Hypothesis Function(Linear Regression)(가설 함수)
H(x)=WX+b
W=weight 하나의 matrix b=Bias 벡터
인공신경망의 구조를 나타낸다. 주어진 input x에 대해 어떤 output y를 예측할지 알려주는 H(x)로 표시한다.
W.torch.zeros(1,requires_grad=True)
b=torch.zeros(1,requires_grad=True) #torch.zeros 후 W와 b를 초기화
hypothesis=x_train*W+b
Cost function(비용함수)
모델 예측값이 실제 데이터와 얼마나 다른지 나타내는 값으로, 잘 학습된 모델일수록 낮은 cost를 가진다.
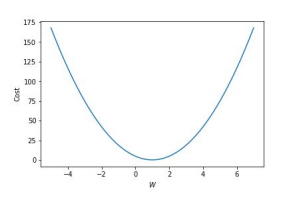
W가 1에서 멀어질수록 예측값과 실제 데이터가 다르므로 cost가 높아진다.
Gradient Desecent(경사하강법)
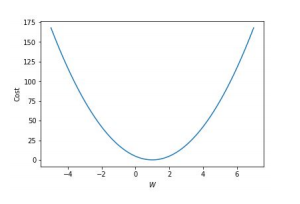
기울기를 Gradient라고 하고, cost function을 최소화 하려면 기울기가 음수일때 W는 커져야하고, 기울기가 양수일때는 W가 더 작아져야 한다.
기울기가 가파를수록 cost가 큰 것이니 W를 크게 바꾸고,
평평할수록 cost가 0에 가까운 것이니W를 조금 바꿔야 할 것이다.
gradient=2torch.mean((W x_train-y.train)x_train) #torch.mean()으로 dataset전체의 평균 gradient 구함
lr=0.1
W-=lrgradient #정의한 상수로 W업데이트
mean(): 평균값 출력

Towards the goal 👀