1. NMT란?
1.1 NMT란?
인간의 신경을 모방한 머신러닝 기법이다.
감각기관을 통해서 정보가 들어오면, 신경세포인 뉴런이 그것을 뇌에 전달한다. 그러면 뇌는 정보를 종합해서 판단하여 다시 명령을 내리게 된다.
이때 신경세포인 뉴런이 서로 연결되면서 복잡한 연산과정을 거치게 된다.
이러한 두뇌 정보처리과정을 모방해서 만든 알고리즘이 NMT이다.
1.2 NMT원리
머신러닝 기술이 적용된 엔진을 통해서 전체적인 문맥을 파악하고, 문장을 통째로 번역한다.
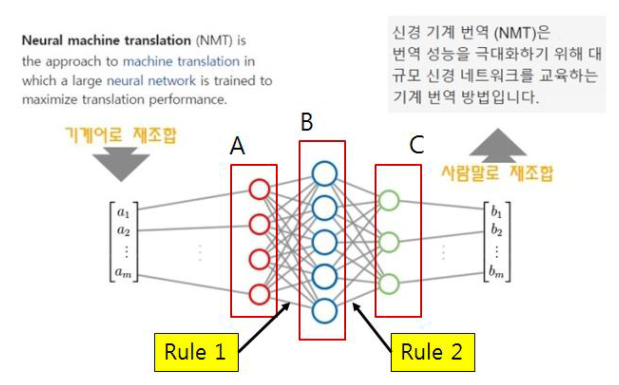
기계어 재조합된 문장A를 문장 C로 번역할 것이다.
A영역의 단어들을 숫자화한 후 순서 재조합하고,
A영역의 모든 숫자를 Rule1로 적용하고 B영역 숫자로 재배치한다.
B영역의 모든 숫자를 Rule2적용하고 C영역 숫자로 재배치한다.
2. 모델 구조
거의 모든 NMT모델은 인코더(Encoder)와 디코더(Decoder) 프레임워크를 사용한다.
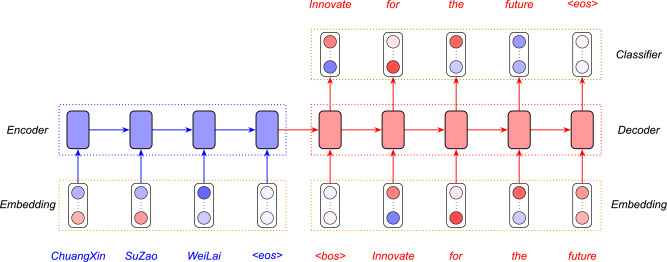
<bos>와<eos>는 각각 시작과 끝을 나타내는 특수기호이다.
신경망은 입력층과 출력층 사이에 여러층의 보이지 않는 Hidden layer층이 있다. NMT는 이런 다층적 연산과정을 거치기 때문에 전후 문맥상황을 파악하여 가장 적절하고 흐름에 맞는 번역을 해내게 된다.
2.1 Encoder
인코더는 번역에 사용될 문장이 입력된다. 이때 문장의 각 단어의 임베딩 벡터가 각 시점마다 입력값으로 사용된다. 이때 RNN류 모델(LSTM,GRU등)을 사용할 수 있다. NMT는 보통 대부분 RNN모델을 사용한다.
hidden state는 번역에 사용될 문장의 정보를 담고있는 벡터가 되어서 디코더의 hidden state로 정보를 전달한다.
(임베딩이란? 비정형화된 텍스트를 숫자로 바꿔줌으로써 사람의 언어를 컴퓨터 언어로 번역하는 것을 뜻한다.)
2.2 Decoder
인코더의 마지막 hidden state에서 넘어온 정보와 문장의 시작을 의미하는 입력값을 받아서 디코더는 첫 단어인 Innovate를 내놓는다.
그리고 다음으로 올 단어를 예측하기 위해서 처음 예측값인 Innovation을 두번째 시점의 입력값으로 사용하게 된다. 이런 방식으로 이런 방식으로 이전 시점의 예측값이 현재 시점의 입력값으로 반복해 사용된다.
3. NMT 모델 수식화
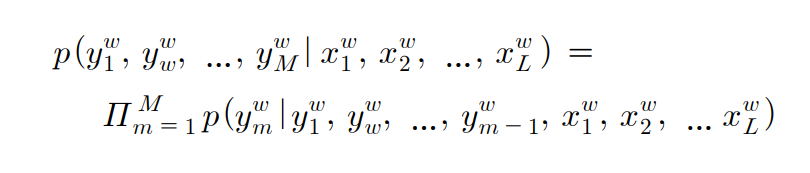
입력 문장을 L개의단어로 이루어진 x라고하고, 타겟 문장은 M개의 단어로 이루어진 y라고 하자.
4. 학습 구성 요소 기술
4.1 Back-Propagation(역전파)
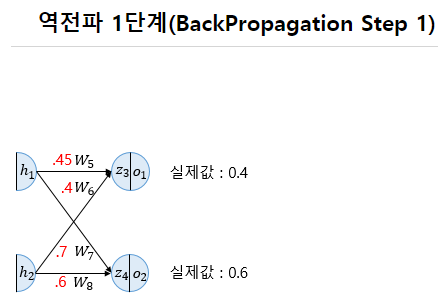
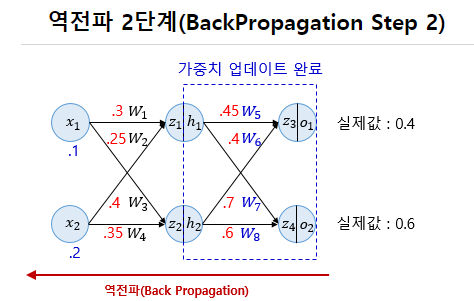
순전파가 입력층에서 출력층으로 향한다면 역전파는 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트해 나간다.
각 시점의 예측값과 실제값 사이의 손실함수를 계산하고, 이 값의 평균을 내서 최종 손실값으로 사용한다.
4.2 AutoEncoder(오토인코더)
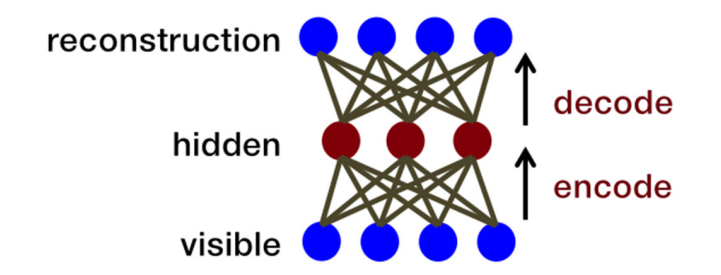
심층망이 역전파만으로 학습이 쉽지 않을 경우, 사전학습과정을 사용할 수 있는데, 심층망의 계층들을 미리 비지도습(Unsupervised learning)으로 학습 후 계층들을 연결하여 심층망을 구성한다. 오토인코더는 비지도학습 방식으로 훈련된 인공신경망이다.
AutoEncoder 구조
NMT에서 오토인코더 적용
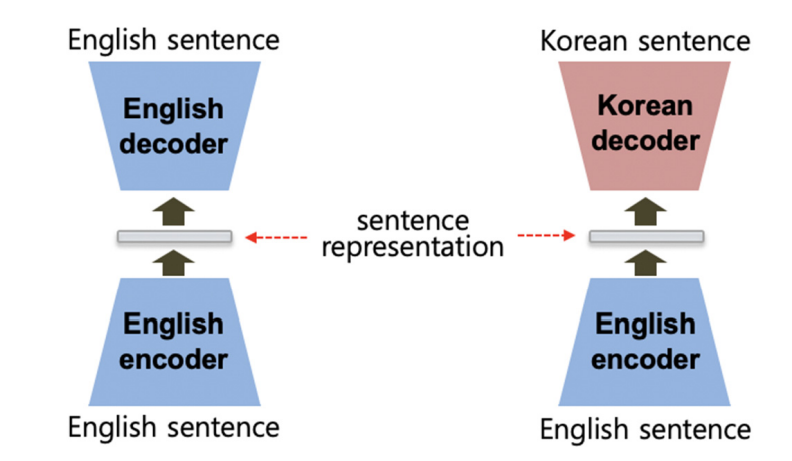
문장을 오토인코딩할 수 있는데, 입력 문장이 벡터로 인코딩되어 표현되고 디코더가 원래 문장을 복구해 낼 수 있다.
4.3 Word Embedding(워드임베딩)
워드 임베딩은 단어를 벡터로 표현하는 방법이다.
심볼로 이루어진 단어들의 연속인 문장을 신경망에 입력하려면 이들을 벡터로 변환해야하는데, 워드임베딩이라는 절차를 거쳐 변환한다.
워드임베딩을 위해서 우선 모든 단어들을 모은 단어사전을 만든다.
이 사전은 보통의 사전과 달리 그저 단어들의 리스트이다.
단어의 개수를 N이라고 하자
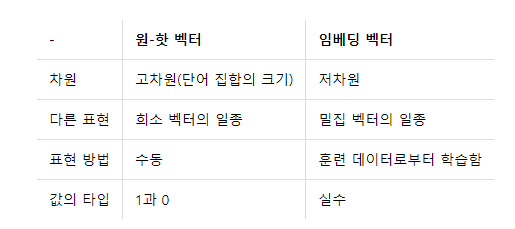
사전이 만들어지면 순서가 정해지는데, 순서가 특별한 의미가 없지만, 한번 정해진 순서는 그 단어의 아이디가 된다. 이 아이디를 이용해서 각 단어에 해당하는 원핫(one-hot)표현의 벡터를 만들 수 있다.
예를들어,
단어 개수가 총10K이면 10K차원의 벡터를 만들고, 그 단어의 아이디가 7이면 10K 차원의 벡터에서 모든 값은 0이고 7번째 값만 1이 되는 벡터가 된다. (단어가 벡터형태로 표현됐지만, 각 단어 사이의 거리는 모두 동일하다.)
원핫 벡터를 의미를 표현하는 벡터로 변환하는 과정은 워드임베딩 행렬을 사용한다.
D차원의 워드임베딩을 얻으려면 임베딩 행렬은 NxD 행렬이 된다.
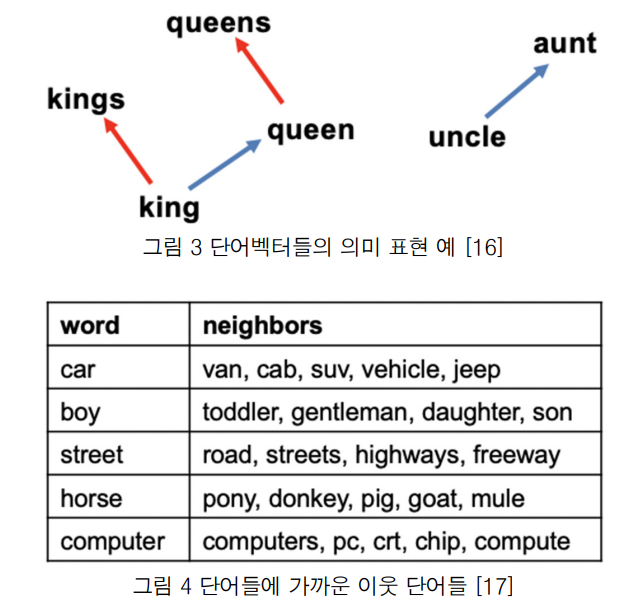
위의 그림처럼 공간에서 단어의 의미를 포함하게되고, 비슷한 의미의 단어들은 백터 공간에서 가까운 곳에 위치하게 된다.
5. NMT 구축 절차
NMT뿐 아니라 자연어처리 문제 전반에 적용 가능하다
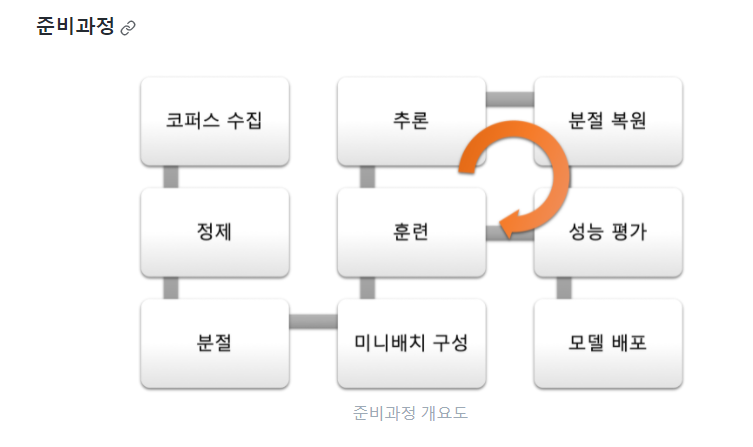
① 코퍼스 수집
병렬 코퍼스(parallel corpus)를 다양한 소스에서 수집한다. WMT(기계번역 경진대회)에서 공개한 번역 시스템 평가용 데이터셋은 물론, 뉴스 기사나 드라마/영화자막, 위키피디아 등을 수집하여 번역시스템에 사용
② 정제
수집된 데이터는 정제 과정을 거쳐야 합니다. 정제 과정에는 양 언어의 말뭉치에 대해 문장 단위로 정렬해주는 작업부터, 특수 문자 등의 노이즈를 제거해주는 작업도 포함됩니다.
③ 분절
각 언어별 형태소 분석기(POS tagger) 또는 분절기(tokenizer, segmenter)를 사용해 띄어쓰기를 정제한다.
한국어의 경우-Mecab, KoNLPy
띄어쓰기가 정제된 이후에는 - Subword 또는 WordPiece와 같은 공개되어 있는 툴을 사용하여 Byte Pair Encoding(BPE)를 수행한다.
④ 미니배치구성
미니배치 내에서 문장길이를 통일한다.
⑤ 훈련
준비된 데이터셋을 사용해 seq2seq 모델을 훈련한다.
⑥ 추론
성능 평가(evaluation)를 위한 추론을 수행한다. 테스트셋의 난이도가 적당해야 한다.
⑦ 분절복원
분절을 복원하는 작업(detokenization)을 수행하면 실제 사용되는 문장의 형태로 반환한다.
⑧ 성능 평가
이렇게 얻어진 문장에 대해 정량 평가를 수행한다. 기계번역용 정량 평가 방법으로 BLEU가 있다.
< 서비스 >
① API 호출 or 사용자로부터의 입력API 호출 or 사용자로부터의 입력
② 분절
③ 추론
④ 분절 복원
⑤ API 결과 반환하기 또는 사용자에게 결과 반환하기
-참고(사진 출처)-
- AI Open volume1, 2020, Pages 5-21
- 신경망 기반 기계번역 모델의 이해(최희열(한동대학교))
- 딥러닝을 이용한 자연어처리 입문 (역전파,워드임베딩)
- 김기현의 자연어 처리 딥러닝 캠프 (NMT구축절차)
