본 포스팅 시리즈는 다양한 머신러닝 테크닉에 대해 수학적 관점과 실용적 관점에서 정리한다.
필자는 수학을 전공했기 때문에 수학적 접근과 용어에 대해 익숙하게 사용한 것이 있지만, 수학을 전공하지 않은 사람들에겐 다소 낯선 접근과 용어가 있을 수 있다.
최대한 그러한 부분을 자세히 설명하려 노력하였지만 필자의 타전공자에 대한 '공감능력부족'으로 효과적으로 전달되지 못한 부분이 있을 것으로 생각된다.
이 글을 읽어주시는 분께 일차적으로 감사드리며, 해당 부분에 대해 질문이나 코멘트를 남겨주시는 분께는 거듭제곱으로 감사드림을 말씀드린다.
Support Vector Machine
서포트 벡터 머신은 딥러닝이 등장하기 이전에 가장 유명하고 성능 좋은 머신러닝 모델이었다고 한다.
현재는 다소 실무에서 사용되는 정도가 줄어들었겠지만, 서포트 벡터 머신에 적용되는 다양한 수학적 테크닉들은 인공지능을 이해하고 연구하는 데에 여전히 훌륭한 인사이트를 준다고 생각한다.
특히 서포트 벡터 머신의 아이디어는 유클리드 기하학과 최적화 이론으로 설명이 된다는 점은 수학자들에게 있어서 굉장히 매력적이다.
본 포스팅의 내용은 다음의 자료들을 참고했다.
- Mathematics for Machine Learning (Deisenroth, Marc Peter and Faisal, A. Aldo and Ong, Cheng Soon)
- The Elements for Statistical Learning (Trevor Hastie, Robert Tibshirani, Jerome Friedman)
- 김민준님(이화여자대학교, 수학과 석사)의 SVM Lecture note
- 김원화 교수님(포항공과대학교, 인공지능대학원 교수)의 데이터 마이닝 Lecture note
- Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow (Aurelien, Geron)
3. Hard Margin SVM (1)
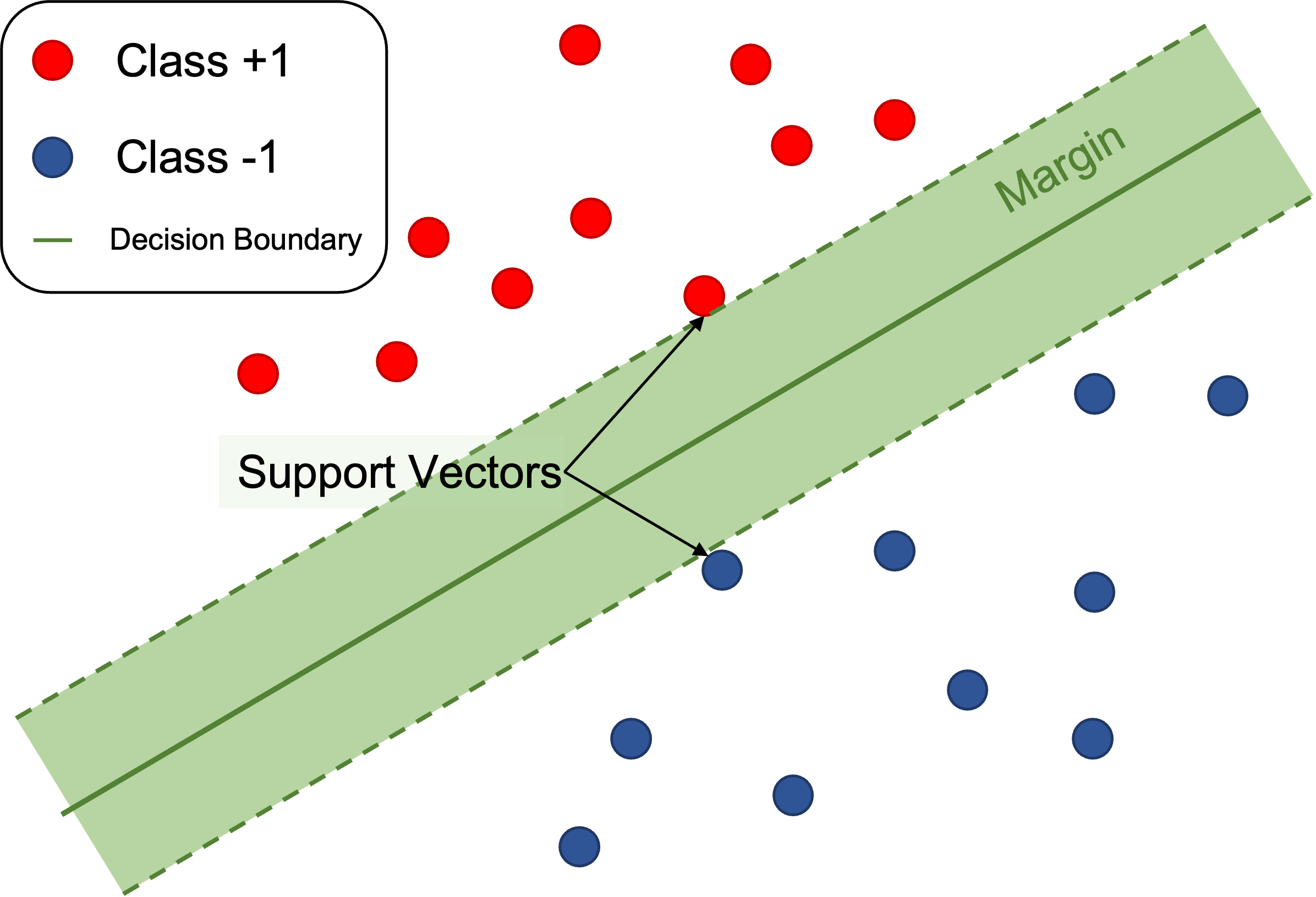
마진(margin)은 결정경계와 그것과 가장 가까이 있는 훈련 데이터와의 거리를 말한다.
마진은 학창시절에 배운 점과 직선 사이의 거리공식을 일반화한 개념으로 계산한다.
3.1 점과 직선 사이의 거리공식
먼저 점과 직선 사이의 거리 공식을 복습해보자.
중고등학교 시절 점 와 직선 사이의 거리 는 아래의 공식으로 구했었다.
이 공식은 보통 고등학교 1학년 과정에서 배우게 되는데 고등학교 1학년때는 벡터의 개념을 배우지 않기 때문에 그 유도과정이 상당히 작위적이다.
여기서는 벡터를 이용해 위 공식을 다시 유도해보고자 한다.
먼저 직선이 어떻게 정의되는지 살펴보자.
직선의 방정식이라고 말하면 보통 일차함수 꼴을 생각한다.
이 일차함수에서 의 계수 는 직선의 기울기를, 는 -절편을 의미했다.
그런데 유달리 점과 직선 사이의 거리 공식을 사용할 땐, 직선을 일차방정식 의 꼴로 정의했다.
아직 내적의 개념을 배우지 않은 고등학교 1학년에게 이러한 형태의 직선의 방정식에서 와 그리고 상수항이 가진 계수 의 의미를 해석하기가 어려웠다.
이 포스팅을 읽고있는 독자들 중에서도 혹시 이 공식의 해석에 대해 잘 몰랐던 분이 계시다면, 이 기회에 배워가보시길 바란다.

먼저 원점을 지나는 직선 을 생각해보자.
이 직선 위의 점은 방정식 을 만족시키는 벡터 들의 집합으로 표현된다.
그런데 를 벡터로 본 순간, 식 는 벡터의 내적 공식으로 보인다!
즉, 방정식 은 사실 두 벡터 과 의 내적 의 값이 0이 된다는 의미다.
내적이 0이 된다는 의미는 두 벡터가 수직임을 의미한다.
따라서 직선 은 벡터 와 수직인 벡터들의 자취를 의미하게 된다.
이런 점에서 직선의 방정식 의 계수벡터 는 직선의 진행방향에 수직인 방향을 나타내고, 이를 법선벡터(normal vector)라고 부른다.
이제 좌표공간 위의 점 와 원점을 지나는 직선 사이의 거리를 구해보자.
점 를 점 의 직선 위로의 정사영이라고 하자.
그런데 앞에서 법선벡터 는 직선 과 수직이라고 했으므로, 와 는 평행하다.
즉, 어떤 상수 가 존재하여,
가 성립한다.
이때 법선벡터 의 크기를 1로 정규화해 방향에 대한 정보만 남겨주면, 는 를 방향으로 거리 만큼 평행이동한 것이므로,
이고
임을 유도할 수 있다.
그런데 와 사이의 거리 는
이 성립하므로
가 성립한다.
이때 이고 이므로 위 식을 정리하면,
이 되어,
임을 얻는다.
중간에 몇 가지 계산과정을 생략했는데 손으로 계산해보면서 생략된 부분을 직접 매꾸어 보면 이 유도과정을 이해하는 데에 도움이 될 것이다.
(원점을 지나지 않는 직선의 케이스는 평행이동의 개념으로 옮겨서 이해한다. 추후 추가 예정)
3.2 마진(margin)
이제 마진을 정의하기 위해 필요한 준비는 모두 끝났다.
가 결정경계와 가장 가까운 훈련 데이터라고 하고, 결정경계는 선형함수 에 의해 정의된다고 하자.
이때 선형함수의 법선벡터 에 대하여, 이라 가정한다.
와 결정경계 사이의 최단거리는 의 결정경계 위로의 사영 와 사이의 거리 로 정의된다.
그런데 결정경계와 단위법선벡터 가 수직이므로, 벡터 는 로 표현될 수 있다.

위와 같은 개념을 생각하면, 결정경계의 양의 방향과 음의 방향으로 만큼 떨어진 영역을 생각할 수 있다.
이 영역 또는 이 영역의 폭을 마진(margin)이라고 부른다.
마진을 이용하면 모든 에 대하여, 가 되도록 하는 선형함수 를 찾는 문제로 선형분류 문제를 변형할 수 있다.

마진을 최대화 하는 선형함수 를 찾는 문제는 다음의 최적화문제로 표현할 수 있다.
SVM은 위 최적화문제의 해로서 결정경계를 선택한다.
즉, 마진의 경계 외부에서 클래스가 분류되도록 하면서 마진의 크기를 최대화 시키는 문제다.
마진 최대화 문제를 이렇게 해석하면 직관적으로 문제를 이해하기가 편리하다.
그러나 이 최적화 문제를 푸는 데에는 다소 유리하지 않다.
다음 포스팅에서는 이 최적화 문제를 수학적으로 풀기 쉬운 형태로 유도하는 방법에 대해서 다루도록 하겠다.
주의!
마진의 개념은 유클리드 공간 상의 거리 개념으로부터 유도된다.
그러나 거리 개념은 데이터의 스케일에 따라 혼란을 야기할 수 있다.예를들어, 입력변수 가 '계좌잔액', '개설연도'로 구성된 데이터라고 할 때 , , 세 가지 샘플의 거리는 어떻게 이해할 것인가?
와 는 개설연도가 같지만, 계좌잔고가 100배나 차이나므로 거리가 굉장히 크다.
와 는 계좌잔고가 20원밖에 차이가 나지 않지만, 개설연도가 20년이나 차이가 난다.
와 중에 와 더 유사한 데이터는 어느 것인가?
이는 문제에 따라 다를 것이다.
그러나 단순히 Euclidean 거리로 계산했을 때엔 와 사이의 거리가 와 사이의 거리보다 매우 크다.이러한 점 때문에 거리 개념을 기반으로한 SVM 모델은 데이터의 scale에 민감하다고 할 수 있다.
따라서 SVM 모델을 학습하기 전에 스케일링을 위한 전처리기법(e.g. Standard Scaling)을 수행하는 것이 일반적이다.
데이터의 스케일링에 대하여 더 자세한 논의는 후에 하도록 하고 지금은 데이터의 스케일링 이슈는 고려하지 않도록 하자.

yif(xi)>=d 가 어떻게 나온 식인가요? 혹시 사이에 마이너스가 빠진건가요?