길이가 각각 다른 Sequence data를 하나의 batch로 묶는 2가지 방법으로 padding 방법과 packing방법이 있다.
먼저 Sequence data에는 자연어 처리NLP에서 많이 쓰이는 text data와 audio data가 있다.
text data의 경우 해당 문장에 몇개의 단어와 문자가 포함되어 있을지는 정해져 있지 않다.
audio data의 경우 시간과 sampling data에 따라 audio data의 길이가 달라지게 된다.
이와 같이, Sequence data는 길이가 미정인 data들이 많다.
반대로 Sequence data가 아닌 image data의 경우는 고정된 크기를 갖는다.
Sequence data
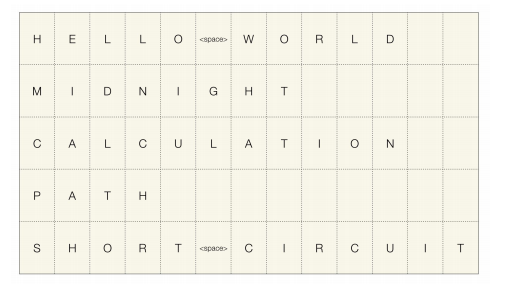
위의 사진에서 charactor단위로 구성된 5개의 text sequence data를 볼 수 있다. 이런 사이즈가 다른 5개의 Sequence data를 하나의 batch로 만들기 위해 사용되는 2가지 방법이 padding 방법과 packing방법이다.
padding 방법
padding 방법은 가장 긴 Sequence에 맞춰 나머지 data뒷부분을 pad라는 token을 써서 채워넣는 방식이다.

보통 이런 data를 처리할때 가장 많이 사용되는 방법이 padding 방법이다.
이 방법은 데이터가 깔끔하게 'batch size x 가장 긴 Sequence 길이'가 되어 하나의 tensor로 표현되기 때문에 컴퓨터에서 처리가 간편해 진다는 장점이 있다.
하지만 불필요하게 뒷부분을 padding으로 채워넣기 때문에 계산하지 않아도 될 뒷부분을 계산해야 한다는 단점이 있다.
packing 방법
packing 방법은 pad token을 쓰지 않고 Sequence길이에 대한 정보를 저장하고 있는 방식으로 진행된다. 하지만 이 방법이 PyTorch에서 제대로 동작하기 위해서는 이 batch data는 길이 내림차순으로 정렬되어야 한다.
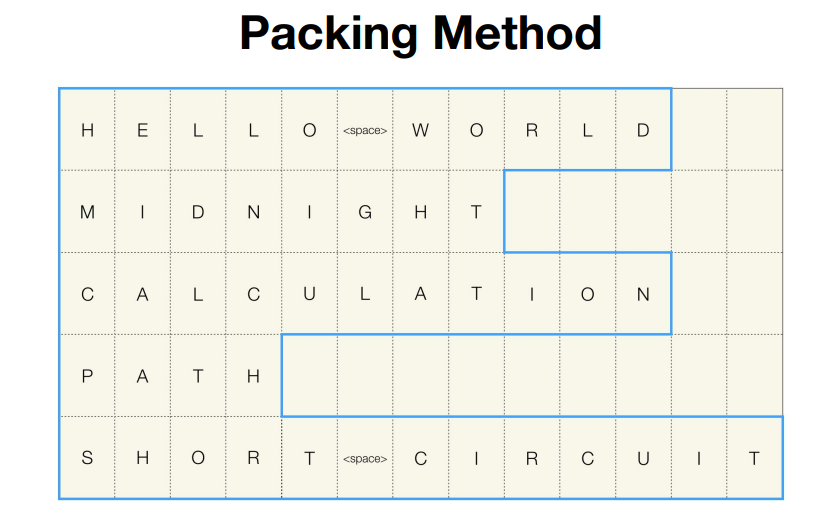

위의 그림처럼 길이 내림차순으로 정렬되어야 PyTorch에서 동작할 수 있다.
Sequence에 대한 정보와 실제 데이터를 함께 가지고 있는 자료구조를 PyTorch에서는 Pack Sequence라고 한다.
이 방법으로는 padding 방법보다 더 효율적으로 계산할 수 있고, padding 방법을 쓰지 않아도 된다는 장점이 있다.
하지만 내림차순으로 정렬해야하는 과정이 필요하고, 구현이 padding 방법보다 복잡해진다는 단점이 있다.
PyTorch에서는 어떤 함수를 써서 활용되는지 알아보자
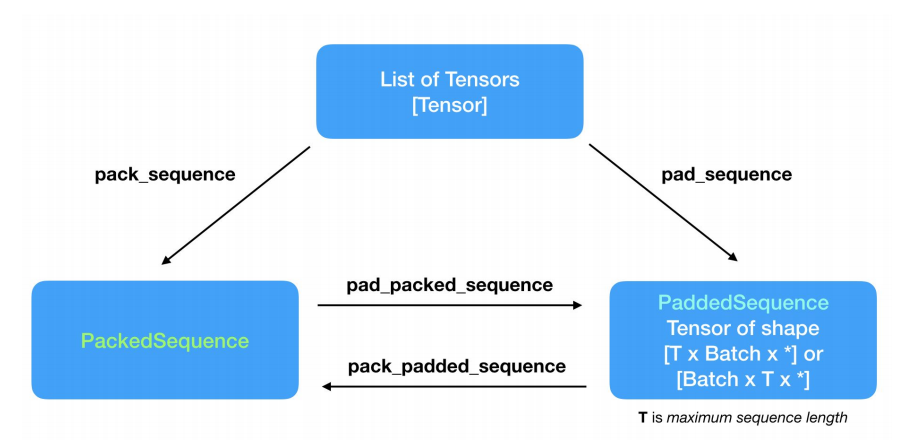
위의 그림은 padding 과 packing에 대한 4가지 함수들의 관계도 이다.
