Human language and word meaning
전통 NLP에서는 단어를 이산 기호(discrete symbol)로 표현했는데, 이를 localist representation이라고 한다. 표현하고자 하는 단어의 인덱스 값만 1이고, 나머지는 모두 0으로 표현하는 원-핫 벡터(one-hot vector)의 양식을 취한다.
단어를 discrete symbol로 표현하는 데는 두 가지 문제가 있다.
- 벡터의 차원이 매우 커져 공간적 낭비를 불러일으킨다. 한 벡터의 차원은 모든 단어들의 개수이어야 하기 때문이다.
- 원-핫 벡터들은 상호 간 직교(orthogonal)하기 때문에 의미의 유사성을 표현하지 못한다.
따라서 의미의 유사성을 단어 벡터에 인코딩하는 방식이 등장하게 됐다. 분포 의미론(distributional semantics) 이라는 방법론에서는 이웃하는 단어들로부터 단어의 의미를 유추할 수 있다고 제안한다. 한 단어의 벡터를 만들어내기 위해 문맥(context)을 사용하는데, 이때 문맥은 고정된 범위(window) 내에 등장하는 주변 단어들의 집합으로 정의한다.
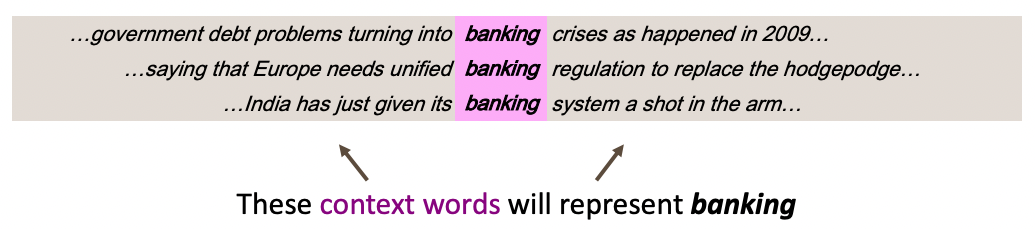
단어는 고정된 차원을 가진 밀집 벡터(dense vector)로 표현되며, 다차원의 공간에서 단어 벡터들은 유사한 문맥에서 나타나는 단어 벡터들과 가까이 위치하도록 설정된다. 그리고 단어 벡터의 내적(dot product)으로 단어의 유사성을 측정한다.
분산 표현(distributed representation): 단어 벡터(word vector) = 단어 임베딩(word embedding) = 단어 표현((neural) word representation)

Word2Vec introduction
단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터로 수치화하는 방법이 필요한데, 단어 벡터를 훈련하는 대표적인 프레임워크가 워드투벡터(Word2Vec)이다.
- 텍스트 코퍼스(corpus)에 있는 모든 단어들에 대해 단어 집합을 만든다.
- 각 단어는 벡터로 표현된다.
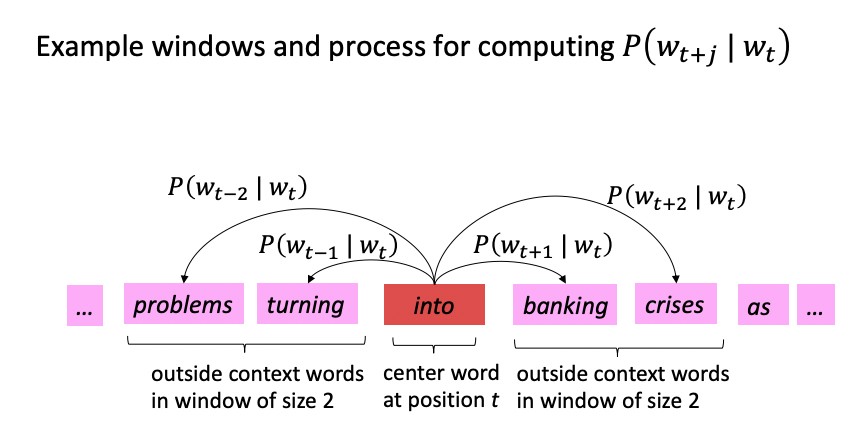
- 텍스트의 번째 위치에는 중심 단어 와 문맥 단어 가 있다.
- 와 단어 벡터 간 유사도로 를 계산하고, 이 확률을 최대화하기 위해 단어 벡터 값들을 조정한다. 중심 단어로부터 주변 단어들을 예측하는 이 방식을 Skip-gram이라고 부른다.

SNU AI