-
Activation Function을 반드시 이용해야 하는이유는?
: 전체 NN가 몇개의 layer를 가지던지 간에, 하나의 단일 linear function으로 표현 가능해짐. 은닉 계층이 없는 단일 네트워크로 표현되어버리기 때문에 미세한 변화를 만들어주는 것이 중요함. -
Weight가 너무 작은 경우에는 activation이 0이 되어버리고, 너무 큰 경우에는 explosion, super saturation이 일어남.
-
tanh - Xavier Init, ReLU - Xavier에서 분모를 2로 나누어서 사용
Momentum Update
- v(속도)를 업데이트
gradient=force (가속도를 계산함)
mu: 마찰계수
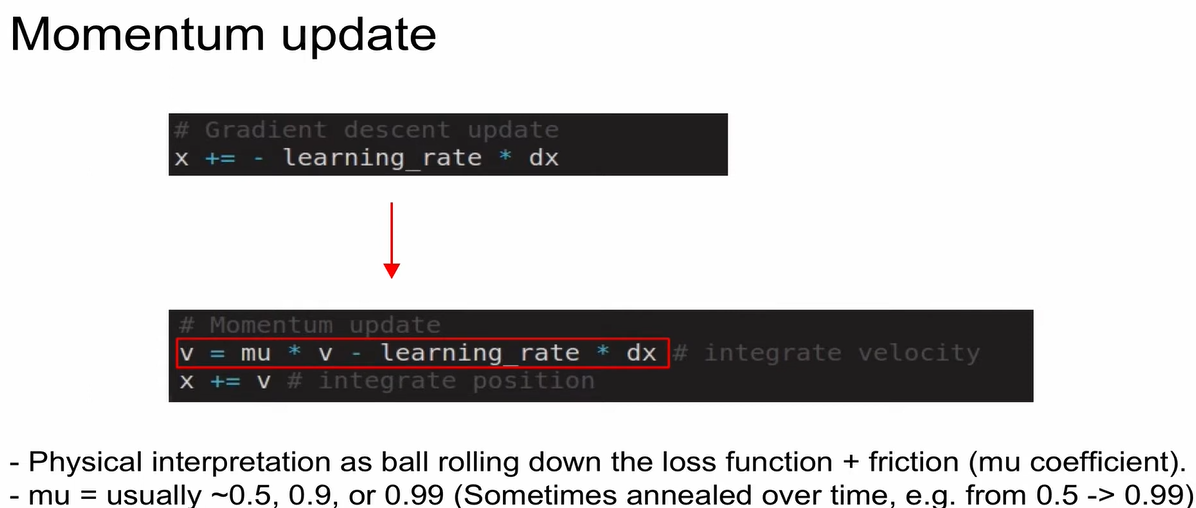

- velocity가 빌드업 됨. overshooting 발생 후 점점 convergence 지점을 찾아감.
Nesterov Momentum update
- Nesterov Accelerated Gradient(NAG)라고도 함.
- 항상 momentum보다 convergence rate가 좋음.
왜? - momentum = momentum step() & gradient step ()
- gradient step을 계산하기 전에 momentum step을 먼저 고려해서 gradient step의 시작점을 momentum step의 종료점으로 설정한 다음, gradient step을 evaluate함.
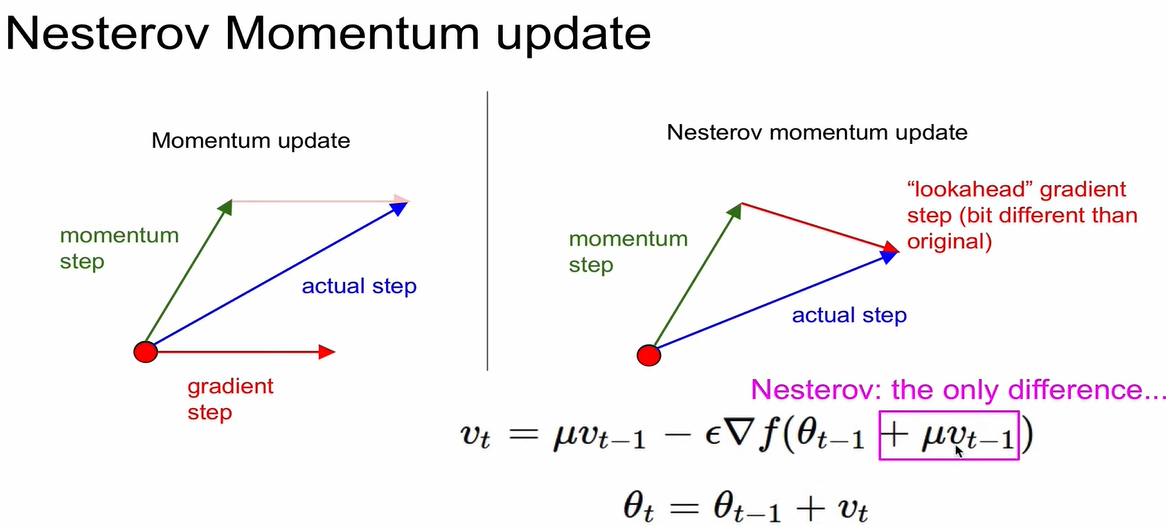


- nag: 방향을 미리 예측하고 가기때문에 더 빨리 convergence 됨.
AdaGrad update
- cache라는 개념을 도입
- cache는 항상 양수, 항상 증가(building up), 우리가 갖고있는 parameter vector와 같은 크기를 가지는 거대한 vector임.
- 모든 parameter들이 동일한 learning rate을 받는 것이 아니라, cache가 빌딩업이 되어가기 때문에 모든 parameter들이 다른 learning rate을 적용받음.
- 1e-7의 역할은 0으로 나누는 것을 방지하기 위한 역할임.

- 수직 방향 gradient는 큼 -> cache의 값이 커짐 -> cache 값으로 learning rate를 나누어주면 x의 업데이트 속도가 낮아짐. (learning rate 작아짐)
- 수평 방향 gradient는 작음 -> cache의 값은 작음 -> cache 값으로 learning rate를 나누어주면 x의 업데이트 속도가 빨라짐.
-> 수직 방향에서는 업데이트 속도를 느리게 하고, 수평 방향에서는 업데이트 속도를 빠르게 함. (Equalization Effect!)

- 문제점: 시간이 지나면서 cache가 너무 커지고 learnin rate가 거의 0에 수렴하게 됨. Neural Net에서는 학습이 종료됨.
- 해결책: RMSProp update
RMSProp update
- Decay Rate 도입 (0.9나 0.99로 설정됨)
- cache의 값이 서서히 줄어들도록 해줌. step size가 0이 되어서 학습이 종료되는 것을 방지함.

Adam Update
-
RMSProp + Momentum
-
RMSProp에서 현재의 gradient인 dx를 사용한 것을, Adam update에서는 m으로 변환해줌. m: 전 단계의 gradient의 decaying하는 sum을 구한 것임.

-
bias correction 과정을 더한 것이 완전한 형태임.
최초의 m과 v가 0으로 초기화 됐을 때 그것들을 scaling up 해주는 것임.
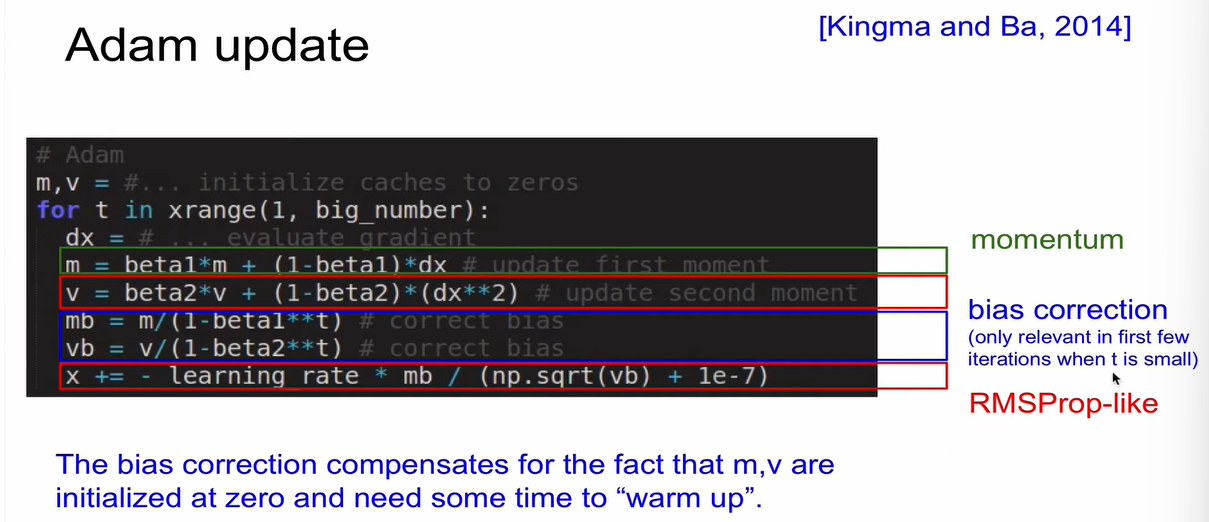
그래서 어떤 방법으로 learning rate을 조정해?
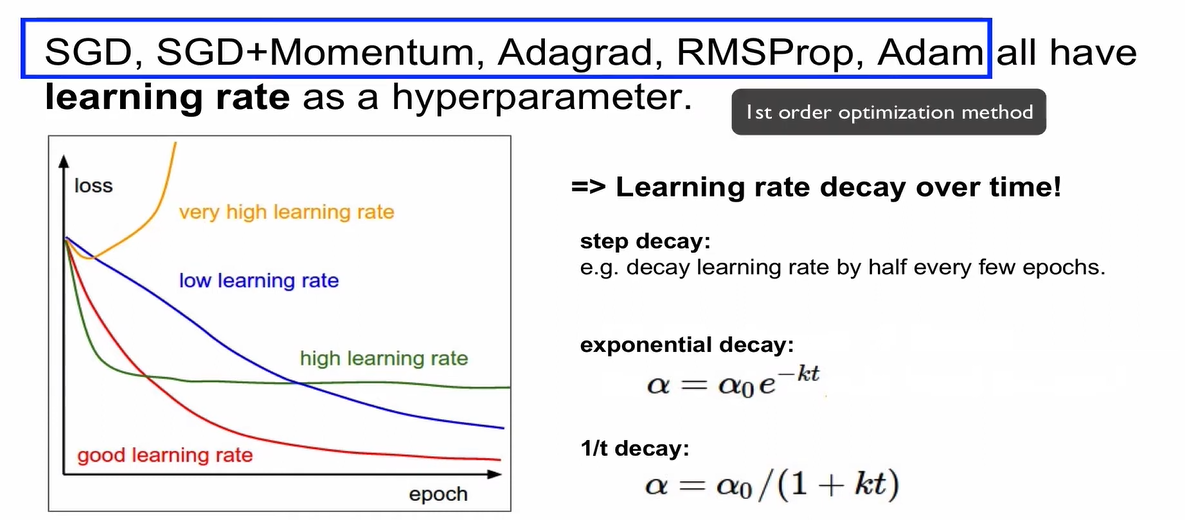
초기에는 learning rate을 크게 잡고, 서서히 작게 만들어주는 것이 최선의 방법임.
-
step decay, exponential decay, 1/t decay가 있는데, 이 중 exponential decay가 가장 잘 쓰임.
-
default choice: Adam
-
1st order optimization method: loss function을 구할 때 gradient 정보만 사용함.
Second order optimization methods
- gradient뿐만 아니라 Hessian을 도입하여 곡면이 어떻게 구성되어있는지를 반영함. -> convergence 지점을 훨씬 빨리 찾아갈 수 있게 됨. learning rate와 같은 hyperparameter가 필요없게 됨.

- 단점: 실행이 불가능한 개념임. 매우 큰 크기의 행렬이며 이에 대한 inverse, 역행렬을 구해야함.
- 그래도 이를 써보자 한 것이
1) BFGS: Hessian을 invert하는 대신에 Hessian with rank 1을 inverse함. (메모리에 저장해야 됨)
2) L-BFGS: 메모리에 저장 안 해도 돼서 가끔 사용됨. 무거운 function이라서 모든 source의 노이즈를 제거하고 사용해야 함. mini batch 환경에서는 사용 안되고, full batch에 댇해서 사용해야 함.
결론: 대부분의 경우 Adam이 잘 작동함. 만약 mini batch update가 아니라 full batch update를 할 수 있다면, L-BFGS를 사용해라. 단, L-BFGS 적용 시 모든 noise를 확실히 제거해야 함.
