0. Intro
raw data를 전처리하고 embedding해서 input data를 만든 뒤, ETRI BERT model을 학습을 시도해본 경험을 정리한 포스트입니다. 내용의 정확도 측면보다는 학부생의 공부 경험 정도로 생각하시면 읽기 수월하실 것 같습니다. 전체 코드는 shoveling42에 있으며, 전반적으로 KorBertSum 블로그를 참고했습니다.
(1) 추출요약(extractive summary)이란?
그냥 요약이라 하면 되지, 왜 하필 '추출요약'이지?
KorBertSum에도 추출요약에 대해 기술돼있지만, 해당 논문에서의 정의가 추출요약을 이해하는데 도움될 것 같아 첨부합니다.
(중략) the extractive text summarization is the process in which 1) the sentences are extracted from the whole text which 2) could depict the similar meaning as the whole text but in a more condensed form.
이 논문에 의하면 추출 요약은 1) 글 전체에서 문장을 추출하고 2) 글의 전체 의미와는 비슷하되, 응축된 표현을 뽑아내는 과정입니다. 쉽게 말해, 글에서 중요한 의미를 담은 문장을 그대로 추출합니다. KorBertSum 블로그 말한 핵심 문장 Top n개를 그대로 뽑아보는 상황을 생각해보면 이해에 도움될 듯 싶습니다. '그대로'를 강조했는데, 생성요약(abstractive summary)에서는 문장에 없는 표현(ex. 유의어)도 사용해서 요약합니다. 자세한 내용은 논문의 II. TEXT SUMMARIZATION TYPES 를 참고하시길 바랍니다.
(2) 데이터의 수집
아니, 학습시킬 데이터셋이 없다고?
KorBertSum에서 언급된 Dacon 경진대회 데이터셋을 이용하면 될 것 같았으나, 대회가 마감돼 데이터셋을 다운받을 수 없었다. 대신, 친구가 건네준 ai-hub의 문서요약 텍스트 데이터를 활용하였다. 다만, 데이터셋이 바뀌었기 때문에 임베딩을 포함한 전처리 함수를 새로 구현해야했다.
1. 전처리(Preprocess)
(1) POS Tagging
이 부분은 KorBertSum 블로그와 BertSum 논문 2.2 Fine-tuning with Summarization Layers 이전 부분까지 참고했던 것 같다.
모델을 학습시킬 preprocess와 embedding이 된 파일을 만들기 위해 다음의 코드를 실행하였다. pt 파일은 pytorch 파일을 저장하는 확장자명이다.
model = torch.load('./bert_data/bert.pt_data/korean.train.0.bert.pt')
print(model[0])결과물 구조는 다음과 같았다.
{
'src': [token embeddings],
'labels': [문장단위 라벨값],
'clss': [positional embeddings],
'src_txt': [전체 sentences의 pos tagging],
'tgt_txt': [extractive sentences의 pos tagging]
}
이후, 이 형식에 맞춰 json file을 만들고자 했다. 그 전에 몇 가지 사항을 반드시 짚고 넘어가자.
- 데이터셋을 셔플(shuffle)하지 않았고 train, valid, test으로 구분(split)하지 않았다.
한 번 실행하는데 너무 오래 걸려 데이터셋의 batch size를 줄일 필요가 있었다. 결국, 모델 학습 과정을 전반적으로 이해하는 게 최우선이었기 때문에 셔플을 고려하지 않고 넘어갔다. 학습의 편향성을 고려해 데이터 셔플을 하고 train, valid, test로 구분하는 게 맞다.
- Pos tagging할 때 형태소 분석기는 Kiwi가 아닌 ETRI 형태소 분석 API를 사용하였다.
성능이 좋다고 판단한 Kiwi tokenizer를 쓰고자 했으나, 형태소 태그셋이 다른 점이 모델의 성능에 영향을 미칠 수 있다고 판단해 ETRI 형태소 분석 API를 사용하기로 결정했다. (현재 코드 재검토하면서 원인 모를 이유로 ETRI 형태소 분석 API가 되지 않아, Kiwi tokenizer로 재배포하였습니다.)
Kiwi 형태소 태그셋: https://github.com/bab2min/Kiwi
ETRI API 형태소 태그셋: link
json file을 생성하는 파일은 article2json.py이며, json_data 폴더에 넣어주면 된다.
(2) Embedding
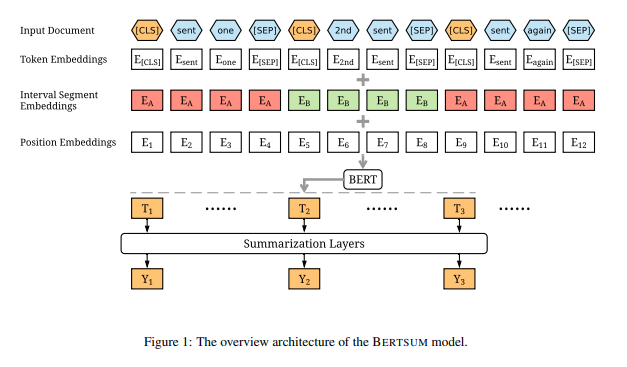
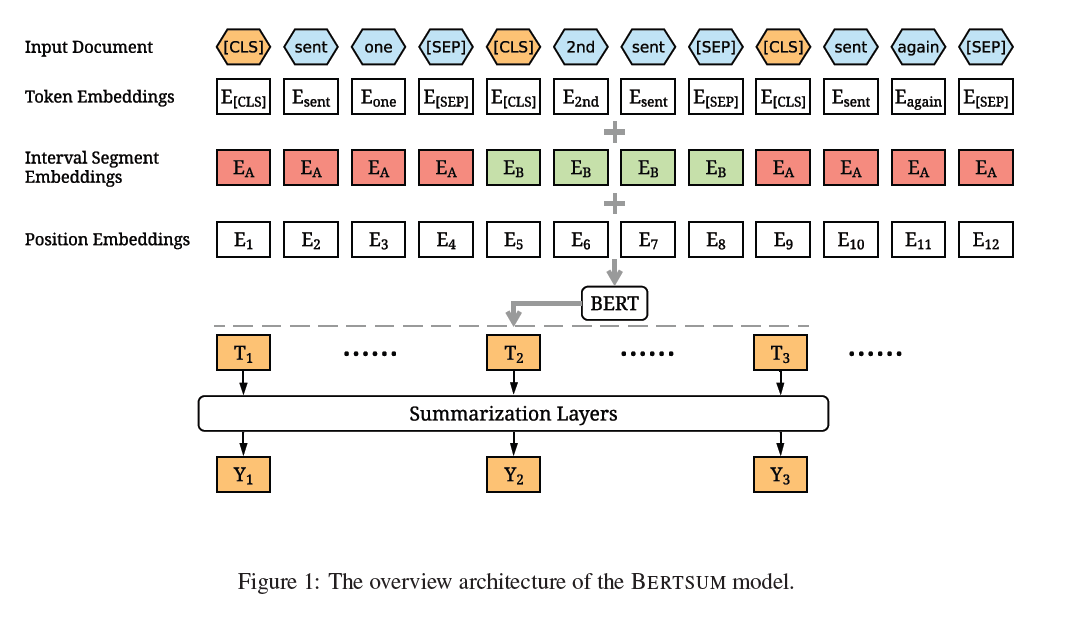
json file의 데이터를 BERT 모델이 학습할 수 있게끔 Embedding 해줘야하는데, 이는 전적으로 KorBertSum 블로그를 따랐고, 각 파일은 shoveling42에서 확인할 수 있다.
inputpreprocess.py: 문장의 시작과 끝을 의미하는 [CLS], [SEP] 토큰 추가
label.py: 요약문이 포함됐는지 여부에 따라 0과 1로 변환
tokenembed.py: '토큰/형태소 태그셋' 형태를 BERT Index로 변환
segmentembed.py: 홀수/짝수 문장에 따라 0과 1로 변환
positionembed.py: [CLS] 토큰의 포지션값(위치 정보)
2. Pre-train
bert_data에 embedding된 파일을 넣어줬다면, 다음의 코드를 실행시켜 학습이 가능하다.
python train.py -mode train -encoder classifier -dropout 0.1 -bert_data_path /content/bert_data/korean -model_path ../models/bert_classifier -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 1000 -decay_method noam -train_steps 1000 -accum_count 1 -log_file ../logs/bert_classifier -use_interval true -warmup_steps 8000 -bert_model 'ETRI BERT model Path' -bert_config_path 'ETRI BERT Config Path' -temp_dir .3. Takeaways
- 데이터셋이 바뀌어서 전처리부터 임베딩을 새로 해야했다. 이 시간이 예상했던 것보다 오래 걸려서 정작 모델 학습에 필요한 hyper-parameter는 제대로 이해하지 못했다.
- 결과가 어떻든 학습에 성공하자는 마인드로 pre-train을 진행해서, BERT model architecture를 간단하게나마 구현하지 못했고, 데이터 셔플 등 성능을 높이기 위한 요소를 고려하지 못했다.
- POS Tagging 과정에서 token embedding을 도저히 구현하지 못해, 해당 블로그를 작성하신 분께 메일을 드렸는데 답장을 해주셨다. 그 내용이 아주 큰 도움이 되었다.
- 모듈화를 신경쓰지 못하고 코드를 작성했다.
- tokenizer 선별 시, 비교적 최근에 배포된 기술을 사용할 때 성능뿐만 아니라 호환성의 문제도 중요하다.
- extractive summary는 이해했지만, abstractive summary를 구현하지 못했다. (GPU가 필요함을 절실히 느꼈다)
- BertSum model architecture를 보고 KorBertSum에서 어떻게 preprocess된 파일 자료구조를 만들 발상을 했는지 궁금함
- 파일 경로를 썼다면, 파일 디렉토리에 대한 설명이 추가되어야한다.
- github에서 다른 사람의 코드를 사용할 때는 license를 확인해보자
references
Fine-tune BERT for Extractive Summarization, https://arxiv.org/abs/1903.10318
R. Boorugu and G. Ramesh, "A Survey on NLP based Text Summarization for Summarizing Product Reviews," 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), 2020, pp. 352-356, doi: 10.1109/ICIRCA48905.2020.9183355.
Velog, "BERT를 활용한 한국어 문서 추출요약 봇", https://velog.io/@raqoon886/KorBertSum-SummaryBot, (2021.04.10)

프로젝트 하는데 도움 많이 되었습니다! 다만 article2json.py 파일 45번째줄에 탭 하나가 더 들어가서 첫번째 기사가 중복해서 들어가는 문제가 있네요.