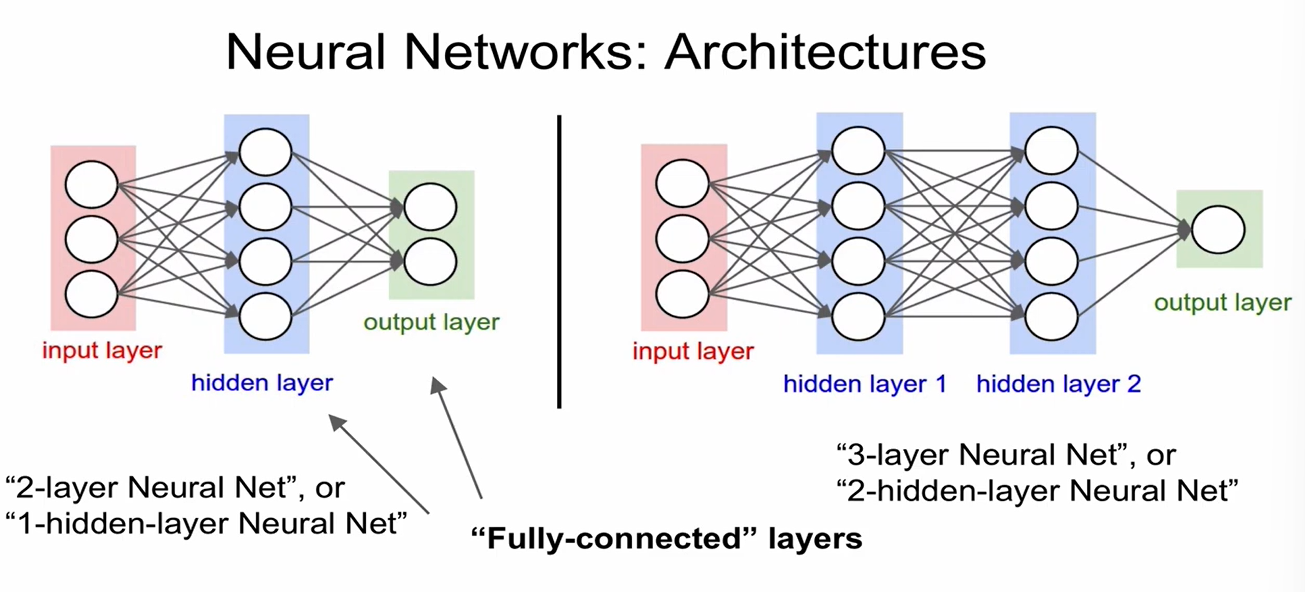
- 2-layer Neural Network
-> max: relu와 같은 activation function임. non-linearity를 부여함.
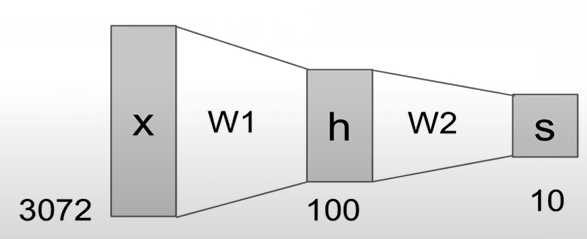
input layer인 x에서는 3072개의 픽셀을 가지게 되고, 이것이 w1이라는 가중치와 연산이 되어서 hidden layer가 100개의 node(feature)로 구성되고, w2 가중치와 연산되어 output layer에서는 10개의 class로 구분이 된다.
- hidden node의 값은 hyperparameter임.
- 기존의 linear score function은 하나의 class에 대해서 하나의 classifier만 존재했지만, Neural network은 하나의 class에 대해서 여러 개의 classifier가 존재함.
Activation Functions
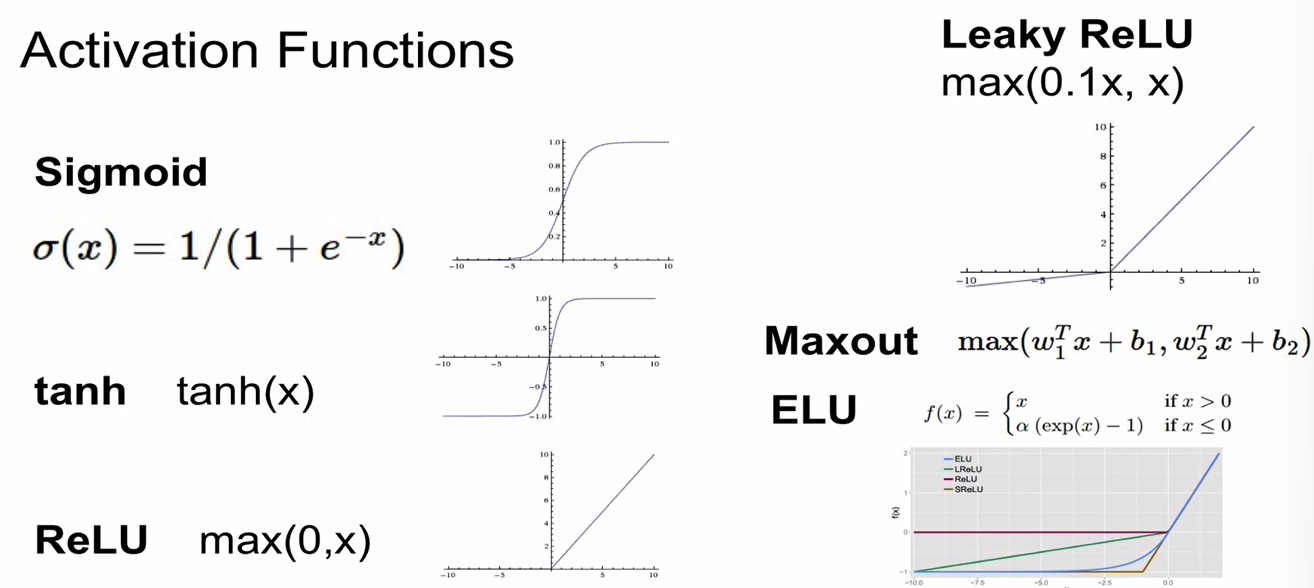
- 개선해야 할 점은 많지만, ReLU가 대부분의 경우에 사용됨.
-
기본적으로 Weight를 가지는 것만 layer라고 해서, weight를 가지지 않는 input layer는 layer로 count하지 않음.
-
모든 node들이 연결되어 있는 layer를 Fully-connected layer라고 한다. (FC layer)
-
fully connected layer - 연산의 편의성 제공
-
neuron이 많아질 수록 분류 능력이 좋아짐. (more neurons = more capacity)
-
neural network의 size가 regularization 역할을 하는 것은 아님. 일반화를 위해서는 regularization strength를 높여야 함.
-
regularization strength를 세게 할 수록 일반화되고 overfitting이 일어나지 않음.
-
즉, 데이터의 overfitting이 일어나지 않도록 하려면 network를 작게 만드는 것이 아니라 regularization strength를 크게 해줘야 하는 것임.
-
regularization이 잘된다는 전제 하에, neural network는 클 수록 좋음

CS231N 5강 Training NN part1

- Train on ImageNet
- 만약 우리가 갖고 있는 데이터셋이 너무 작은 경우에는 기존 imageNet에서 학습한 모든 가중치를 고정시키고, 마지막 classifier 부분만 다시 training함. (ex. 마지막의 softmax layer만 변경해줌)
- 만약 우리가 갖고 있는 데이터셋이 너무 작지는 않지만 크지도 않다면, finetuning.
(1) 다른 곳에서 가져온 가중치들을 새로운 모델의 initializtion value로 사용하고, 이를 기반으로 전체 netwrok를 학습시킴
(2) 윗단은 그대로 두고 아랫단을 학습시킴.
- Mini-batch SGD
- data sampling
- forward pass - loss 구함
- back propagation - gradient 구함
- gradient를 이용해서 parameter를 update
- 다음 batch에 대해서 진행 (1~5 반복)
History
-
Perceptron (1957)
hw, circuit 형태
activation function이 binary step function이라서 미분 불가능 -> back prop 불가능 -> 가중치 W 값들을 임의로 조절해가면서 network 최적화 시도 -
Multi-layer perceptron (1960)
parametric approach 도입 -> 성과가 별로였음
(암흑기 1) -
Back Prop 도입 (Rumelhart, 1986)
미분 가능 - 가중치를 체계적인 방법으로 찾아나갈 수 있음
network가 커지면 제대로 동작하지 못함.
(암흑기 2) -
Restricted Boltzman Machine(RBM) 이용 - pretrain 단계 도입
RBM 활용하여 각각 pretrain 후 하나로 묶어서 back prop 진행, 마지막 단계에서 fine-tuning -
2010 - Microsoft, AlexNet
Sigmoid
- 값의 범위를 [0,1]로 squash해줌.
문제점
(1) vanishing gradient: 0 또는 1에 매우 가까운 결과값을 내는 뉴런
x의 값이 너무 작거나 너무 큰 경우에는 local gradient가 0이 되어 gradient가 없어지고 back prop이 멈추는 현상이 발생함.
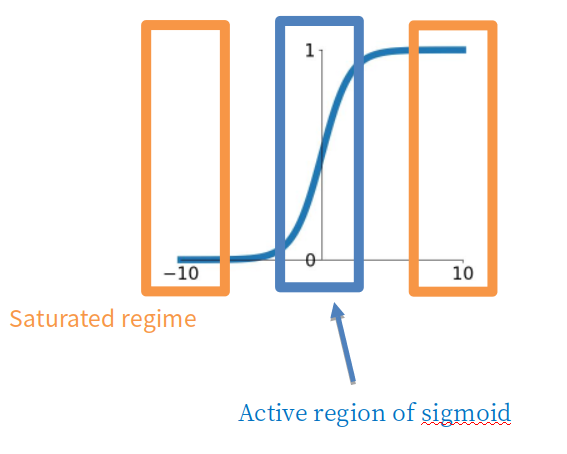
(2) sigmoid outputs are not zero-centered (설명)
input 가 항상 양수라고 가정하면, w의 gradient는 항상 양수이거나 항상 음수임. graident가 이동할 때 지그재그로 이동할 수 밖에 없음. convergence가 느려짐.

(3) exp() 계산에 computing resource가 많이 필요함.
tanh(x)
-
hyperbolic tangent
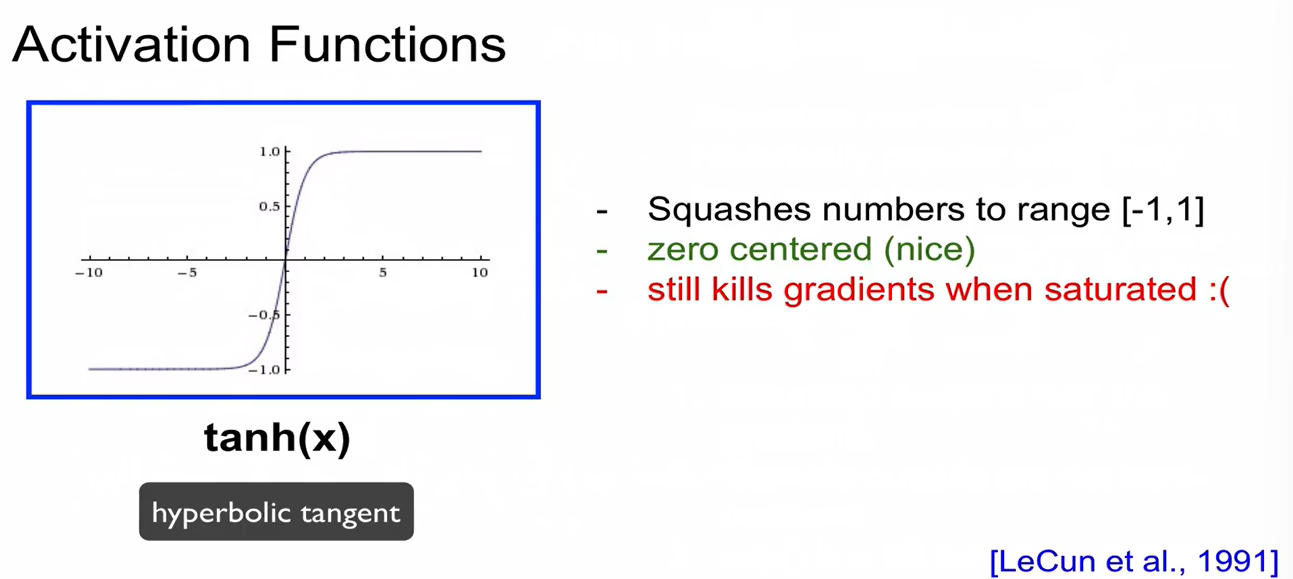
-
값의 범위를 [-1,1]로 squash해줌. -> zero-centered
-
하지만 saturation 발생함.
ReLU
- Rectified Linear Unit
- 를 계산함
- saturation 발생 X, convergence가 빠르게 이루어짐.
문제점
(1) zero-centered 되어 있지 않음.
(2) x<0 인 경우, gradient가 0임 -> vanishing gradient가 발생함.

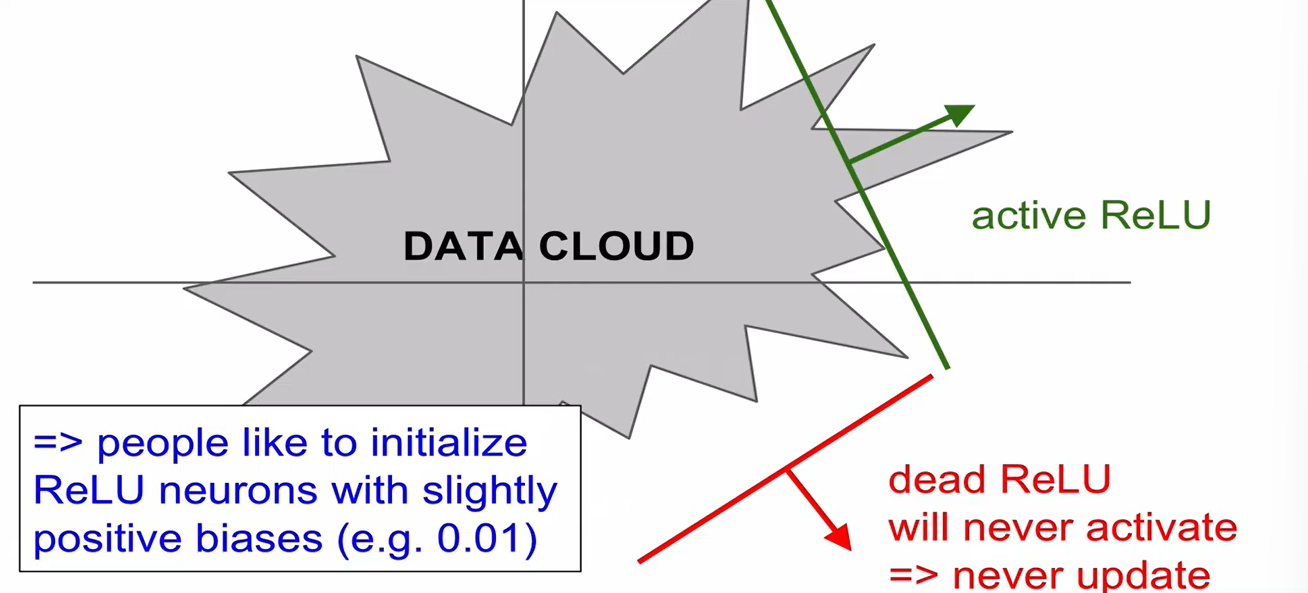
- data cloud 내부에서 activation 된 경우 - active ReLU, 외부 - deadReLU
- deadReLU 발생
(1) weight initialization (2) learning rate가 너무 큰 경우, deadReLU zone으로 나가버리는 경우
Leaky ReLU & PReLU

ELU (Exponetial Linear Units)
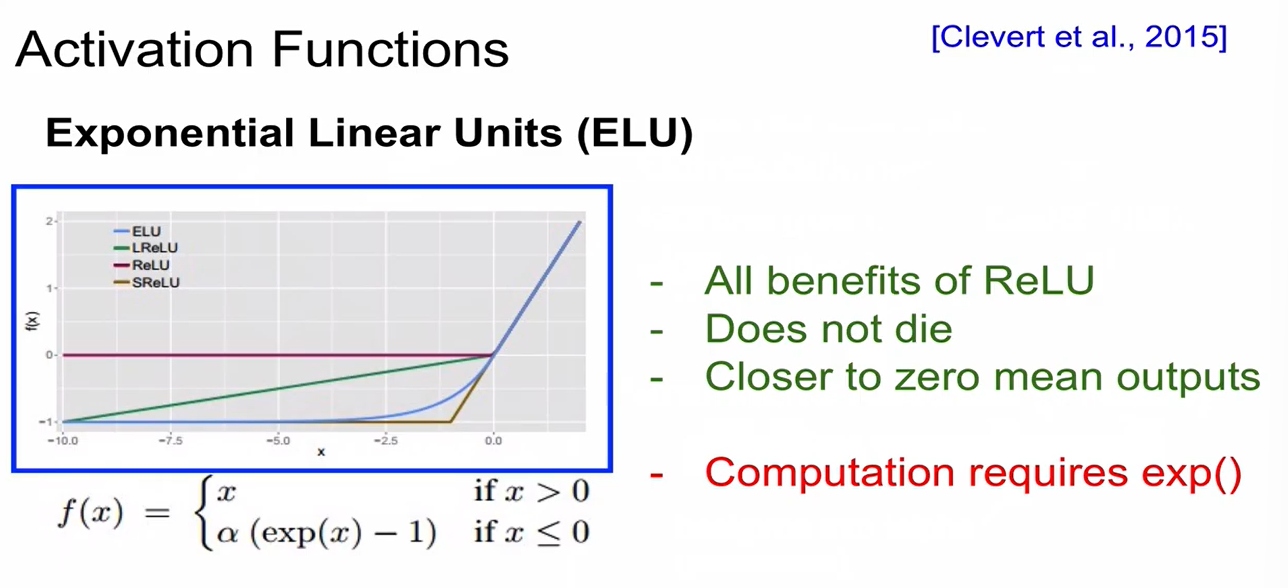
Maxout

- parameter 2배 -> 연산 2배!
In practice
- ReLU를 쓰기!
- 실험이 필요한 경우 Leaky ReLU/Maxout/ELU 사용해보기
- tanh와 sigmoid는 쓰지말 것 (sigmoid는 LSTM에서 쓰이기는 함.)

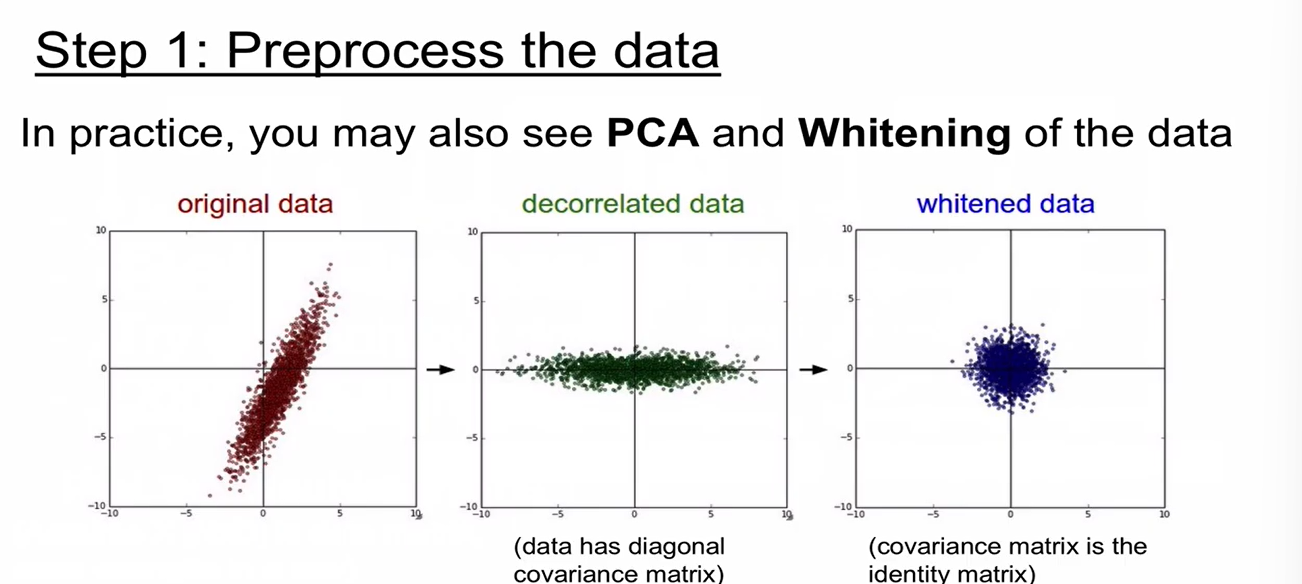
- 이미지 데이터에서는 Normalization, PCA, Whitening 하지 않음.
- 이미지 데이터의 경우 Zero-Centered로만 만들어주면 됨.
- Zero-Centered로 만드는 방법
(1) subtract the mean image (ex. AlexNet - orange 색을 갖는 blob을 빼줌)
(2) subtract per-channel mean (ex. VGGNet - R,G,B 3개의 channel 별 평균을 빼줌)
Weight Initialization
- 중요! Restricted Boltzman Machine(RBM)이 작동하지 않았던 이유도 weight intialization이 잘못되었기 때문임.
방법
(1) small random number (gaussian with zero mean and 1e-2 standard deviation)
-> 작은 network에서는 작동하지만 큰 network에서는 vanishing gradient 문제가 발생함.
(2) Xavier initialization
W=np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)잘 작동하지만 ReLU 사용 시 문제가 생김
-> solution (3) by Kaiming He - relu에 최적화!
W=np.random.randn(fan_in, fan_out/2) / np.sqrt(fan_in)Batch Normalization
- W 초기화에 의존하지 않도록 해줌!
- vanishing gradient가 발생하지 않도록, 학습 속도를 가속화시키면서도 학습 과정 전반을 안정화하는 근본적인 방법
- 불안정화가 일어나는 이유는 각 layer들을 거치면서 입력 값의 분포가 달라지는 현상 (covariance shift)가 일어나기 때문임.
-> 각 layer를 거칠 때마다 normalization을 하자!

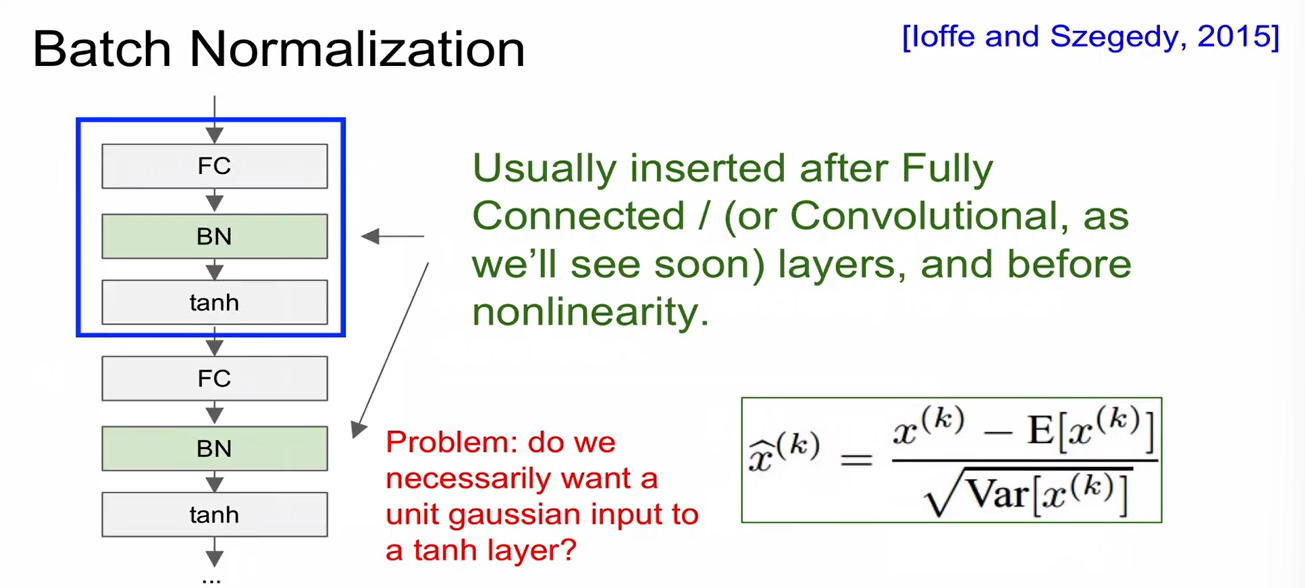

- mean, var 구할 때, training 시에는 batch 기준으로 구하고 test 시에는 전체 데이터에 대해 구함. 그리고 이를 이용하여 BatchNorm 진행
Baby Sitting the Learning Process!!
-
Sanity Check
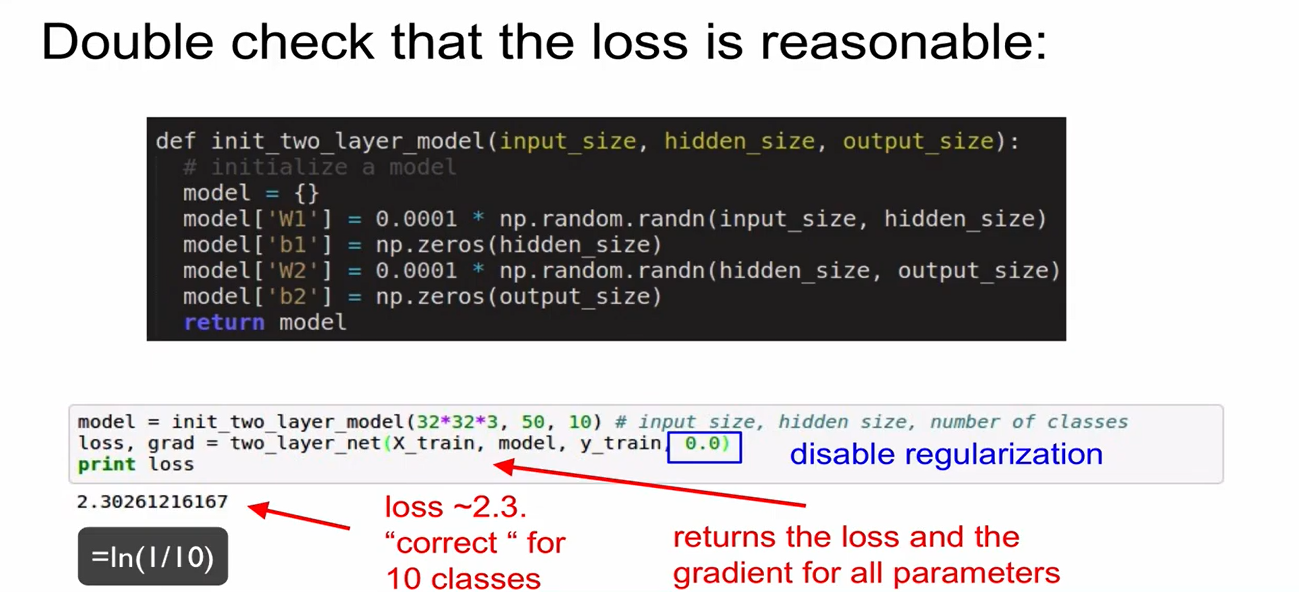
-
Regularization -> loss 커짐
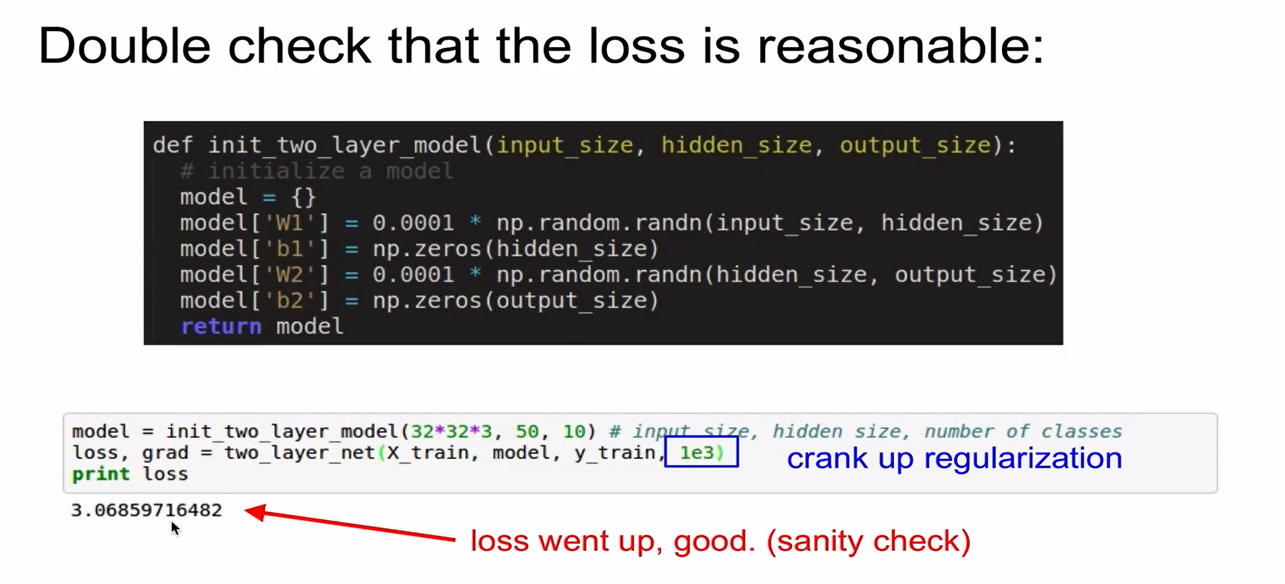
-
데이터의 일부만 training 시키고 (reg X) loss와 accuracy를 출력해서 overfitting이 일어나고 있는지를 확인해야 함. overfitting이 안 일어나면 문제가 있는 것임. overfitting이 일어나는 이유는 back prop이 잘 작동하며 learning rate이 적절하게 설정되었기 때문임.

-
learning rate을 극히 작은 숫자로 설정하면 cost 변화 X.
-
이때 loss는 안 변하고 있는데 train/val accuracy는 증가하고 있음. 왜지?
score가 diffuse한 상태로 학습을 시작하기 때문에 score는 약간 변화함.

-
learning rate 높게 하면 NaN(not a number) or inf 나오게 됨.


Hyperparameter Optimization
Cross-validation strategy
1단계 Coarse search) 반복을 여러번 하지 않는다. epoch를 작은 값으로 설정하여 몇번만 반복하면서 param 어떻게 설정할지 감 잡기
2단계 Finer search) running time을 길게하고 세부적인 param search
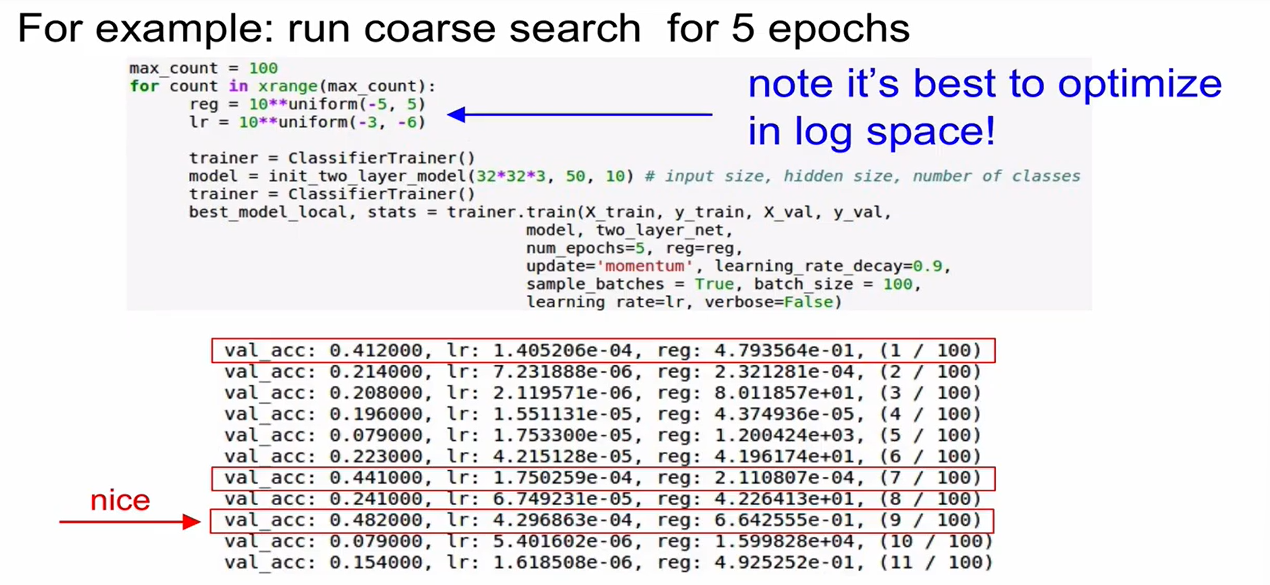
- log space화를 하는 것이 연산에 유리함.
- 작은 epoch를 돌려본 뒤 가장 높은 accuracy를 갖는 case를 찾고 해당 case의 parameter 값을 사용하여 좀더 큰 epoch로 돌려보기
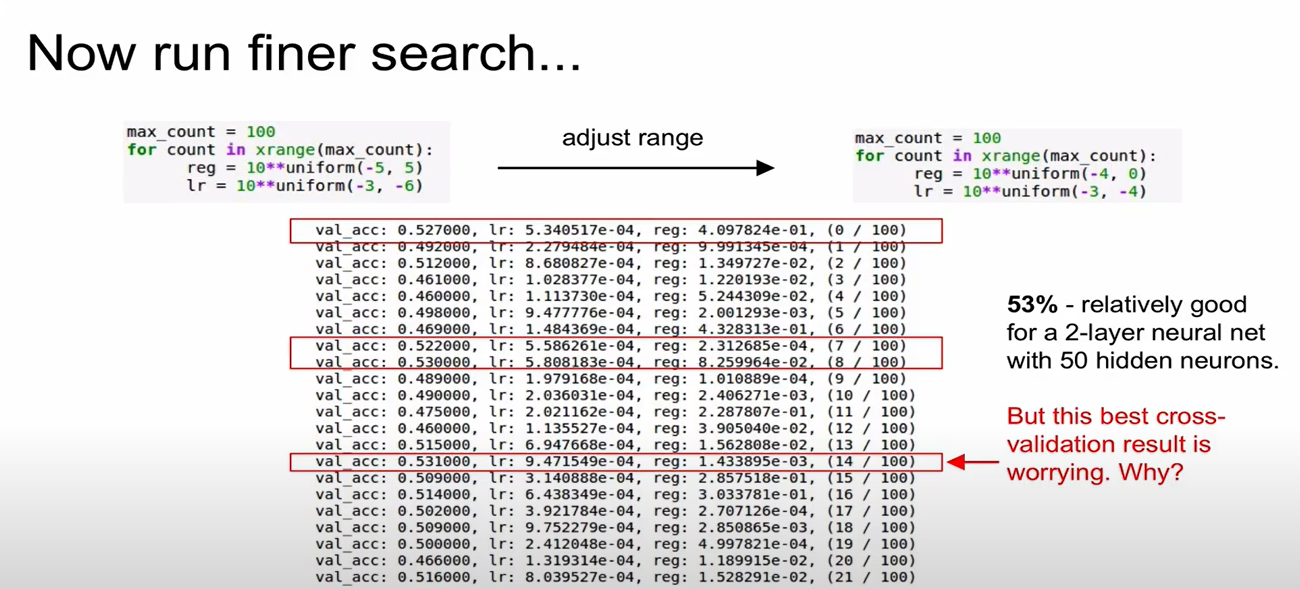
- val_acc=0.531일 때를 보면 learning rate의 값이 설정한 boundary ()와 매우 가까운 값을 보임. 범위가 잘못된 것을 의미함. -2, -2.5 정도로 고쳐보기
- 지금은 random search한 case임, grid search하는 경우도 있음(등간격 탐색) -> grid search는 나쁜 방법임. 언제나 random search를 사용해야 함!
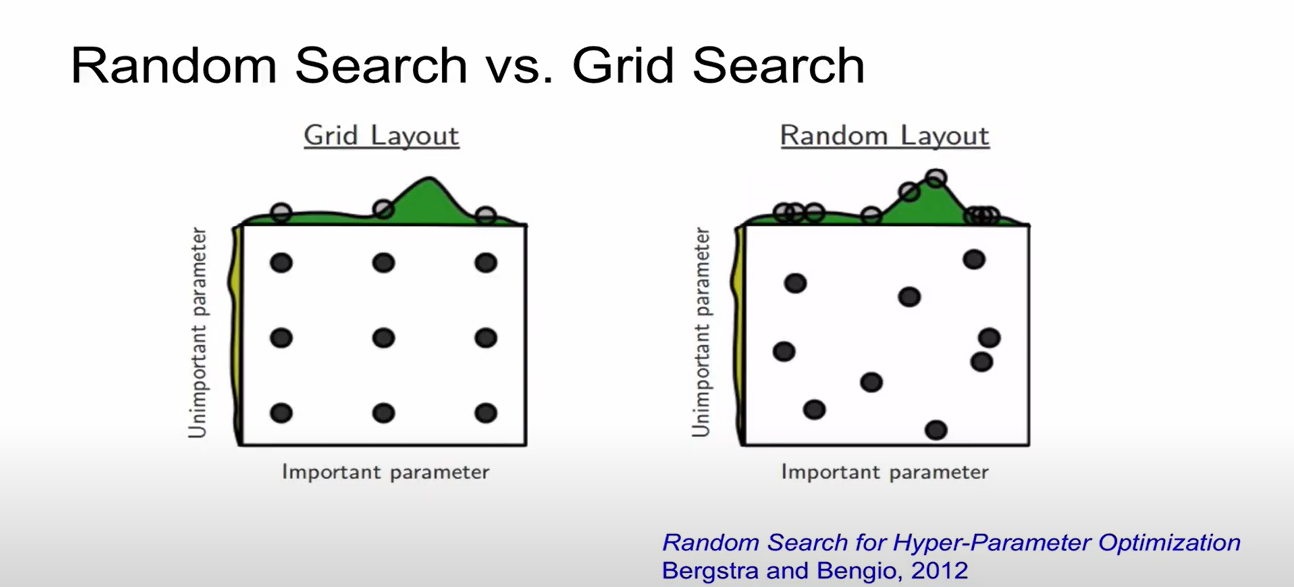
결정해야 하는 parameter
- network architecture (hidden layer 개수, node 개수 등)
- learning rate, its decay schedule, update type
- regularization (L2/Dropout strength)
monitoring 대상 1: loss
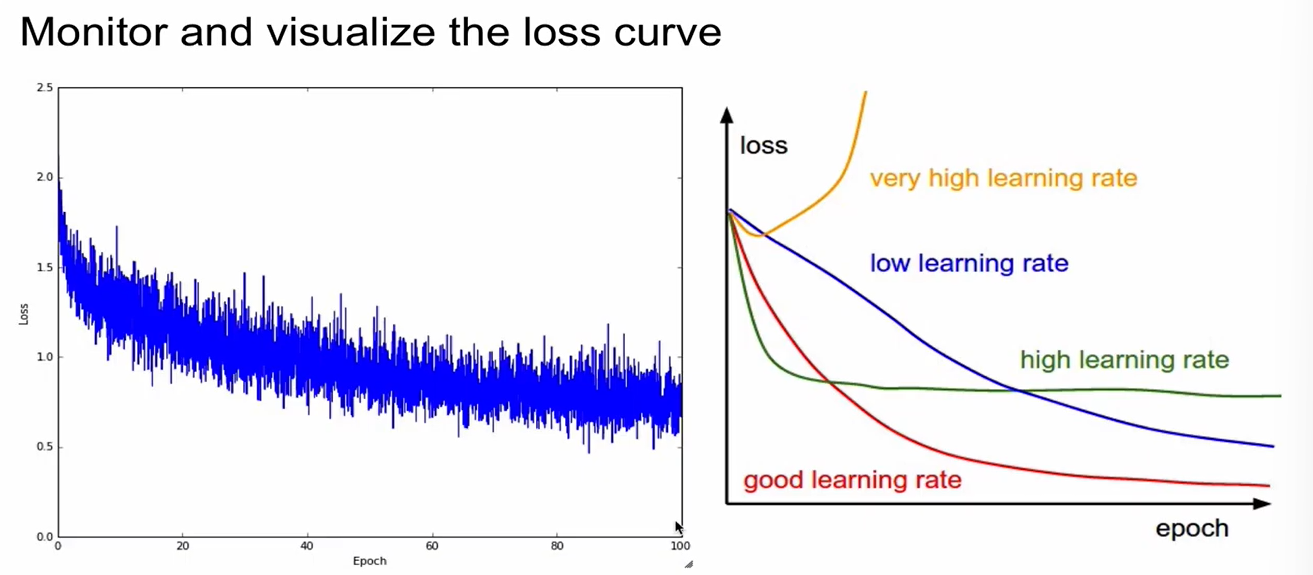
- loss가 너무 느리게 converge함.
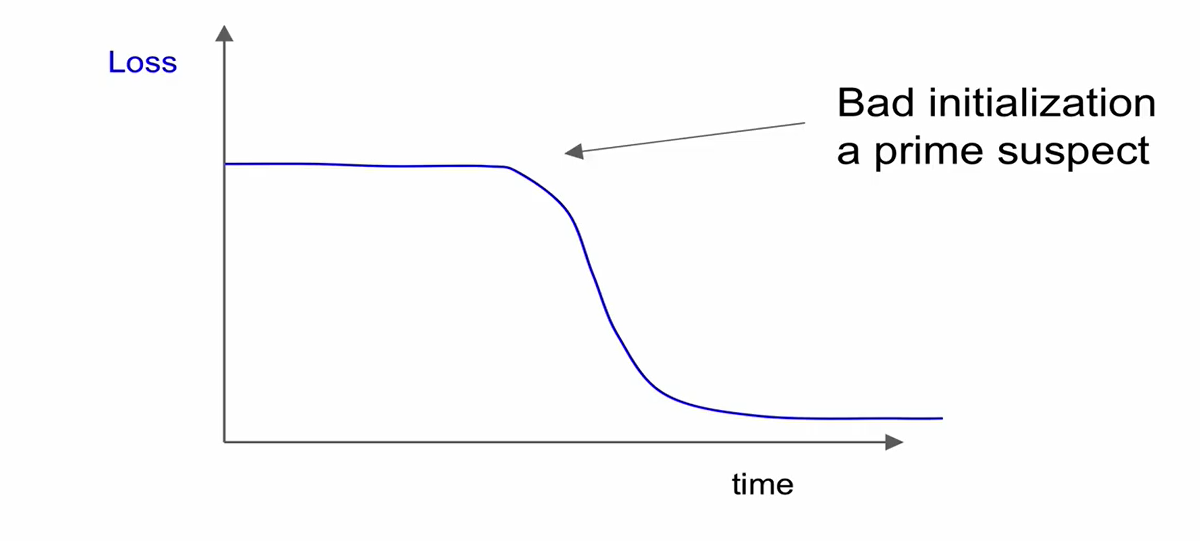
- initialization을 잘못한 case
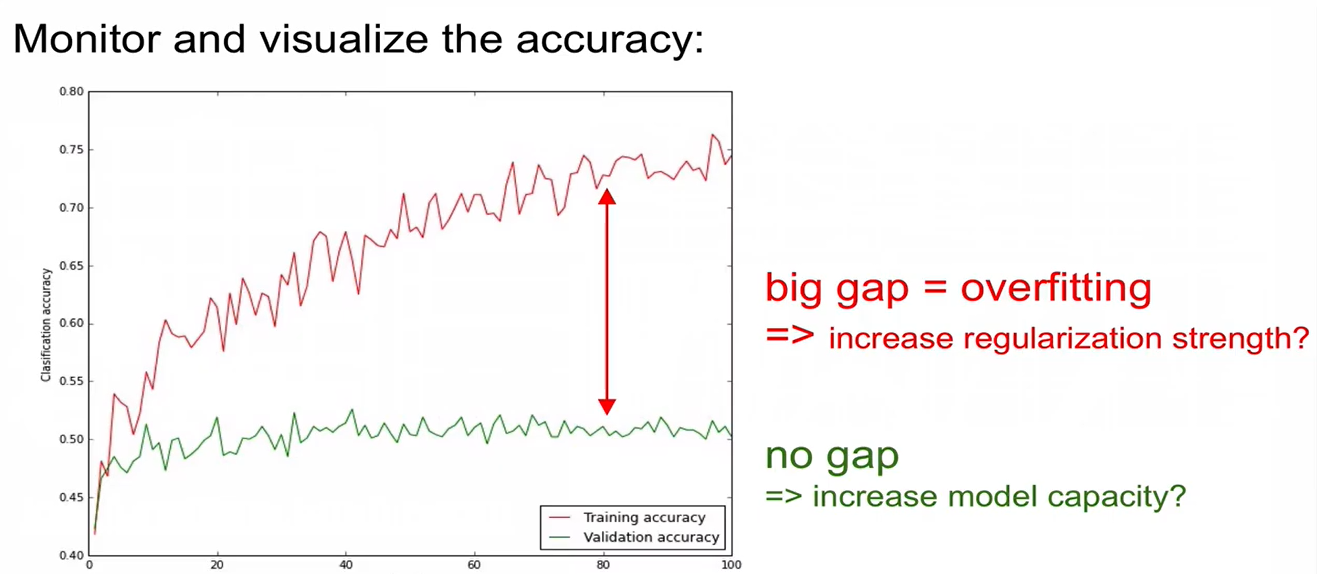
monitoring 대상 2: accuracy
- loss는 값 자체로 해석이 불가능하지만, accuracy는 그 값 자체로 해석이 가능해서 monitoring 대상으로 더 선호됨
- training accuracy와 validation accuracy는 차이가 나는 게 당연하지만, 너무 큰 차이가 나거나 아예 gap이 없으면 문제가 있음.
monitoring 대상 3: weight updates/weight magnitudes
- weight를 한번 업데이트 할 때의 크기를 weight 전체의 크기로 나눠준 것
- 0.001 정도가 가장 이상적임.

Summary

