
이 글에서는 활성화 함수에 대해 알아볼 것이다.
활성화 함수란?
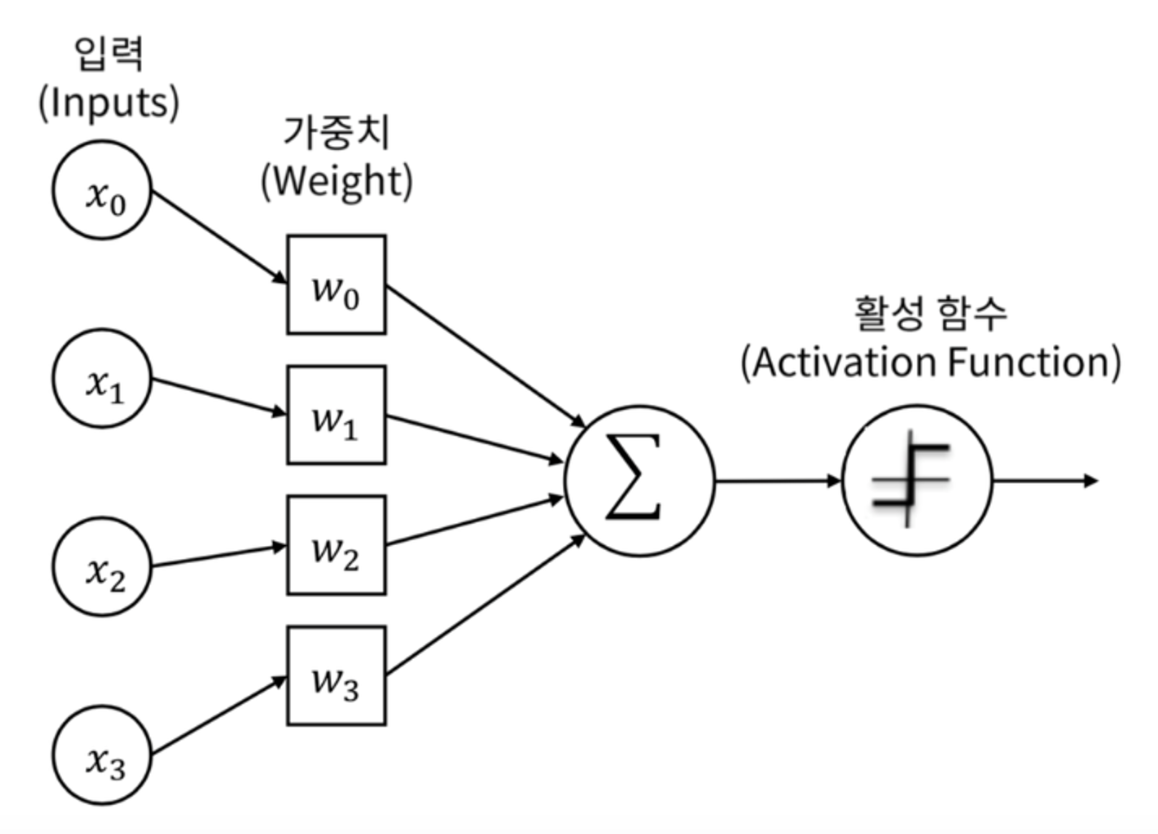
퍼셉트론의 출력값을 결정하는 비선형함수를 활성화 함수라 한다.
즉 활성화 함수는 퍼셉트론에서 입력 값의 총합을 출력할지 말지를 결정하고, 만약 출력하게 된다면 어떤 값을 출력할지 결정하는 함수이다.
위 사진에서 입력의 총합에 대해, 활성화 함수를 거쳐 출력값이 결정되는 것을 볼 수 있다.
이때 활성화 함수로는 비선형 함수를 사용해야한다. 그 이유는 아래와 같이 밑바닥부터 시작하는 딥러닝 1권에서 잘 설명하고 있다.
선형함수인 h(x)=cx를 활성화함수로 사용한 3층 네트워크를 떠올려 보세요.
이를 식으로 나타내면 y(x)=h(h(h(x)))가 됩니다. 이는 실은 y(x)=ax와 똑같은 식입니다.
a=c3이라고만 하면 끝이죠. 즉, 은닉층이 없는 네트워크로 표현할 수 있습니다.
뉴럴네트워크에서 층을 쌓는 혜택을 얻고 싶다면 활성화함수로는 반드시 비선형 함수를 사용해야 합니다.
밑바닥부터 시작하는 딥러닝 中
다양한 활성화 함수의 종류
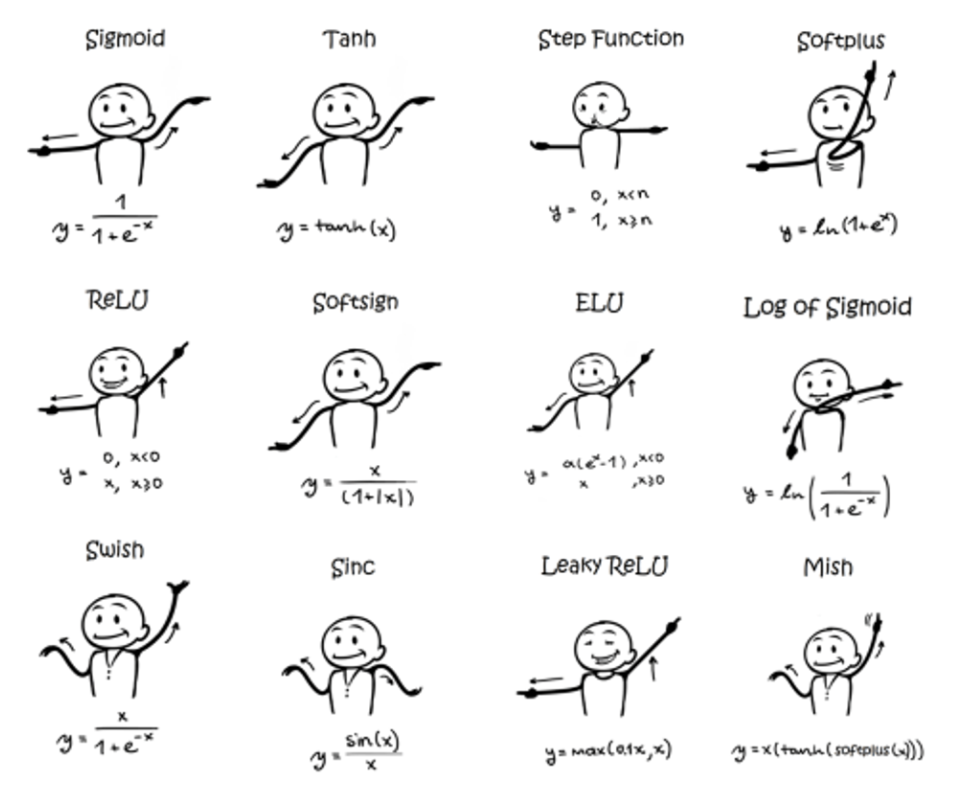
1. 계단 함수 (Step Function)
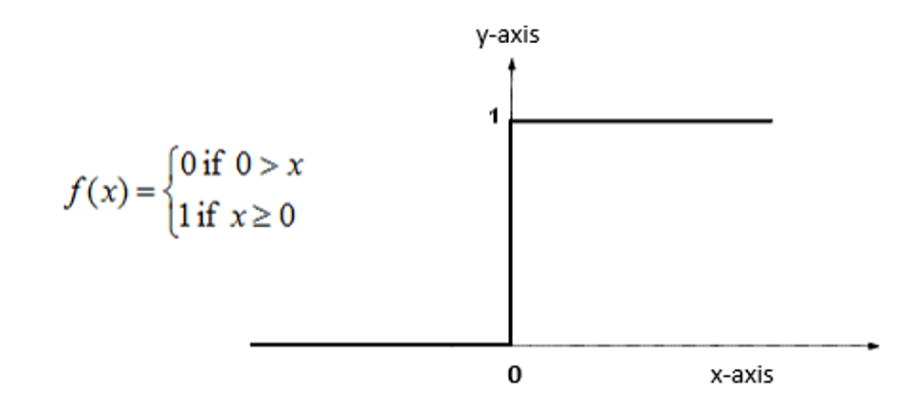
가장 기본적인 활성화 함수로 계단함수가 있다.
0보다 작을때는 0의 값을 갖고, 0 이상일때는 1의 값을 갖는 가장 단순한 구조를 가진다.
초기 인공신경망 모델에서는 계단 함수를 활성화 함수로 사용했지만, 지금은 잘 사용하지 않는다.
그 이유는 아래 서술할 활성화 함수들처럼 gradient(기울기)를 갖는 함수들이 미분이 가능하고, 이를 통해 학습과정해서 더 세밀한 조정이 가능하기 때문이다.
2. 시그모이드(Sigmoid) 함수
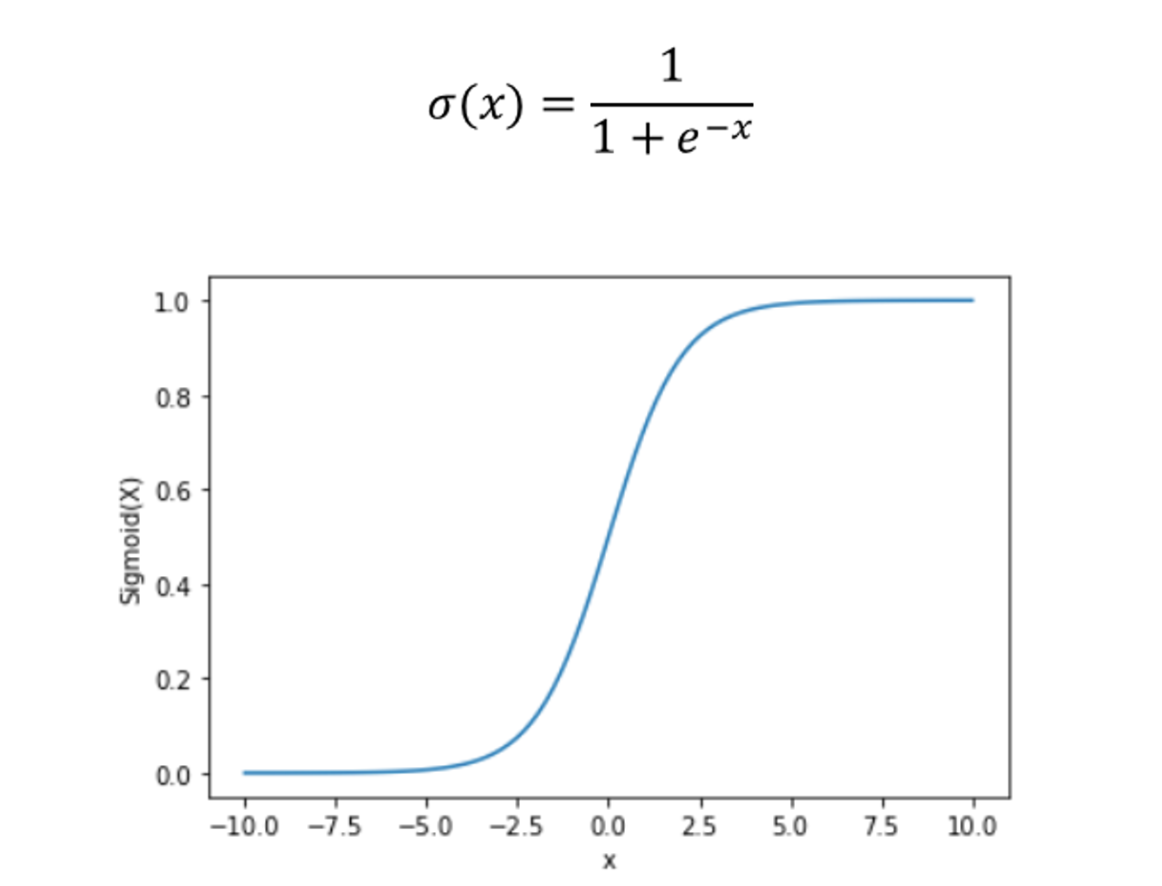
시그모이드 함수는 가장 대표적인 활성화 함수중 하나이다.
일반적으로 활성화 함수를 표현할때 시그모이드의 S자 모양을 써놓는 경우가 많다.
시그 모이드 함수는 x 값에 따라 0~1의 값을 가지며 정의와 그래프는 아래와 같다.
또한 시그모이드 함수의 미분과정과 결과는 다음과 같다.
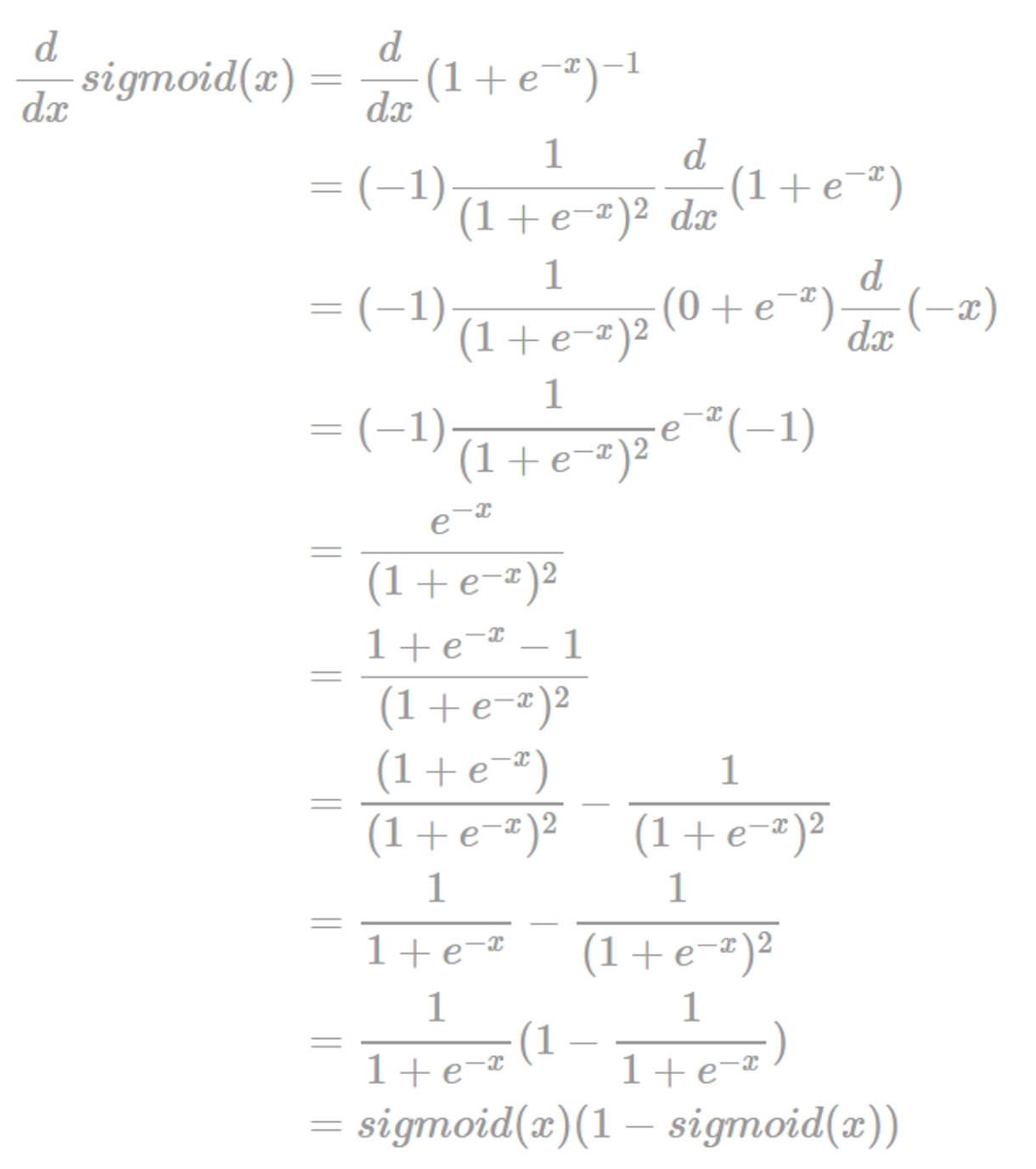
여기서 시그모이드의 도함수를 시각화하면 다음과 같은 모습을 띈다
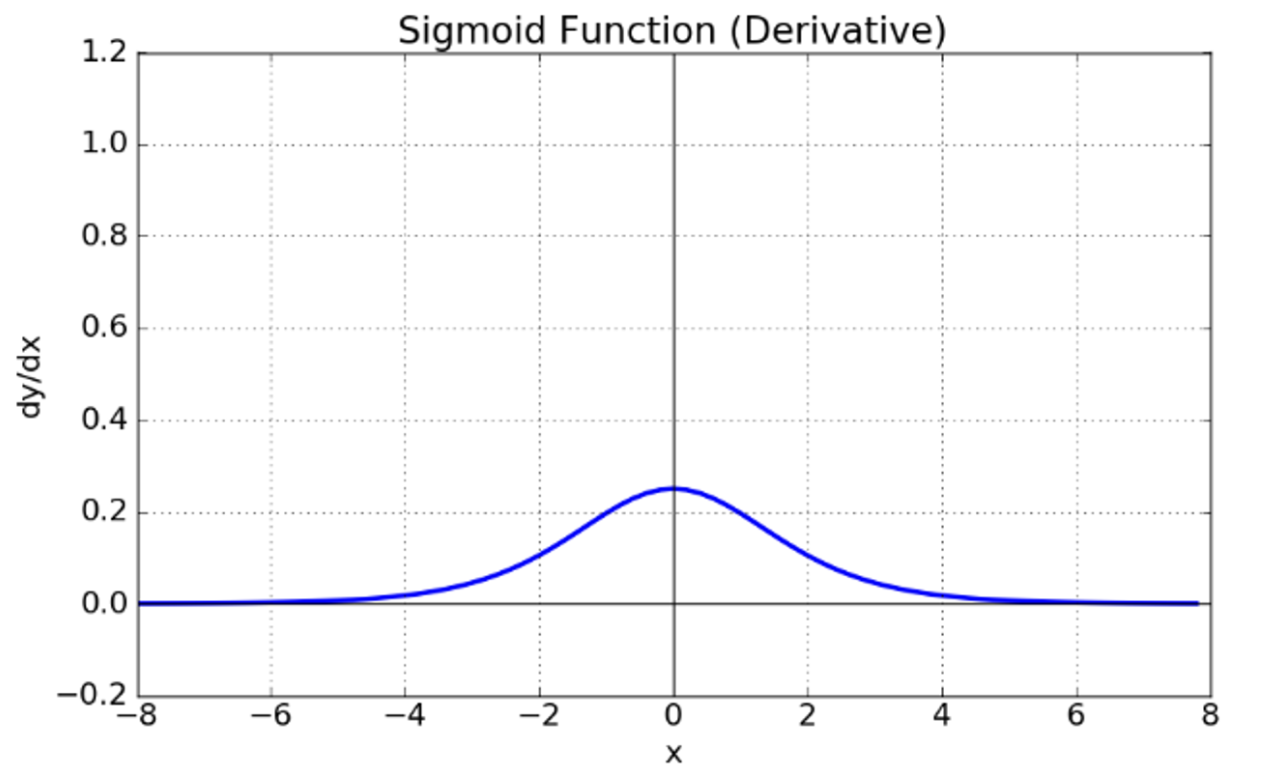
여기서 시그모이드 함수의 도함수 그래프를 보면 절대값 4 이상이 되면 0에 수렴하는 현상을 볼 수 있다. 이는 쉽게 말해 x의 절대값이 커짐에 따라 기울기가 0에 가까워 진다고 볼 수 있다. 이를 기울기가 소실되는 현상 , 즉 기울기 소실(vanishing gradient) 문제가 발생한다.
vanishing gradient가 왜 문제가 될까? 그 이유는 딥러닝 모델에서 학습되는데 오차 역전파법(Back propagation)이 사용되기 때문이다. 오차 역전파법에 대해선 후에 작성하겠지만, 간단히 말해 파라미터를 학습할때 편미분을 사용하기때문에 미분값이 굉장히 중요한데, 이때 기울기가 0에 가까워지게 되면 학습속도가 느려질 수밖에 없는 것이다.
시그모이드 함수의 또다른 문제점으로 not zero-centered(비대칭) 하다는 점이 있다.
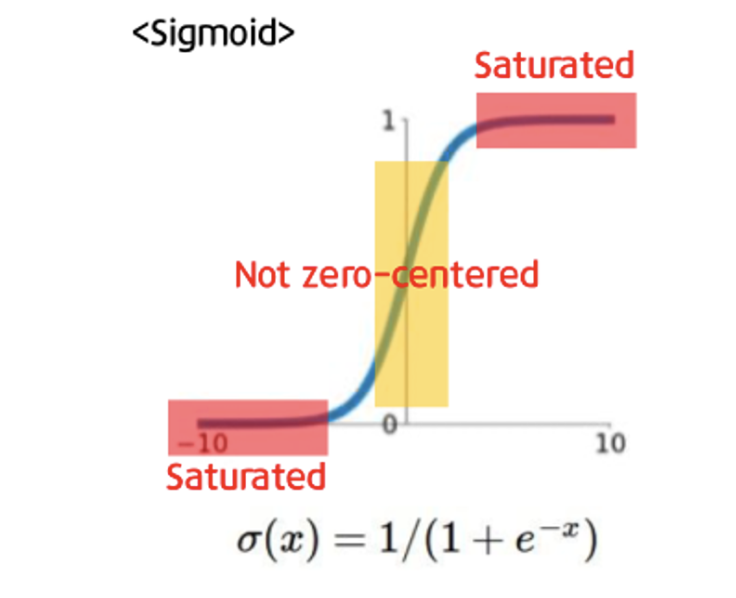
Zero-centered란 그래프의 중심 0인 형태로 함숫값이 양수 혹은 음수에만 치우치지 않고 실수 전체에서 나타나는 형태를 의미한다. Sigmoid는 위의 그래프에서도 볼 수 있듯이 함숫값이 항상 0보다 크거나 같은 형태로 나타난다. Neural networks에서 input은 이전 layer의 결과값이라고 생각하면 된다. 그런데 sigmoid 함수는 항상 양수이기에 sigmoid를 한번 거친 이후론 input 값은 항상 양수가 된다. 그렇게 되면 backpropagation을 할 때 문제가 생긴다. 2차원 평면에서 살펴보면 부호가 모두 같은 지점은 1,3 사분면 뿐이다. 따라서 지그재그의 형태로 학습이 될 수 밖에 없고 이는 학습을 오래 걸리게 한다.
즉 정리하자면 시그모이드 함수는 대표적인 활성화 함수이지만, gradient vanishing 문제와 zero-centered하지 않다는 문제점이 있다.
3. tanh 함수(Hyperbolic Tangent function)
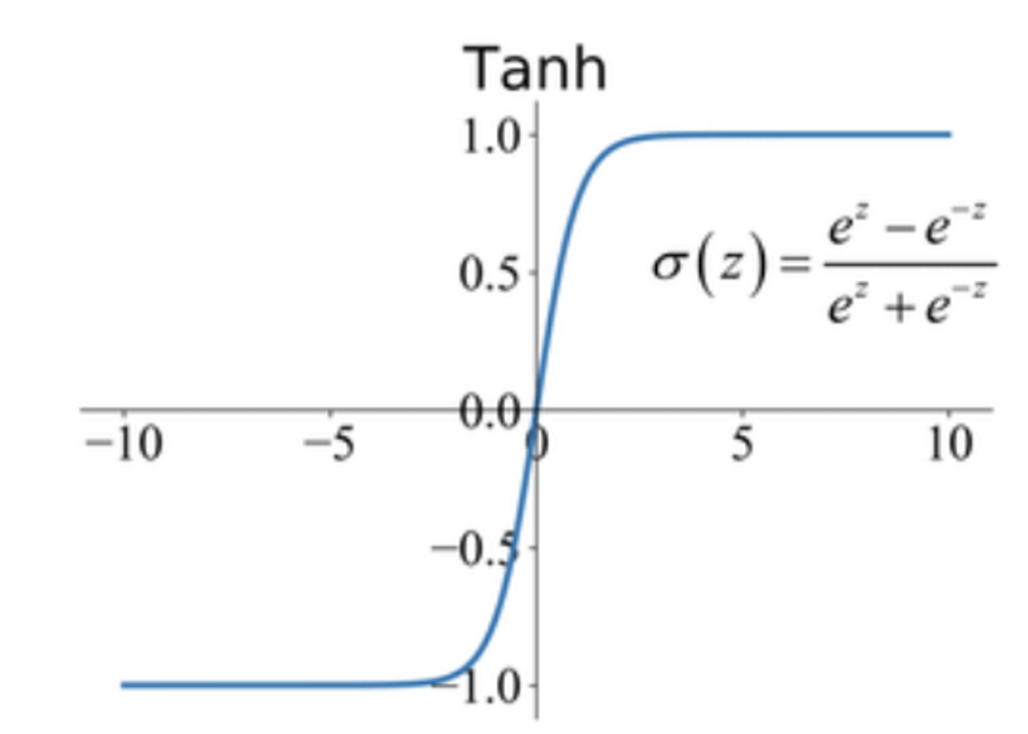
tanh 함수는 시그모이드의 변형인 활성화 함수라 볼 수 있다. 아마 대학 수학에서 한번쯤 봤을 그 하이퍼볼릭 탄젠트 함수가 맞다.
값의 범위가 0~1인 시그모이드 함수와 비교했을때 값의 범위가 -1 ~1 이고, 원점을 지나면서 원점을 기준으로 대칭이다. 이는 시그모이드에 비해 zero-centered 하다는 것을 알 수 있다.
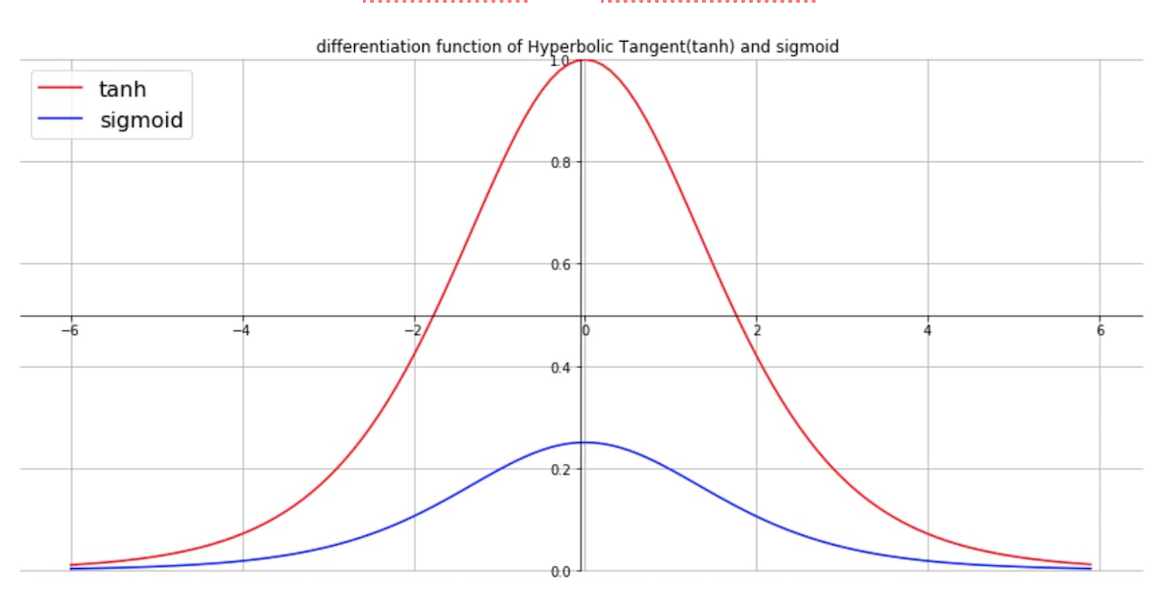
하지만 tanh의 도함수를 보면 시그모이드와 마찬가지로 기울기가 0으로 수렴하는 vanishing gradient 문제는 해결하지 못했다.
즉 정리하자면 시그모이드의 not zero-centered 문제는 해결했지만 vanishing gradient 문제는 해결하지 못했음을 알 수 있다.
일반적으로 시그모이드 함수는 이진분류 문제에서 출력층으로 사용하고, tanh의 경우 은닉층으로 사용하게 된다.
4. 소프트맥스 함수(Softmax Function)
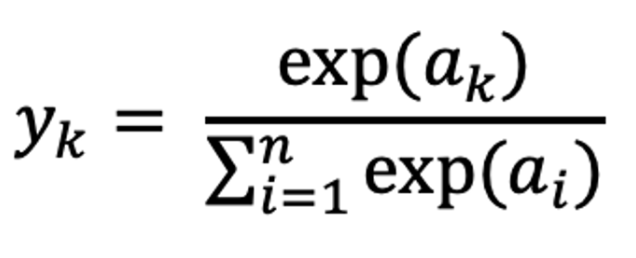
소프트맥스는 대표적인 다중 분류 문제의 출력층으로 사용되는 함수이다. 이때 n개의 class가 있는 분류 문제에서 k번째 class에 속할 확률을 계산하는 식이다.
소프트맥스 함수의 특징
- 소프트벡터의 출력은 확률벡터이며, 모든 성분의 합은 1이다.
- 성분에 지수함수를 취함으로서, 작은값은 상대적으로 더 작게 만들어 정답 클래스와 오답 클래스 간의 차이를 확대한다.
소프트맥스 함수 사용시 주의사항
- 지수함수를 사용하기 때문에 너무 큰 값에 대해 안정성이 떨어질 수 있다. (ex. 오버플로우) 이를 대비해 실제 구현시 로그-소프트 맥스를 사용하거나 값을 빼는 방식을 이용한다.
- 이진 분류문제에서는 소프트 맥스가 아닌 시그모이드를 사용한다.
5. Relu 함수 (Rectified Linear Unit function)
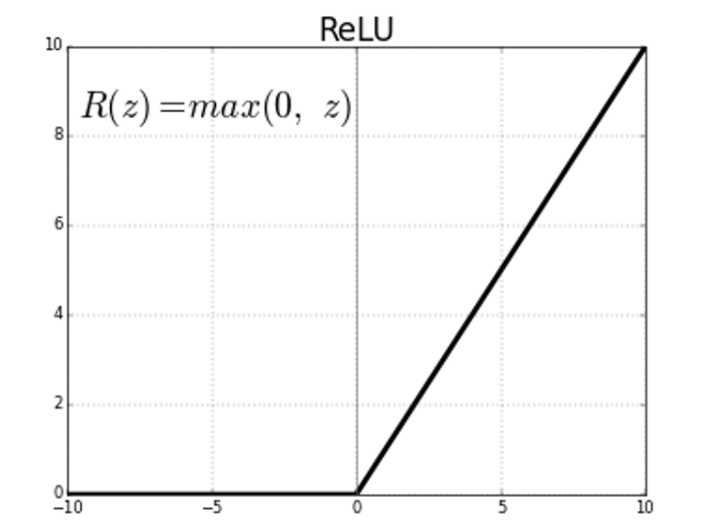
ReLU 함수는 간단하지만 정말 자주 사용되는 함수이다. 거의 대부분의 딥러닝 모델의 은닉층으로 사용된다.
ReLU 함수의 장점
- Sparsity (희소성) : 음수 입력에 대해 0을 출력하기 때문에 활성화되는 뉴런의 수가 적어지고, 계산 효율성이 증가하고 오버피팅을 줄여준다.
- Gradient Vanishing 해결 : 양수인 값에 대해 기울기가 상수 1이므로 기울기가 사라지는 현상을 부분적으로 해결할 수 있다.
하지만 ReLU의 경우 0 미만의 값에 대해 뉴런이 죽는 Dying ReLU 현상이 발생한다. 이를 해결하기위해 다양한 ReLU의 변형이 존재한다.
ReLU의 변형
- Leakly ReLU
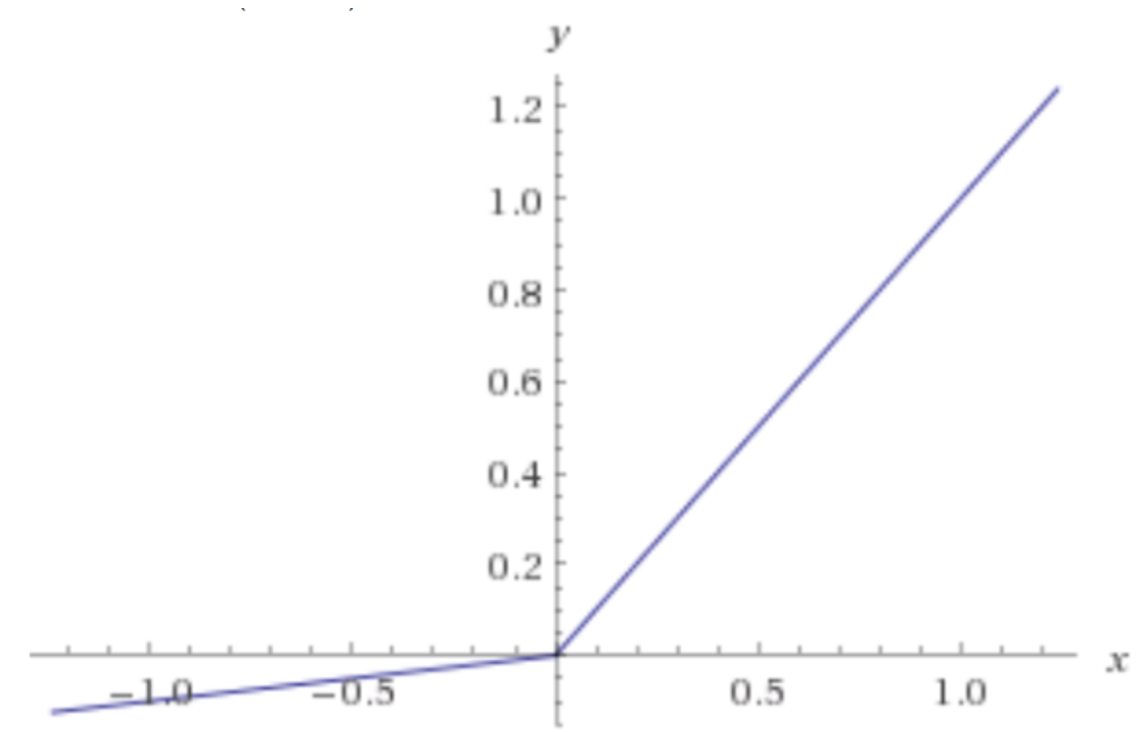
Leaky ReLU는 음수 입력에 대해 0이 아닌 매우 작은 기울기를 부여하여, 네트워크가 '죽은' 뉴런을 다시 '활성화'하는 데 도움을 준다.
- PReLU
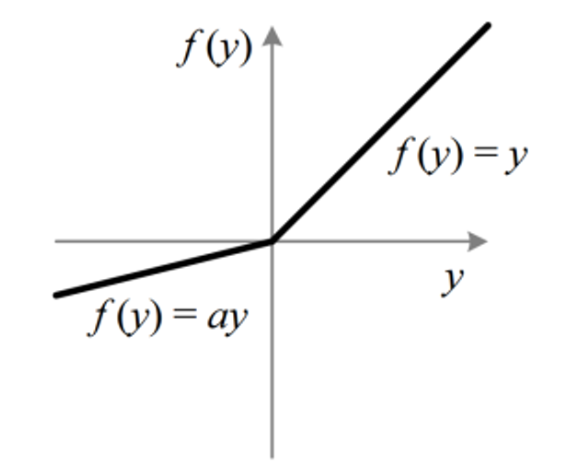
PReLU는 Leaky ReLU와 유사하지만, a가 학습 가능한 파라미터입니다. 이는 데이터에 따라 a가 자동으로 조정될 수 있음을 의미한다.
- Exponential Linear Unit (ELU)
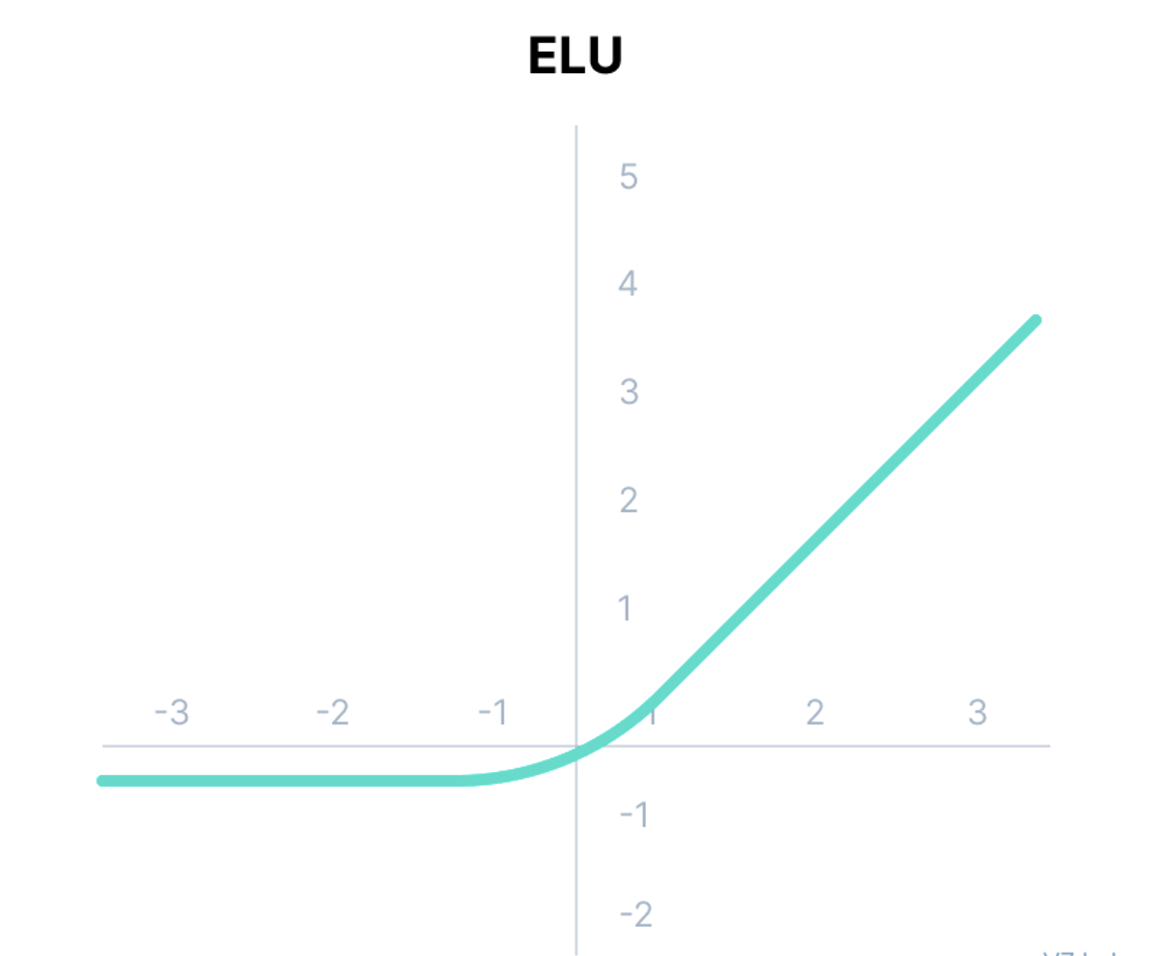
ELU는 음수 입력에 대해서도 포화되지 않는 지수적인 증가를 제공하여, 평균 출력이 더 zero-centered에 가까워지도록 돕는다.
