Paper : Unsupervised Attention-guided Image-to-Image Translation (Youssef A. Mejjati, Christian Richardt, James Tompkin, Darren Cosker, Kwang In Kim / NIPS 2018)
- Motivation : Image-to-Image translation을 학습시키고 결과를 보다보니, 내가 원하는 특정 object에 대해서만 translation을 시키거나 그 object만큼은 잘 보존해주기를 바라는 경우가 종종 있었다. 바로 떠올릴 수 있는 간단한 아이디어가 attention이나 heatmap을 기반으로 네트워크로 하여금 해당 object의 중요성에 대해 알려주는 것이었다. 이러한 내용을 다룬 논문이 여러 개 있어서 그 첫 페이지로 해당 논문을 선택했다.
Short Summary
- 기존의 I2I network들은 내가 의도한 object만을 translation하지 못했다.
- Source와 target domain의 data generating distribution에서 오직 필요한 부분만의 차이를 최소화하는 방법을 제시
- CycleGAN의 각 geneator에 attention network를 추가하는 방법을 제시

CycleGAN
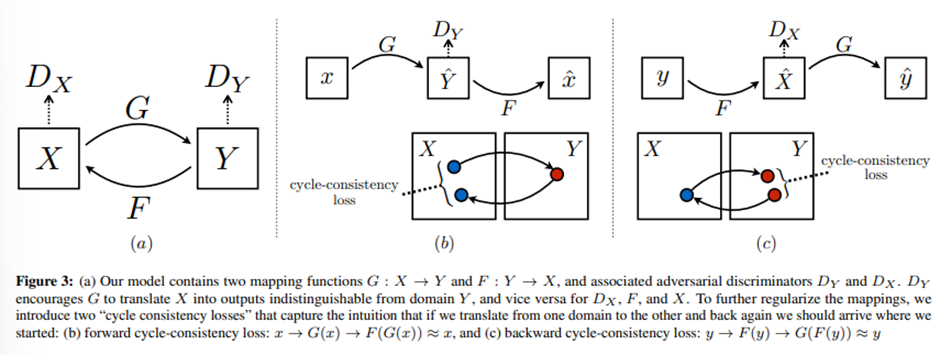
이 논문은 CycleGAN을 baseline으로 하므로 remind해보자. Image translation의 목표는 서로 독립적인 data sample instances 와 를 이용하여 가 target domain data distribution을 따르도록 하는 를 estimate하는 것이다.
CycleGAN에서는 cycle consistency(: )를 부여하여 unsupervised training에서 두 도메인의 space를 regularize하였다.
Methods
하지만 위의 Figure 1에서 볼 수 있다시피, 이러한 CycleGAN은 내가 원하는 object말고도 다른 것들을 변화시키곤 한다. 이러한 문제를 풀기 위해서는 아래의 두 가지 task에 집중해야할 것이다.
(1) 각 이미지에서 translation을 할 영역을 정하는 것
(2) 그 정해진 영역에서 정확한 translation을 하는 것
이 논문에서는 attention network 와 를 도입하여 이 문제를 해결하고자 했다. 이 attention network는 discriminator가 가장 실수할 확률을 높이는 area를 선택하도록 학습이 된다. 는 Source의 이미지를 받아 Source attention map 을 생성한다. (vice versa)
Generator가 input image를 받아 translation을 하면, 이 learned attention mask와 element-wise product하여 masking 해준다. 동시에, inverse mask를 활용하여 background를 더해준다.
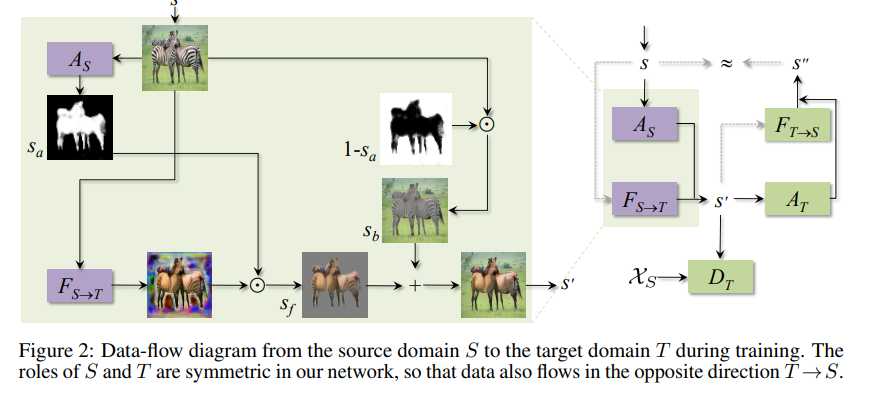
아주 직관적으로 attention을 부과하며, 위에서 설명한대로 가 에서 domain 로 옮겨지고, 같은 이미지가 를 거쳐 attention map 를 얻게 된다. 그러면 domain T에서 내가 원하는 foreground object 를 얻기 위해 generated output에 를 곱하고, background는 원본 그대로 가져가도록 한다. 즉, mapping이 된 이미지 는
Attention map intuition
사실 이 model은 단지 attention map이 다 한다고 보면 된다. 예를 들어 attention map이 모두 1이라면, 이는 모든 이미지가 해당 도메인을 규정짓는데 관련있다고 보는 것이고 CycleGAN이랑 같은 것이 된다. 반대로, attention map이 모두 0이라면, 생성된 이미지는 input이랑 같을 것이고, discriminator는 이를 확실히 구분해낼 것이다. 또한 만약에 attention map이 실제로는 중요하지 않은 곳을 highlighting 했다고 치면, 실제로 중요한 object (=그 domain을 가장 잘 나타내는 중요한 object)(위의 예시에서는 horse)는 그대로 있을 존재할테니까 discriminator가 여전히 잘 구분해낼 것이다.
즉, generator, attention network와 discriminator가 equilibrium으로 도달할 유일한 방법은 attention network가 해당 도메인에 most descriptive한 object에 집중하여 generator가 translation할 수 있게 해주는 것이다.
Loss function
CycleGAN과 다를 것이 없다. total loss는 adversarial loss와 cycle loss로 이루어진다.
Attention map이 추가된 상태에서 cycle loss는 생성된 이미지에서 attended region의 content를 더욱 유지하게 해주고, unattended region은 cycle loss가 0이 되도록 하므로attention map자체가 더욱 sharp하게 (binary map정도로 수렴) 만들어주는 부가적인 효과가 있다.
Attention-guided discriminator
Attention network가 중요한 object에만 잘 집중해서 바꿨다고 해보자 (예를 들어 그림에서 말 만을 얼룩말로 바꾸는데 성공). 하지만 discriminator는 여전히 이미지 전체를 보기 때문에 말은 초원에서만 살고, 얼룩말은 사바나에서 산다는 것을 알아챌 수도 있을 것이다.
이렇게 되면 generator는 background를 바꾸는데 힘을 써야할 것이고, attention map은 점점 더 많은 background를 포함하여 나중에는 모두 1의 값을 갖게 될 것이다.
이를 해결하기 위해 이 논문에서는 discriminator도 attended region만을 고려하도록 하였다. 이렇게 되면 또한 discriminator가 처음에는 학습되지 않은 attention network에 의존하는 꼴이 되어버리므로, 첫 30 epoch정도를 먼저 학습시켜 attention network가 어느 정도 object를 잡기 시작한 뒤로 attended region만 고려하게 하였다.
Training Details
추가적으로 discriminator가 attented region만을 고려할 때, 학습의 용이성을 위해 attention map에 threshold를 하는 trick이 있다.
Results

Attention map이 생각보다 상당히 sharp하게 생성되는 것을 볼 수 있고, 이에 따라 중요한 부분만 잘 바꿔내는 것을 확인할 수 있다.
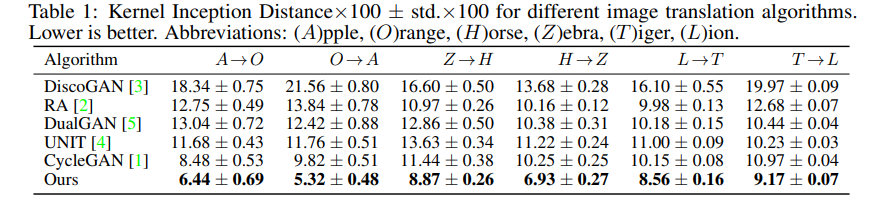
Quantitative result로는 Kernel Inception Distance (KID)를 사용하였다. 이는 실제 이미지와 생성된 이미지의 feature representation 사이의 squared maximum mean discrepancy를 구하는 metric이라고 한다. 이 value가 더 낮으면 두 이미지 사이에 visual similarity가 더 크다고 한다.
Opinion
이 논문은 많은 I2I가 실제로 이미지를 target 도메인으로 잘 옮기지만, 보통 불필요한 background도 변화시키는 문제가 많았는데, 간단하게 CycleGAN에서 추가적인 supervision없이 attention mechanism만을 도입하여 이를 해결했다.
어떻게보면 두 도메인에서 가장 discriminative한 object만을 바꾼다는 개념은 아주 자연스러운 것 같다. 뭔가 아주 구별하기 쉬운 task가 아니고서는 attention map을 안정적으로 학습하기는 쉽지 않아보이긴 하지만, GAN 네트워크 자체의 특성을 잘 활용하여 디자인한 네트워크 같다. (discriminator가 구별하는 기준이 자연스럽게 attention이 될 것이므로)
하지만 이미지 전체의 style을 바꾼다거나 texture를 바꾸는 translation이나, 이미지의 shape 자체를 변형시키는 translation에서는 이 방법이 잘 작동하지 않을 수도 있겠다고 생각이 됬다. 논문에서도 limitation으로 이 method가 도메인 사이의 shape change에 대해서는 robust하지 못하다고 했다. 당연스럽게도 attention이 생긴 부분에서만 change가 일어나야 하므로 shape이 변해야 하는 translation에는 맞지 않을 수 있다. 또한 전체 style을 바꾸는 경우는 사실 cycleGAN이랑 다를 바가 없어보인다.
아무튼, discriminator가 도메인을 구별하도록 하는 어떤 discriminative한 region에 대해서는 적어도 내가 원하는 변화를 가할 수 있겠구나라는 아이디어를 얻을 수 있었던 것 같다.
[+] 그러면... discriminator가 도메인을 구별할 수 있게 하는 어떤 feature에 대한 지식을 갖고 있다면, 내가 원하는 region에 그 feature를 나타내는 imaging 특성을 박아넣을 수 있으려나??
