Reinforcement Learning Based Control for Uncertain Robotic Manipulator Trajectory Tracking (CAC 2022, IEEE)
- Authors: Aohua Liu, Bo Zhang, Weiliang Chen, Yiang Luo, Shuxian Fang, Ouyang Zhang, Zhuang Liu, Zhenhuan Wang, Jianxing Liu*
- Conference/Publisher: 2022 China Automation Congress (CAC), IEEE
- DOI: 10.1109/CAC57257.2022.10055583
로봇팔 궤적 추종 paper
0. 한눈에 보기 (요약)
이 논문은 로봇 매니퓰레이터의 궤적 추종(tracking) 문제에서, 모델 불확실성(질량/길이 파라미터 불일치 등)과 외란(시간변화 토크)을 고려한다. 핵심 아이디어는:
- 기본 제어기로는 안정성을 보장하는 슬라이딩 모드 제어(SMC) 를 사용한다.
- 강화학습(RL) 은 “모델 불확실성/외란을 보상하는 추가 토크(Compensation torque)”를 학습한다.
- 학습은 Soft Actor-Critic(SAC) 구조를 따르되, Lyapunov 제약(Constraint) 을 추가해 학습된 제어가 폐루프 안정성을 해치지 않게 한다.
- 시뮬레이션(3-DOF RRP 매니퓰레이터)에서 SMC 단독 대비 SMC+RL 결합(compound) 이 더 작은 오차로 추종함을 보인다.
[Fig.1 삽입: Model-based RL controller block diagram] 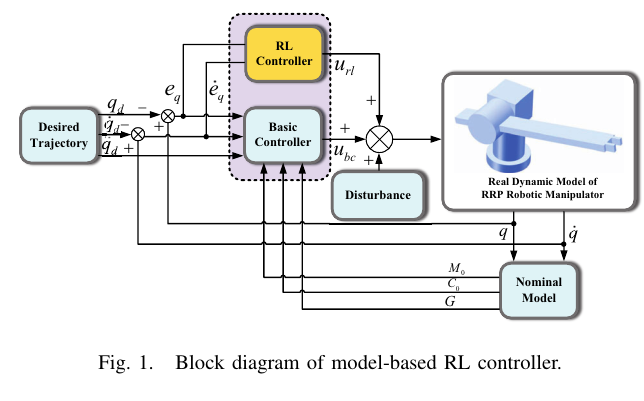
[Fig.2 삽입: Off-line training process of RL] 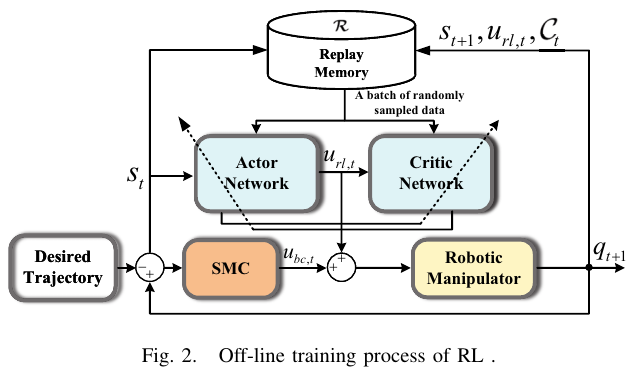
[Fig.3 삽입: 3-DOF manipulator 구조] 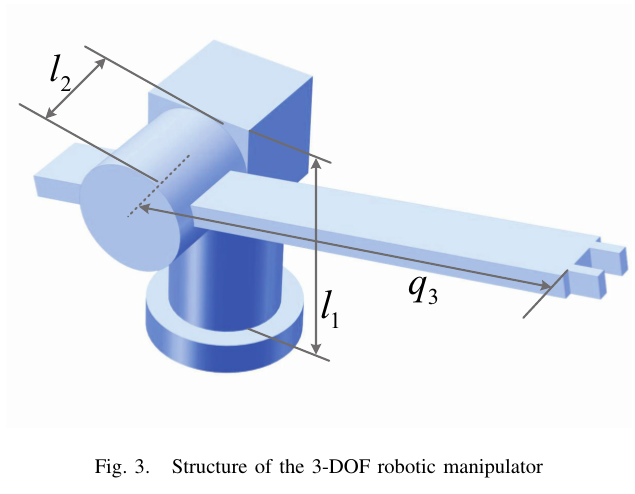
[Fig.4 삽입: 각 관절 tracking 결과(좌 SMC, 우 compound)] 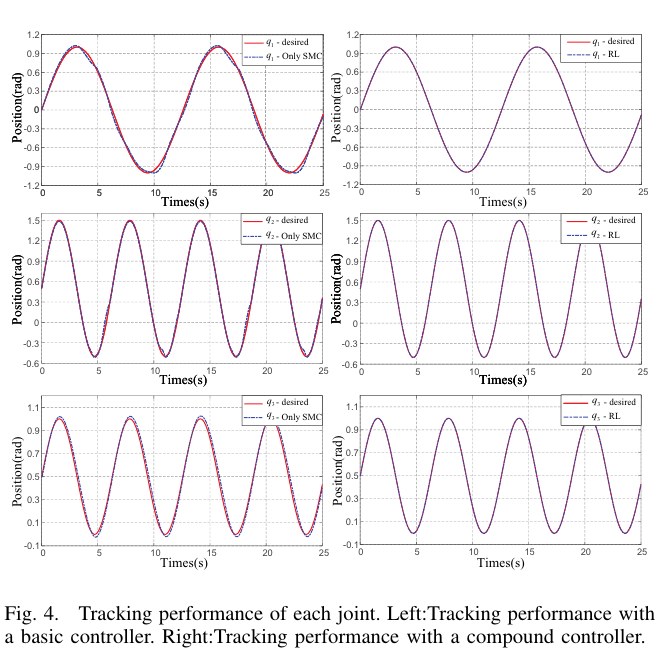
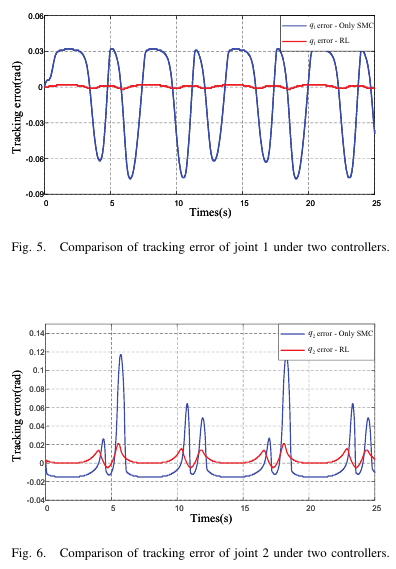
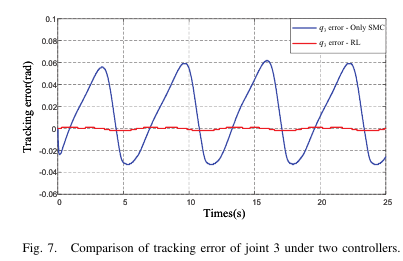
[Fig.5~7 삽입: 관절별 tracking error 비교]
1. Abstract 정리
논문은 불확실성을 가진 로봇 매니퓰레이터의 궤적 추종 제어를 다룬다. 전통 제어법 + 딥 RL을 결합한 복합 제어기(compound controller) 를 설계해 추종 정확도와 적응성을 높인다. 모델 기반 제어를 활용해 RL 학습의 샘플 효율을 높이고, SAC 구조 + Lyapunov 제약을 통해 불확실성을 보상하면서 안정성을 유지한다. 3-DOF 매니퓰레이터 시뮬레이션에서 순수 모델 기반(SMC) 대비 더 높은 정확도를 보인다.
2. Introduction: 왜 SMC + RL 결합인가?
로봇 매니퓰레이터는 비선형/강결합/시변 특성이 강하고, 정확한 모델링이 어려워 “정확 추종”이 어렵다.
2.1 기존 접근의 한계
- 모델 기반 제어(SMC 등): 안정성과 강인성에 강하지만, 모델 불일치가 크면 보수적으로 큰 이득을 써야 하고(채터링, 오버슈트, 과도한 제어 등), 성능이 떨어질 수 있다.
- 적응제어/관측기 기반: 파라미터 식별이 어렵거나, 특정 형태의 불확실성(매칭 외란)만 보상 가능해 적용 제한이 있다.
- 모델 프리 RL: 데이터로 정책을 학습해 모델 의존도를 낮추지만, 폐루프 안정성 보장이 어렵고 학습 효율도 문제다.
2.2 결합의 장점(논문 주장)
- 기본 제어기(SMC)가 “최소한 안정성/오차 유계(bounded)” 를 잡아주면, RL은 그 위에서 “불확실성 보상” 에 집중할 수 있다.
- 결과적으로 RL이 무작정 탐험하다 불안정해지는 “불필요한 실패 시도”가 줄고, 샘플 효율이 증가한다.
- 불확실성 보상으로 SMC의 스위칭 이득을 낮춰 채터링을 완화할 수 있다.
N-DOF 매니퓰레이터의 동역학은 다음과 같이 쓴다.
M(q)q¨+C(q,q˙)q˙+G(q)=τ+d(1)
- q,q˙,q¨∈Rn: 관절 위치/속도/가속도
- M(q)=M0(q)+MΔ(q): 관성 행렬 (nominal + 불확실)
- C(q,q˙)=C0(q,q˙)+CΔ(q,q˙): 코리올리/원심 항 (nominal + 불확실)
- G(q): 중력 항
- τ: 입력 토크
- d: 외란 토크
- M0,C0,G 는 알려진 nominal, MΔ,CΔ,d 는 미지지만 유계(bounded) 라고 둔다.
3.1 불확실성을 하나의 항으로 묶기
M0 가 non-singular라고 가정하면 (1)을 다음처럼 정리한다.
q¨=M0−1(τ−C0q˙−G)−L(q,q˙,q¨,t)(2)
여기서 전체 불확실성(모델 불일치 + 외란)을
L(q,q˙,q¨,t)=−M0−1(MΔ(q)q¨+CΔ(q,q˙)q˙−d)
로 정의한다.
해석: “모델의 불확실한 부분”과 “외란 토크”를 모두 L 로 합쳐버리면, 이후 제어 설계에서 “미지의 항 하나” 를 보상하는 문제로 바뀐다. RL이 학습할 대상도 결국 이 L 을 상쇄하도록 추가 토크를 만들어내는 것이다.
3.2 추종 오차 상태공간 표현
목표 궤적 qd,q˙d,q¨d 가 주어졌다고 하자. 오차를
e1=q−qd,e2=q˙−q˙d,e˙2=q¨−q¨d
로 두면 상태공간은
e˙1=e2
e˙2=M0−1(τ−C0q˙−G)−L(q,q˙,q¨,t)−q¨d(3)
목적: 각 관절이 목표 궤적을 따라가도록 즉 e2→0 (그리고 보통 e1→0)가 되게 하는 제어 입력 τ 를 설계하는 것이다.
4. Controller Design: u=ubc+url
논문은 전체 제어 입력을 기본 제어기 + RL 보상으로 분해한다.
u=ubc+url(4)
- ubc: 기본 제어기(여기서는 SMC). 안정성/오차 유계를 책임.
- url: RL이 학습한 보상 토크. 불확실성/외란 상쇄가 목적.
[Fig.1 삽입: 모델 기반 RL 블록도]
(Desired trajectory → 기본제어기/명목모델 → 실제 플랜트, RL 보상 토크가 추가로 더해지는 구조)
5. Basic Controller: Sliding Mode Control(SMC)
논문은 [15]를 따라 SMC 기반 기본 제어기를 다음처럼 준다.
ubc=M0[−κθsiga(e2)−Ktanh(ρ2s)+q¨d]+C0q˙+G(5)
여기서
- siga(e2)=[∣e21∣asign(e21),…,∣e2n∣asign(e2n)]T
- a=2−λ 는 상수
- 슬라이딩 변수는
s=e1+λ1sigα(e2)
주의(확실하지 않음): PDF 텍스트 추출본에서 sigα(⋅) 의 정확한 지수/정의(예: ∣x∣αsign(x) 형태) 표기가 일부 깨져 있다. 원문에서는 일반적인 terminal sliding 형태의 sig 함수로 이해된다(추측).
5.1 왜 이런 형태인가?
- SMC는 슬라이딩면 s=0 로 상태를 끌어와 유지하면 오차가 감소한다.
- tanh(⋅) 를 쓰는 것은 이상적인 sign switching 대신 연속 근사로 채터링을 줄이기 위함이다(스무딩).
- 하지만 불확실성이 크면 SMC의 스위칭 이득 K 를 크게 잡아야 하고, 이는 채터링/과도 제어로 이어질 수 있다.
- 그래서 RL이 url 로 불확실성 보상을 해주면, SMC는 “안정성 유지”에 집중하면서 이득을 과도하게 키우지 않아도 되는 그림이다.
6. Reinforcement Learning Design
RL은 “불확실성 보상 토크”를 학습한다. 즉 url≈(불확실성으로 인한 추가 토크) 를 만들어서, 결과적으로 (3)의 L 항 영향을 줄이는 것이 목표다.
6.1 MDP 정의
논문은 MDP를 ⟨S,M,P,C,γ⟩ 로 둔다.
- 상태: 각 관절의 추종오차와 속도오차
st={e1,t,e2,t}
- 행동(모션): url,t (RL 보상 토크)
- 비용함수:
Ct=e1TD1e1+e2TD2e2(6)
여기서 D1,D2 는 positive definite.
해석: 추종 문제에서 가장 직관적인 비용은 “오차 제곱”이다. e1(위치 오차)와 e2(속도 오차)를 동시에 줄이도록 설계했다. 다만 제어입력 크기(에너지)를 벌점으로 넣지 않았다는 점은 특징(또는 한계)일 수 있다.
6.2 Q-function / Value function
논문은 Q-function을 다음처럼 둔다.
Qπ(st,url,t)=γst+1∈S∑P(st+1∣st,url,t)Vπ(st+1)+Ct(7)
Value function은 누적 비용으로 서술한다(원문 표기 유지).
Vπ(st+1)=t∑+∞url,t∈M∑π(url,t∣st)st∈S∑P(st+1∣st,url,t)(γVπ(st+1)+Ct)(8)
그리고 목표는 Q를 최소화하는 최적 정책
π\*=argπminQπ(st,url,t)(9)
직관: 비용이 작아지도록(오차가 작아지도록) 정책을 학습한다.
6.3 SAC (Soft Actor-Critic): 엔트로피로 탐험 강화
SAC는 엔트로피 항을 추가해 “확률적 정책의 다양성”을 유지한다. 논문은 목적을
π\*=argπmin[Qπ(st,url,t)+μH(π(url,t+1∣st+1))](10)
로 쓴다. 엔트로피는
H(π(url,t∣st))=−url,t∈M∑π(url,t∣st)ln(π(url,t∣st))=−Eπ[ln(π(url,t∣st))](11)
- μ: temperature(엔트로피 가중치). 크면 더 랜덤/탐험, 작으면 더 결정적.
6.4 Lyapunov 제약: “학습해도 안정성을 깨지 말 것”
RL은 안정성 보장이 약하다는 약점이 있다. 논문은 Lyapunov 제약을 추가한다.
- Q-function을 Lyapunov 후보로 보고,
- 다음을 만족하도록(학습 중) 제약을 걸어 폐루프 안정성을 유지하려 한다.
원문 제약식은 다음과 같이 제시된다(부등호 기호가 PDF 추출에서 누락되어 확실하지 않음).
Qπ(st+1,url,t+1)−Qπ(st,url,t)≤−νCt(12)
확실하지 않음: PDF 텍스트 추출본에는 부등호가 빠져 있고 “−νCt” 형태만 남아 있다. 문맥상 “Lyapunov 감소 조건”이므로 위처럼 해석하는 것이 자연스럽다(추측).
이를 라그랑지 승수 λ 로 묶어 최적화 문제를 다음처럼 바꾼다.
π\*=argπmin[Qπ(st,url,t)+μH(π(⋅))+λ(Qπ(st+1,url,t+1)−Qπ(st,url,t)+νCt)](13)
직관: 제약을 위반하면 라그랑지 항이 벌점을 크게 주어, “정책이 안정성 조건을 만족”하도록 압력을 준다.
6.5 SAC 업데이트(정책 평가/개선)
Policy evaluation(Q 업데이트)는 Bellman 형태로:
Qπ(st,url,t)=Ct+γEst+1[Eπ(Qπ(st+1,url,t+1)−μln(π(url,t+1∣st+1)))](14)
Policy improvement(정책 업데이트)는:
π′=argπ∈ΠminEπ[Qπ(st,url,t)+μln(π(url,t∣st))+λ(Qπ(st+1,url,t+1)−Qπ(st,url,t)+νCt)](15)
7. 딥 RL 구현: Actor/Critic + Replay Buffer (오프라인 학습)
논문은 오프라인 학습 프로세스를 제시한다.
[Fig.2 삽입: Off-line training process of RL]
(로봇 시스템에서 (s,u,C,s') 수집 → replay memory → 미니배치로 actor/critic 업데이트)
7.1 Critic(=Q 네트워크) 업데이트
actor 네트워크 πσ(url∣s) 와 critic 네트워크 Qω(s,url) 를 둔다.
- replay buffer R 에서 샘플을 뽑아 Q를 학습한다.
Behrman residual(= Bellman residual) 최소화:
JQ(ω)=E(st,url,t)∼R[21(Qω(st,url,t)−Qobj)2](16)
타깃은(원문 표기):
Qobj=γEst+1[Eπ(Qωˉ(st+1,url,t+1)−μln(πσ))]+Ct
- ωˉ: 타깃 네트워크 파라미터(느리게 갱신)
미니배치 크기 N 에 대해 기울기:
∇ωJQ(ω)=(st,url,t)∼R∑N(Qω(st,url,t)−Qobj)∇ωQω(17)
7.2 Actor(정책) 업데이트
정책 손실은 다음으로 주어진다.
Jπ(σ)=E(st,url,t)∼R[μln(πσ)+Qπσ(st,url,t)+λ(Qπ(st+1,url,t+1)−Qπ(st,url,t)+νCt)](18)
그리고 (19)식은 “확실히 복원되지 않음” 상태로 남아 있다.
∇σJπ(σ)=X(19)
원문은 X=μ∇url,tlnπσ∇σuσ,t+μ∇σlnπσ+λ∇url,t+1Qω,t+1∇σπσ(⋅∣st+1) 와 같이 서술한다(추출본 기준).
확실하지 않음: PDF 추출본에서 (19)의 전체 형태가 일부 줄바꿈/기호 깨짐이 있어, 정확한 미분 기호와 인덱스 표기는 원문 PDF를 직접 확인하는 것이 안전하다. 다만 SAC의 reparameterization trick 기반 actor gradient 형태와 라그랑지 항의 gradient가 결합된 형태라는 점이 핵심이다.
7.3 Temperature(μ)와 Lagrange multiplier(λ) 학습
엔트로피 온도 μ 는 다음을 최소화하며 업데이트한다.
J(μ)=Eπ[−μlnπ(url,t∣st)−μH](20)
라그랑지 승수 λ 는 dual maximization으로 업데이트한다(원문 표기):
J(λ)=λE[Qθ,t+1−Qθ+νCt](21)
직관: λ 가 커질수록 Lyapunov 제약 위반에 대한 패널티가 강해져 “안정성 쪽으로” 정책을 끌어간다.
7.4 Algorithm 1 (논문 알고리즘) — 원문 흐름대로 정리
Algorithm 1: Control algorithm based on Deep RL

- Input: 기본 제어기 ub 하에서의 각 관절 tracking error
- Output: 최적 보상 토크(정책) 파라미터
- ω,σ,μ,λ 초기화
- 타깃 네트워크 ωˉ←ω
- while Training do
- 데이터 샘플링 루프:
- url,t∼πσ(url,t∣st) 샘플
- 시스템에 url,t 적용 → 새 상태 획득
- replay memory 갱신: R←R∪(st,url,t,Ct,st+1) (문장상 의미)
- 파라미터 업데이트 루프:
- ω←ω−rQ∇JQ(ω)
- σ←σ−rπ∇Jπ(σ)
- μ←μ−rμ∇J(μ)
- λ←λ+rλ∇J(λ)
- return ω\*,σ\*
해석: SMC가 이미 시스템을 “망가지지 않게” 잡아주므로, 데이터 수집이 비교적 안정적이고 replay 기반 오프라인 업데이트로 정책을 개선한다.
8. Stability Analysis (Theorem 1)
논문은 결합 제어 un=ubc+urln 의 안정성을 보인다. 분석에서는 “최종적으로 엔트로피 항이 0에 수렴하므로” 엔트로피를 무시해도 된다고 둔다(원문 문장).
Theorem 1 (원문)
n번째 iteration에서 얻은 결합 제어기
un=ubc+urln
는 원하는 궤적 주변에서 시스템을 안정화할 수 있다.
Proof (핵심 논리)
1) 초기에는 RL 보상토크가 없다고 두고 url,t0=0 인 상태에서 SMC만으로 안정(오차 유계)이 확보된다고 한다. 이때 Q는
Q0(st,url,t0)=Ct0+γQ0(st+1,url,t+10)(22)
이며 Ct0 는 오차 기반 비용이고 SMC로 인해 bounded.
2) Lyapunov 후보로 Q를 택해
Vt0=Q0(st,url,t0)=Ct0+γQ0(st+1,url,t+10)(23)
3) Lyapunov 제약(12)을 만족하면 V 가 감소(또는 비증가)하고 bounded → 오차가 0으로 가는 경향을 갖는다(원문 논리).
4) 정책 개선 단계에서
url,t1=πmin[Ct0+γQ0(st+1,url,t+10)](24)
정책 평가에서
Vt1=Ct1+γQ0(st+1,url,t+11)(25)
이 되어 Vt1≤Vt0 를 얻고, 반복하면 각 iteration의 제어가 시스템을 안정화한다는 결론.
코멘트: 엄밀한 제어이론 증명이라기보다는, “SMC가 기본 안정성 확보” + “Lyapunov 감소 조건을 학습 중 강제” + “policy iteration이 성능을 개선”이라는 직관을 수식으로 엮은 형태에 가깝다. 그래도 논문이 주장하는 바는 “RL을 얹어도 안정성 조건을 학습 과정에서 강제했기 때문에 폐루프 안정성이 유지된다”는 점이다.
9. Simulation (3-DOF RRP Manipulator)
[Fig.3 : 3-DOF(RRP) 구조]
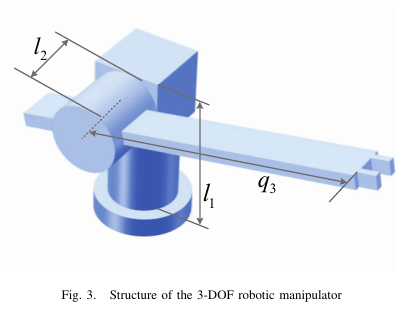
논문은 2개의 회전관절 + 1개의 직선관절(prismatic)을 가진 3-DOF 매니퓰레이터로 검증한다. 자세한 동역학은 [18]을 참고하라고 한다.
9.1 불확실성/외란 설정
- nominal 파라미터 M0,C0 는 “명목 파라미터” mi′,li′ 로 계산하며 실제 파라미터와 다르게 둔다(즉 모델 불일치).
- 외란 토크:
d(t)=⎣⎢⎡2.5sin(t)0.5sin(2t)cos(2t)+1⎦⎥⎤N⋅m
qd(t)=⎣⎢⎡sin(0.5t)sin(t)+0.50.5sin(t)+0.5⎦⎥⎤rad
-
초기 상태:
q(0)=⎣⎢⎡00.50.5⎦⎥⎤,q˙(0)=⎣⎢⎡000⎦⎥⎤ rad/s
-
SMC 기본 제어 파라미터(원문):
κ=45,θ=79,ρ=0.1,K=diag{13,75,6}
9.2 Table I — 로봇 시스템 파라미터 (원문)
[Table I 삽입]
| Parameters | Description | Value |
|---|
| m1 | Quality of joint 1 | 2.00 kg |
| m2 | Quality of joint 2 | 1.50 kg |
| m3 | Quality of joint 3 | 1.00 kg |
| l1 | Length of joint 1 | 0.35 m |
| l2 | Length of joint 2 | 0.35 m |
| m1' | Nominal quality of joint 1 | 1.20 kg |
| m2' | Nominal quality of joint 2 | 1.00 kg |
| m3' | Nominal quality of joint 3 | 0.70 kg |
| l1' | Nominal length of joint 1 | 0.30 m |
| l2' | Nominal length of joint 2 | 0.15 m |
| g | Gravitational acceleration | 9.80 m/s² |
9.3 Table II — Algorithm 1 하이퍼파라미터 (원문)
[Table II 삽입]
| Parameters | Value |
|---|
| ν | 0.06 |
| Batch size | 256 |
| time step δt | 0.01 |
| Steps per episode | 5000 |
| Soft replacement ς | 0.005 |
| Discount factor γ | 0.9 |
| Target entropy H | -3 |
| Learning rate rQ | 4 × 10^-4 |
| Learning rate rπ | 6 × 10^-4 |
| Learning rate rμ | 3 × 10^-4 |
| Learning rate rλ | 1 × 10^-4 |
| Memory capacity | 5 × 10^5 |
| Structure for actor network | (64, 32) |
| Structure for critic network | (128, 64) |
9.4 학습/평가 프로토콜(원문)
- 학습: 시간스텝 0.01s, 50s 시뮬레이션
- 에피소드당 “100 times such process”를 반복해 정책을 얻는다고 서술(문장상: 한 에피소드에서 여러 rollout을 하는 구조로 이해됨)
- 10개의 전략을 학습 후 가장 좋은 것을 선택
- 평가: 25s만 실행(학습보다 짧게)하여 “짧은 시간 내 오차 수렴”을 확인
코멘트: 학습 세부(정확히 몇 episode/몇 rollout/선정 기준)는 논문에서 상세하게 수치로 완전히 풀어쓰진 않는다. 다만 표(Table II)로 주요 하이퍼파라미터를 제공한다.
10. 결과: SMC 단독 vs SMC+RL 결합
[Fig.4 ]
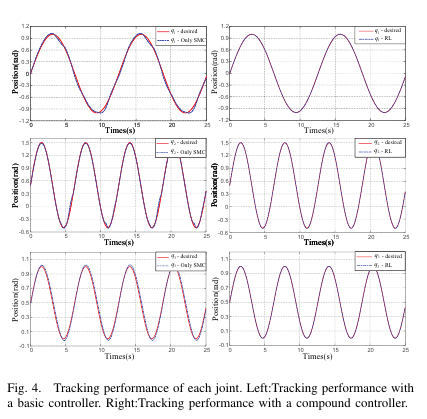
- 좌: SMC 단독 추종
- 우: 결합 제어(SMC + RL)
논문 관찰:
- SMC만으로는 불확실성/외란 때문에 만족스러운 추종이 어렵다.
- RL을 더하면 추종이 “유의미하게” 개선된다.
- 기본제어기+Lyapunov 제약 덕분에 안정성도 유지된다.
[Fig.5~7 : 관절별 tracking error 비교]
- 각 관절 오차가 더 작은 영역으로 수렴하며, 주기적 외란/궤적 형태에 따라 주기적인 변화는 남는다.
- 그러나 RL 결합이 오차 크기를 크게 줄인다.
11. Conclusion (원문 요지)
논문은 불확실한 매니퓰레이터 궤적 추종 문제에서 SMC+딥 RL 결합 제어기를 제안했다.
- SMC: 안정성 유지 + RL의 불필요한 실패 시도 감소
- SAC + Lyapunov constraint: 모델 불확실성/외란 보상 + 안정성 유지
- 3-DOF 시뮬레이션에서 순수 모델 기반(SMC) 대비 추종 정확도 향상
향후: 장애물 등 더 복잡한 환경 + 실제 실험으로 확장
12. 개인 코멘트(읽을 때 체크포인트)
- 핵심 기여는 “SMC가 안정성을 잡고 RL이 보상” 이라는 구조적 결합이다.
- Lyapunov 제약을 Q-function에 얹는 방식은 “학습 기반 제어의 안정성” 문제를 다루려는 시도.
- 다만 (12) 부등호, (19) 미분표기 등 일부는 PDF 추출 과정에서 기호가 불명확해, 원문 PDF로 교차 확인이 필요하다(확실하지 않음).
- 시뮬레이션은 3-DOF로 제한되어 있고 실제 실험은 미래 과제로 남겨둔다.
13. 참고문헌
논문 말미 References [1]–[18]을 그대로 따른다(원문 참고).
- SAC 관련: Haarnoja et al. (2018) 등 [16], [17]
- SMC/ESO/UDE 및 강인제어 관련: [1]–[5], [15]
- 매니퓰레이터 동역학/제어 예시: [18]