Overfitting
Overfitting이란 신경망이 훈련 데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응하지 못하는 상태를 말한다.
Overfitting은 주로 다음의 두가지 경우에 일어난다
- 매게변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음
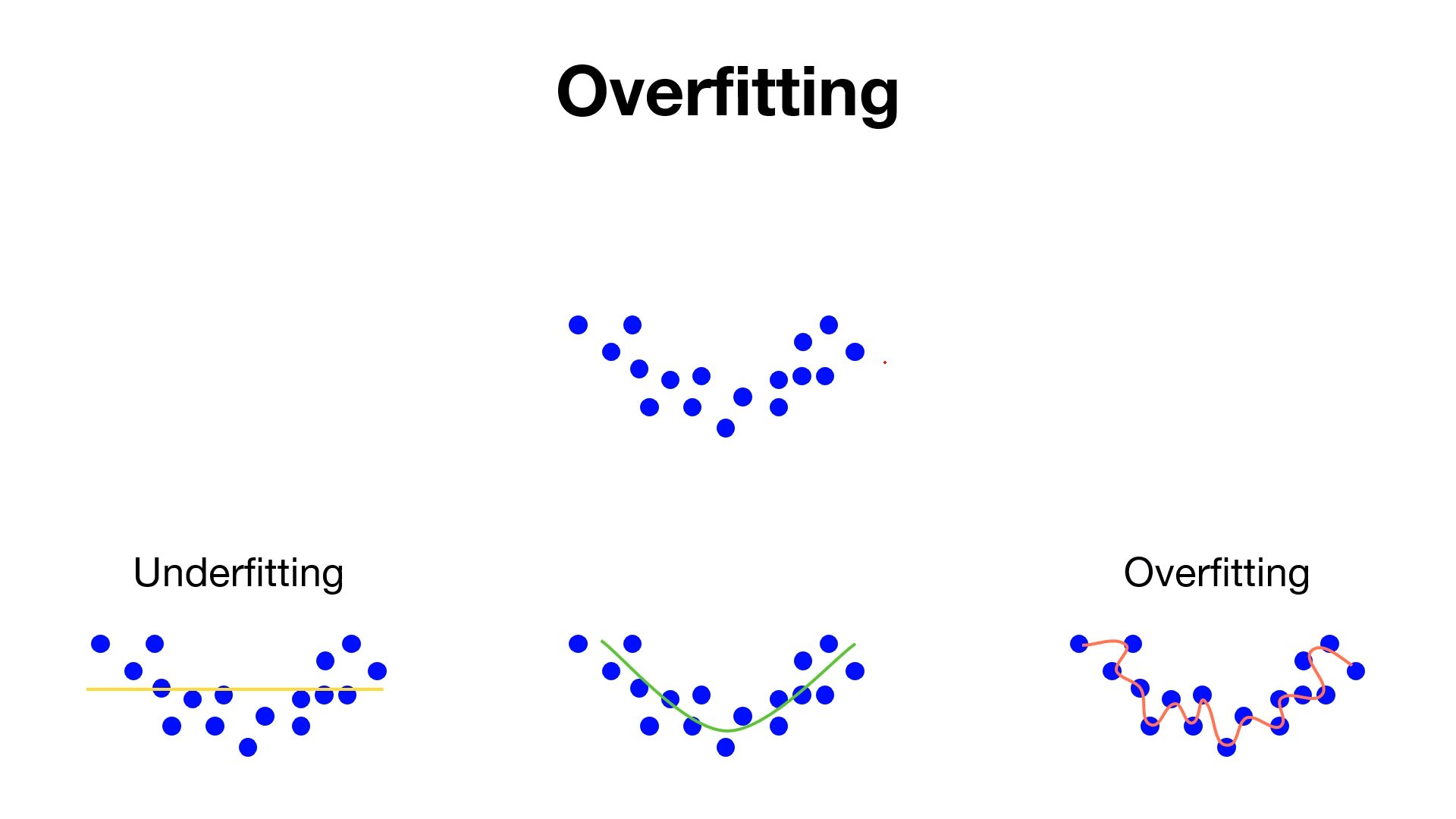
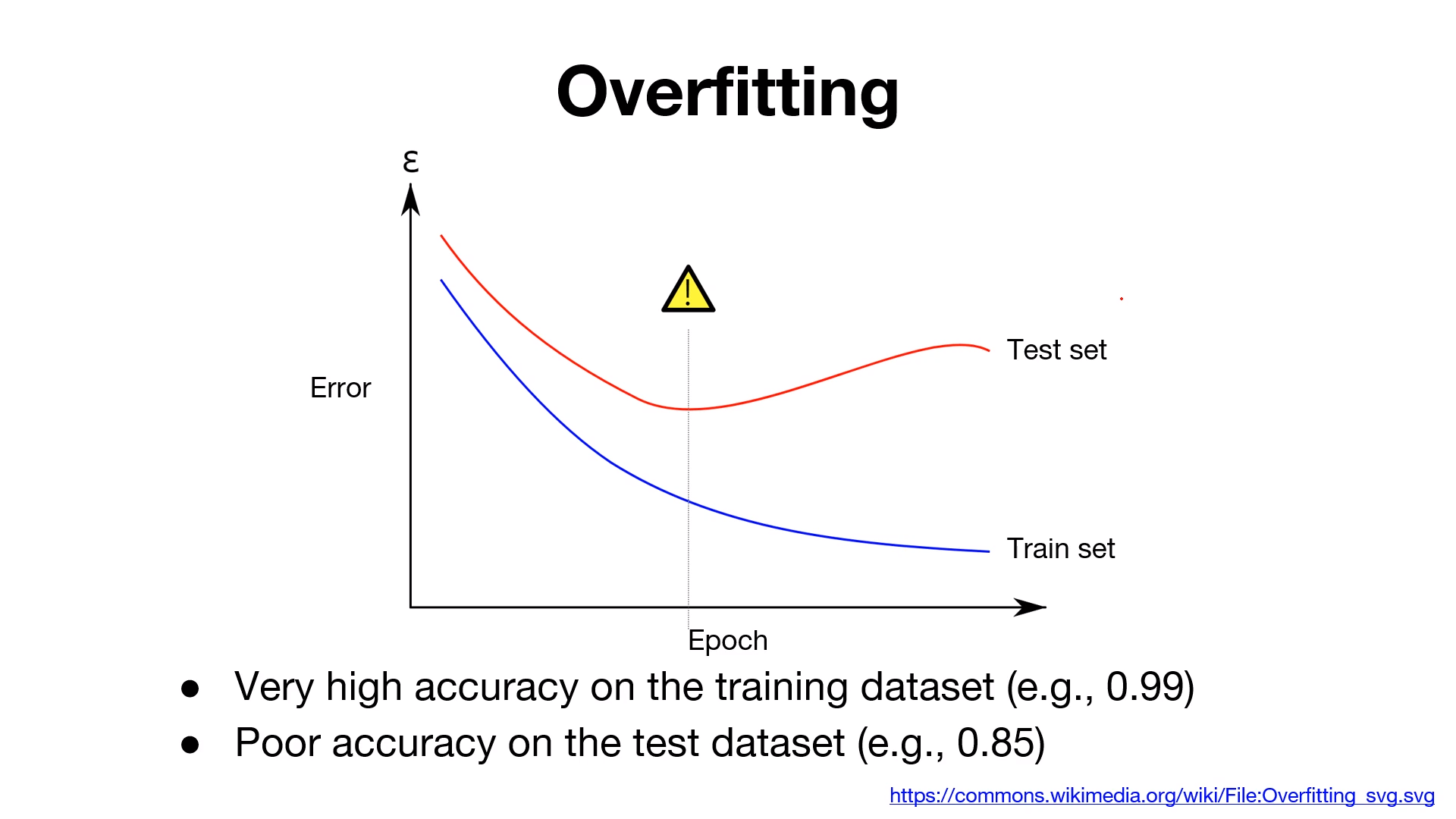
훈련데이터(train set)을 사용하여 측정한 정확도는 높은데 비해, 시험데이터(test set)에 대해서는 큰 차이를 보인다.
이처럼 정확도가 크게 벌어지는 것은 훈련데이터에만 적응(fitting)해버린 결과이다.
훈련때 사용하지 않은 시험데이터에는 제대로 대응하지 못하는 것을 그래프를 통해 확인할 수 있다.
Overfitting 문제를 해결할 수 있는 방법
- training data를 늘린다
- feature를 줄인다
- Regularization term을 추가한다
- Dropout
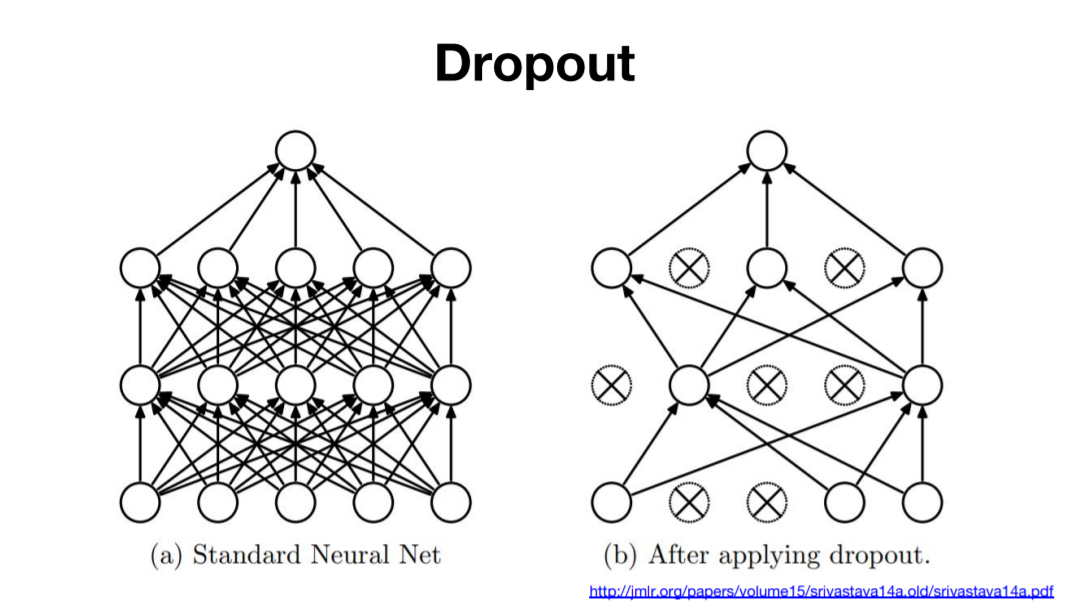
Dropout(드롭아웃)
Dropout은 뉴런을 랜덤하게 삭제하면서 학습하는 방법이다. 훈련때는 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택하고, 시험 떄는 모든 뉴런에 신호를 전달한다.
단, 시험때는 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력한다.
코드 구현
# nn layers
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
linear4 = torch.nn.Linear(512, 512, bias=True)
linear5 = torch.nn.Linear(512, 10, bias=True)
relu = torch.nn.ReLU()
dropout = torch.nn.Dropout(p=drop_prob)
# model
model = torch.nn.Sequential(linear1, relu, dropout,
linear2, relu, dropout,
linear3, relu, dropout,
linear4, relu, dropout,
linear5).to(device)class Propout:
def __init__ (self,dropout_ratio=0,5):
self.dropout_ratio=dropout_ratio
self.mask=None
def forward(self,x,train_flg=True):
if train_flag:
self.mask=np.random.rand(*x.shape)>self.dropout_ratio
return x*self.mask
def backward(Self,dout):
return dout*self.mask
self.mask에 삭제할 뉴런을 False로 표시한다.
self.mask는 x와 형상이 같은 배열을 무작위로 생성하고, 그 값이 dropout_ratio보다 큰 원소만 True로 설정한다.

Towards the goal 👀