Paper : Unsupervised Monocular Depth Estimation with Left-Right Consistency (Clément Godard, Oisin Mac Aodha, Gabriel J. Brostow / CVPR 2017)
Monodepth1 논문으로 monocular depth estimation에서 seminar한 work인 것 같다. Monodepth2 읽기전에 한번..
Highlights
- Ground truth가 없는 학습 데이터를 이용하여 monocular depth estimation할 수 있는 방법 제안
- Left-Right consistency loss를 활용하여 성능 향상
Introduction
Depth estimation은 이미지의 깊이, 즉, 이미지 내 물체들이 얼마나 멀리 있는지를 추정하는 task이다.
이 task를 수행하기 위해는 보통 multiple observation을 이용하는데, 최근에는 하나의 이미지만을 사용하는 monocular depth estimation 방법이 발전하고 있다.
다만, supervised 방식으로 직접적으로 각 pixel의 깊이를 추정하기 위해서는 많은 학습 데이터 (depth data)가 필요하게 되는 한계가 있다.
Monodepth1에서는 depth estimation problem을 training 시 image reconstruction problem 관점으로 접근하여, self-supervised 방식으로 이 문제를 풀었다.
Stereo pair를 이용한 image reconstruction이 supervisory signal이 되어서, 한 이미지의 depth information을 이용하여 다른 이미지를 reconstruct하게 하고, 이 recon error를 줄이도록 학습하는 방식이다.
기존의 Stereo depth estimation에 대한 간단한 정리는 여기.
Method
Depth Estimation as Image Reconstruction
test time에 single image 가 주어졌을 때, per-pixel scene depth 를 추정하는 를 학습하는 것이 목표.
Supervised learning으로 이 문제를 풀기 위해서는 GT depth data가 많이 필요하기 때문에, 저자들은 depth estimation을 학습시 image reconstruction problem의 관점에서 풀고자 하였다.
이러한 관점은 binocular camera의 pair 이미지가 주어졌을 때, 네트워크가 하나로부터 다른 이미지를 recon할 수 있다면, 그 네트워크는 3D shape에 대해 어느정도 이해했다고 볼 수 있다는 직관을 바탕으로 한다.
실제 학습시에. 같은 시점에 찍은 calibrated stereo pair의 left/right image ()를 사용한다. 그리고 depth를 직접적으로 predict하는 방식이 아니고, dense correspondence field 을 예측하는데, 이는 left image에 적용됬을 때, right image를 reconstruct할 수 있게 하는 field이다.
Left image로부터 recon된 right image를 로 하고, 반대로 right image로부터 recon된 left image를 로 한다.
Image가 rectified되어있다는 가정 하에, 는 image disparity가 되고, camera baseline distance 와 camera focal length 가 주어졌을때, predicted disparity로부터 depth 를 recover할 수 있다.
** rectified되었다는 것은 left/right image가 horizontally parallel하게 되어있다는 뜻인 것 같다.
Depth Estimation Network
저자들은 이 모델의 핵심이 오직 left image만을 사용해서 left-to-right과 right-to-left disparity를 동시에 구할 수 있다는 것이라고 하고, 추가로 서로 consistent하게 만듦으로써 depth를 더욱 잘 추정하는 것이라고 한다.
Monodepth1 network는 bilinear sampler를 이용한 backward mapping을 통해 synthesize image를 생성한다.
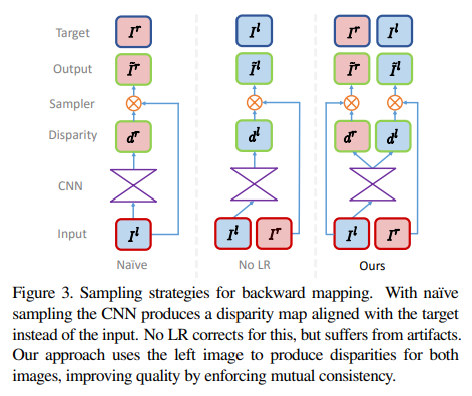
Left image로부터 right image를 생성하는 전략으로,
Naive한 방식의 경우 left image가 CNN에 들어가서 right image와 align되는 disparity 를 추정하고, left image에 sampling을 적용하여 right image 를 생성하도록 학습된다.
그런데 우리는 inference시에 left image를 넣어 left image와 align되는 disparity map을 얻는 것이 목적이기 때문에, network가 right image에서 sampling하도록 하는 No LR 방식으로 발전시켰다.
하지만 아래 그림과 같이 No LR은 'texture-copy' artifact와 depth discontinutity error가 발생하였기 때문에, 최종적으로는 양쪽 view에 대한 disparity map을 예측하고, 반대 이미지에서 sampling하는 방식으로 발전시켰다.

Training Loss
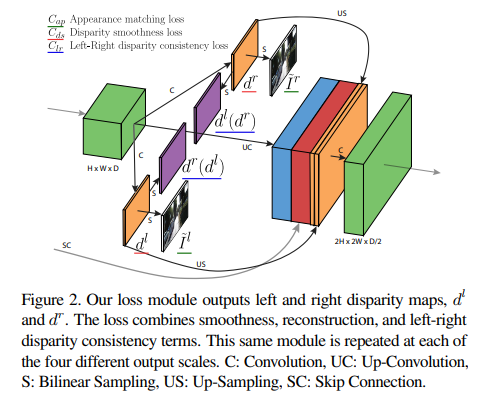
Monodepth1에서는 각 output scale 에 대해 loss 를 정의하고, 최종 loss를 로 사용하였다.
그리고 는 아래와 같이 3가지 main term의 조합으로 정의된다.
- : recon된 image가 training input과 비슷하도록 학습
- : enforce smooth disparity
- : 추정된 left/right disparity가 consistent하도록
각 term이 left/right image를 변수로 가지지만, 실제로는 left image만 CNN에 들어간다. (network가 left/right disparity map을 둘 다 추출하기 때문에 loss는 둘 다 구할 수 있는 것)
아래는 각 component에 대한 설명으로, 위의 그림이랑 matching시켜보면 편하다.
네트워크는 left image를 input으로 받아 먼저 left와 right disparity를 생성해낸다,
Right disparity는 sampling되어 left disparity로 생성하는 데 사용되거나, left image를 sampling하여 right image를 recon하는데 사용된다. Left disparity는 반대로 left disparity로 다시 sampling되거나 right image와 함께 left image를 recon하는데 사용된다.
(1) Appearance Matching Loss
학습하는 동안, 네트워크는 disparity map을 사용하여 opposite stereo image로부터의 pixel을 sampling하여 이미지를 생성하는 법을 배운다.
이때, recon된 image가 원래의 이미지와 비슷하도록 하는 loss를 사용한다. (예를 들어, 과 을 통해 을 생성하고 과 compare)
(2) Disparity Smoothness Loss
Disparity discontinuity를 방지하기 위하여 disparity gradient 에 penalty를 사용하여 locally smooth하게 만들어준다.
이 Edge-Aware Smoothness Loss는 depth map을 최대한 smooth하게 만들면서도, edge가 있을 때는 smoothness를 조금은 무시할 수 있도록 해준다.
(3) Left-Right Disparity Consistency Loss
Monodepth1의 network는 오직 left view만을 input으로 받아 left/right image disparity를 둘 다 생성한다.
이때, 더욱 정확한 disparity map을 생성하기 위해, left-right disparity consistency penalty를 부여한다. 이 loss는 left-view disparity map이 projected right-view disparity map과 일치하도록 학습시키는 용도이다. (위 그림에서 로 표현)
cycle loss과 비슷한 느낌인 것 같다.
Inference
Test time에는 network가 left image의 finest scale level에서 disparity를 예측하고, training set에서 이미 알고 있는 camera focal length와 baseline를 통해 disparity map을 depth map으로 변환시킨다.
Model architecture
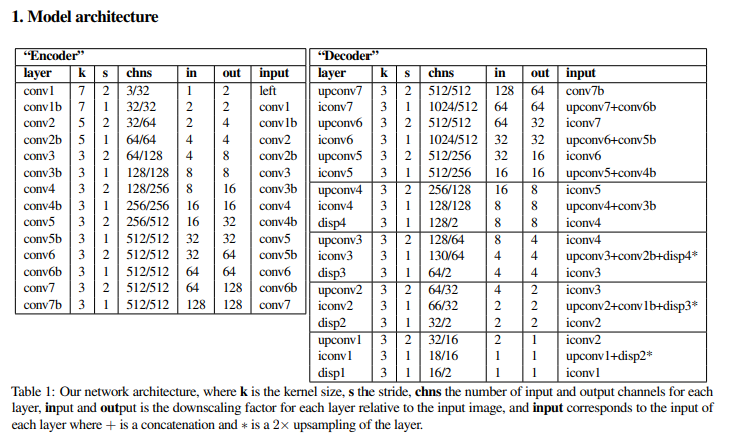
Architecture는 DispNet을 따르며, ground truth depth를 받지 않도록 변형되었다.
Encoder와 decoder로 이루어져 있는 구조로, decoder part를 보면 disp4 ~ disp1까지 4개 scale의 disparity prediction을 구하여 위에서 정의한 loss를 통해 학습한다.
Result

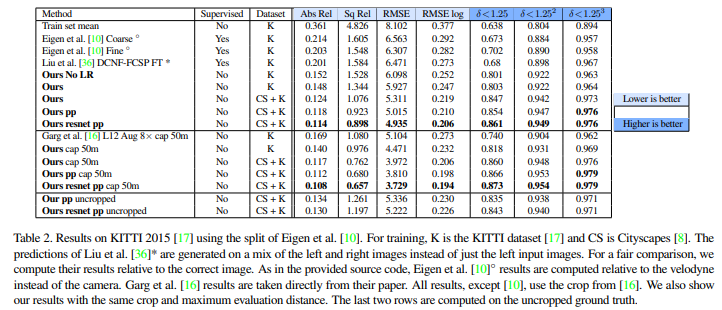
Unsupervised 방법으로, 좋은 성능을 보인다.
추가적으로, 위의 표에서 는 post processing을 통한 성능 향상을 보여주는데, 이는 disparity ramp 현상을 야기할 수 있는 stereo occlusion을 해결하기 위해서 적용된다.
Disparity ramp 현상은 물체의 edge나 이미지의 side부분에서, 한 view에서 보이는 것이 다른 view에서는 가려져 corresponding point가 없는 부분이 생기는 현상이다.
이러한 현상을 해결하기 위해 본 논문에서는 left image를 horizontally flipping한 이미지의 disparity map을 구하고, 이를 다시 flipping시킨 disparity map을 원래의 disparity map과 weighted sum하였다.

Discussion
monocular image를 통해 충분히 좋은 성능의 depth estimation을 수행한 것 같으나, 여전히 occlusion boundary의 artifact가 존재하는 한계가 있다.
또한, 학습 시에 GT가 필요없긴 하지만 aligned stereo pair 이미지가 필요하다는 단점이 있다. Unsupervised method긴 하지만 여전히 한 장의 이미지만을 통해 학습/추론되는 framework는 아니라고 볼 수 있다.
Stereo pair 이미지와 그 3D 공간에 대한 이해를 바탕으로 Network로 하여금 중간에서 간접적으로 disparity map을 추출해내려는 생각이 기발했던 연구인 것 같다.
Monodepth 2는 어떻게 발전시켰는지 궁금해진다.
