Paper : StarGAN v2: Diverse Image Synthesis for Multiple Domains (Yunjey Choi, Youngjung Uh, Jaejun Yoo, Jung-Woo Ha. / CVPR 2020)
- Motivation : 기존에 공부하고 실험해보았던 MUNIT framework에서 보다 발전된 최근 style transfer 연구에 대해 공부하려고 한다. 하나의 Generator로 여러 도메인에서 다양한 style을 표현하는데 성공했고, 이미지 퀄리티 또한 훌륭해보인다. 그리고 한국분 작품이던데 멋지다.
Short Summary
-
Domain-specific style code를 활용하여 하나의 generator만을 이용하여 다양한 domain으로 style transfer를 할 수 있었다.
-
Style regularization technique과 StyleGAN의 learned style space를 이용하여 더 다양하고 퀄리티 좋은 이미지를 만들어내었다.
Introduction
Image to image translation의 목적은 서로 다른 domain 사이의 mapping 함수를 배우는 것이다.
여기서 domain이라 함은 시각적으로 구분이 되는 카테고리로 분류되는 이미지 set을 의미한다. 이때, 각 이미지는 고유한 외관을 가지는데, 이를 style이라고 하자.
예를 들면, 사람의 성별(남자 혹은 여자)을 domain으로 볼 수 있고, 각 성별을 가진 사람의 메이크업, 수염, 헤어스타일 등을 스타일로 볼 수 있다.
X-ray 영상으로 따지면 특정 abnormal finding(lung opacity 등)을 domain으로 볼 수 있고, 각 finding이 나타나는 형태(Ground glass opacity, Consolidation 등)를 style로 볼 수 있겠다.
좋은 image to image translation 모델의 mapping은 생성되는 이미지의 style diversity를 보장할 수 있어야 하며, multiple domain에 대해 scalable해야한다.
이전의 image to image translation 연구에서는 보통 low-dimensional latent code를 gaussian 분포에서 sampling한 다음, domain-specific generator에 입력으로 넣어 다양한 이미지를 생성하려고 시도하였다. 하지만 이들은 두 도메인 사이에서의 mapping만을 고려하였고, domain이 늘어남에 따라 필요한 모델의 수가 많아 실제 사용에 한계가 있었다.
이를 해결하기 위해 이전 논문인 starGAN은 하나의 generator가 domain에 대한 label을 추가적인 input으로 받아 해당 domain으로 mapping을 시도하였다. 하지만 StarGAN은 이미 정해진 domain label만을 이용해 각 domain에 대한 deterministic mapping을 학습하므로 데이터 분포의 multi-modal 특성을 반영하지 못했다. (MUNIT에서 제기한 문제와 같음)
결론적으로 두 개의 domain 사이에서만 작동하는 이전 연구의 문제와 여러 domain에서 작동하지만 여러 domain 내부에서 다양한 style을 표현해내지 못하는 문제를 해결하기 위해 StarGAN v2를 제안한다.
Proposed Framework
가 어떤 이미지 집합, 그리고 가 가능한 도메인이라고 할 때, 이 framework의 목적은 하나의 generator 로 임의의 이미지 에 대해 각 도메인 에 해당하는 다양한 이미지를 생성해내는 것이다.
이를 위해 학습된 각 도메인의 style space에서 domain-specific style vector를 생성하여 generator가 이를 반영하도록 학습한다.
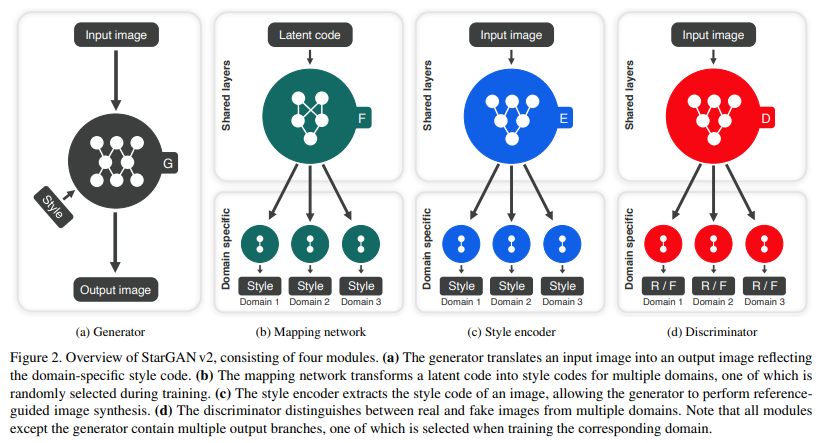
Generator
Generator는 input image 를 받아 domain specific style code 를 이용해 output image 를 출력으로 한다.
이때, style code는 mapping network 나 style encoder 에서 구해지며, AdaIN을 이용하여 주입된다.
는 특정 domain 의 style을 표현하도록 설계가 되었기 때문에 domain 라는 정보를 generator에 넣어줄 필요가 없다. 그러므로 generator 하나만으로 모든 domain의 이미지를 생성할 수 있는 것이다.
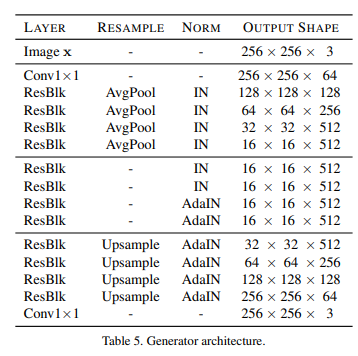
Mapping Network
Mapping network F는 latent code 와 domain 를 받아 style code 를 생성한다.
이는 가능한 모든 도메인에 대해 각각 style code를 만들어내도록 여러 출력 branch를 가지는 MLP로 구성되어있다. 와 를 sampling하여 각 domain마다 서로 다른 style space를 학습한다.
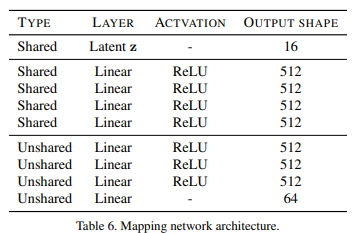
Unshared layer가 domain 갯수만큼 달리고 각 domain마다 output이 나오게 된다. input 는 gaussian distribution에서 sampling한다.
여기서 함께 받은 domain 의 index에 맞는 style을 return한다.
Style Encoder
Style encoder E는 image 와 domain 를 받아 style code 를 추출한다.
E는 서로 다른 reference image에서 다양한 style code를 추출할 수 있다. 이는 G가 reference image 의 style을 이용해 새로운 이미지를 생성할 수 있도록 해준다.
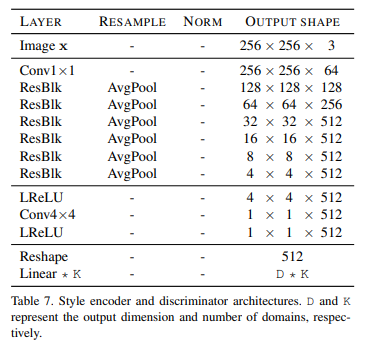
Resblk을 공유하고 domain 갯수만큼 branch를 달아 output을 낸다. Mapping network와 동일하게 domain 의 index에 맞는 style을 return한다.
Discriminator
Discriminator는 multi-task discriminator로 multiple branch를 가진다.
각 branch 는 input image가 domain 의 real image인지, fake image인지 분류한다.
Discriminator구조는 Style Encoder의 구조와 같으며 output dimension 만 1로 설정하여 사용하였다.
Training objectives
이미지 와 이 이미지의 도메인 가 주어졌을 때, starGAN v2는 아래와 같은 목적함수를 통해 학습한다.
Adversarial objective
학습시, latent code 와 target domain 를 랜덤으로 추출하여 target style code 를 생성한다.
그리고 Generator는 와 를 받아 이미지를 생성한다.
이때, Adversarial loss는 아래와 같이 구해진다.
여기서 는 domain y에 해당하는 의 output을 의미한다.
Mapping network 는 target domain 에 likely한 style code 를 만들어내는 것을 학습하고, Generator는 이 를 이용하여 의 real image와 구분할 수 없는 image를 만들어내는 것을 학습한다.
Style reconstruction
Generator가 이미지를 생성하는데 를 잘 활용할 수 있게 하도록 하기 위해 style reconstruction loss를 아래와 같이 정의한다.
기존의 연구들이 이미지를 latent code로 mapping하기 위해 여러 개의 encoder를 사용했던 것과 다르게 이 논문에서는 하나의 encoder가 여러 domain의 다양한 output을 만들어낼 수 있다.
Inference 시에는 학습된 encoder를 이용해 reference image의 style을 추출하여 generator가 input image를 reference style로 변환시킬 수 있다.
Style diversification
Generator가 더욱 다양한 이미지를 만들어낼 수 있도록 하기 위해, diversity sensitivity loss를 주어 regularize한다.
여기서 과 는 하나의 도메인 에서의 random latent code 과 로부터 생성된 임의의 스타일이다.
이 regularization term을 maximize함으로써 generator는 더 다양한 이미지를 생성하기 위해 image space를 탐색하고 의미있는 style feature를 찾으려고 노력하게 된다.
원래 ds loss는 다른 형태라고 하는데, training stability를 위하여 분모를 없애고 위의 식을 채택했다고 한다.
Preserving source characteristics
생성된 이미지가 input image의 포즈와 같은 domain-invariant한 특성을 보존하도록 cycle-consistency loss를 추가한다.
여기서 는 input image의 원래 도메인에 대한 style로, generator가 이를 이용해 원본 이미지를 다시 만들 수 있도록 한다.
Full objective
전체 목적함수는 아래와 같이 정의된다.
실제 학습시에는 random latent code 뿐만 아니라 reference 이미지를 이용해서도 style code를 생성해서 학습한다.
Experiments and Results
Analysis of individual components
성능 평가 metric으로는 Frechet inception distance(FID)와 learned perceptual image patch similarity(LPIPS)를 사용하였다.
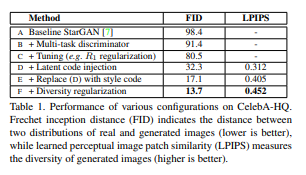

위의 표와 그림은 baseline인 stargan에서부터 새로 추가된 configuration으로 인한 성능향상과 이 변화를 시각적으로 나타낸 것이다.
Discriminator에 대한 설명은 건너뛰도록 하겠다. multi-task discriminator랑 R1 Loss를 부여하는 내용은 알아만 두자
- Latent code injection
Latent code를 이용해 generator에서 AdaIN을 통해 style을 변화시키는 framework는 하나의 input에 대해 다양한 결과를 낼 수 있도록 하였다. (위의 표에서 이미지 다양성을 나타내는 지표인 LPIPS가 latent code injection에서부터 구해지는 것만 봐도 알 수 있다)
이때 diversity를 높이기 위해서 직접적으로 latent reconstruction loss 를 부여하는 방법을 생각할 수 있다. (MUNIT에서 latent recon loss를 사용한다.)
하지만 이 논문에서는 latent code 자체로는 domain을 구별하는 능력이 없기 때문에, 이 경우 latent loss는 hair style과 같은 domain specific style보다는 color와 같은 domain shared style을 modeling하게 될 수 밖에 없다고 생각했다.
-
Style code injection
Latent code를 generator에 직접 넣는 대신에 를 mapping network를 통해 domain specific style code 로 매핑하여 style reconstruction loss를 부여하였다. Mapping network는 를 각 domain에 해당하는 branch마다 로 매핑하기 때문에 domain을 구별하는데 문제가 없다. -
Diverse style regularization
마지막으로 diverse style regularization을 통해 더욱 다양한 결과를 낼 수 있다.
위의 다양한 기법들을 통해 아래 그림과 같이 reference 이미지에서 다양한 style을 반영하는 이미지를 생성해낼 수 있다.
Source 이미지의 pose는 그대로 가져가고 reference 이미지의 hair style, beard 등을 그려낸 것을 볼 수 있다.

Comparison on diverse image synthesis
기존의 다른 multi-output style transfer 연구에 비교했을 때, StarGAN v2는 latent-guided synthesis와 reference-guided synthesis의 입장에서 우월하다고 한다.

위 그림은 원본 이미지에 대해 random noise를 이용하여 여러 개의 가짜 이미지를 생성한 결과이다.
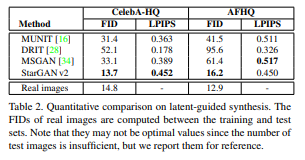
이미지의 퀄리티(FID)와 다양성(LPIPS) 입장에서 뛰어나다. 실제로 FID가 real image의 점수와 비슷할 정도로 퀄리티가 좋았다.

두번째 그림은 target domain의 reference image로부터 style code를 추출하여 이를 이용해 source image를 transfer한 결과이다.
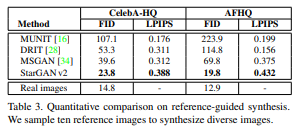
StarGAN v2는 mode collapse 현상이 발생하지 않는다고 한다.
정리하자면 StarGAN v2가 잘 작동하는 이유는 아래와 같다.
(1) Mapping network와 Style encoder가 도메인마다 output branch를 가지고 있다.
Generator는 이미 domain-specific한 정보를 담고 있는 style code를 잘 활용하는 것에만 집중할 수 있다.
(2) Learned style space
StyleGAN 논문 리뷰에서도 알아보았듯이 고정된 가우시안 분포로 style space를 가정하는 것보다 를 learned transformation을 통해 매핑한 를 style space로 사용하는 것이 훨씬 disentangle하다.
(3) Fully exploiting training data
추가적으로 각 도메인마다 모듈이 있던 이전 연구와 달리 StarGAN v2에서는 각 모듈이 모든 training data를 input으로 받고 shared layer와 unshared layer를 구분하는 방식이다.
그러므로 shared layer는 도메인에 상관없는 feature를 잘 배우고, 이는 generalization에 도움을 줄 수 있다고 한다.
Opinion
실제로 학습을 시켜보았을 때, 확실히 MUNIT에 비해 이미지 퀄리티나 다양성 측면에서 뛰어나다는 것을 알 수 있었다.
Face는 이미 잘된다고 가정하고, 아래는 NIH data를 이용한 reference-guided synthesis 예시이다. (normal과 effusion을 도메인으로 생각하여 학습)
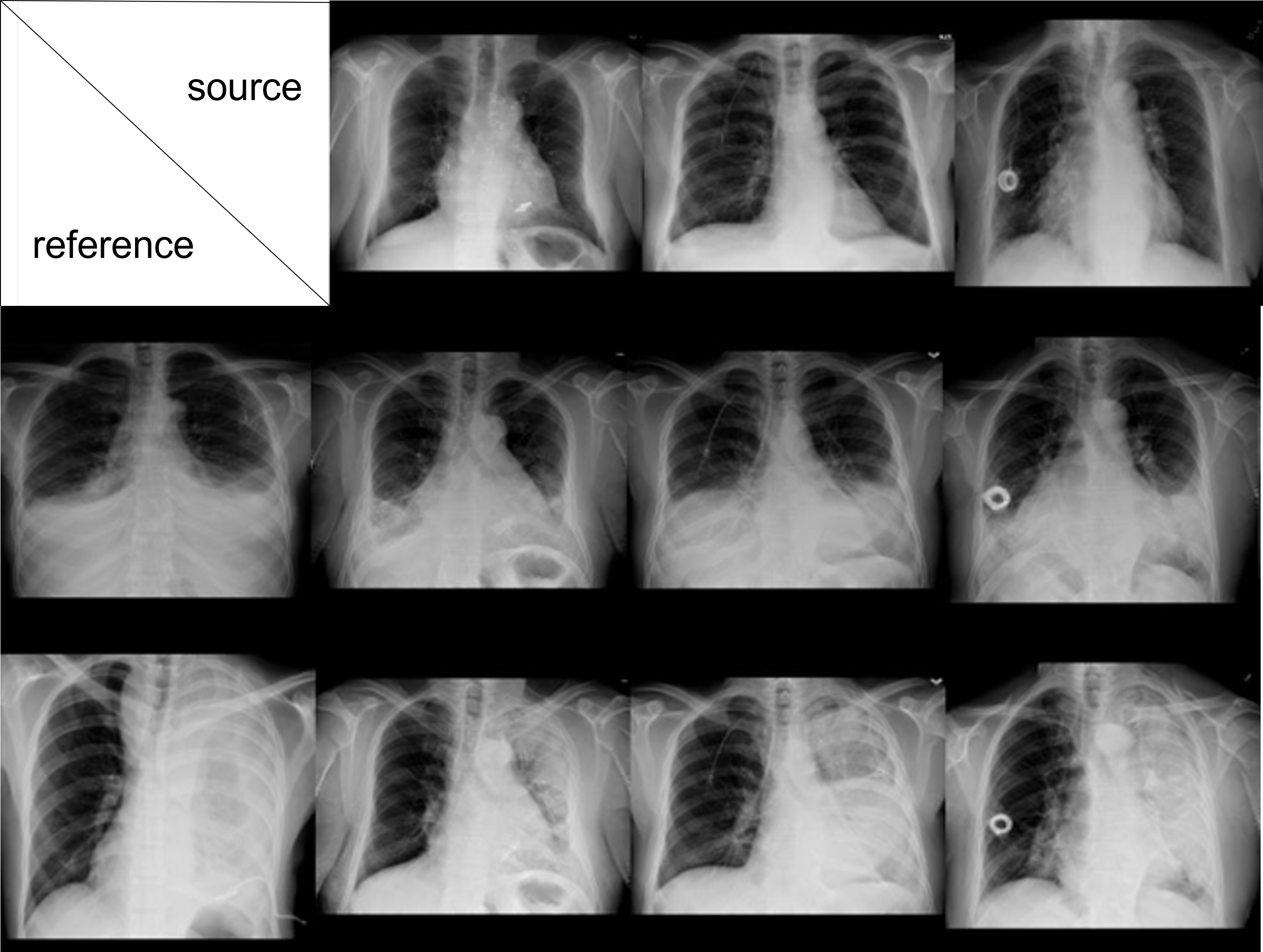
reference 이미지의 style이 확실한 경우, 이를 잘 반영하는 것을 확인할 수 있었다.

두번째로 위의 결과는 latent guided synthesis이다. 첫번째 row가 실제 이미지이고, 아래 row들은 각 row가 같은 latent vector로 생성된 것이다.
이때, latent vector가 변함에 따라 다양한 이미지를 생성해내는 데에는 성공하였으나, 각 row를 비교하였을 때, 모델이 이미지의 밝기나 contrast 또한 style로 해석한 것 처럼 보였다. 즉, Style space 내부에서 X-ray 이미지의 abnormality feature와 X-ray 이미지의 physics factor(brightness나 contrast)가 entangled되어있는 것 같았다.
같은 이미지 품질을 가진 도메인의 데이터를 학습데이터로 사용하면 가장 좋겠지만, 그런 데이터는 얻기가 너무 어려우므로, X-ray physics에 대한 차이가 domain이나 style에 영향을 주지 않도록 하는 방법에 대한 공부가 필요할 것 같다. (Augmentation 등이 있겠다)
X-ray이미지를 이용한 style transfer가 어려운 두번째 이유는 X-ray의 특성 상 discriminative feature가 (1) 매우 subtle하고 이러한 특성이 (2) 하나의 이미지 안에 혼재되어 있기 때문에, domain과 style을 정의하는 것이 쉽지가 않다는 것이다.
(1) 나는 X-ray의 lung 내부에서 나타나는 대표적인 abnormality 중 하나인 effusion을 하나의 도메인으로 정하였고, 이는 매우 명확하게 구분되는 feature이기 때문에 이를 나름 잘 학습한 것으로 보이나, 작은 결절의 형태나 미묘한 consolidation이나 infiltration을 domain으로 정했을 때, 다양한 style로 표현되는 모습을 잘 학습할 수 있을지 의문이다. (데이터가 엄청 많이 필요할 것 같다.)
(2) 또한 주요 abnormality를 domain으로 정했을 때, 이미지가 male/female 처럼 이분법적으로 구분되는 것이 아니라, 여러가지 abnormality를 하나의 이미지가 포함하고 있는 경우에 대한 대처도 생각해보아야할 것 같다.
실제 학습시에는 generator를 제외한 모든 network가 multi-task network로 이미지에서 기본적인 feature를 추출하는 shared layer와 각 domain specific unshared layer로 나뉘어 여러 개의 output을 낸다. 이 때 target domain을 명시적으로 E 및 F에 넣어 해당하는 branch의 output을 사용한다. 이때 다른 branch는 다른 도메인에 특정된 style vector를 encoding하게 되므로 이 정보를 같이 활용할 수 없을까 생각이 된다.
예를 들어 이 framework에서는 남자/여자가 0, 1의 도메인으로 나뉘어져서 하나만 선택하게 되어있는데, 예를 들어 domain이 effusion/nodule/opacity로 나뉘어 있어서 여러 개를 복수 선택할 수 있는 경우에도 학습이 가능할까? 어떻게 설계할 수 있을까? 재밌는 고민인 것 같다.
마지막으로 Normal을 하나의 domain으로 보아야 하는지도 의문점이다. Style transfer 연구에서 중요한 점은 하나의 domain 내부 다양한 style을 얼마나 잘 표현하냐는 것인데, Normal X-ray 이미지는 deterministic한 결과를 내더라도 문제가 없을 것 같다고 생각했기 때문이다. 예를 들어 양방향 style transfer가 아닌 단방향 style transfer를 위한 framework가 있어야 할 것 같다. 나중에 고민해볼 문제다.
