Paper : You Only Look Once: Unified, Real-Time Object Detection (Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi / CVPR 2016)
Real-time object detection에 관심을 갖게 되면서, 가장 주로 사용되는 Yolo model의 시작인 seminar work인 You Only Look Once: Unified, Real-Time Object Detection을 시작으로 yolo model들을 method 위주로 차근차근 리뷰해보려고 한다.
Highlights
-
Localization과 classification을 동시에 수행하여 end-to-end training / one time evaluation이 가능한 Object detection (OD)모델 제안
-
Unified structure는 매우 빠른 inference 속도를 가져 real-time OD에 최적화
Overview
이전의 OD모델들은 보통 2-stage로 작동하여 먼저 region proposal을 하고 classifier가 proposed box를 분류하는 식이었다.
이 연구에서는 OD를 single regression problem으로 재해석하여 이미지로부터 직접 box coordinate와 그 box의 class probability를 구하도록 하였다.

Yolo의 가장 큰 장점은 속도이다. 이미지가 하나의 CNN을 통과하고 곧바로 box를 prediction하기 때문이다. Batch processing 없이 Titan X GPU에서 45fps로 작동한다고 한다. 즉, Yolo는 real-time video streaming을 처리하는데 특화되어있다.
Method
Yolo network는 이미지 전체 feature를 사용하여 각 class의 bounding box를 동시에 예측한다. 저자들은 region proposal된 위치의 feature를 이용하는 것보다 전체 feature를 이용하기 때문에 global reasoning을 더욱 잘 한다고 주장한다.
Yolo의 전체 process는 아래와 같이 간단하게 표현된다.
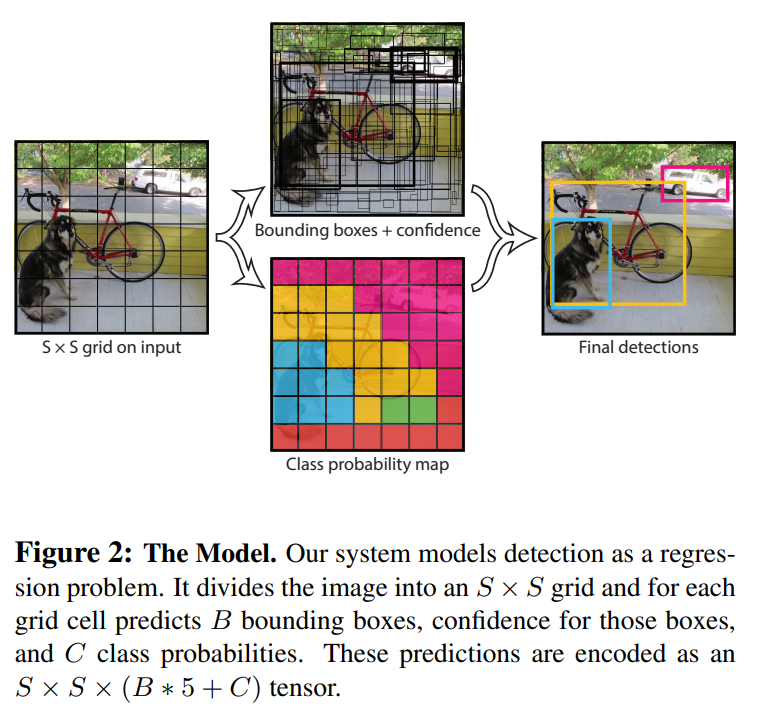
1) Input image를 의 grid로 나눈다.
이때, object center가 어떤 grid cell에 위치하게 되면, 그 grid cell이 해당 object를 detection하게 된다.
2) 각 Grid cell에 대해 개의 bounding boxes와 그 boxes의 confidence score를 예측
이 confidence score는 모델이 얼마나 confident하게 해당 박스 안에 object가 있다고 생각하는지, 그리고 얼마나 정확하게 그 box가 prediction을 하는지를 의미한다.
이 논문에서는 confidence를 아래와 같이 정의한다.
은 present하는지 여부를 나타내므로, object가 해당 cell안에 없으면 confidence는 0이고, 있다면, IOU값이 confidence가 된다.
** Grid Cell과 Bound Box
조금 헷갈릴 수 있는 부분이라서 그림을 그려서 이해해보자.
여기서 각 grid cell 당 개의 bounding box를 예측한다고 했는데, 각 bounding box는 5개의 prediction ($confidence, x,y,w,h $)을 포함한다.
그리고 유의할 점은, prediction의 좌표는 grid cell의 bound에 상대적인 bounding box의 center 좌표이고, 는 전체 이미지에 상대적인 width와 height이다. (두 값 모두 0~1사이의 값을 가지게 됨, x와 y는 서로 바뀌었을수도..)
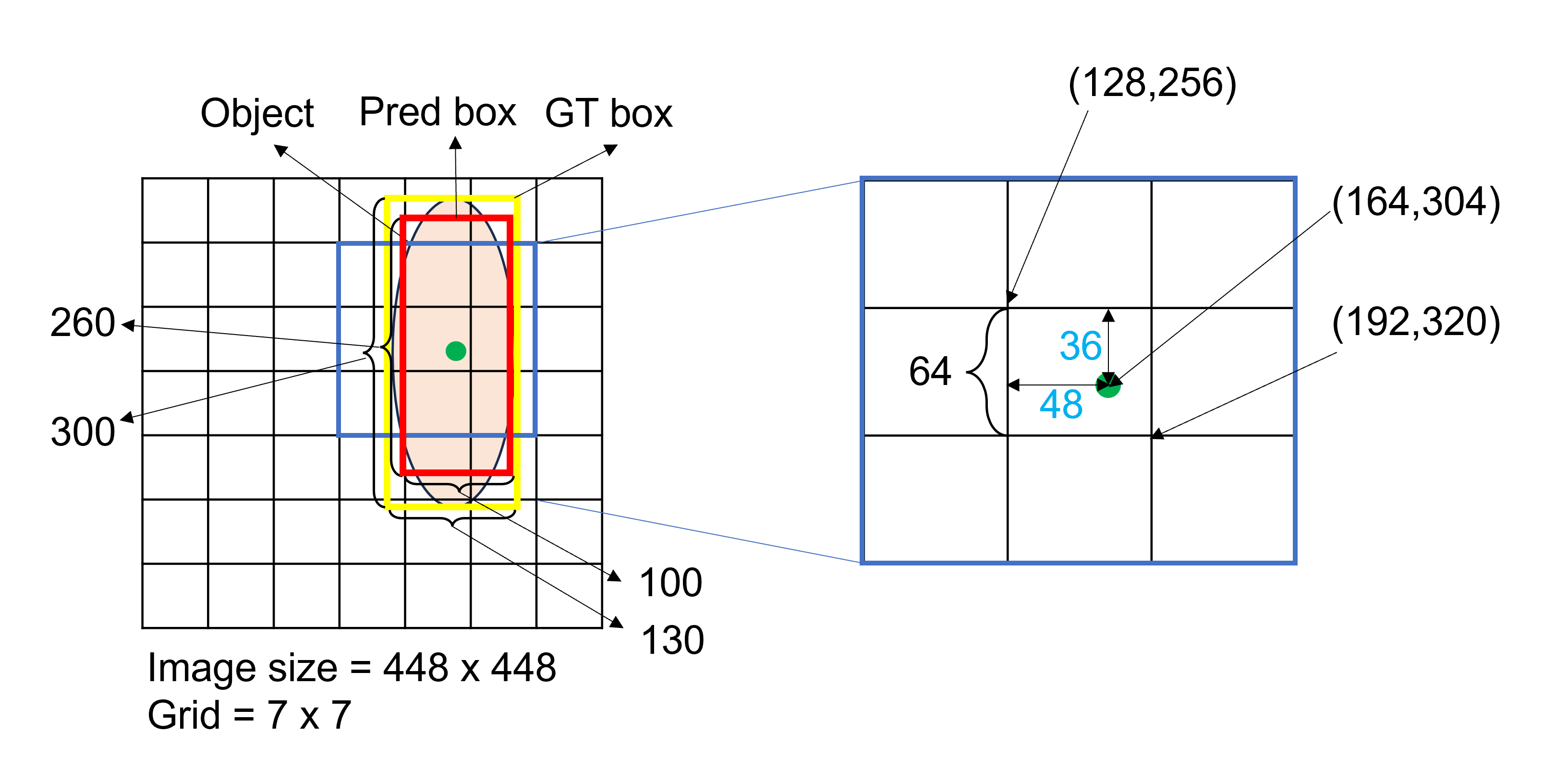
살색 타원이 Object이고 노란색 박스가 GT box, 빨간색 박스가 Pred Box, 초록색 점이 Object의 center point이다.
GT bounding box는 어떻게 표현될까?
먼저 object의 center point가 grid의 에 위치하므로, grid에서 만 confidence score GT가 1이고, 나머지는 0이다.
이제는 cell 안에서 center point의 좌표를 cell에 대해 정규화하면 된다. 크기의 grid cell 안에서 상대적인 center point의 위치는 이므로 정규화하면 가 된다. Width와 height는 전체 이미지 기준이므로 가 된다.
최종적으로 에서 정의된 object의 GT는 이 된다.
Pred bounding box는 이 GT값을 도출하기 위해서 Squared sum loss를 통해 학습된다. (아래 training에 설명: GT의 중심점을 포함하는 grid cell을 중심으로 학습이 된다.)
3) Bbox prediction과 동시에 개의 conditional class probability 예측
각 grid cell별로 bbox prediction과 함께, 그 grid cell이 어느 class에 속하는지에 대한 probability도 함께 예측한다. 이때, probability는 각 bbox마다 구해지는 것이 아니고, grid cell마다 한 set씩 구해진다.
해당 논문에서 사용한 PASCAL VOC dataset의 경우, Class 갯수가 20개, grid는 , 각 cell마다 bounding box 개를 사용하였는데, 이 경우 최종 prediction tensor는 개의 값을 가진다.
Network architecture
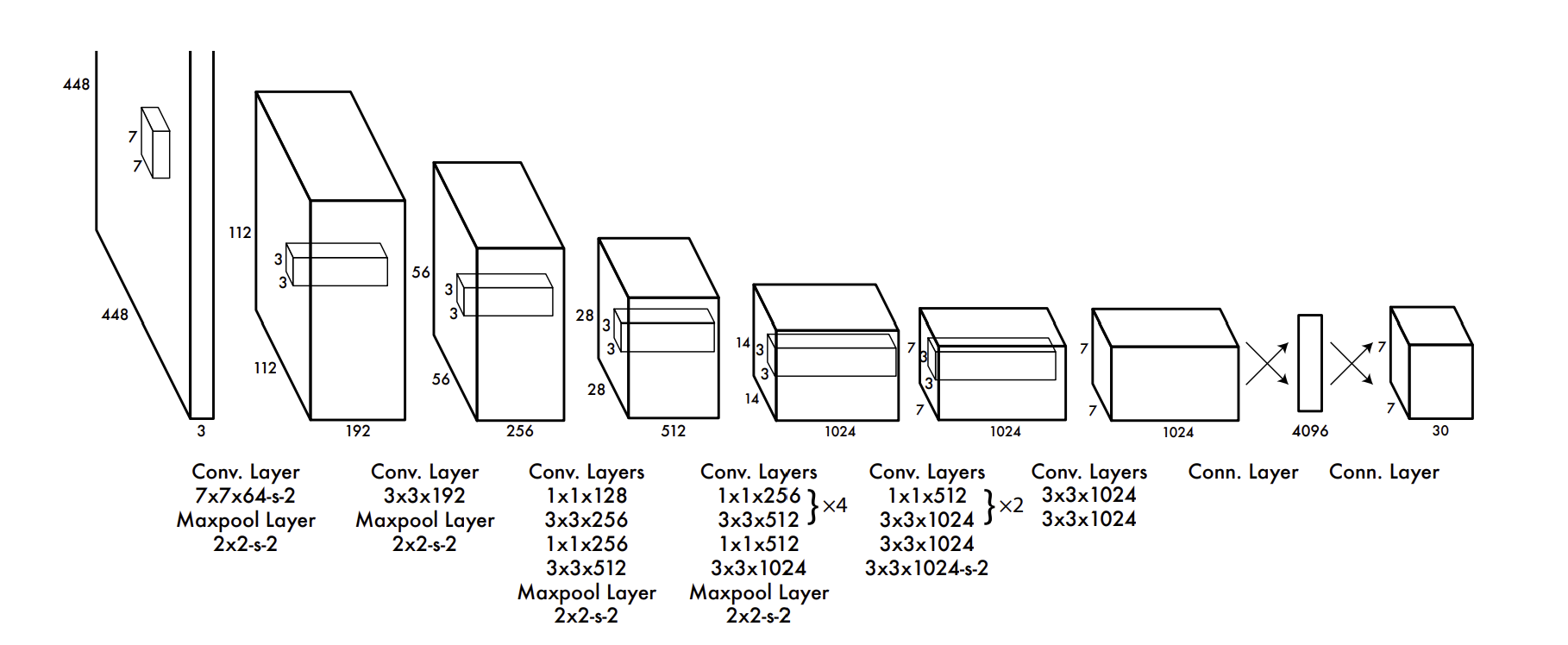
GoogleNet을 기반으로 하는 CNN으로 image feature를 추출하고, 얻어진 feature map에 Fully-connected layer를 통해 최종 prediction 을 구하는 구조이다.
Training
loss function을 보면 어떻게 학습되는지 더 이해하기가 쉽다.
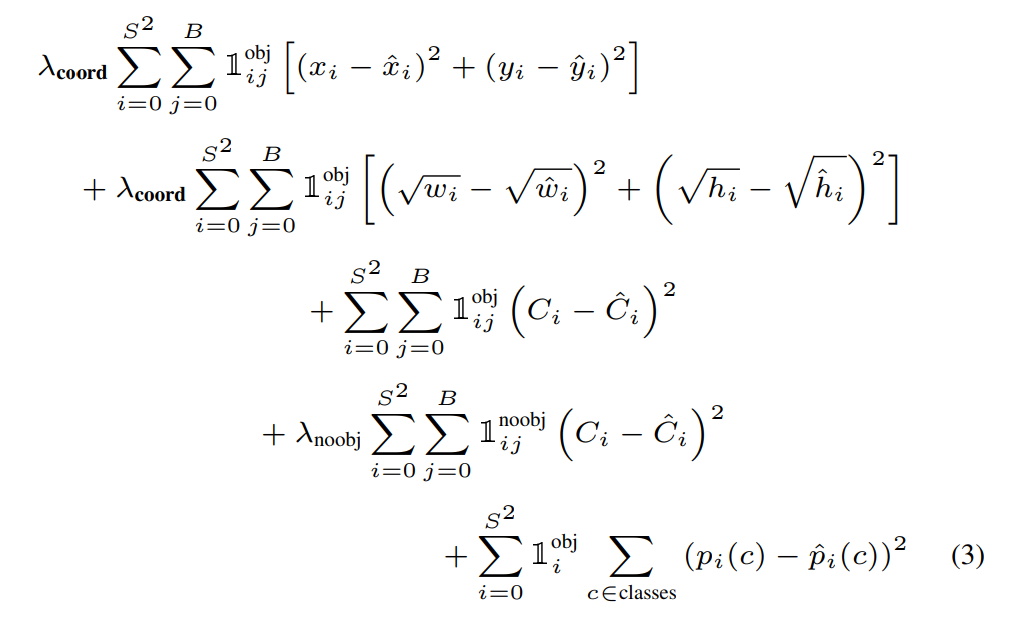
여기서 는 object가 해당 cell에 있는지 없는지를 나타내는 indicator, 는 cell 의 번째 bbox가 그 prediction에 대해 "responsible"한지를 나타내는 indicator이다. (결국 두 indicator는 같은 역할을 하긴 한다.)
("responsible"한 bbox는 개의 bbox중에서 GT와 가장 IOU가 높은 bbox를 의미하며, 이는 한 grid cell 가 predict한 여러 bbox중에서 하나만 취한다는 것을 의미한다.)
1) Localization loss
위의 두 줄은 localization loss를 의미하며, prediction에 responsible한 bbox에 대해 좌표와 값을 sum-squared error를 구한다.
2) Confidence loss
세번째, 네번째 줄은 confidence loss를 의미하며, responsible한 bbox에 대해 object가 있으면 1, 없으면 0을 출력하도록 학습한다.
3) loss weight
이미지를 grid로 나누고 나면, 사실 어떠한 object도 포함하지 않는 cell이 포함하는 경우보다 훨씬 많게 된다. 이런 경우 confidence score는 0이 되는데 gradient가 불안정해질 수 있으므로, 와 를 곱해줘서 객체를 포함하는 cell에 더 가중치를 준다.
4) classification loss
마지막 줄은 각 grid cell마다 classification loss를 구한 것으로, object가 해당 cell안에 위치할때만 계산한다.
Inference
Inference시에도 똑같이 하나의 네트워크를 이용하여 prediction하고, 각 grid cell마다 개의 bounding boxes와 그 bounding boxes의 confidence를 구하게 된다.
위에서 conditional class probability는 각 bbox가 아닌 grid cell마다 구해진다고 했는데, test time에는 각 bbox의 confidence score와 conditional class probability를 곱해서 최종적으로 각 box에 해당 class의 확률과 얼마나 잘 fit하는지를 확인할 수 있다.
또한, object가 적당한 크기라서 한 grid에 잘 들어가면 best지만, 큰 object나 여러 border가 겹쳐서 있는 object의 경우 multiple cell을 통해 detection하는 것이 좋고, Non Maximal Suppression을 적용하여 post processing해준다고 한다.
Discussion
Yolo v1 model은 1-stage detection model로, 한번의 process로 bounding box localization과 classification을 수행하는 network이다. 속도가 매우 빠른 장점을 가지고 있어, 여러 real-time detection task에 특화되어 있다.
하지만 몇 가지 단점도 존재한다. 먼저 Yolo v1 model에서는 각 grid cell이 하나의 class만을 추출하기 때문에 같은 grid에 있는 여러 object를 잘 구분하지 못한다는 단점이 있고, 7x7의 비교적 큰 grid로 인해 작은 물체를 탐지하지 못하며, 한 grid가 2개의 boundind box를 만드므로 살짝 떨어지는 성능을 가진다.
아래 그림은 detection 결과 예시이다.

