Skip-gram with negative sampling
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2 (NIPS'13). Curran Associates Inc., Red Hook, NY, USA, 3111–3119.
기존 Word2Vec 모델에서는 중심 단어가 주어졌을 때 주변 단어가 나타날 확률의 분모에서 모든 단어 벡터를 반영하여 정규화를 시도한다. 그렇지만 중심 단어와 연관성이 떨어지는 단어 벡터까지 모두 취합하여 계산하는 것은 컴퓨팅 부담이 크며 비효율적이다.
네거티브 샘플링(Negative sampling)에서는 "참인" 단어쌍(중심 단어와 문맥 단어) 그리고 여러 "노이즈" 단어쌍(중심 단어와 코퍼스에서 랜덤 추출한 단어)를 만들어 이진 로지스틱 분류 문제를 푼다. 참인 단어쌍(positive)에 대해서는 확률을 최대화하고, 노이즈 단어쌍(negative)에 대해서는 확률을 최소화하는 학습 목표를 두는 것이다. 이는 다음 두 가지 측면에서 연산의 효율성을 개선할 수 있다.
- 하나의 중심 단어에 대해 전체 단어 집합보다 훨씬 작은 단어 집합을 만든다.
- 전체 단어 집합만큼을 선택지로 두고 다중 클래스 분류 문제를 풀던 것과는 다르게 positive와 negative 두 가지 클래스만 분류하면 된다.
손실 함수는 다음과 같다.
개의 노이즈 단어를 의 확률 분포로부터 추출하면, 중심 단어가 주어질 때 실제 문맥 단어가 나타날 확률을 최대화하고 랜덤 단어가 나타날 확률을 최소화하도록 함수를 구성한다. 이때 는 unigram distribution이며, 지수배 하는 것은 빈도가 적은 단어들이 더 자주 추출되도록 모델링한다.
여기에 확률적 경사 하강법(SGD)를 적용하여 손실 함수의 최솟값을 구하면 된다.
Capture the essence of word meaning more effectively by counting
그런데 단어 벡터 값 업데이트를 위해 매번 코퍼스를 iterate하는 것은 비효율적으로 보인다. 미리 코퍼스의 전체적인 통계 정보를 만들어놓는 방법도 있는데, 단어의 공기 관계를 나타내는 행렬, 즉 공기 행렬(co-occurence matrix)을 만드는 것이다. 공기 행렬은 두 가지 방법으로 구성할 수 있다.
- 단어-단어 행렬(term-term matrix): Word2Vec처럼 중심 단어가
window_size내에 있는 단어들과 공기하는 횟수를 세는 방법이다. 통사론적, 의미론적 정보를 반영할 수 있다는 특징이 있다. - 단어-문서 행렬(term-document matrix): 각 문서에 각 단어가 나타난 횟수를 센다. 주제어 분석과 같은 잠재 의미 분석(Latent Semantic Analysis, LSA)를 수행하는 데 사용한다.
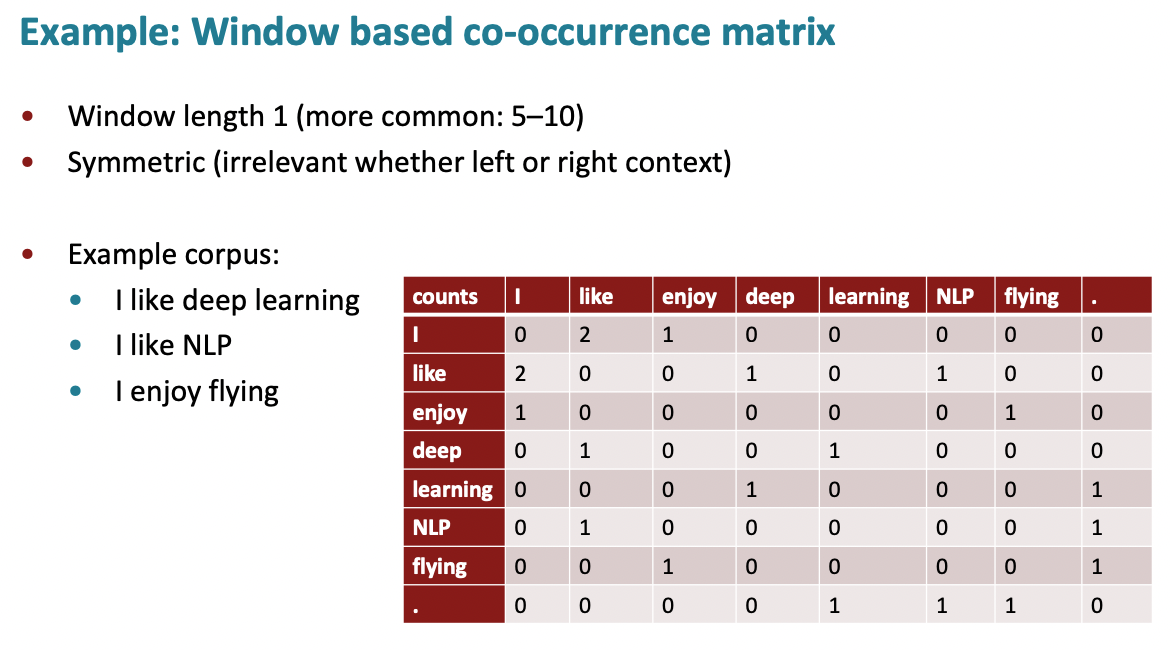
그렇지만 공기 행렬은 차원이 커서 메모리 부담이 크고, 이를 그대로 벡터로 수치화하면 희소 표현(sparse representation)이 주를 이뤄 모델의 강건성이 떨어진다는 문제가 있다. 그래서 Word2Vec처럼 밀집 벡터로 차원을 압축시키는 차원 축소(dimensionality reduction) 방법을 사용하여 벡터화한다.
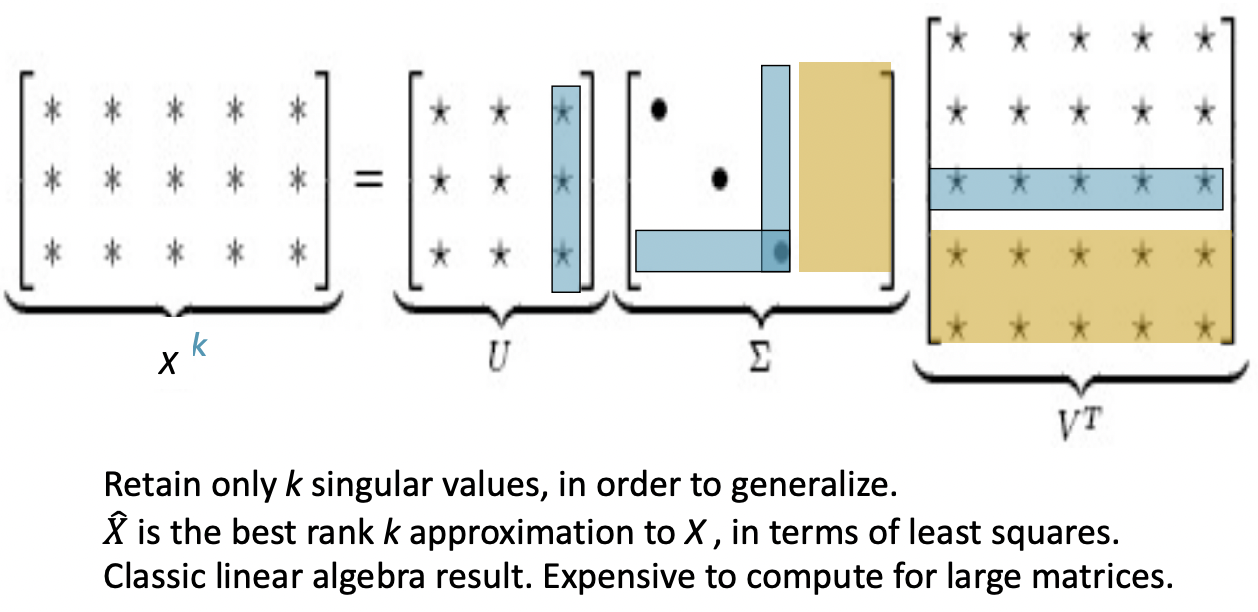
클래식한 차원 축소 방법은 특이값 분해(Singular Value Decomposition, SVD)를 통해 공기 행렬을 3개의 행렬의 곱으로 분해하는 것이다(LSA 모델). 개의 특이값들에 대응되는 값들로부터 잠재 의미를 파악할 수 있다.
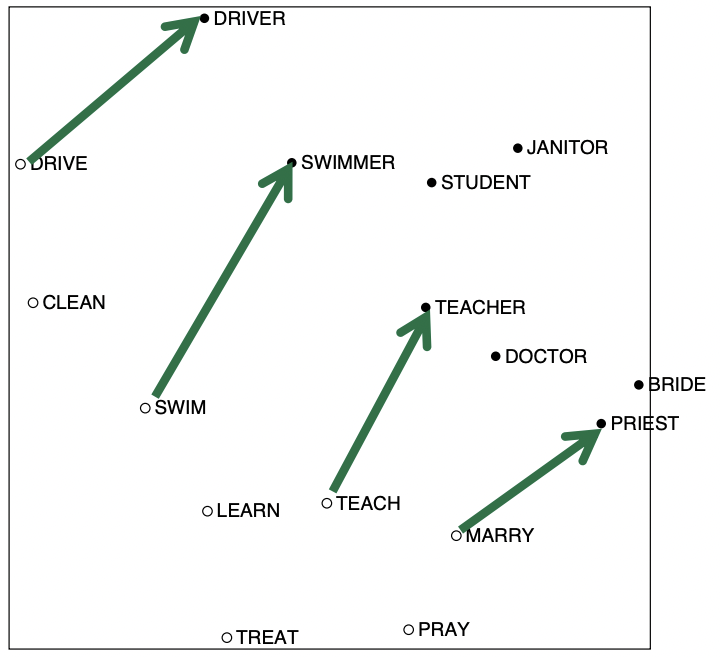
공기 행렬 내 빈도값들을 스케일링(scaling)하고, 윈도우 크기를 조정하고, 단순 빈도 대신 피어슨 상관계수를 사용하는 등 방법론을 수정하면(COALS 모델) 단어 벡터 공간에서 흥미로운 의미론적 패턴들을 관찰할 수 있다. 유추가 가능한 단어쌍들은 서로 평행하고, 단어쌍 사이 거리도 상당히 비슷하다.
GloVe
단어 임베딩 방법론은 Skip-gram Word2Vec과 같은 예측 기반, LSA와 같은 카운트 기반 방법론으로 계열이 나뉜다. 전자는 각 문서에서 각 단어의 빈도수를 행렬로 만들고 차원을 축소하여 잠재된 의미를 끌어낸다. 후자는 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가면 학습하는 예측 기반의 방법론이다.
카운트 기반 방법론은 훈련이 빠르고, 통계 정보를 효율적으로 사용할 수 있다는 장점이 있지만, 단어 유사도만 계산해낼 뿐 단어 의미의 유추 작업에는 성능이 떨어진다. 또한 빈도가 높은 단어들이 지나치게 크게 주목된다.
예측 기반 방법론은 코퍼스가 커질수록 연산량이 늘어나고, 통계 정보를 활용할 수 없다는 비효율성이 지적되나, 다양한 태스크에 높은 성능을 보일 수 있고, 단어 유사도를 넘은 복잡한 패턴들을 반영할 수 있다는 장점이 있다.
이렇듯 상호보완적 관계에 있는 두 가지 단어 임베딩 방법론들의 장점을 취하여 등장한 것이 글로브(Global Vectors for Word Representation, GloVe)이다. 공기 확률들의 비율을 계산하면 의미 관계를 포착할 수 있는 것이다.
- ice가 solid와 등장할 확률이 steam이 solid와 등장할 확률보다 크다.
- ice가 gas와 등장할 확률이 steam이 gas와 등장할 확률보다 작다.
- ice가 water와 등장할 확률이 steam이 water와 등장할 확률과 비슷하다.
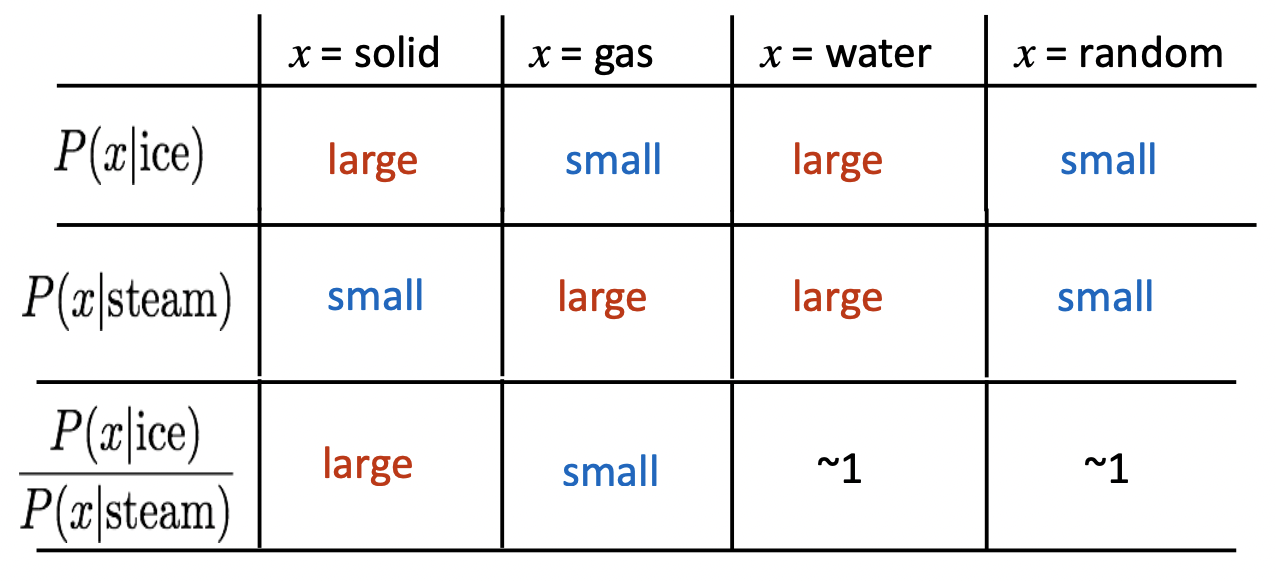
이 아이디어를 한 줄로 요약하면, 임베딩된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 공기 확률이 되도록 만드는 것이다. 손실 함수는 다음과 같으며, 유도 과정은 생략한다. 이는 훈련이 빠르고, 큰 코퍼스에도 스케일러블(scalable)하며, 작은 코퍼스와 작은 벡터들로도 좋은 성능이 나오는 것으로 알려져있다.
Evaluating word vectors
자연어 처리에서 모델 평가 방식은 크게 intrinsic과 extrinsic으로 나뉜다. Intrinsic evaluation은 작은 태스크에 대해 모델을 평가하는 것으로, 연산이 빠르고, 시스템을 이해하는 데 도움을 준다. 그렇지만 실제 상황에서 쓰이는 태스크에 대한 extrinsic 평가 없이는 결과의 유용성이 떨어진다. Extrinsic evaluation은 실제 태스크에 모델을 평가하는 것으로, 평가 시간이 오래 걸리며, 부분 시스템과 부분 시스템들 사이의 상호작용 효과를 구분해야 한다. 제안하는 모델이 어떠한 부분 시스템을 대체했을 때 더 높은 성능이 나오기를 기대하는 것이다.
Intrinsic word vector evaluation
- word vector analogies
- word vector distances and their correlation with human judgments
Extrinsic word vector evaluation
- named entity recognition (NER)
Word senses
유의어들은 어떻게 임베딩해야 할까? 단어 주위의 윈도우들을 클러스터링하고, 각 유의어에 대해 서로 다른 클러스터들의 단어들로 훈련시킨다. (Improving Word Representations via Global Context and Multiple Word Prototypes)

또는, 각 단어 벡터들에 대해 빈도수를 기반으로 가중합하는 방법도 있다. (Linear Algebraic Structure of Word Senses, with Applications to Polysemy)
Classification and how neural nets differ
Neural networks
