Paper : YOLOv3: An Incremental Improvement (Joseph Redmon, Ali Farhadi / arxiv 2018)
Yolo의 세번째 버전으로, 몇 가지 update를 통해 성능을 더욱 향상시켰다.
특히 이번 논문은 arxiv에만 업로드한 짧은 분량의 페이퍼이고, 저자의 개인적인 연구 일기와 같은 형식으로 글을 써놓아서 상당히 흥미로웠다.
Highlights
- YOLO v2를 발전시킨 새로운 버전의 YOLO 모델 제안
- Bounding box prediction / Class prediction 방식에 변화
- Multi-scale feature의 활용
Overview
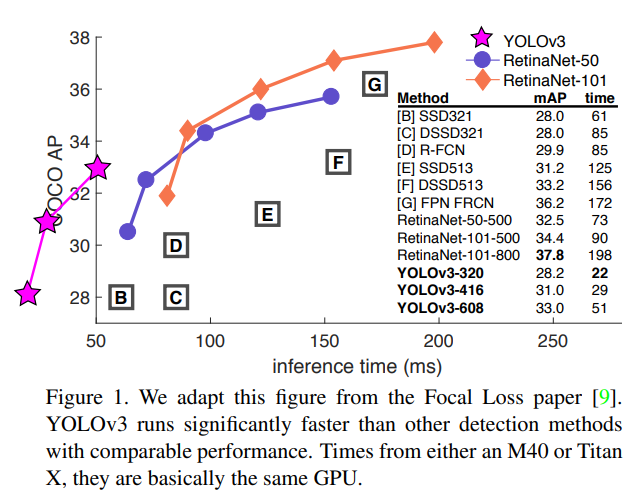
저자들은 YOLO v3에 대해, 특별히 novelty가 있는 방법론을 제안한 것은 아니고, 다른 연구에서 좋은 방법론들을 잘 적용해서 YOLO의 성능을 적당히 향상시킨 TECH REPORT정도라고 표현하고 있다.
그럼에도 불구하고 여전히 좋은 성능을 보이며, 당시 Focal loss를 제안했던 RetinaNet과 비슷한 성능을 보이면서 x3.8배 빠른 inference time을 보여주었다.
Method
1) Bounding Box Prediction
YOLO v3에서는 YOLO v2때와 같이, dimension cluster를 anchor box처럼 사용하는 방식을 택하며, 네트워크는 각 bbox에 대해 4개의 coordinate를 추출한다. ()
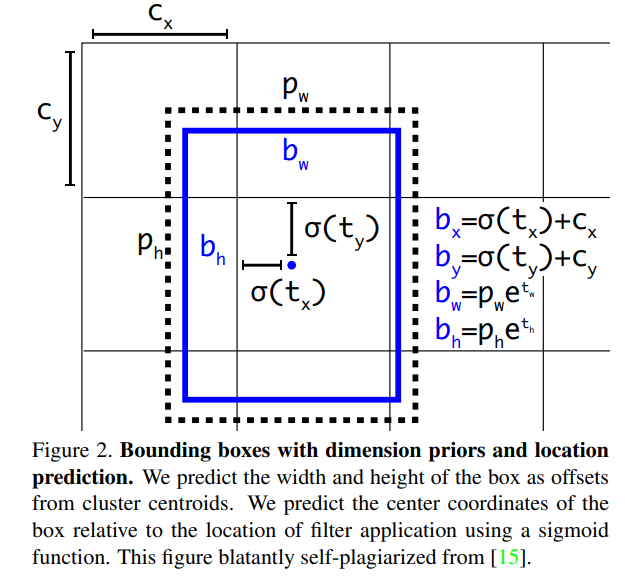
만약 이미지의 top left로부터 해당 cell의 offset이 ()이고, bounding box prior(=anchor box)의 width, height가 라면, 아래와 같이 실제 bbox prediction을 계산할 수 있다.
실제 training 때는, squared error loss를 사용하며, GT coordinate를 위의 식을 변형시켜서 ()와 같은 좌표계로 바꾸고 loss를 계산한다.
추가로, network는 각 bbox마다 logistic regression을 통해 objectness score를 구하는데, 이 값은 GT object와 가장 많이 overlap되는 bbox prior에게 1로 부여된다.
그런데 GT와 가장 많이 겹친 bbox라고 하더라도, 어떤 임의의 threshold (여기선 0.5)를 정해서, IOU가 threshold보다 낮으면, 해당 prediction bbox를 무시한다.
2) Class Prediction
각 bbox에 대해서는 이제 softmax를 사용하지 않고, multi-label classification을 수행한다.
softmax는 하나의 class만 있다는 가정을 전제로 하므로, 하나의 box안에 여러 label이 겹쳐있을 때, 학습이 잘 안되는 문제가 있기 때문에 multi-label approach를 사용.
3) Predictions Across Scales
YOLO v3에서는 FPN과 유사한 방법으로 추출한 3개의 서로 다른 scale feature를 사용하여 box를 예측한다.
각 scale에서 최종 예측은 bounding box, objectness와 class prediction을 포함하는 3D tensor가 되는데, 예를 들어 COCO 데이터셋의 경우 각 scale마다 3개의 박스를 예측하도록 하였고, 이때 tensor shape는 이다. (class 갯수가 80개)
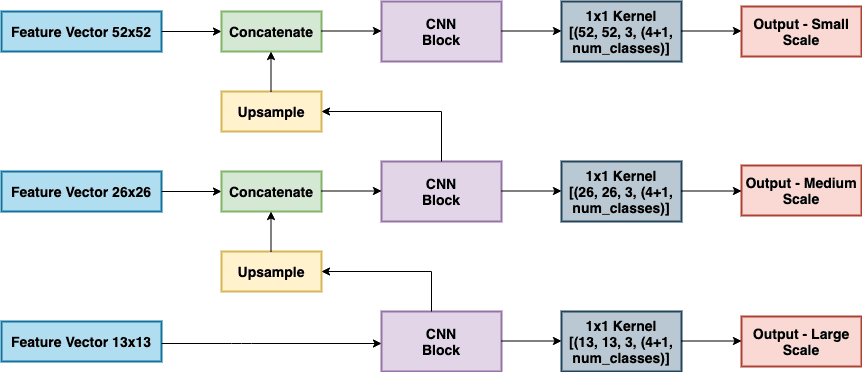
서로 다른 scale에서 predict를 수행하는 방식은 위의 그림과 같다. 먼저 가장 semantic information을 담고 있는 feature map을 FCN을 통해 위에서 정의된 크기의 output을 내도록 한다.
다음에 CNN block에서 나오기 2-layer 전에 feature map을 upsample하고 더 finer-grained information을 담고 있는 feature map과 concat하여 output을 낸다.
같은 방식으로 feature map에도 같은 방식을 적용한다.
Bounding box prior같은 경우에도 3개의 scale이 3개씩 사용하게 되므로 9개가 필요한데, YOLO v2에서 처럼 k-means clustering을 사용하여 크기순으로 3개씩 나눠 사용하게 된다.
4) Feature Extractor
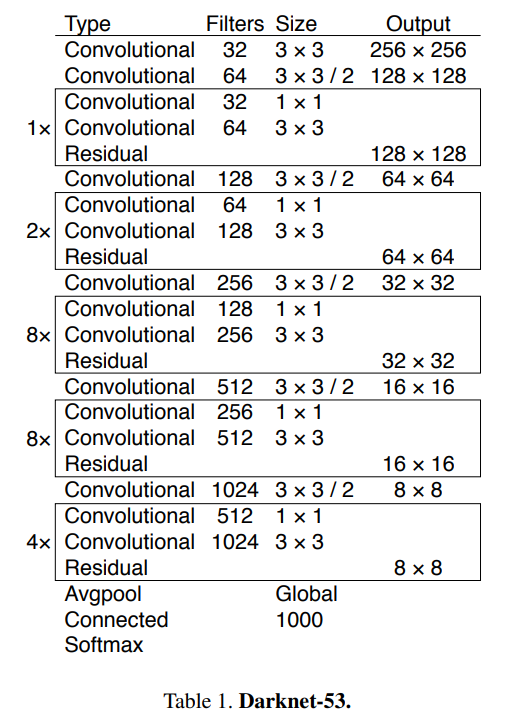
YOLO v3에서 사용된 feature extractor는 53개의 layer를 가지는 Darknet-53이다. Darknet-53은 과 conv layer로 이루어져있으며, shortcut connection을 사용한다.
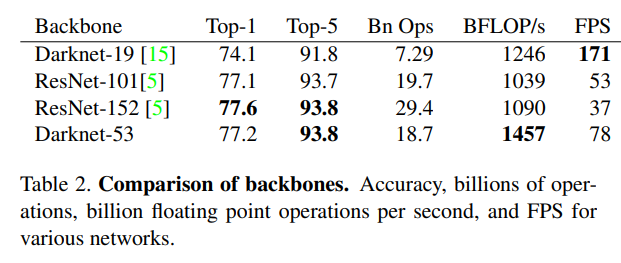
새로 제안된 Darknet-53이 이전 YOLO v2의 Darknet-19보다 성능면에서는 더 강력해지고, ResNet과 비슷한 성능을 내면서 효율적인 computation을 한다고 한다.
위 표를 보면 ImageNet Accuracy는 ResNet-152와 Darknet-53이 비슷한 성능을 보이고 있다.
BFLOP/s는 floating point operation per second로, Darknet-53이 GPU를 더욱 잘 활용하여 효율적이고 빠르다는 의미를 내포하고 있다.
Performance
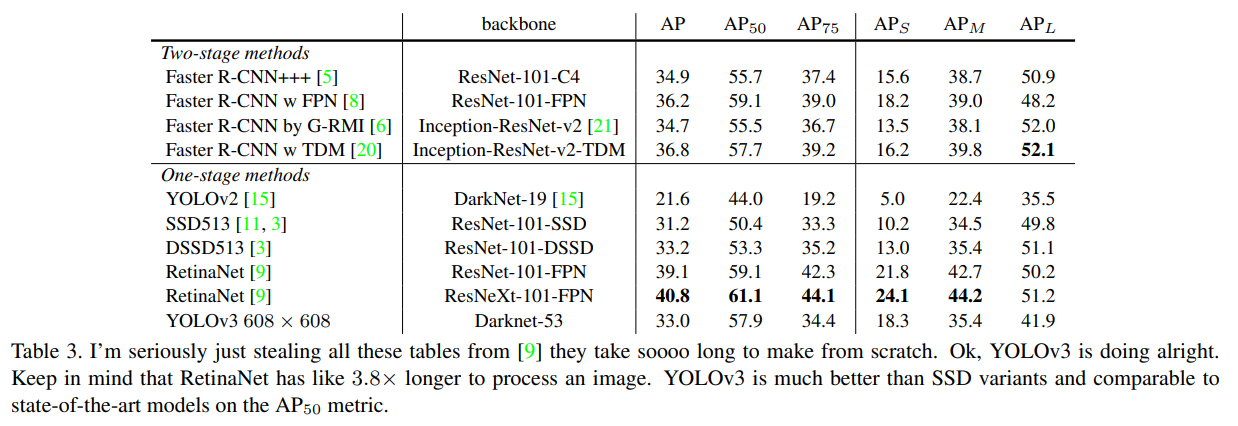
RetinaNet보다는 떨어지지만 준수한 성능을 보여주고 있다. 그리고 과거 YOLO 모델이 small object를 detect하지 못했던 문제에 비해서 multi-scale을 사용한 YOLO v3모델은 나름 잘 작동하는 것을 보여준다.
Thing We Tried That Didn't Work
재미있게도, 시도해봤지만 잘 작동하지 않은 방법론에 대해서도 논의를 하고 있다.
-
Anchor box x,y offset predictions
normal anchor prediction mechanism처럼 bbox의 x, y offset을 예측하는 방식을 적용했을 때 성능이 떨어졌다고 한다. -
Linear x,y prediction instead of logistic
logistic activation (sigmoid)를 안쓰고 직접 x, y offset을 계산하는 방식을 적용했을 때 성능이 떨어짐 -
Focal loss
RetinaNet에서 사용된 Focal loss를 사용했을 때는 성능이 오히려 떨어졌다고 한다. 저자는 YOLOv3가 objectness prediction과 conditional class prediction을 사용하기 때문에 Focal loss가 풀고자하는 문제에 대해 robust하기 때문이라고 예상했다. -
Dual IOU thresholds and truth assignment
Faster RCNN에서는 두 개의 threshold를 사용해서, IOU가 0.7보다 높은 example은 positive example로, [0.3,0.7]인 example은 무시하고, 0.3보다 낮은 example은 negative example로 두고 학습을 한다. 이러한 방식을 YOLO v3에 적용했을 때는 성능이 별로 좋지 ㅇ낳았다.
Discussion
YOLO v3만의 새로운 방법론을 통해서 성능을 향상시키지는 않았지만, 이런저런 실험을 통해 잘 발전시킨 모델을 내놓은 것 같다.
저자는 글의 마지막 부분에 컴퓨터 비전에 대한 도덕적인 견해도 기술해두었다.
“What are we going to do with these detectors now that we have them?”
