Paper : [Simple online and realtime tracking with a deep association metric] (https://arxiv.org/pdf/1703.07402 (Nicolai Wojke, Alex Bewley, Dietrich Paulus / IEEE ICIP 2017)
Multi-object tracking 기술의 근간이 되는 SORT와 이를 발전시킨 DeepSORT에 대해서 공부해보려 한다.
Highlights
- Appearance 정보를 SORT에 결합함으로써 성능을 향상시킴 (이때 딥러닝 네트워크인 re-identification model이 활용됌)
- Occlusion에 더 잘 대응하게 되었고, identity switch를 효율적으로 감소시킴
Introduction
- Tracking-by-Detection : multi-object tracking 방법론 중 하나로, detection model을 활용하여 각 frame마다 object를 detect하고, 여러 frame에 걸쳐 이 detection들을 연관시키는 작업을 통해 tracking하는 방식.
SORT
- Motivation : 이전의 tracking-by-detection 알고리즘들은 computational cost나 implementation complexity 등의 문제가 많아 real-time application에 부적합했다.
- Methodology :
SORT는 image space에서kalman filter를 사용하며, bounding box overlap (IOU)을 측정하는association metric을 활용한hungarian method를 사용하여 각 frame data를 연관짓는 방법을 제안하였다. - Advantage : high frame rate에서 잘 작동하며, tracking precision과 accuracy를 많이 향상 시킬 수 있었다.
- Limitation : 하지만 SORT는 state estimation uncertainty가 낮을 때만
association metric이 정확하하므로, identity switch가 상대적으로 빈번했고, occlusion에 취약하다는 단점을 가지고 있다.
DeepSORT 는 이러한 문제를 해결하기 위해 motion과 appearance 정보가 포함된 association metric을 활용하였다. 특히, person re-identification dataset을 통해 학습된 딥러닝 네트워크를 활용하여 이 정보를 추출하도록 하였다.
Kalman filter
-
kalman filter는 bayes filter의 한 예로, recursive한 prediction과 correction을 통해 state를 예측하는 방법 -
알고리즘을 매우 간단하게 써보려면 이렇게도 쓸 수 있을 것 같다.
prev_mean, prev_cov: 이전 step의 statemea: correction을 위한 측정 값 (예를 들면 센서 측정값)known_noise: prediction model이나 sensor의 noise를 의미kalman_gain: prediction과 measurement사이의 중요도를 결정해주는 factorcorrected_mean, corrected_cov: correction된 예측값 → 현재 step의 optimal state estimation으로, 다음 step의 state input으로 활용
Kalman_filter(prev_mean, prev_cov, mea):
pred_mean, pred_cov = predict(prev_mean, prev_cov)
kalman_gain = function_of(pred_cov, known_noise)
corrected_mean, corrected_cov = weighted_sum(pred_mean, mea, kalman_gain)
curr_mean, curr_cov = corrected_mean, corrected_cov
return curr_mean, curr_covMethodology
Track Handling and State Estimation
DeepSORT에서는 각 tracking object의 state를 8차원의 state space에서 표현한다.- 는 bounding box의 center position
- 는 aspect ratio
- 는 height
- 나머지는 각각의 velocity를 의미한다.
- Constant velocity motion과 linear observation model을 가정하는 standard kalman filter 사용
- 이때, linear observation model은 bounding box coordinate 을 직접적으로 관측하는 모델 (detection model의 output을 쓸 것이므로)
Track의 소멸과 생성
-
각
track(하나의 tracking target의 경로? 라고 하자)마다 last successfulmeasurement association로부터의 frame 수를 기록한다. (kalman filter에서 prediction을 할 때마다 1씩 증가하고, measurement와 association되면 0으로 reset되는 counter) -
사전 정의된 파라미터인
maximum age가 넘는 track은 해당 scene (혹은 frame)을 벗어났다고 판단하여 track set에서 삭제한다. -
기존의 track과 association될 수 없는 각 detection (혹은 measurement)은 새로운 track으로 initialize된다.
-
이때, 첫 3개의 frame 동안 measurement association이 성공적으로 완수되면, 새로운 track으로 등록, 아니면 삭제
Assignment problem
-
Assignment problem은 조합 최적화 문제로, 어떠한 비용을 최소화 하도록 각 agent (~kalman filter state)를 각 task (~measurement)에 할당하는 문제. 즉, frame 마다 검출되는 bounding box와 kalman filter를 통해 추적하고 있는 객체가 동일하다는 것을 판별해주는 과정을 assignment problem이라고 할 수 있다.DeepSORT에서는Hungarian algorithm를 사용한다. -
이때,
DeepSORT는 motion 정보와 appearance 정보를 적절한 metric를 사용해 결합하여 assign한다.
Motion 정보 integration
- 먼저, motion 정보를 결합하기 위해, Kalman filter state와 새로 얻어진 measurement사이의
Mahalanobis distance를 사용한다.
Mahalanobis distance는 어떤 점으로부터 어떤 분포까지의 거리를 의미하며, 평균 과 positive semi-definite covariance 를 가지는 확률 분포 가 주어졌을 때 로부터 의 거리를 아래와 같이 표현한다.
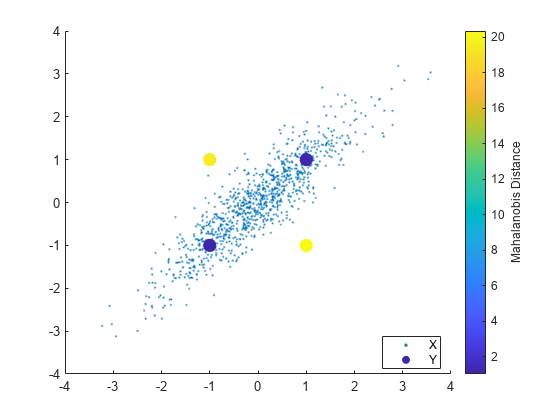 출처: https://kr.mathworks.com/help/stats/mahal.html
출처: https://kr.mathworks.com/help/stats/mahal.html
- 특히, 이 distance는 covariance로 normalize된 distance이기 때문에, data 분포의 spread와 orientation을 고려한다.
- 이러한 normalization은 더 높은 variance를 가지는 direction이 distance에 덜 기여하고, 작은 variance를 가지는 direction이 distance에 더 기여할 수 있도록 해준다.
- 예를 들어, 위 figure에서 Y 관측값은 X로부터 모두 같은
euclidean distance에 있지만,mahalanobis distance는 노란색이 더 크다.
DeepSORT에서는 squared distance를 사용하며, 번째 track distribution을 measurement space로 projection 시킨 것을 로 표현하고, 번째 bounding box를 로 표현한다.
→ 이렇게 하면, Mahalanobis distance는 mean track location으로부터 detection이 얼마나 떨어져 있는지를 측정함으로써 state estimation의 uncertainty를 고려할 수 있게 된다.
→ 추가적으로, 이러한 metric을 사용하면, inverse 분포로부터 95% 신뢰구간을 선정하여 불필요한 association들을 제외할 수 있다. (번째 track과 번째 box가 연관이 있는지 결정하는 indicator)
Appearance 정보 integration
-
여기서 한가지 더 고려할 점은 camera motion으로 인해 image plane 상에서 rapid displacement가 발생할 수 있다는 것이다.
-
DeepSORT에서는 이를 해결하기 위해 assignment problem에 두번째 metric으로 appearance를 고려하였다. -
각 bounding box detection 에 대해
appearance descriptior()를 계산한다. -
추가적으로 각 track 마다 개의
appearance descriptor를 보관하는 gallery 를 둔다. -
그리고 appearance metric은 번째 track과 번째 detection의 appearance space 상에서 가장 작은 cosine distance로 한다.
- 마찬가지로 해당 metric에 대해서도 thresholding을 통해 association이 valid한지 check한다.
-
Appearance descriptor를 구하기 위해서는 pretrained CNN을 활용하였다.
-
최종적으로는 assignment problem을 풀기 위해 위의 두 metric을 합쳐서 활용한다.
Mahalanobis distance는 object의 motion에 기반하여 가능한 object의 위치에 대한 정보를 주므로, short-term prediction에서 유용하다.Cosine distance는 appearance 정보를 활용하므로 motion이 큰 의미를 갖지 않는 long-term occlusion 상황에서 identity를 다시 찾아내는데 유용하다.
-
두 metric의 weighted sum으로 assignment problem의 cost를 정의
- 이때, association이 받아들여질 지는 위에서 정의했던 두 metric의 indicator가 둘 다 만족할 때로 한다.
- 각 metric의 영향은 hyperparameter인 로 정할 수 있다.
- 실제로 실험 결과, 저자들은 camera motion이 많은 경우 으로 설정하는 것이 합리적이라고 했는데, 이때 association cost term으로는 appearance만 사용되지만, Mahalanobis distance도 indicator를 통해 고려된다고 한다.
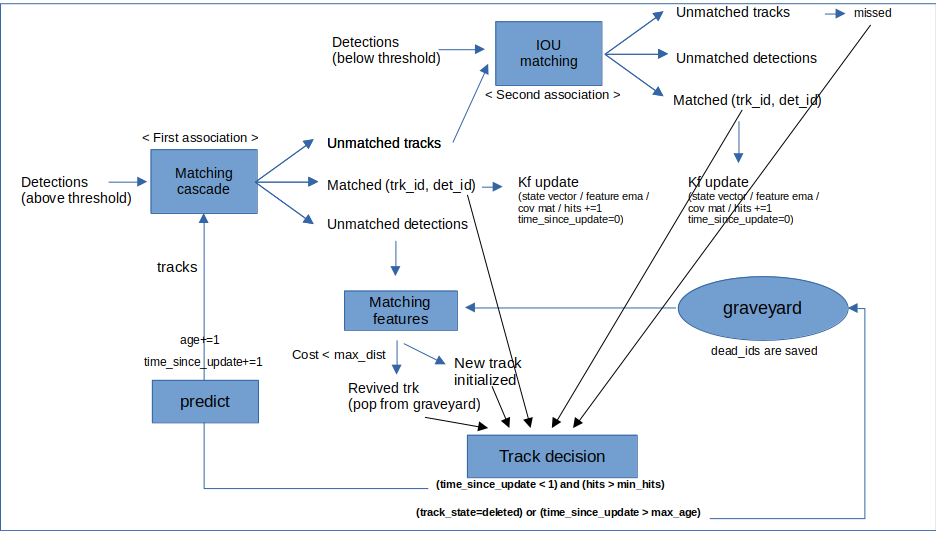
Matching Cascade
DeepSORT에서는 measurement-to-track association problem을 풀기 위해 cascade matching 방식을 택했다.
Cascade matching의 motivation
- 예를 들어, 한 object가 꽤 오랜 시간 가려졌다고 해보자.
- 그러면 correction할 수 있는 measurement가 없기 때문에 kalman filter prediction의 uncertainty가 높아질 것이다.
- uncertainty가 증가함에 따라 state space에서 position prediction의 분포가 spread out
- 직관적으로는 association metric이 이러한 분포의 퍼짐을 고려해서 measurement-to-track distance가 증가해야 한다.
- 하지만 직관과는 다르게, covariance가 커지면, mahalanobis distance의 공식 상 covariance의 inverse는 작아지게 된다. 즉, normalized distance 값이 작아지게 된다.
- 그 말은 두 개의 track이 하나의 detection을 가지고 경쟁하게 되면 algorithm은 uncertainty가 더 큰 쪽을 선택하게 된다.
- 이렇게 되면 더 uncertain한 track이 해당 detection에 assign될 확률이 높다는 것이고 이는 이상적인 상황이 아니다.
→ 더 자주 보이는 object에게 우선권을 주는 방식을 택함
Matching algorithm

- track과 detection의 index set, 그리고 maximum age를 input으로 받는다.
- line 2: Assignment problem에서 정의한 association cost matrix를 계산
- line 3: motion과 appearance를 고려해서 각각의 space에서 계산한 distance를 thresholding 쳐서 얻어낸 gating (채택할 것인지 말 것인지 결정) matrix를 계산
- line 4 : matches & unmatched detection을 초기화
- line 5~9 : 정해진 age 만큼 iterate 하면서 linear assignment problem을 푼다.
- line 6 : 최근 n개의 frame동안 detection box와 associate 되지 않은 track subset 을 추출
- line 7 : 과 unmatched detection 를 이용해 linear assignment 수행
- line 8 & 9 : matchs & unmatched detection을 update
** 여기서 중요한 점은 matching cascade가 age가 더 작은 track (더 최근에 보인 track)에게 priority를 부여한다는 것이다.
- Matching이 다 끝난 후에는 SORT와 같이 IOU association을 수행하여, unconfirmed, unmatched track을 구분한다.
Deep Appearance Descriptor
- 양질의 appearance feature를 추출하기 위해 1,100,000개 이상의 사람 이미지를 포함하는 re-identification dataset으로 pre-train한 deep learning 모델을 사용했다.
- 네트워크 구조는 아래와 같다.
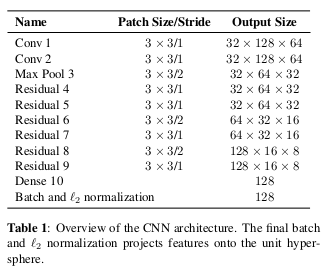
- 사실 feature extractor는 어떤 것이든 잘 학습된 거 가져다 쓰면 될 것 같다.
Experiments
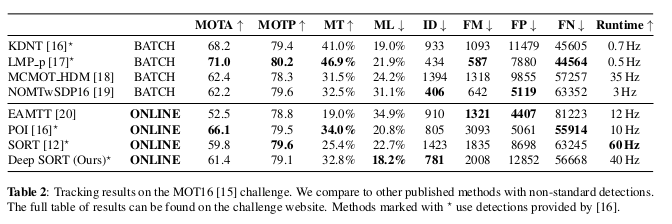
- 실험을 위해서는 을 사용하였다.
- 위 표에서 각 evaluation metric에 대한 정보는 아래와 같다
- MOTA : overall tracking accuracy
- MOTP : overall tracking precision in terms of bbox overlap
- MT : 적어도 80% 이상 같은 label을 유지한 track의 percentage
- ML : 최대 20% 동안 track에 성공한 track의 percentage
- ID : identity가 바뀐 경우의 수
- FM : detection을 놓쳐서 track을 하지 못한 경우의 수
Code analysis
ref: https://github.com/nwojke/deep_sort/blob/master/deep_sort/track.py
Run
- frame이 연속적으로 들어온다고 했을 때, tracker는 간단하게
detection→prediction→update로 작동한다.
def frame_callback(vis, frame_idx):
print("Processing frame %05d" % frame_idx)
# Load image and generate detections.
detections = create_detections(
seq_info["detections"], frame_idx, min_detection_height)
detections = [d for d in detections if d.confidence >= min_confidence]
# Run non-maxima suppression.
boxes = np.array([d.tlwh for d in detections])
scores = np.array([d.confidence for d in detections])
indices = preprocessing.non_max_suppression(
boxes, nms_max_overlap, scores)
detections = [detections[i] for i in indices]
# Update tracker.
tracker.predict()
tracker.update(detections)
Tracker class
- tracking process를 총괄하는 class이다.
- 매 frame마다 현재 정의되어 있는 모든 track에 대해 prediction & update를 수행하게 된다.
class Tracker:
"""
This is the multi-target tracker.
Parameters
----------
metric : nn_matching.NearestNeighborDistanceMetric
A distance metric for measurement-to-track association.
max_age : int
Maximum number of missed misses before a track is deleted.
n_init : int
Number of consecutive detections before the track is confirmed. The
track state is set to `Deleted` if a miss occurs within the first
`n_init` frames.
Attributes
----------
metric : nn_matching.NearestNeighborDistanceMetric
The distance metric used for measurement to track association.
max_age : int
Maximum number of missed misses before a track is deleted.
n_init : int
Number of frames that a track remains in initialization phase.
kf : kalman_filter.KalmanFilter
A Kalman filter to filter target trajectories in image space.
tracks : List[Track]
The list of active tracks at the current time step.
"""
def __init__(self, metric, max_iou_distance=0.7, max_age=30, n_init=3):
self.metric = metric
self.max_iou_distance = max_iou_distance
self.max_age = max_age
self.n_init = n_init
self.kf = kalman_filter.KalmanFilter()
self.tracks = []
self._next_id = 1
def predict(self):
"""Propagate track state distributions one time step forward.
This function should be called once every time step, before `update`.
"""
for track in self.tracks:
track.predict(self.kf)
def update(self, detections):
"""Perform measurement update and track management.
Parameters
----------
detections : List[deep_sort.detection.Detection]
A list of detections at the current time step.
"""
# Run matching cascade.
matches, unmatched_tracks, unmatched_detections = \
self._match(detections)
# Update track set.
for track_idx, detection_idx in matches:
self.tracks[track_idx].update(
self.kf, detections[detection_idx])
for track_idx in unmatched_tracks:
self.tracks[track_idx].mark_missed()
for detection_idx in unmatched_detections:
self._initiate_track(detections[detection_idx])
self.tracks = [t for t in self.tracks if not t.is_deleted()]
# Update distance metric.
active_targets = [t.track_id for t in self.tracks if t.is_confirmed()]
features, targets = [], []
for track in self.tracks:
if not track.is_confirmed():
continue
features += track.features
targets += [track.track_id for _ in track.features]
track.features = []
self.metric.partial_fit(
np.asarray(features), np.asarray(targets), active_targets)
def _match(self, detections):
def gated_metric(tracks, dets, track_indices, detection_indices):
features = np.array([dets[i].feature for i in detection_indices])
targets = np.array([tracks[i].track_id for i in track_indices])
cost_matrix = self.metric.distance(features, targets)
cost_matrix = linear_assignment.gate_cost_matrix(
self.kf, cost_matrix, tracks, dets, track_indices,
detection_indices)
return cost_matrix
# Split track set into confirmed and unconfirmed tracks.
confirmed_tracks = [
i for i, t in enumerate(self.tracks) if t.is_confirmed()]
unconfirmed_tracks = [
i for i, t in enumerate(self.tracks) if not t.is_confirmed()]
# Associate confirmed tracks using appearance features.
matches_a, unmatched_tracks_a, unmatched_detections = \
linear_assignment.matching_cascade(
gated_metric, self.metric.matching_threshold, self.max_age,
self.tracks, detections, confirmed_tracks)
# Associate remaining tracks together with unconfirmed tracks using IOU.
iou_track_candidates = unconfirmed_tracks + [
k for k in unmatched_tracks_a if
self.tracks[k].time_since_update == 1]
unmatched_tracks_a = [
k for k in unmatched_tracks_a if
self.tracks[k].time_since_update != 1]
matches_b, unmatched_tracks_b, unmatched_detections = \
linear_assignment.min_cost_matching(
iou_matching.iou_cost, self.max_iou_distance, self.tracks,
detections, iou_track_candidates, unmatched_detections)
matches = matches_a + matches_b
unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))
return matches, unmatched_tracks, unmatched_detections
def _initiate_track(self, detection):
mean, covariance = self.kf.initiate(detection.to_xyah())
self.tracks.append(Track(
mean, covariance, self._next_id, self.n_init, self.max_age,
detection.feature))
self._next_id += 1- 각 track은
self.tracks리스트에 저장되어 있다. predict는 각 track object 내의 predict를 통해 수행된다.update에서는 해당 frame에서 검출된 detection과 현재 track들과 cascade matching을 수행하고,matches,unmatched_tracks,unmatched_detections로 구분한다.- matching된 detection은 track object에서 실제로 kalman filter update에 활용된다.
- unmatched track은 missing track으로 간주된다. (가려지거나 frame에서 나가거나)
- unmatched detection은 새로운 track으로 initialize된다.
- track set을 update하고 distance metric도 update한다.
Track object
- track의 state는 크게 3가지로 나눌 수 있다.
class TrackState:
"""
Enumeration type for the single target track state. Newly created tracks are
classified as `tentative` until enough evidence has been collected. Then,
the track state is changed to `confirmed`. Tracks that are no longer alive
are classified as `deleted` to mark them for removal from the set of active
tracks.
"""
Tentative = 1
Confirmed = 2
Deleted = 3- track class는 각 track을 표현하며, state mean & cov와 id, age 등 정보를 포함한다.
- kalman filter prediction할 때마다 age가 늘어나며, update 할 때마다 time_since_update는 0으로 초기화된다.
class Track:
"""
A single target track with state space `(x, y, a, h)` and associated
velocities, where `(x, y)` is the center of the bounding box, `a` is the
aspect ratio and `h` is the height.
"""
def __init__(self, mean, covariance, track_id, n_init, max_age,
feature=None):
self.mean = mean
self.covariance = covariance
self.track_id = track_id
self.hits = 1
self.age = 1
self.time_since_update = 0
self.state = TrackState.Tentative
self.features = []
if feature is not None:
self.features.append(feature)
self._n_init = n_init
self._max_age = max_age
def predict(self, kf):
"""Propagate the state distribution to the current time step using a
Kalman filter prediction step.
Parameters
----------
kf : kalman_filter.KalmanFilter
The Kalman filter.
"""
self.mean, self.covariance = kf.predict(self.mean, self.covariance)
self.age += 1
self.time_since_update += 1
def update(self, kf, detection):
"""Perform Kalman filter measurement update step and update the feature
cache.
Parameters
----------
kf : kalman_filter.KalmanFilter
The Kalman filter.
detection : Detection
The associated detection.
"""
self.mean, self.covariance = kf.update(
self.mean, self.covariance, detection.to_xyah())
self.features.append(detection.feature)
self.hits += 1
self.time_since_update = 0
if self.state == TrackState.Tentative and self.hits >= self._n_init:
self.state = TrackState.Confirmed
Discussion
- 꽤 오래된 연구이지만, 해당 분야에서 널리 사용되는 유명한 연구라서 공부해보았다.
- 페어퍼가 엄청 짧은데, compact하게 잘 설명이 되어있어서 읽기 편했다.
- Detection 기반 tracking 기술의 전반적인 알고리즘 흐름에 대해서 이해할 수 있었다. 결국 data association part가 가장 중요한 것 같다.
- 요즘에는 detection model과 re-id model이 public에 잘 공유되어있기 때문에 알고리즘만 잘 이해하면 implementation이 쉬울 것 같다고 생각했다.
- 이전에 공부했었던 end-to-end 방식의 tracker (e.g., TCTRack) 들과 장단점을 비교해보는 것도 재밌을 것 같다.
-
SOTA tracking module을 사용해볼 수 있는 BOXMOT을 사용해보았는데, 매우 정리 잘되어있고 사용하기 간편하다. https://github.com/mikel-brostrom/boxmot
-
그 중에서도 어떤 분이 resurrection system를 구현하여 이전에 사라졌던 타겟을 더 잘 찾아낼 수 있도록 개발해놓은 브렌치가 있어 돌려보고 공부해보고 있다. STRONGSORT 기반이지만 전체적인 흐름은 거의 비슷하다. https://github.com/mikel-brostrom/boxmot/pull/626