Paper : NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng / ECCV 2020)
- Motivation : View synthesis field에서 아주 중요한 논문이고, 최근 3D reconstruction 등에 관심이 생겨서 분석해보려 한다. 방법론 자체가 아주 novelty가 있고, medical image synthesis로 쉽게 확장될 수 있겠다고 생각했다.
NeRF project page에 들어가면 이게 무엇을 하는 것인지 intuitive하게 알 수 있다.
Short Summary
- 간단한 fully-connected neural network를 이용하여 novel view synthesis에서 아주 효과적인 방법을 제시한다.
- 하나의 object에 대하여 몇 가지 view image와 해당 view direction을 이용하여 continuous volumetric scene function을 최적화하는 방식을 사용한다.
- Train-inference 방식이 아니고, test-time optimization 방식이다.
Introduction
](https://velog.velcdn.com/images/shj4901/post/1a87448f-a062-4a14-8b8c-fa0642646f13/image.JPG)
figure from [https://developer.nvidia.com/discover/ray-tracing]
Terms
(1) View synthesis
View synthesis는 어떤 물체(object)를 서로 다른 관점(view)에서 촬영한 이미지를 가지고 새로운 관점에서 촬영했을 때의 모습을 합성하는 task이다. 이때, NeRF는 3D object를 완전히 reconstuction하는 task는 아니고, 이를 다른 view에 대해 projection했을 때의 이미지를 예측하는 task를 수행한다.
(2) Scene: scene은 우리가 view synthesis를 만드려고 하는 object라고 볼 수 있는데, NeRF에서는 이 scene을 3D 공간의 각 point에서 각 direction으로 방출되는 radiance와 그 point의 density를 출력하는 연속적인 함수로 정의한다. (이거 자체를 neural radiance field라고 볼 수도 있겠다.)
(3) View: view synthesis하려고 하는 object를 바라보는 view를 의미하며, 이 view는 3D object의 좌표에 대해 상대적인 좌표계를 가지고 있다.
(4) Radiance: 어떤 3D space내부 한 점의 RGB color value를 나타낸다. 이는 보여지는 view에 따라 달라질 수 있다.
(5) Density: 어떤 3D space내부 한 점의 opacity를 의미한다. 이는 그 point를 통과하는 ray에 의해 radiance가 얼마나 누적되는지를 control한다.
(6) Ray: 3D object를 바라보는 view에서 camera를 찍는다고 했을 때, camera hole로 부터 물체로 향하는 어떤 가상의 광선이다. Ray가 물체에 닿으면서 radiance가 누적된다고 이해했다. 뒤에 ray는 더 설명하려고 한다.
Overall approach

NeRF는 어떤 scene에 대해 50~100개의 input image를 이용하여 5D neural radiance field representation을 optimize하고, 새로운 view의 image를 rendering한다.
이때 neural radiance field function은 간단한 MLP로 이루어져 있으며, 3D voxel 좌표 ()와 카메라 view direction ()를 받아 그 voxel에서의 RGB value와 volume density ()를 출력한다. 3D 공간 point의 color와 density는 volume rendering을 통해 다시 2D pixel로 projection되어 새로운 view image를 생성한다.
이 모든 rendering 과정은 differentiable하기 때문에 gradient descent로 최적화가 될 수 있으며, 전체 voxel grids를 modeling하는 것에 비해서 storage cost effective하다고 한다.
Neural Radiance Field Scene Representation
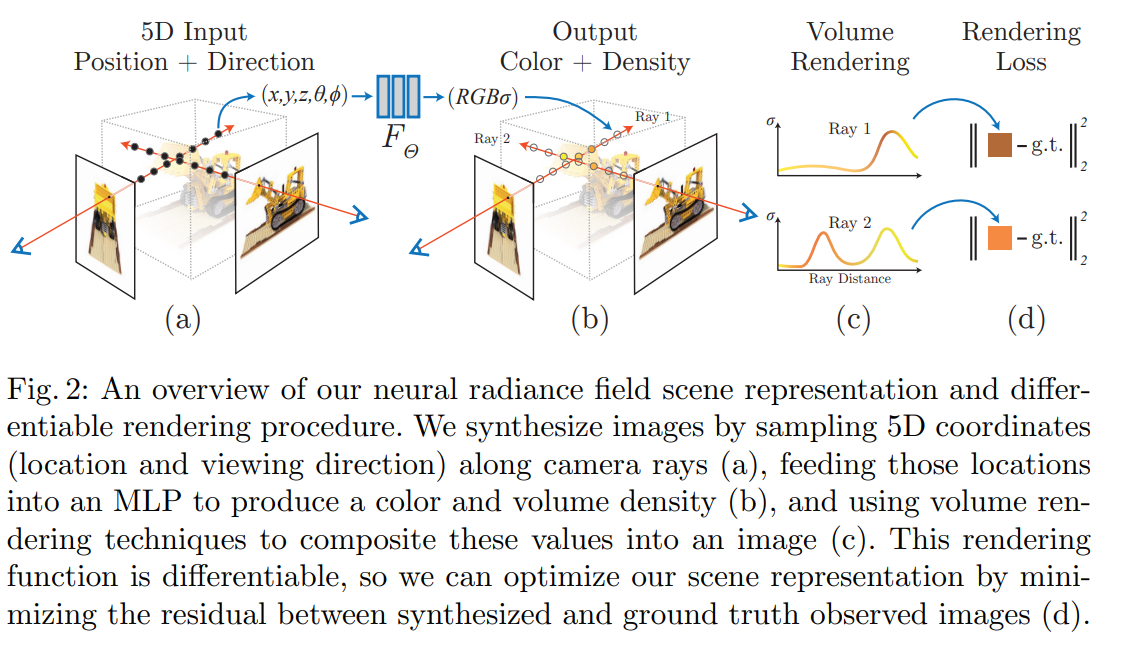
NeRF optimization에 대해서 조금 더 자세히 알아보자.
하나의 view에서 camera ray를 scene으로 march시켜 3D 공간의 point들을 sampling하고 (a), 이 points를 network에 넣어 color와 density를 출력한다 (b). 출력해낸 결과는 volume rendering을 통해 그 ray가 온 방향으로 다시 2D pixel로 투영되어 2D pixel의 RGB값을 구해내는데 사용된다 (c). 그러면 이 2D image의 pixel을 gt와 비교하여 학습할 수 있다 (d).
Rays
Ray는 카메라의 원점으로부터 object로 향해 나아가는 3차원 상의 직선이라고 할 수 있다.
이 가상의 광선은 원점에서 출발하여 object를 통과하게 되는데, 2D 이미지만을 사용하는 문제 상황에서 object의 3D 공간의 정보를 고려할 수 있게 되므로 매우 중요하다. 아래는 camera로부터 출발하는 ray를 간단히 도식화한 것이다.
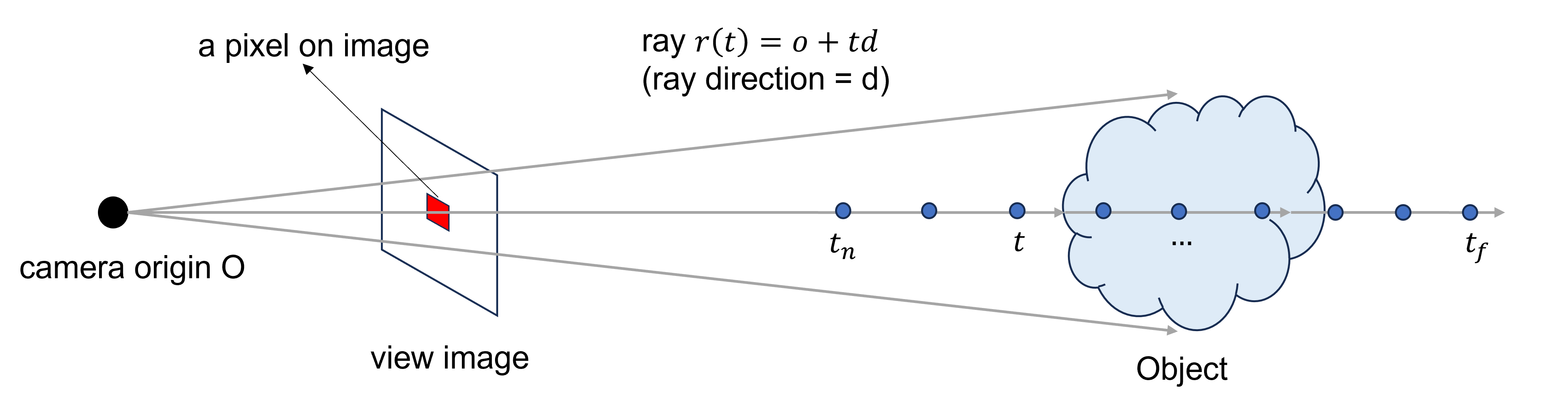
위와 같이 특정 view에서 얻은 2D image만 가지고 있는 상황에서 ray를 통해 object의 3차원 공간을 고려하게 된다. 정해진 ray direction 와 정해진 z-axis의 interval 를 통해 3차원 공간의 점들도 표현할 수 있다.
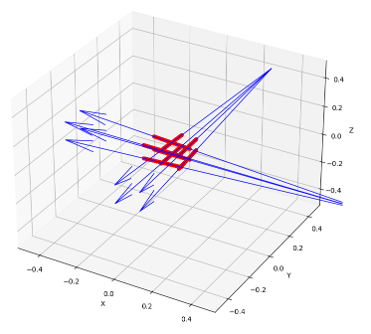
어떤 source로부터 출발하는 ray와 point들을 아래와 같이 3차원으로 그려볼 수도 있겠다. (90도를 회전해서 두 개의 ray를 그려본 것)
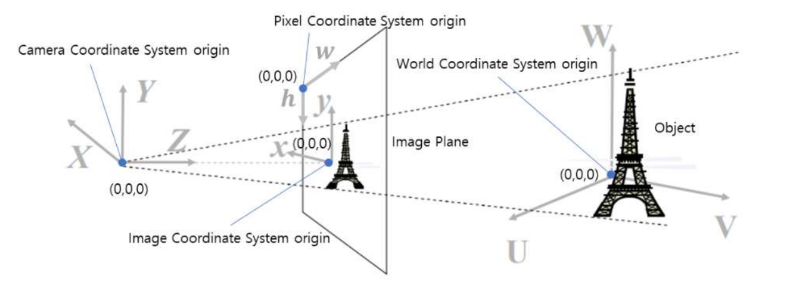
그리고 참고로 ray를 사용할 때에는 이 ray를 world coordinate system으로 바꾸어서 사용해야한다. 이는 같은 origin과 같은 direction을 갖는 직선일지라도 내가 사용하는 coordinate에 따라서 표현하는 방식이 달라지기 때문이다. 이를 camera coordinate로 사용하면 각각 view마다 그 좌표가 정의되어야 하므로 scene의 함수를 학습하기 어려울 것이다. Coordinate 변환은 camera parameters (extrinsic/intrinsic parameter)를 이용한 matrix multiplication으로 가능한데, extrinsic matrix는 world coordinate에서 camera coordinate로의 3D->3D 변환이고, intrinsic matrix는 camera coordiante에서 pixel coordinate로의 3D->2D 변환이다. 이러한 개념은 자세히 잘 설명되어 있는 곳이 많으니 참고하면 좋겠다. 나도 공부가 더 필요하다. 실제로 구현할 때에는 input image의 meshgrid로부터 시작하며(pixel coordinate), 이미지의 중심으로 원점을 바꿔주고(image coordinate) focal length로 scaling하고 (camera coordinate), extrinsic matrix의 rotation과 translation으로 world coordinate의 직선 (ray)와 point를 도출한다.
Neural Radiance Field
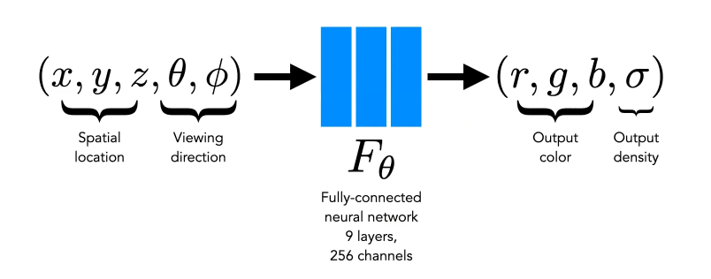
NeRF network 자체는 위와 같이 아주 간단한 function이다.
- Input: 한 point의 spatial location과 viewing direction
- Output: 그 point의 color와 density
이때, point의 spatial location은 3D space에서 그 point의 위치, viewing direction은 카메라가 어디서 보고있는지를 의미한다. Color는 그 점에서의 RGB value이고, density는 얼마나 그 점이 얼마나 dense하게 차있는지를 나타내는 값이라고 볼 수 있겠다. (density=0이면 그 곳에는 아무것도 없다.)
이를 optimize하기 위해 한 scene에서 여러 개의 view image에서 ray를 sampling하고, ray에서 point를 sampling해서 그 point들을 network에 넣어준다.
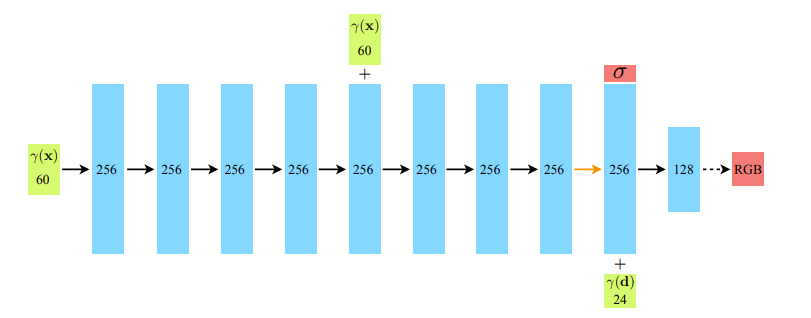
이러한 NeRF function은 사실 매우 간단한 MLP로 구성되어 있다.
여기서 는 view direction, 는 3D spatial location이다.
그림에서도 보면 알 수 있듯이 view direction은 density를 구한 다음에 입력되는데, 이는 view direction은 오직 RGB값을 구하는데에만 영향을 끼치고, 3D space내에서 한 점의 density는 하나의 spatial location에서 consistent하다는 개념이 반영되어 있다.
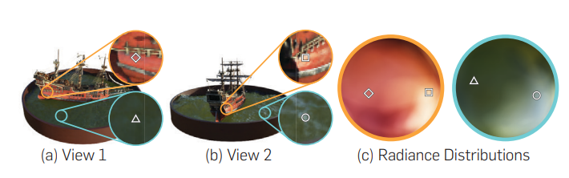
NeRF paper의 figure에서 볼 수 있듯이, 이렇게 design했을 때, 같은 점이라도 다른 view에서 보이는 RGB value가 다르다는 것을 확인할 수 있다.
Volume Rendering
Origin으로부터 출발한 ray가 scene을 지나면, 그 ray 직선을 따라 point를 sampling할 수 있다. 그리고 각 point 좌표와 viewing direction을 통해 color와 density를 구해낼 수 있었다.
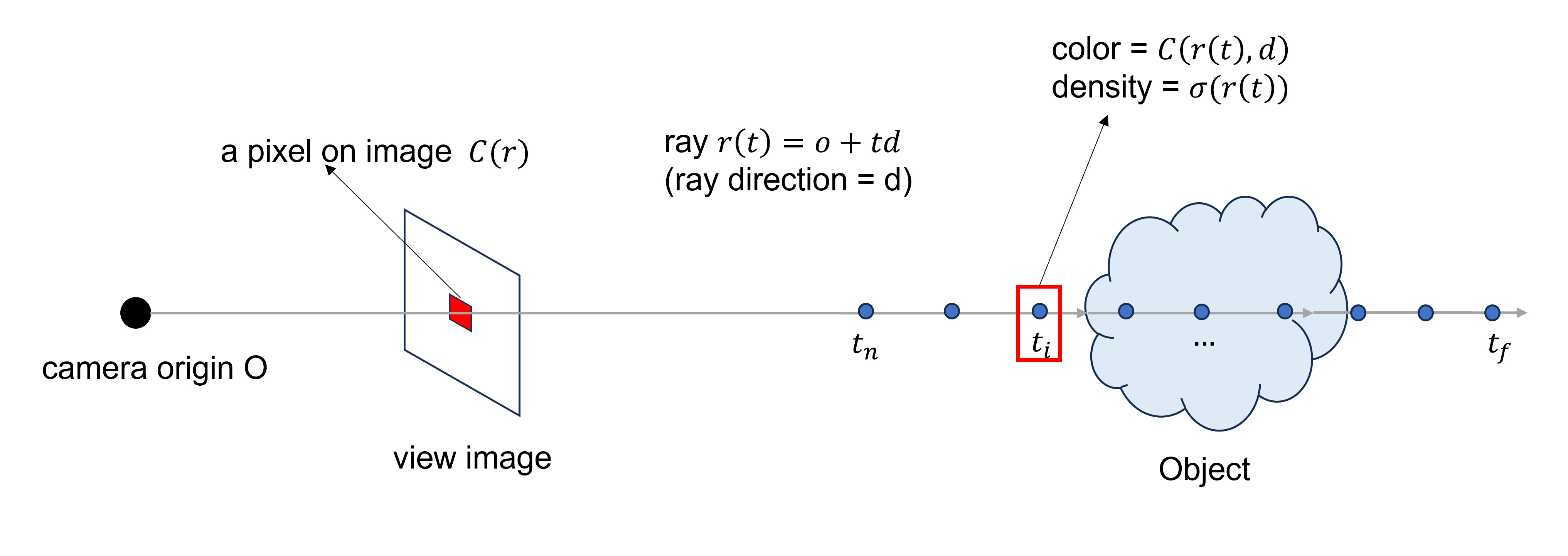
그럼 이제 우리는 그 ray를 통해 2D image에 맺히는 pixel값을 도출해낼 수 있다.
위에서도 언급했지만 Color는 3D space의 한 점에서 각 방향으로 방출되는 radiance, density는 3D space자체의 dense한 정도로, 해당 점에 아주 작은 미소 공간을 ray 막힐 확률로도 생각할 수 있다.
3D 공간에 있는 어떤 물체에 ray를 쏜다고 해보자. 물체 주변에 비어있는 공간 (공기층?)은 ray가 쭉쭉 통과할 것이므로, 그 공간의 point의 color는 이미지 상 pixel의 값에 영향을 주지 못할 것이다. 반면에 물체에 정면으로 들어간 ray는 물체에 부딪혀 뒤까지 닿지 못할 것이다. 대신에 그 물체의 앞에 있는 pixel이 이미지 상에 보이는 pixel value과 비슷하게 될 것이다.
Volume rendering은 opacity의 개념을 가지고 있다. 앞의 pixel에 가려진 뒤의 pixel의 rgb value가 실제 보이는 view의 pixel에 끼치는 영향은 적을 수밖에 없다는 것이다.
near boundary point 와 far boundary point 를 갖는 하나의 ray 의 expected color 는 아래와 같이 구해질 수 있다.
여기서 는 accumulated transmittance, 즉 투과율을 의미하며, 가까운 near point로부터 까지 ray가 얼마나 잘 통과하는지를 나타낸다.
항을 보면 near points의 density의 누적값이 커지면 커질수록 투과율을 작아지게 된다. 앞에 물체에 의해 가려지면 가려질수록 pixel rgb값에 영향을 덜 준다는 것이다.
항도 마찬가지로 density가 커질수록 그 rgb의 영향이 커지고, 작아질수록 그 영향이 작아지게 만들어져 있다.

예를 들어 다음과 같은 ray가 있다고 하면,
와 에서 density가 0이기 때문에 ray는 그냥 통과하고, 에 영향을 주지 못한다.
에서 density가 0.5이기 때문에 만큼의 RGB값이 에 반영된다.
에서 density가 1이기 때문에 더 많은 영향을 주지만, 그 영향은 만큼 감쇠되어 반영된다.
Rendering Loss

최종적으로는 volume rendering을 통해 구한 이미지 상의 pixel값과 실제 그 위치의 pixel값의 차이로 loss를 구하고 optimize시킨다.
여기서 은 각 batch에 들어간 ray집합으로 한 이미지 view에서 4096개의 ray를 추출하고, ray마다 192개의 3D points를 sampling해서 사용한다.
Optimizing NeRF
추가적으로 view synthesis 결과를 향상시키기 위해 사용한 기법을 두 가지 정도 간단히 소개하고 넘어가도록 하자.
Voxel sampling
ray에서 3D voxel을 추출할 때, 매번 미리 정의된 point에 대해서 계산을 한다면, static scene에 대한 continuous function을 학습하기가 어려울 것이고 그러면 좋은 resolution의 결과를 추출하기 어려울 것이다. 그렇다고 random sampling을 하면 ray가 object를 지나가는 데 있어서 공간에 대한 정보를 최대한 활용하기가 어려울 것이다.
이러한 문제를 해결하기 위해 이 논문에서는 stratified sampling strategy를 사용하였는데, 단순히 near point와 far point사이를 미리 정의된 갯수의 bin으로 나누고 그 bin 안에서 random으로 하나를 무조건 추출하도록 했다.

이러한 sampling을 이용해 1차적으로 coarse training을 하고, 중요한 부분에 대해 2차적으로 fine sampling을 통해 fine training을 한다고 하는데, 여기에선 더 다루진 않겠다.
Positional Encoding
Nerf network는 input으로 3D point 좌표를 받는데, 직접적으로 )를 넣어주면 high-frequency color variation과 geometry를 표현하는데 한계가 있다고 한다. 그래서 input을 더 높은 dimension space로 mapping해줄 필요가 있었고 이를 위해 frequency encoding을 사용하였다.
각 point location과 view direction을 아래와 같이 더 높은 dimension으로 바꾸어서 네트워크에 넣어 학습하면 훨씬 fine한 detail을 추출할 수 있다고 한다.
위와 같은 문제 설정과 해결 방안 (frequency encoding)에 대한 내용은 아래 논문에 아주 자세하게 어렵게 설명되어있다.
Rahaman, Nasim, et al. "On the spectral bias of neural networks." International Conference on Machine Learning. PMLR, 2019.
Inference

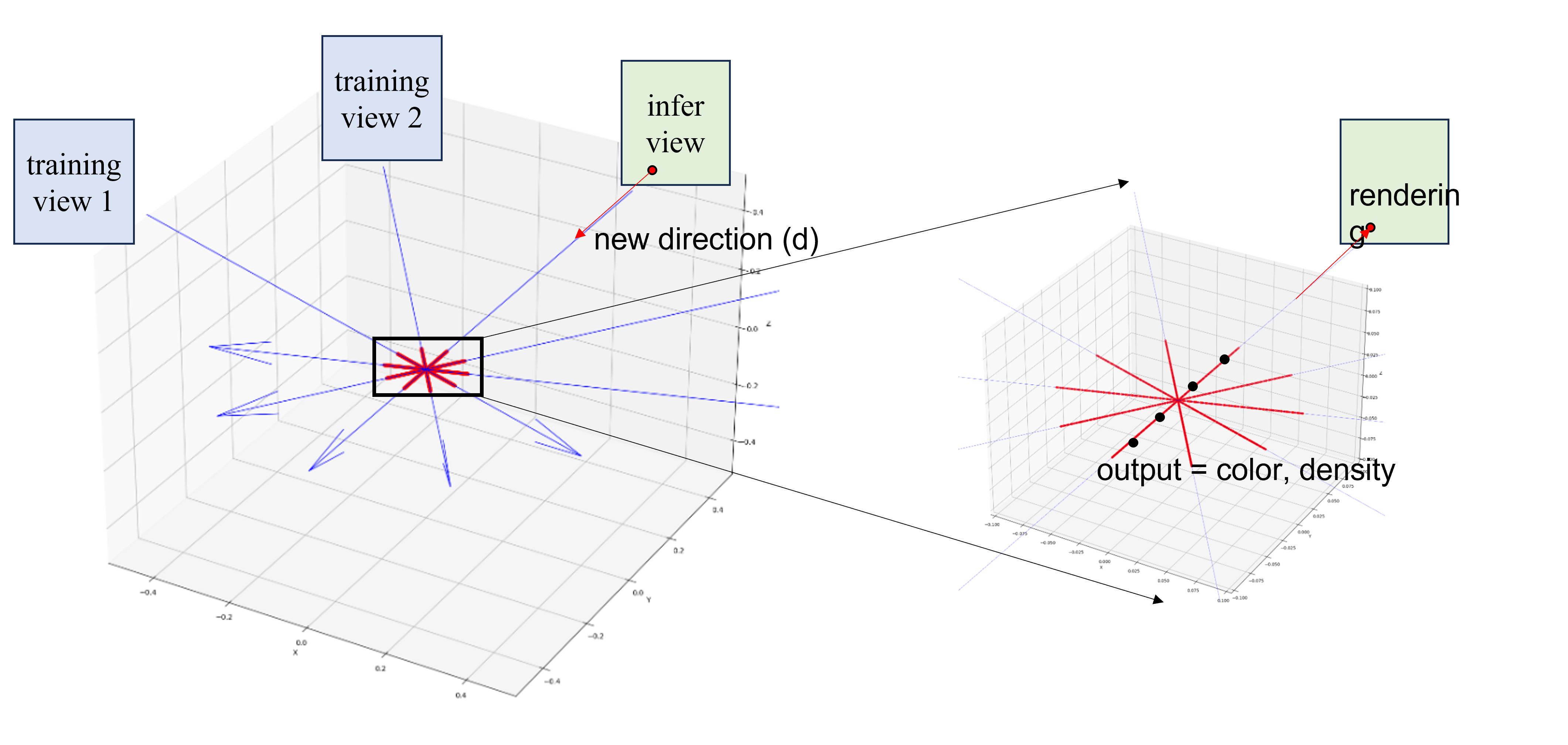
하나의 scene에 대해 많은 view를 training set으로 보여주어 network를 optimize한 뒤에는 새로운 view direction을 query하여 새로운 view를 만들어낼 수 있다.
View direction을 이용하여 똑같이 ray를 만들어내고, point를 추출하여 network에 넣어서 color, density를 구한다음에 volume rendering으로 해당 위치의 pixel value를 얻어낸다.
Results
성능 비교를 위한 metric으로는 SSIM(Structural Similarity Index Map), PSNR(Peak Signal-to-noise ratio)와 LPIPS(Learned Perceptual Image Path Simiarlity)가 사용됬다.

Novel view synthesis task를 수행하는 다른 method들과 그 성능을 비교했다. 위의 다른 method도 다 비교적 최신에 진행된 연구인 것 같았는데, NeRF가 SOTA라고 한다.


Qualitative result를 보면 확실히 NeRF로 만든 view synthesis가 더 fine detail을 잘 표현한 것을 확인할 수 있다.
Opinion
View synthesis field에 관련되어서 처음으로 접한 논문이었고, 아주 재밌게 읽은 논문이다. Camera pose나 ray, volume rendering에 대한 개념들이 생소해서 처음에는 이해하기가 조금 어려웠는데, 이해하고 나니까 아주 간단하고 강력한 method를 잘 만든 것 같다는 생각을 했다. Result에서 비교된 기존의 연구들은 3D Volume feature을 decoding하여 사용하거나, RNN 구조로 3D ray 상의 point value를 rendering하는 등의 내용이 있는 것 같은데, 다른 방법들도 공부해볼 필요가 있을 것 같다.
이러한 NeRF의 개념을 추후에 medical image에도 적용시켜볼 예정이다. 가령 몇 개의 X-ray image (PA, AP, Lateral images)를 이용해 찍지 않은 각도에서의 X-ray image(oblique images)를 합성해내는 등의 기술을 생각해볼 수 있다. 더 나아가 환자를 기준으로 source와 detector가 회전하면서 촬영하는 Computed radiography를 생각하면 이러한 X-ray image를 이용하여 3D CT reconstruction을 생각해볼 수도 있을 것 같다. 그러면 이러한 3D volume을 DRR (Digital Reconstructed Radiograph)을 통해 projection 시킴으로써 새로운 view를 얻어낼 수도 있다. 실제로 이러한 관점으로 접근한 연구들이 종종 있는 것 같다. 물론 Camera를 촬영하는 것과 X-ray를 촬영하는 것 자체는 image acquisiton process가 많이 다르기 때문에 네트워크를 조금 다르게 설계해야할 수는 있겠지만, 오히려 NeRF에서 사용되는 ray peneration과 volume rendering의 개념은 X-ray photon이 object를 통과하면서 attenuation되는 개념과 상당히 닮아있다는 것을 알 수 있다. 고민해볼만한 가치가 있는 것 같다.
NeRF는 training & inference의 frame을 갖는 feed-forward식의 generalized network의 개념은 아니고, test-time optimization network라고 할 수 있다. 즉, 하나의 scene를 view-synthesis task를 위한 network가 하나씩 필요하다는 것이다. 어떻게 보면 여러 가지 scene에 대한 데이터 없이 하나의 scene으로 네트워크를 최적화할 수 있다는 점에서 self-supervised라고 말할 수도 있을 것 같고 반면에 one scene optimization은 어떠한 prior도 없이 네트워크를 학습시켜야한다는 단점을 가지고 있다. 그렇기 때문에 network optimization에 데이터가 많이 든다 (거의 100장 정도의 view를 사용하는 것 같다). 그런데 이 정도로 많은 view는 real application에서는 거의 불가능할 정도의 양이라서 이러한 단점을 addressing하려는 연구도 이 뒤로 엄청 많이 나오고 있다.
가장 중요한 개선은 아마 네트워크에게 prior를 주는 것이 아닐까 싶다. 다음으로는 네트워크에게 이러한 view synthesis task에 대한 prior를 주는 아래의 방법론들을 공부해보려고 한다.
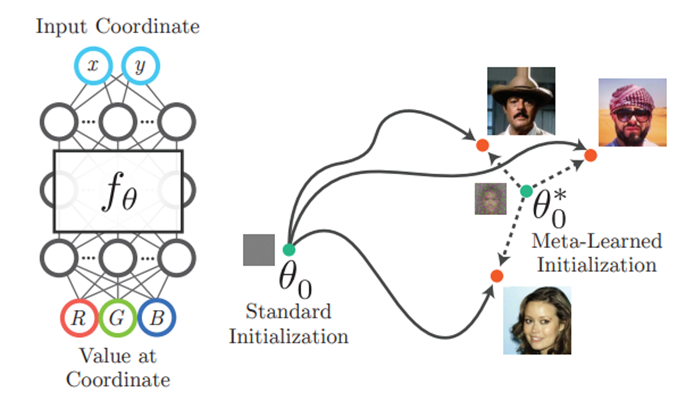
1) 네트워크를 random initializtion에서부터 training을 하는 것이 아니고 meta-learning 방식을 도입하여 비슷한 scene을 view synthesis하는 task의 network들을 학습하여 learned initialization을 사용하는 방법. (예를 들어서 사람 얼굴의 view synthesis를 한다고 가정하면 대충 얼굴의 형태 (머리, 눈, 코, 입) 정도에 대한 정보를 미리 가지고 있는 pretrained network를 만드는 것)
Learned Initializations for Optimizing Coordinate-Based Neural Representations

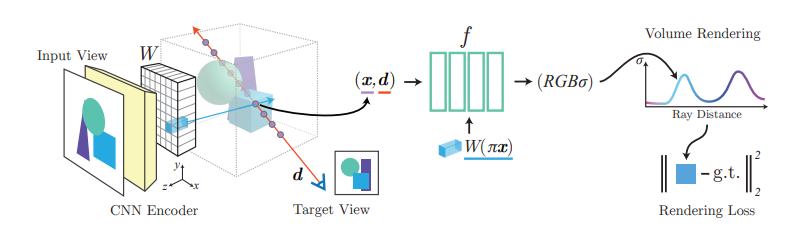
2) 네트워크에게 2D image feature를 같이 input으로 넣어주어서 image와 view에 대한 conditioning을 부여하는 방법. (예를 들어서 10도, 20도, 30도의 input view가 주어졌을 때, 40도의 view는 보통 어떻게 mapping되어야 하는지 여러 scene을 하나의 network로 학습시켜서 image prior를 부여)
pixelNeRF: Neural Radiance Fields from One or Few Images

재미있겠다.
