 추가하여 각 input feature의 중요도를 네트워크가 학습할 수 있도록 하였다.
Weighted fusion 방식으로 Unbounded fusion / Softmax-based fusion / Fast normalized fusion을 고려하였는데, 이 중에서 이 논문에서는 Fast normalized fusion을 활용 하였다.
학습 파라미터인 에 Relu를 적용하여 0보다 큰 값을 가지도록 하였고, numerical instability를 피해기 위해 epsilon을 더해서 normalize해준다. 이렇게 하는 연산이 softmax 대비 효율적이라고 한다.
최종적으로 BiFPN은 bidirectional cross-scale connection과 fast normalized fusion을 결합한 형태이다.
위 그림의 (d) BiFPN의 level 6 feature가 하나의 feature network layer에서 어떻게 fusion되는지 예를 통해 알아보자.
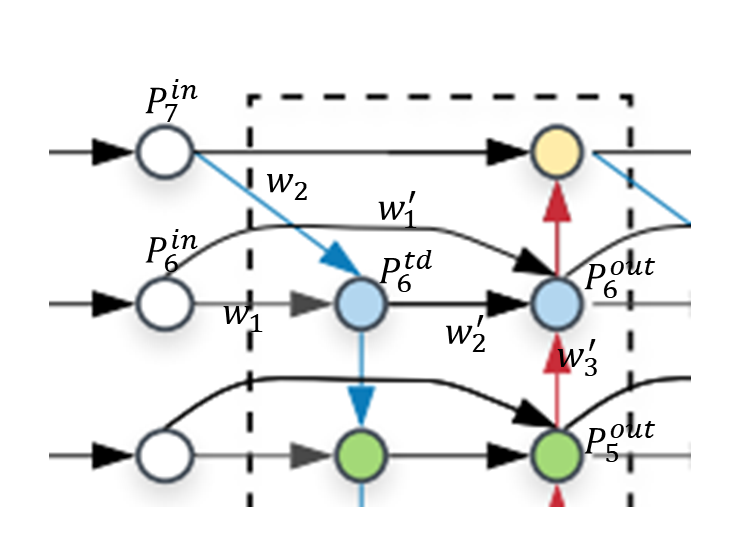
매우 직관적이다.
추가적으로, 더욱 효율적인 feature network 구성을 위해 depthwise separable convolution를 사용하였고, 각 convolution 연산 후에 batch norm과 activation을 사용하였다.
EfficientDet
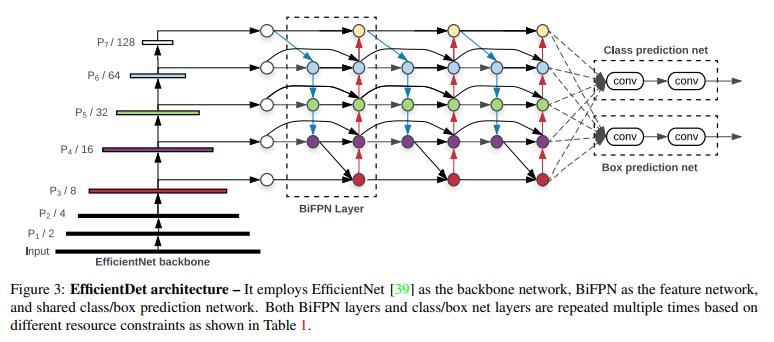
위 그림과 같이 EfficientNet backbone과 해당 논문에서 제안한 BiFPN을 결합한 것이 EfficientDet 모델이다.
Backbone으로부터 level 3~7의 feature를 추출한 후 BiFPN에 입력하여 fusion한다.
그리고 fused feature는 class와 box network의 input으로 사용되어 object class와 box를 예측하게 된다.
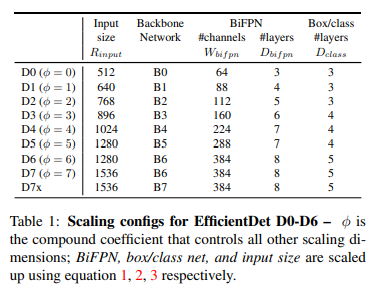
Compound scaling
Accuracy와 efficieny를 동시에 최적화하기 위해 EfficientNet과 비슷한 방식으로 compound coefficient 를 사용하여 backbone, BiFPN, class/box network 와 resolution을 jointly scaling하였다.
-
Backbone network
EfficientNet의 B0-B6의 width/depth coefficient를 그대로 사용하였다. -
BiFPN network
BiFPN의 depth (= num of layers)는 정수로 표현되어야 하므로 linearly 증가시키고, width (= num of channels)는 exponentially 증가시켰다. 특히, grid search를 했을 때, 1.35가 가장 좋은 width scaling factor라고 한다.
- Box/class prediction network
Box/class network의 width는 항상 BiFPN과 동일하게 하였지만 (), depth는 아래의 식을 통해 선형적으로 증가시켰다.
- Input image resolution
BiFPN을 위한 feature level은 3-7이였으므로, input resolution은 로 나누어 떨어져야 하므로, 아래와 같이 선형적으로 증가
이러한 조건을 따라서, 서로 다른 에 대해 EfficientD0~D7을 만들었고, scaling configuration은 아래와 같다.
Experiements
꽤나 오래전 결과
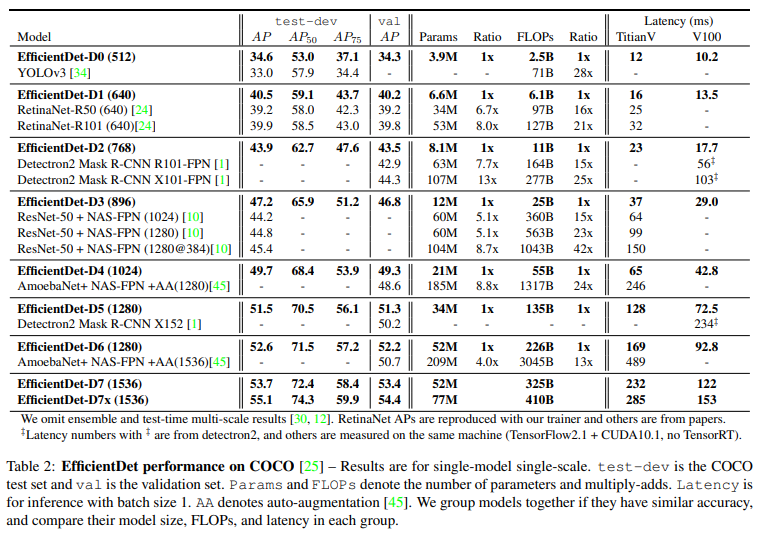
여러 모델들보다 좋은 성능
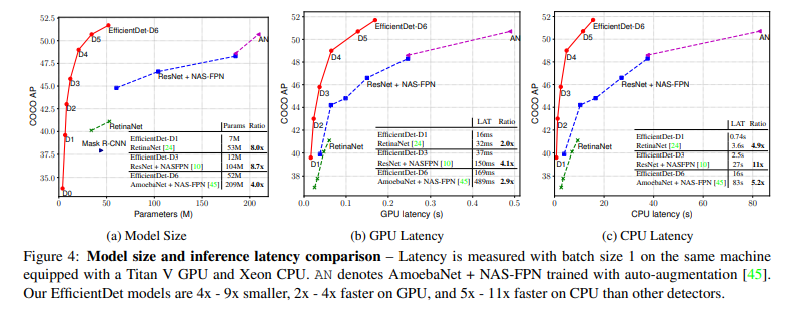
Titan-V FP-32, V100 GPU FP16, single-thread CPU에서 모두 좋은 성능 -> real-world application 가능
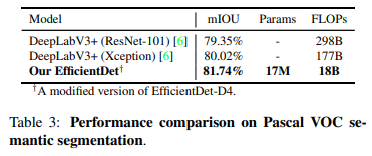
심지어 segmentation도 잘 할수 있음. Segmentation 모델로 학습하기 위해서는 BiFPN을 까지 받도록 수정하고, 만 최종 per-pixel classification을 위해 사용하였다.
Ablation은 생략하는 것으로..
Discussion
좋은 Detection 모델을 찾고 있었는데, EfficientDet만한 모델이 없는 것 같다. 간단하면서도 직관적인 모델을 통해 가볍고 정확한 성능을 내는 모델이다.
다만 compound scaling에서 backbone model과 input size scaling이 조금 헷갈리긴 한다. EfficientNet에서는 B6에 528x528을 사용했던 것 같은데, 여기서는 같은 backbone으로 1280x1280을 사용하도록 설계한 것 같다.
