Paper : YOLO9000: Better, Faster, Stronger (Joseph Redmon, Ali Farhadi / CVPR 2017)
Yolo의 두번째 버전으로, 이전 모델에 비해 Better, Faster, Stronger한 모델이라고 한다.
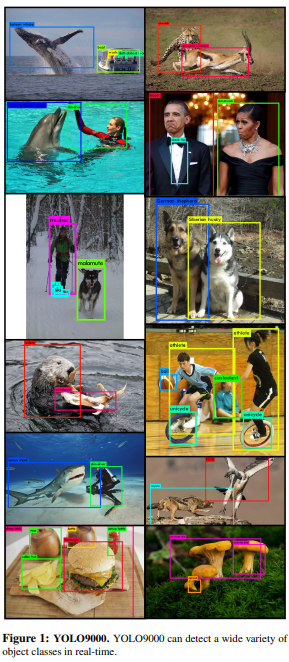
Highlights
- YOLO v1을 다방면 (정확도, 속도, class 갯수)으로 발전시켜 YOLO v2 제안
- Object detection과 classification의 joint training 방법 제안
Overview
이 논문에서는 YOLO baseline method를 다방면에서 발전시켰다. 특히 detection과 classification을 함께 학습시킬 수 있는 방법을 제시함으로써 충분히 많은 양의 classification dataset을 활용할 수 있었고, 이를 통해 9000개의 서로 다른 object를 real-time으로 detect할 수 있는 YOLO9000을 제시하였다.
Method
Better, Faster, Stronger의 세 가지 파트의 발전을 나누어 설명
Better
Yolo v1은 Fast R-CNN 모델과 같은 region proposal-based method에 비해서 1) localization error가 크고, 2) 상대적으로 recall ()이 낮다는 단점이 있었다.
이러한 문제를 개선하기 위해 YOLO에 다양한 method를 적용하였고, 각 방법론이 모두 성능 향상에 도움을 주었다.
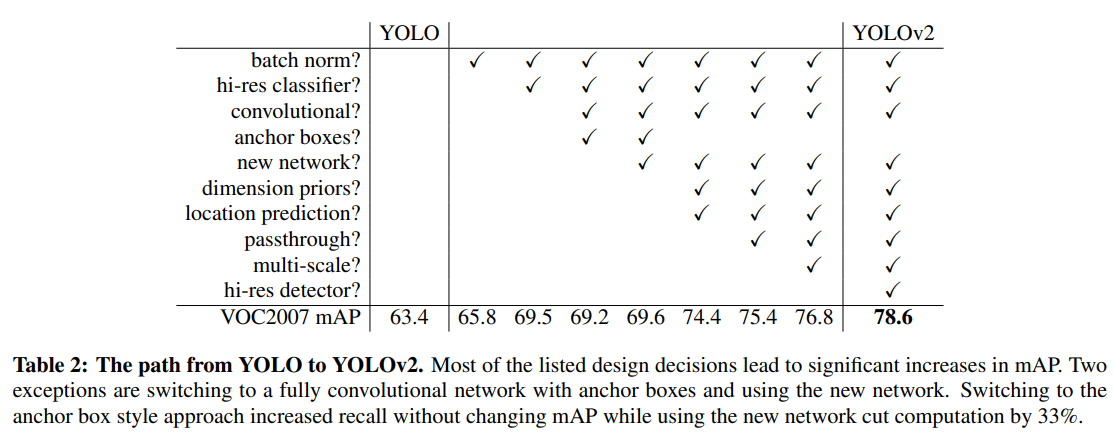
1) Batch normalization
YOLO의 모든 conv layer에 BN을 적용하여 convergence에 도움을 주었다. (mAP 2% 향상)
2) High Resolution Classifier
YOLO v1은 224x224로 pre-train 시킨 후 448x448로 detection을 학습했는데 (네트워크가 다시 resolution에 적응해야함), YOLO v2에서는 ImageNet dataset을 이용해 448x448 resolution으로 classification network를 10 epoch정도 finetune하고, 이후로 detection으로 finetune. (mAP 4% 향상)
3) Convolutional with Anchor boxes
YOLO v1에서는 CNN 다음에 곧바로 FC layer를 달아서 bounding box들을 예측했었다. 반면에 Faster R-CNN의 경우에는 hand-picked prior인 anchor를 사용하며, Region Proposal Network는 각 anchor box의 offset과 confidence를 예측한다.
논문에서는 coordinate를 예측하는 것 보다 offset을 예측하는 것이 network가 학습하기에 더욱 간단한 문제라고 하였다.
그래서 YOLO v2에서는 FC layer가 사라지고 bbox를 예측하기 위해 anchor box가 사용되었다. Anchor box 방법을 사용하면서 spatial location에 대한 예측이 아니고 모든 anchor box마다의 class와 objectness prediction을 하게 된다. (YOLO v1은 이미지 당 개의 boxes였고, YOLO v2는 천개가 넘는 predictions)
Anchor box 사용 안했을 때는 69.5 mAP에 recall 81%, Anchor box 사용 했을 때는 69.2 mAP에 recall 88%. (mAP 살짝 떨어지긴 했어도, recall 값이 꽤 높아진다는 것은 실제 object를 잘 detect한 비율이 높다는 것 : 예측하는 bbox 수 자체가 많아지므로 당연한)
또한 입력 이미지를 416x416으로 줄이고, 최종 output feature를 13x13크기로 설정하였다. 이렇게 하면 최종 feature를 홀수 크기로 해서 하나의 중심 cell이 존재하기 때문에 큰 물체를 탐지하는 데 유리하다고 한다.
4) Dimension Clusters
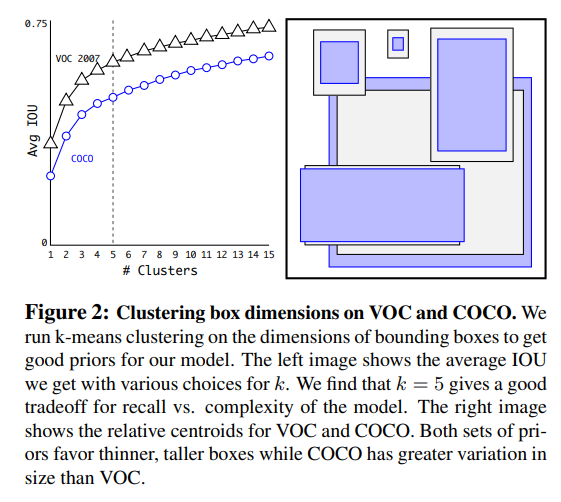
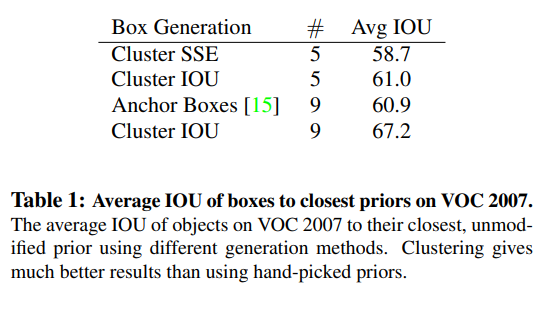
YOLO에 anchor box를 적용할 때에 하나의 이슈는 box dimension을 hand-picked한다는 것인데, 만약 더 좋은 prior boxes를 선택한다면, 네트워크가 더 잘 학습할 수 있을 것이다.
해당 논문에서는 bounding box를 미리 정의하기보다는 k-means clustering을 사용하여 좋은 prior를 탐색하는 방법을 제시하였다.
즉, training bounding boxes의 dimensions (width & height)를 이용하여 k-means를 사용하여 좋은 anchor box를 선정한 것이다. 또한 k-means를 적용할 때, 일반적인 Euclidean distance를 적용하지 않고, IOU가 높을 때, 가까운 것으로 계싼할 수 있도록 distance metric을 정의하였다.
이렇게 선정된 5개의 prior anchor만 사용했을 때에도 9개의 anchor box를 사용했을 때와 성능이 비슷하고 recall vs. model complexity 입장에서 효율적이기 때문에, k=5를 사용한다고 한다.
5) Direct location prediction
YOLO에 anchor box를 적용할 때에 또 다른 이슈는 초기 학습에서의 model instability이다. 이러한 instability는 box의 를 예측하는데에서 오는데, 이는 network가 아래와 같이 계산되는 , , 를 예측할 때,
, 값이 제한되어 있지 않기 때문에 어떤 anchor box도 이미지 내 어느 점에도 도달할 수 있게 되어, 학습 초기에는 모델의 학습이 불안정할 가능성이 크다.
YOLO v2에서는 YOLO v1의 접근을 따라서, offset을 prediction하기 보다 grid cell의 location에 상대적인 location coordinate를 예측하는 방식을 택했다.
이렇게 하면 GT가 0~1사이 값을 갖게 되므로, network output을 activation function을 통해서 constraint할 수 있게 된다.
YOLO v2 network는 output feature map의 각 cell마다 5개의 bbox를 예측하는데, 각 bbox는 5개의 coordinate로 이루어져 있다 (network output = ()).
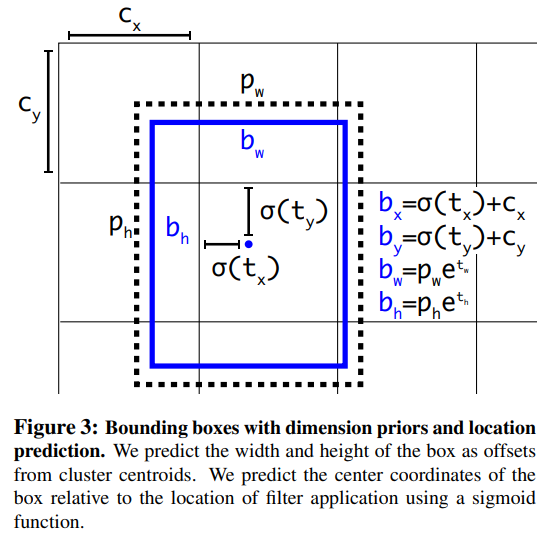
위의 그림과 같이 cell이 이미지의 top left corner로 부터 만큼의 offset을 가지고 bbox prior가 의 width와 height를 가지고 있다면, prediction은 아래와 같이 구할 수 있다.
이렇게 location prediction을 constrain하여 network 학습을 더욱 안정적으로 만들었으며, dimension cluster와 direct prediction을 통해 5%가 넘는 성능 향상을 얻을 수 있었다.
6) Fine-Grained Features
YOLO v2는 13x13 feature map에서 detection을 수행하는데, 이는 큰 object를 detect하기는 충분하지만 작은 객체를 위해서는 조금 더 fine feature가 필요하다.
이를 위해서 최종 13x13 feature로 pooling 되기 전 feature를 로 나누어 길게 늘어뜨린 뒤에 original feature에 합쳐준다.
그렇게 find-grained feature를 최종 feature에 추가해줌으로써 1%의 성능 향상이 생겼다고 한다.
7) Multi-scale Training
Original YOLO input size는 448x448인데, 이 논문에서는 YOLO v2를 different image size에 대해 robust하게 만들기 위해 더욱 다양한 size의 이미지를 입력으로 학습했다고 한다.
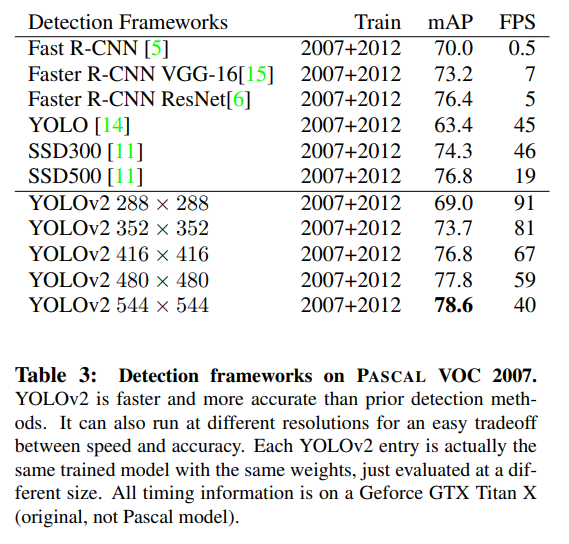
Faster
이 논문에서는 속도 측면에서도 YOLO를 발전시키고자 하였다. 이를 위해 YOLO v2의 base로 사용되는 classification model인 Darknet-19도 제안하였다. 이 네트워크는 Googlenet을 기반으로 설계되었으며, GAP를 사용하고 1x1 conv를 사용하여 FC에 비해 속도가 빠르며, 3x3 conv 사이에 1x1 conv를 사용하여 feature를 압축시켰다는 특징이 있다.
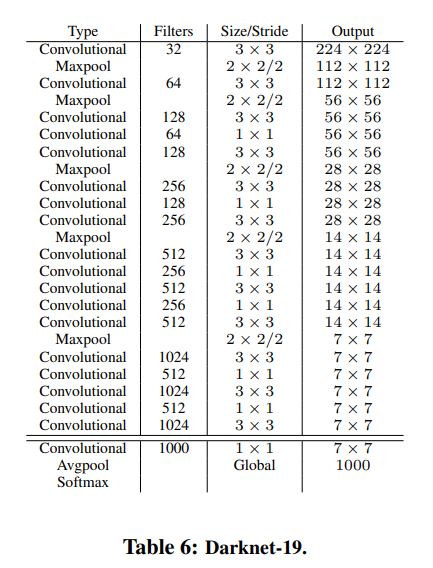
Classification and Detection
YOLO v2에서는 먼저 위의 Darknet-19를 Imagenet classification dataset으로 224x224로 pretrain시킨 후, 448x448로 finetune했다.
그 후, Detection을 위해서 마지막 conv layer를 제거하고 이를 1x1 conv로 대체하고, detection을 위한 output 갯수만큼 출력하도록 설계하였다.
예를 들어 VOC 데이터셋의 경우 각 grid cell마다 5개의 coordinate를 갖는 박스를 5개 추출하고, 각 box가 20개의 class를 예측해야하므로, 1x1 conv는 개의 filter를 가져야 한다.
Stronger
YOLO v2에서는 classification과 detection 데이터를 함께 학습시켜 모델을 더욱 강력하게 만들고자 하였다. 학습 시에, 두 데이터셋을 섞어서 학습하며, detection labelled image에 대해서는 YOLOv2 loss function으로 학습시키고, classificaiton image에 대해서는 classification part에 대해서만 loss를 역전파시킨다.
하지만 이때, classification dataset이 가지는 label과 detection dataset이 가지는 label의 range가 달라서 학습에 문제가 생길 수 있다. 예를 들어, classification dataset의 label은 detection보다 훨씬 세부화되어 있는데, 이를 softmax를 통해 학습할 경우 "dog"와 "Yorkshireterrier"가 서로 다른 것으로 학습되게 될 수 있다.
물론 multi-label problem으로 문제를 풀어볼 수 있겠지만, YOLO v2는 Hierachical classification을 이용하여 이 문제를 풀려고 한다.
Hierachical classification
ImageNet label은 WordNet이라는 language database로부터 추출되었는데, WordNet은 directed graph로 구성되어 각 label의 상하관계를 표현한다.
예를 들어 "Yorkshire terrier" -> "terrier" -> "hungting dog" -> "dog" -> "canine" ... 등의 범주(노드)를 나열할 수 있을 것이다.
이를 이용해 hierarchical model을 구성할 수 있게 되는데, 예를 들어 "terrier" 노드에서는 "terrier" 하위 노드에 대한 모든 conditional probabilites를 구하게 된다.

만약에 특정 노드의 absolute probability를 구하고 싶을 때에는 root node까지 모든 conditional probability를 곱해서 구할 수 있다.

학습 시에는 ground truth label을 가장 하위 노드부터 상위 노트까지 전파시켜서 각 같은 계층 구분에서 softmax로 학습될 수 있도록 한다. (예를 들어 "Norfolk terrier" = 1이면, "terrier" = 1, "dog" = 1, ...)
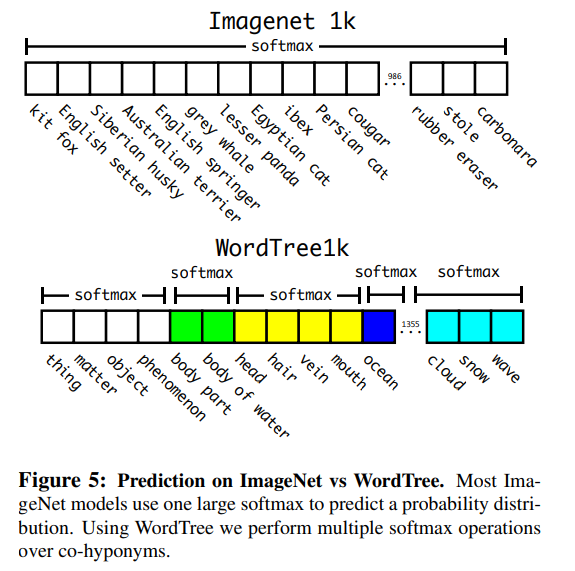
위에서 설명한 방법을 통해 COCO dataset과 ImageNet dataset을 합쳐서 9000개의 class를 학습시켰다.
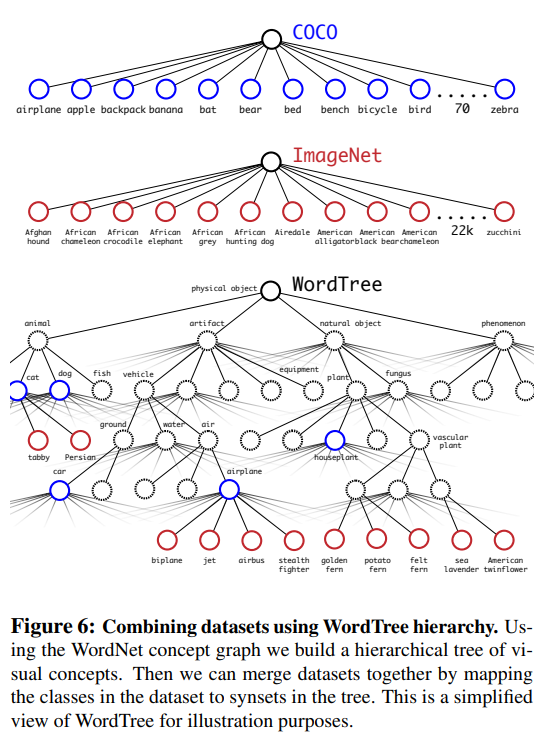
Discussion
YOLO v1을 성공적으로 발전시킨 논문으로, 여러 가지 방법을 시도했지만, 이미지 사이즈를 키워주는 것과 anchor box를 사용하는 것(정확히 anchor box는 아니지만)이 가장 키 포인트였던 것 같다. 개인적인 생각으로는 direct prediction이 좋은 아이디어였던 것 같다. Stronger 모델을 구축하기 위해 hierarchy를 고려하여 label dependency를 고려하 한 것도 매우 참신하지 않은가 싶다.
