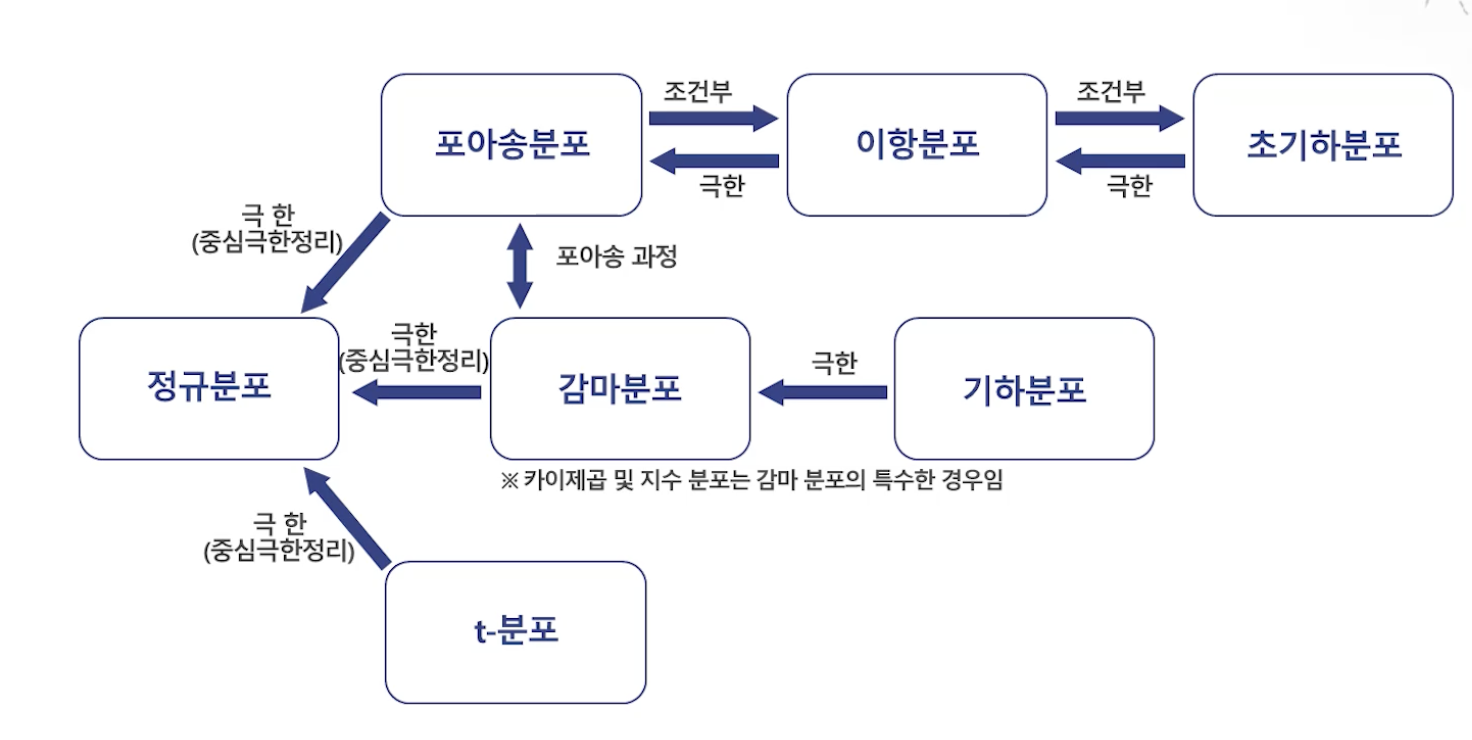
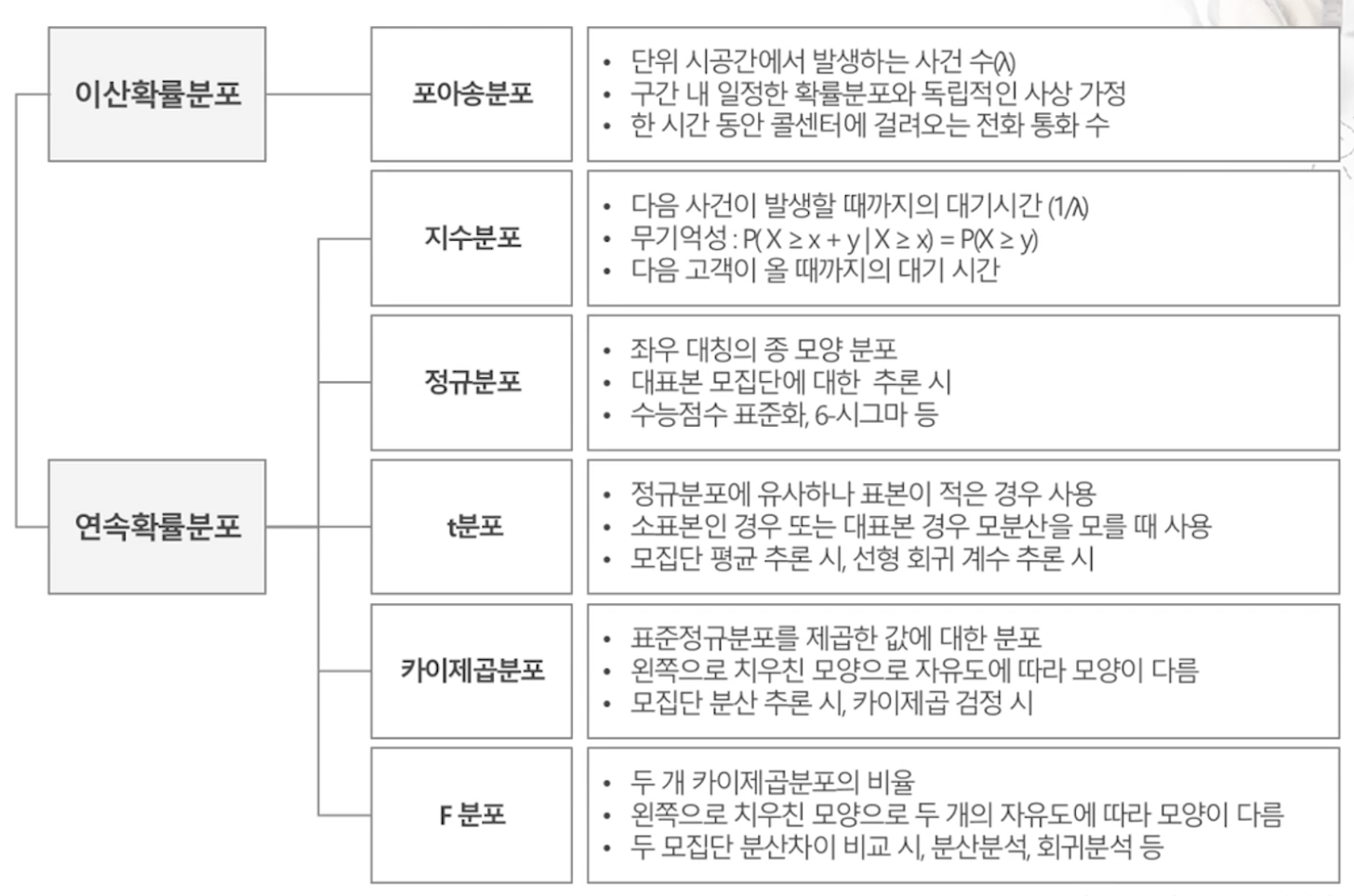
확률변수/확률분포
- 확률변수: 표본공간의 원소를 실수로 대응한 값. 동전의 앞앞을 0, 앞뒤를 1, 뒤뒤를 2로 매핑하는 행위.
- 확률분포: 확률변수와 그 값이 나올 수 있는 확률을 대응시켜 표시하는 것. 앞앞은 4분의 1, 앞뒤는 4분의 2, 뒤뒤는 4분의 1
확률분포함수는 이산확률분포, 연속확률분포 함수가 있다. 이산확률분포는 확률질량함수, 연속확률분포는 확률밀도함수로 나타낼 수 있다.
이항분포(Binomial Distribution)
확률 시행시 결과가 2종류인 시행을 베르누이 시행이라고 한다. 동전 던지기가 그 예이다. 주사위에서 3이 나오는 케이스와, 그 이외의 결과가 나오는 케이스도 베르누이 시행이다. 상호배타적인 결과를 갖는다.
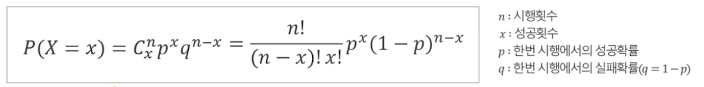
- 이항분포의 형태는 모수인 시행횟수 n과 성공확률 p의 값에 따라 결정된다.
- 만일 성공확률 p=0.5에 가까우면 시행횟수 n의 크기에 관계없이 이항분포는 좌우대칭의 종모양을 나타낸다.
- 반대로 시행횟수 n이 크면 성공확률 p의 크기에 관계없이 이항분포는 좌우대칭을 이룬다.
- 만일 p<1/2이고 n이 작은 경우에 이항분포는 오른쪽 꼬리분포를 나타낸다.
- 만일 p>1/2이고 n이 작은 경우에 이항분포는 왼쪽 꼬리분포를 나타낸다.

-
포아송분포(Poisson Distribution) : 일정한 단위시간, 단위거리, 단위면적과 같이 어떤 구간에서 어떤 사건이 랜덤하게 발생하는 경우에 사용할 수 있는 이산형 확률분포.
적용조건-> 구간마다 발생하는 사상은 서로 독립적이고, 사상의 발생확률은 구간의 길이에 비례하며, 작은 구간에서의 사상이 발생할 확률은 무시할만 하고, 구간마다 확률분포가 일정한 경우.
활용예-> 1시간동안 은행에 방문하는 고객의 수, 1시간동안 콜센터로 걸려오는 전화의 수, 책1페이지당 오탈자가 발생하는 건수, 반도체 웨이퍼 25장 당 불량 건수...
포아송분포의 람다(𝛌)값이 커질수록 정규분포에 수렴한다. -
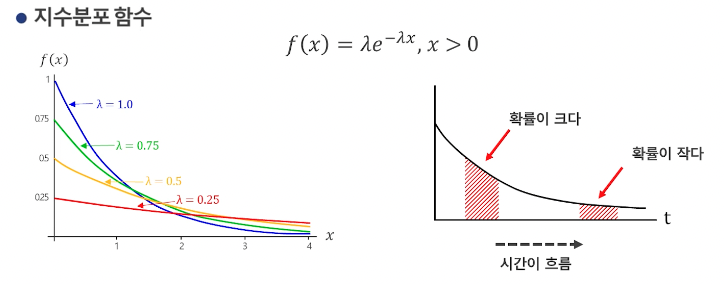
지수분포(Exponential Distribution) : 사건이 서로 독립일 때, 일정 시간 동안 발생하는 사건의 횟수가 포아송 분포를 따른다면, 다음 사건이 일어날 때까지 대기시간이 지수분포를 따른다. 항상 양의 값만 갖고, 시간이 지날수록 확률이 작아진다.
정규분포
연속확률변수의 측정으로 얻는 많은 표본을 그린 히스토그램 정규곡선(normal curve)이라고 하는데, 연속확률분포의 형태가 종같이 보이는 부드러운 곡선임을 의미한다. 정규곡선은 정규분포의 확률밀도함수에 의해서 결정할 수 있다.
중심극한정리에 의해 독립적인 확률변수들의 평균은 정규분포에 가까워지는 성질이 있기 때문에, 수집된 자료의 분포를 근사하는 데에 자주 사용된다.
중심극한정리 : 모집단이 어떤 분포를 따르든, 거기서 추출한 샘플인 표본들의 각각의 평균들이 있을 텐데, 그 평균들의 평균은 무조건 정규분포를 따른다. 표본 평균의 평균.
-
정규곡선은 종모양을 갖는다.
-
정규분포는 평균을 중심으로 좌우대칭을 이룬다. 따라서 평균=중앙값=최빈값이다.
-
정규분포의 형태와 위치는 평균(𝛍)과 표준편차(𝛔)가 결정한다.
-
정규곡선은 x축에 닿지 않아 확률변수 X의 범위는 -∞<x<∞이다.
-
정규곡선 밑의 면적은 1이다. 따라서 평균을 중심으로 오른쪽, 혹은 왼쪽으로 곡선 밑의 면적은 0.5이다.
-
정규곡선 밑의 두 점 사이의 면적은 정규확률변수가 이들 두 점 사이를 취할 확률이다.
-
표준정규분포: 확률변수Z가 평균0, 분산1인 정규분포.
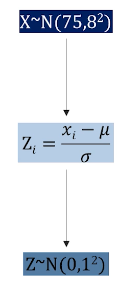
-
t분포(Student's t-Distribution) : 표본을 보면서 모집단의 평균값을 추론할 때 쓴다. 정규분포와 유사하게 좌우 대칭의 종모양으로 중심은 0. 자유도에 따라 형태가 달라진다. 표본의 수가 충분히 크면 표준정규분포와 거의 같아지고, 표본의 수가 작으면 양쪽 꼬리가 더 두터워진다.(데이터가 중심에 덜 모여 있다는 의미). 표본의 수가 적을 경우, 평균 검정을 위해 고안된 분포이다. 모집단의 분산을 모를 경우, 가설검정, 회귀분석 등에 활용된다.
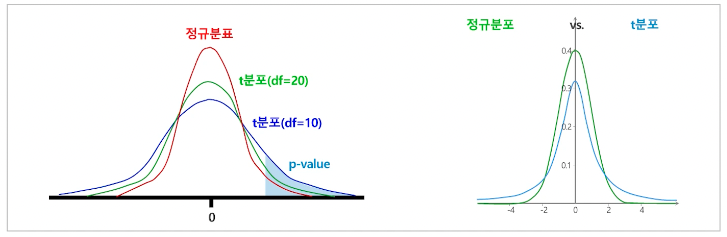

-
카이제곱 분포(Chi-squared Distribution) : 모집단의 분산을 추론하고 싶을 때 쓴다. Z1,Z2...Zk가 서로 독립적인 표준정규분포(0,1)을 따를 때, 이들의 제곱합 ΣZi²은 자유도가 k인 𝞆²분포를 따른다. 자유도가 k인 𝞆²분포의 평균은 k, 분산은 2k를 따른다. 항상 양수이며, 심하게 왼쪽으로 쏠린 분포로 자유도에 따라 모양이 변하고 자유도가 커질수록 정규분포에 가까워진다.
-
F 분포(F Distribution) : F가 나오면 분산을 떠올려야한다. 회귀에 쓰인다. 분산의 비를 이용해 특징을 추출한 것이다. 두 모집단의 분산을 이용해 ANOVA 등을 구한다. 두 분산간의 동질성 여부, 평균치 간의 차이 유무를 검정하는데 쓴다. F검정, 분산분석, 회귀분석 등.