RB-LLM Control: An Intelligent Control Framework with Rule-Based Large Language Model Decision-Making paper review
Trajectory Tracking
RB-LLM Control: An Intelligent Control Framework with Rule-Based Large Language Model Decision-Making
논문 정보
Title: RB-LLM Control: An intelligent control framework with rule-based large language model decision-making
Journal: Aerospace Science and Technology, Vol.168 (2026)
Authors: Fateme Aghaee, Hamid Reza Shaker
Abstract
본 논문은 대규모 언어 모델(LLM)의 장기 논리 추론 능력을 활용하여,
환경 외란과 모델 불확실성이 존재하는 상황에서도 자율 제어 시스템의
의사결정 능력을 향상시키는 RB-LLM(Rule-Based LLM) 제어 프레임워크를 제안한다.
LLM이 수학적·논리적 추론에서 불안정성을 보일 수 있다는 한계를 보완하기 위해,
규칙 기반 구조화 프롬프트(structured prompting)를 도입하였다.
RB-LLM은 자연어, 로그, 오류 정보를 해석하여 제어 입력 조정,
제어기 파라미터 튜닝, 비상 대응을 수행한다.
UAV 시뮬레이션 결과,
RB-LLM은 최대 오차를 기존 기법 대비 36%~89% 감소시키며,
모델 불확실성, 비선형성, 긴급 상황에서 우수한 적응성과 안전성을 보였다.
- Introduction
자율 제어 시스템은 다음과 같은 문제에 직면한다.
- 모델 불확실성
- 외란(Environmental disturbance)
- 파라미터 변화
- 제어기 튜닝의 어려움
전통적 제어(LQR, MPC)는 정확한 모델을 요구하며,
실환경 변화에 취약하다.
LLM은 다음 능력을 제공한다.
- 자연어 이해
- 고수준 추론
- 맥락 기반 의사결정
하지만 LLM은:
- 출력 변동성
- 수학적 추론 불안정성
이라는 단점을 가진다.
👉 본 논문은 이 문제를 해결하기 위해
Rule-Based LLM (RB-LLM) 구조를 제안한다.
1.1 Background
- MPC: 대규모 외란에 강함
- LTL + Lyapunov: 반응형 제어
- Adaptive Control: 불확실성 대응
- LLM 기반 제어 연구:
- Code-as-Policies
- REAL framework
- DriveLLM
- LLM-PID
한계:
- 실시간성
- 신뢰성
- 안정성 보장 부족
1.2 Contribution
본 논문의 기여는 다음과 같다.
- LLM 출력 변동성 감소를 위한 RB 초기 프롬프트
- LQR + RB-LLM 하이브리드 제어 구조
- 안전한 API 추상화 계층
- 비상 상황 자율 판단
- MPC, REAL, Naive LLM 대비 성능 비교
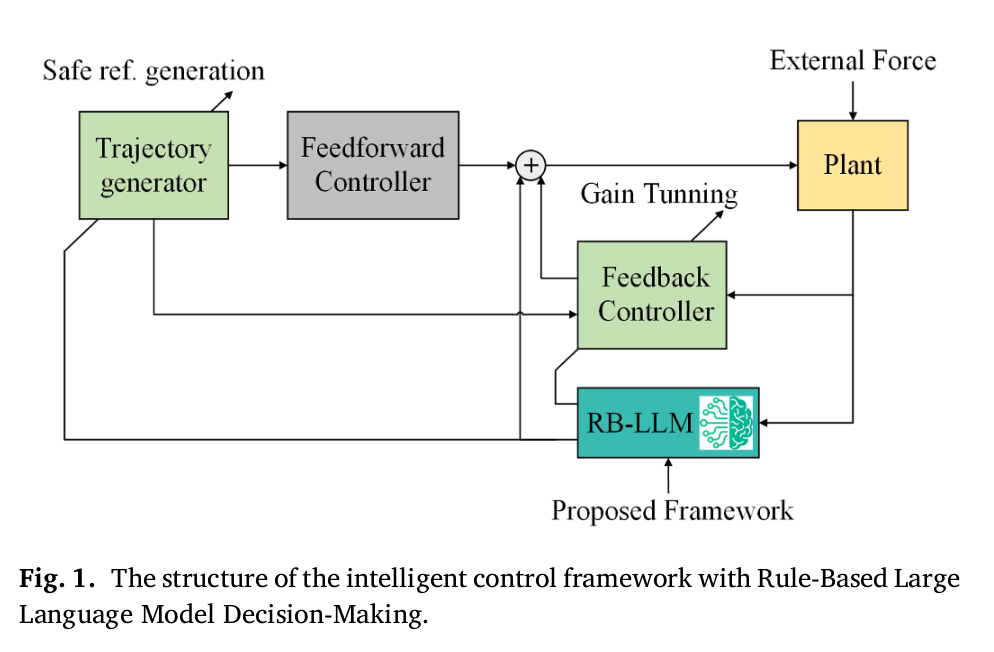
2 Methodology (Detailed Explanation)
본 절에서는 제안된 RB-LLM 제어 프레임워크의 수학적 기반과
아키텍처 구성 요소를 상세히 설명한다.
핵심 목표는 전통 제어 이론의 안정성 보장과
LLM 기반 고수준 의사결정의 적응성을
하나의 제어 구조 안에서 결합하는 것이다.
2.1 Overall Control Architecture
본 논문에서 고려하는 제어 대상은 일반적인 비선형 동역학 시스템이며,
다음과 같이 정의된다.
여기서,
- 은 시스템 상태 벡터
- 은 제어 입력
- 는 비선형 동역학 함수이다.
UAV와 같은 실제 시스템은 강한 비선형성과
외란, 파라미터 불확실성을 포함하므로,
직접적인 비선형 제어 설계는 복잡하고 계산 비용이 크다.
따라서 본 연구에서는 기본 안정성은 선형 제어기로 확보하고,
비선형성 및 불확실성에 대한 보정은
RB-LLM 계층이 담당하도록 역할을 분리한다.
2.1.1 Linearization and Discretization
제어기 설계를 위해 시스템은
기준 작동점 주변에서 선형화된다.
여기서,
실시간 디지털 제어 구현을 위해,
연속 시스템은 샘플링 주기 에 대해
이산화되어 다음과 같이 표현된다.
이때,
- 는 이산 상태 전이 행렬
- 는 이산 입력 행렬이다.
2.1.2 Feedforward–Feedback Control Decomposition
제어 입력은 참조 궤적 추종 성능을 높이기 위해
다음과 같이 분해된다.
Feedforward Control Term
Feedforward 항은
이상적인 모델 조건에서
다음 시점의 참조 상태를 정확히 달성하기 위한 입력이다.
이 항은 오차가 0일 때
시스템이 참조 궤적을 따라가도록 보장한다.
Feedback Control Term
실제 시스템에서는 외란과 모델 불일치로 인해
오차가 필연적으로 발생한다.
이를 보정하기 위해 피드백 항을 추가한다.
여기서,
- 는 이산 LQR을 통해 계산된 최적 이득
- 는 상태 오차
- 는 RB-LLM이 생성하는 적응 보정 항이다.
중요한 점은,
LLM이 제어의 주체가 아니라 보조(adaptation) 역할만 수행한다는 것이다.
기본 안정성은 항상 LQR에 의해 보장된다.
2.1.3 Role of LQR in the Hybrid Architecture
LQR은 다음 비용 함수를 최소화하도록 설계된다.
- : 상태 오차 가중치
- : 제어 입력 가중치
이 구조는 다음 장점을 가진다.
- 폐루프 안정성 보장
- 계산 효율성
- 제어 입력의 연속성
RB-LLM은 이 LQR 구조를 유지한 채,
, , 또는 에
작고 제한된 수정만 가한다.
2.2 RB-LLM as an Adaptation Layer
RB-LLM은 제어 루프의 상위 계층에서
다음과 같은 정보를 입력으로 받는다.
- 위치 및 속도 오차
- 오차 변화 추세(trend)
- 최근 제어 이력
- 실패 지속 시간
- 현재 제어기 파라미터(Q, R)
이 정보는 자연어 + 구조화된 수치 정보 형태로
LLM에 전달된다.
2.2.1 Motivation for Rule-Based Prompting
기존 LLM 기반 제어의 핵심 문제는 다음과 같다.
- 동일 입력에도 출력이 달라지는 비결정성
- 과도한 제어 입력 제안
- 안정성 고려 부족
이를 해결하기 위해,
본 논문은 Rule-Based Prompting을 도입한다.
즉,
LLM은 자유롭게 행동하지 않으며,
사전에 정의된 규칙 집합 안에서만 판단한다.
2.2.2 Structure of Rule-Based LLM
RB-LLM은 IF–THEN 구조의 규칙을 사용한다.
예시:
-
IF large_positive_position_error_x
THEN accel_positive_x -
IF failure persists for N steps
THEN emergency_landing
이 규칙들은 다음 특징을 가진다.
- 전문가 지식 기반 초기 설계
- 로그 분석을 통한 점진적 확장 가능
- 보수적(conservative) 의사결정 유도
2.3 API Abstraction Layer
LLM이 직접 제어 입력을 생성하는 것은
안정성 측면에서 매우 위험하다.
따라서 본 논문에서는 API 추상화 계층을 도입한다.
LLM은 오직 다음 API만 호출할 수 있다.
-
Control Input Modulation API
- thrust 증가/감소
- roll/pitch 미세 보정
-
Controller Tuning API
- , 행렬 스케일 조정
-
Emergency Response API
- hover
- emergency landing
각 API는
- 크기 제한
- 적용 빈도 제한
- 점진적(incremental) 적용
을 가진다.
2.3.1 Mapping from API to Control Action
예를 들어,
추력 증가 명령은 다음과 같이 매핑된다.
자세 보정 명령은
roll 또는 pitch 기준각에
작은 오프셋을 추가하는 방식으로 적용된다.
이러한 매핑은
- 해석 가능성
- 안전성
- 되돌림 가능성
을 보장한다.
2.4 Summary of Methodology
제안된 RB-LLM 제어 구조의 핵심은 다음과 같다.
- 안정성은 항상 전통 제어(LQR)가 보장
- LLM은 제한된 규칙과 API 안에서만 동작
- 적응은 점진적이고 해석 가능
- 비상 상황은 명시적 규칙으로 처리
이로써,
LLM의 장점인 고수준 판단 능력을 활용하면서도
제어 시스템의 신뢰성과 안전성을 유지한다.
3 Evaluation (Detailed Explanation)
본 절에서는 제안한 RB-LLM 제어 프레임워크를
멀티로터 UAV(quadrotor/multirotor) 시뮬레이션 환경에서 구현하여,
(1) 모델 불확실성(질량/페이로드 변화),
(2) 외란(고주파 진동/풍 등),
(3) 비상 상황(안전 종료/착륙)
에서의 추종 성능과 안정성, 계산 효율성을 정량·정성적으로 평가한다.
3.1 Dynamic Model of the Micro Aerial Vehicle (MAV)
이 논문은 UAV 모델을 “물리(physical) 동역학 + 자세(Attitude) 내부루프 모델”의
2계층으로 구성한다. 이유는 다음과 같다.
- 상위(outer-loop) 위치 제어기는 실제로 roll/pitch/thrust 명령을 생성한다.
- 하지만 실제 UAV에는 고속 내부 자세 제어기가 존재하며,
상위 제어기는 내부루프의 폐루프 응답 특성을 고려해야 한다. - 따라서 “물리 모델(추력/토크/항력)”과 “자세 응답(1차 시스템 근사)”를 함께 둔다.
3.1.1 Physical Model (Translational + Rotational Dynamics)
(1) 좌표계 정의
- 관성 좌표계(Inertial frame) I: 세계 좌표
- 동체 좌표계(Body frame) B: UAV 중심(CoM)에 붙은 좌표계
- 위치 , 속도
- 자세는 회전행렬 로 표현
- 각속도는
(2) 각 로터(프로펠러)의 추력 모델
각 로터의 추력은 회전 속도 제곱에 비례한다고 가정한다.
- : i번째 로터 회전 속도
- : 추력 계수(양수)
- : body frame의 z축 단위벡터(추력이 z방향으로 작용)
이 식은 멀티로터 모델에서 가장 널리 쓰이는 “quadratic thrust model”이다.
즉, 로터 RPM이 커질수록 추력이 비선형적으로 증가한다.
(3) 로터 토크(드래그 토크) 모델
로터는 추력뿐 아니라 공력 드래그로 인한 토크를 만든다.
특히 로터 회전 방향이 번갈아가며 배치되므로
토크 방향도 번갈아 바뀐다.
- : 토크 계수
- : 로터 회전 방향 교번(시계/반시계) 효과
이 항은 주로 yaw 제어 및 회전 동역학에 영향을 준다.
(4) 항력(Blade flapping + Induced drag) 효과
고속/급기동 시 blade flapping 및 induced drag가 발생하여
x-y 평면에서 damping 성분을 만든다.
논문은 이를 단일 드래그 계수 로 “lumped”하여 다음과 같이 모델링한다.
- : 추력의 z성분(스칼라)
- : 관성계 속도를 body frame으로 변환한 값
해석적으로는,
- 속도가 증가할수록,
- x-y 방향으로 속도에 비례하는 감쇠력이 커지고,
- z방향 감쇠는 모델에서 제외(0)한다는 뜻이다.
(5) 전체 병진/회전 동역학
최종적으로 UAV의 물리 동역학은 아래와 같이 표현된다.
여기서,
- : UAV 질량
- : 외란(풍, 케이블 진동 등)
- : 중력항(는 중력가속도)
이 식의 핵심은,
- “추력의 합”이 자세()에 의해 관성계 힘으로 변환되어
x-y-z 방향 가속도를 만든다는 점이다. - 따라서 위치 추종 성능은 roll/pitch/thrust 명령과 강하게 결합된다.
3.1.2 Attitude Control Dynamics (Inner-loop Approximation)
실제 UAV는 roll/pitch/yaw를 제어하는 내부루프가 매우 빠르게 동작한다.
상위 제어기는 내부루프를 “블랙박스”로 두거나,
시스템 식별(system identification)로 근사할 수 있다.
논문은 내부루프 응답을 1차 시스템으로 근사한다.
- : 실제 자세(roll, pitch, yaw)
- : 명령값
- : 이득
- : 시정수(시간상수)
의미:
- 상위 제어기에서 명령한 roll/pitch가 즉시 적용되지 않고,
1차 지연을 가지고 따라간다는 것을 반영한다. - yaw는 위치에 직접 영향이 작다고 가정하여 단순화한다(논문 설명).
3.1.3 Linearized Model for Control Design
제어기(LQR) 설계를 위해,
논문은 hover 근처(작은 각도, yaw=0 근처)에서 선형화한다.
- 상태벡터:
- 입력벡터:
또한 yaw에 의한 결합을 줄이기 위해
관성계 roll/pitch 를 사용하며,
body와 inertial의 관계를 회전행렬로 표현한다.
이 과정을 통해 Section 2에서 제시한
이산 선형 시스템() 형태로 내려오며,
기본 피드백은 LQR이 담당한다.
3.2 Implementation & Simulation Setup
3.2.1 Simulation Environment
- Python 기반 시뮬레이터에서 multirotor 모델을 구현
- LQR 기반 기본 제어 + RB-LLM 적응항 결합
- LLM은 외부 API(논문에서는 GPT-4 API)를 통해 질의
3.2.2 Decision-Making Interval (LLM Query Rate)
논문은 LLM을 매 시간스텝마다 호출하지 않고,
0.5초 간격으로 호출한다.
- Decision-making LLM interval: 0.5 s
이는 다음 trade-off 때문이다.
- 너무 잦은 호출: 네트워크 지연/비용 증가, 실시간성 악화
- 너무 느린 호출: 적응 반응이 늦어져 외란 대응 성능 저하
3.2.3 Table 1 (Simulation Parameters) — 설명
📌 Table 1 위치
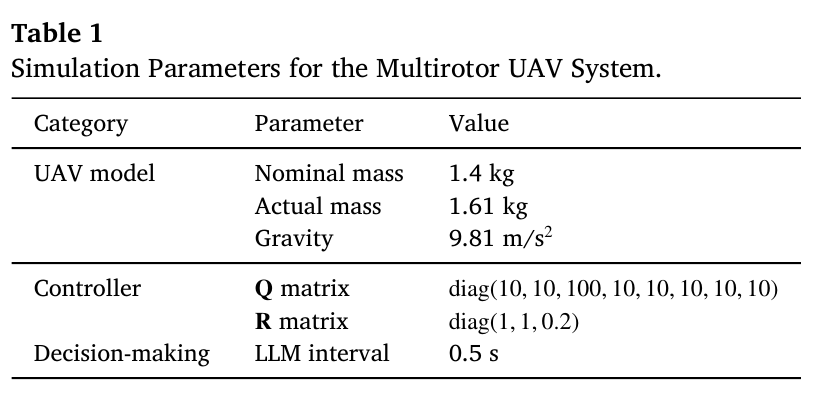
Table 1은 “실험 조건을 재현 가능하게 만드는 핵심 설정”이다.
특히 논문은 “명목 질량(nominal mass)”과 “실제 질량(actual mass)”를 다르게 두어
모델 불일치(parametric uncertainty)를 의도적으로 만든다.
- Nominal mass: 1.4 kg
- Actual mass: 1.61 kg (약 15% 오차)
- Gravity: 9.81 m/s^2
- LQR Q: diag(10,10,100,10,10,10,10,10)
- LQR R: diag(1,1,0.2)
- LLM interval: 0.5 s
해석:
- z축(고도) 오차에 큰 가중치를 둠(Q의 100 항목)
- thrust 입력은 상대적으로 작은 비용(0.2) → 고도 추종에 적극적일 가능성
3.3 Simulation Scenarios & Results (Fig.2–Fig.9 상세 설명)
논문은 “단일 시나리오에서 잘 된다”가 아니라,
다음처럼 난이도를 단계적으로 올리며 평가한다.
- (A) 질량 오차 15% + figure-eight 궤적
- (B) payload 증가(0.21 kg)로 모델 mismatch 강화
- (C) 질량 변화 + 고주파 외란 + 비상 착륙 판단
각 그림이 의미하는 바를 아래에 정리한다.
📌 Fig.2 — RB-LLM 활성화: Figure-eight 궤적 추종(질량 15% 오차)
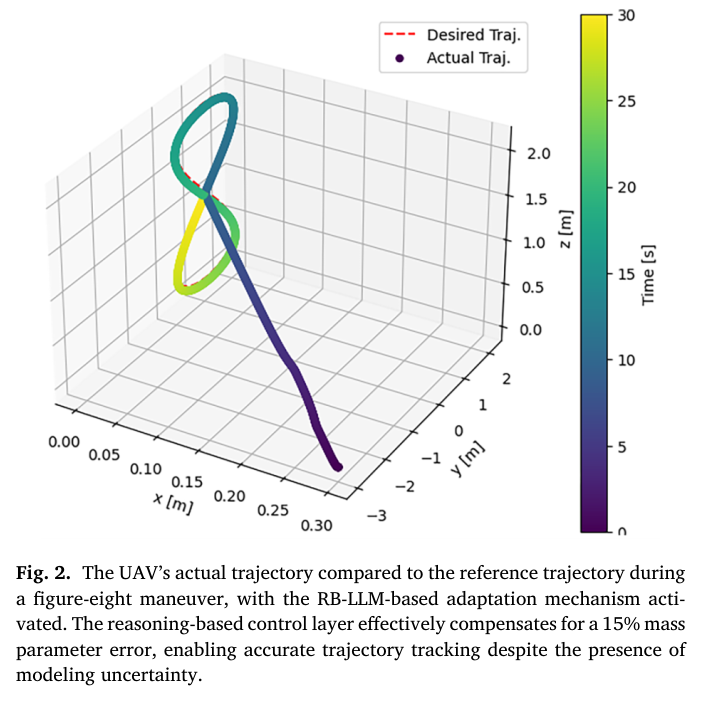
Fig.2는 RB-LLM 적응 계층이 켜진 상태에서,
UAV의 실제 궤적이 참조 figure-eight 궤적과 거의 겹치도록 추종됨을 보여준다.
핵심 포인트:
- 컨트롤러는 nominal mass(1.4kg)로 설계됨
- 실제 UAV는 1.61kg → 같은 입력이면 가속도가 작아져 오차 증가가 예상됨
- RB-LLM이 API를 통해 thrust/자세 또는 튜닝을 수행하여 이를 보정
즉, Fig.2는 “모델 불일치가 있어도 적응으로 경로를 유지한다”는 1차 증거다.
📌 Fig.3 — x,y,z 위치 추종 곡선(참조 vs 실제)
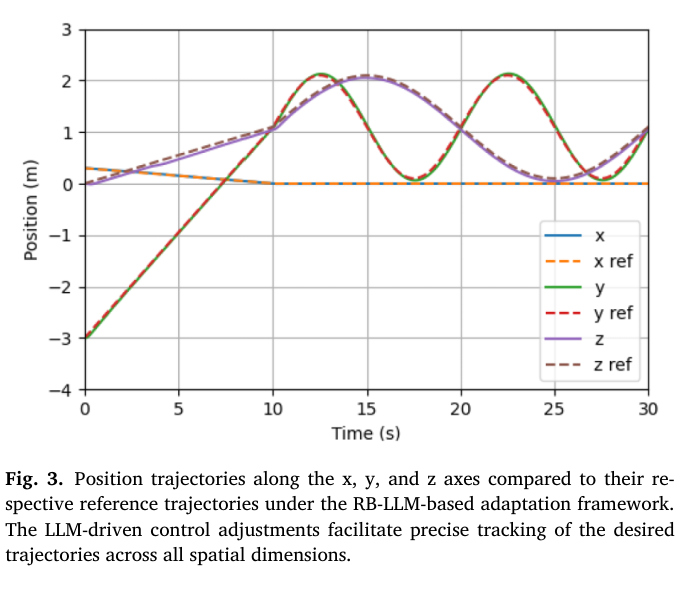
Fig.3는 각 축별로 “참조 궤적 vs 실제 궤적”을 시간에 따라 비교한다.
논문이 주장하는 핵심은:
- RB-LLM이 켜진 경우 오차가 좁은 범위 내에서 유지
- 최대 편차(max deviation)가 모든 축에서 0.082m를 넘지 않음
해석:
- 단순히 2D 경로만 맞춘 것이 아니라,
z축(고도)까지 안정적으로 추종한다는 점이 중요하다. - 고도 제어는 thrust와 직결되며,
질량 오차가 있을 때 가장 먼저 무너질 수 있는 축이기도 하다.
📌 Fig.4 — RB-LLM 비활성화(기본 LQR만): 성능 저하
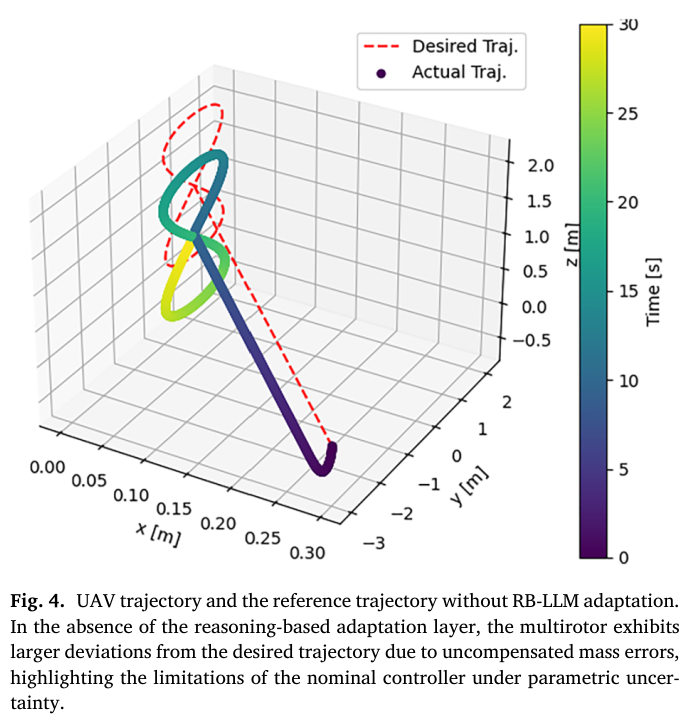
Fig.4는 동일한 조건(질량 오차)에서
RB-LLM 적응을 끈 경우의 결과를 보여준다.
관찰:
- 궤적이 참조에서 크게 벗어남
- 모델 오차가 실시간으로 보정되지 않기 때문에 편차가 누적
Fig.2와 Fig.4의 대비는,
RB-LLM이 “추가되었을 때만” 성능이 유지된다는 비교 근거를 제공한다.
📌 Fig.5 — payload 증가(0.21kg)에서도 3D 궤적 추종 유지
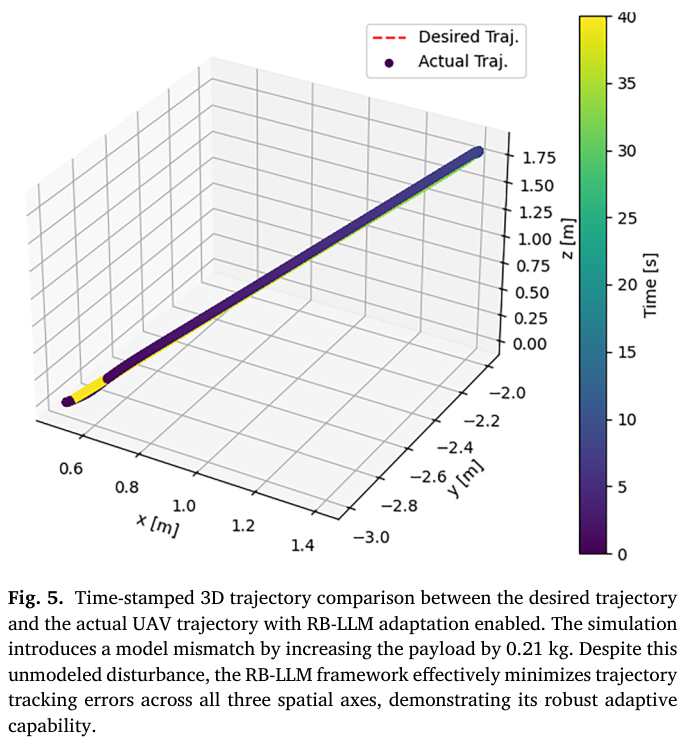
Fig.5는 모델 mismatch를 더 현실적으로 만들기 위해
payload를 0.21kg 증가시킨 경우를 보여준다.
핵심:
- 3D 경로가 시간에 따라 색상으로 표시(time-stamped)
- mismatch에도 불구하고 참조와 실제 궤적이 매우 가깝게 유지됨
해석:
- RB-LLM이 단순한 “한 번의 튜닝”이 아니라,
지속적으로 오류 경향을 감지하고 작은 수정들을 반복 적용한다는 증거다.
📌 Fig.6 — 축별 추종 오차가 빠르게 0 근처로 수렴
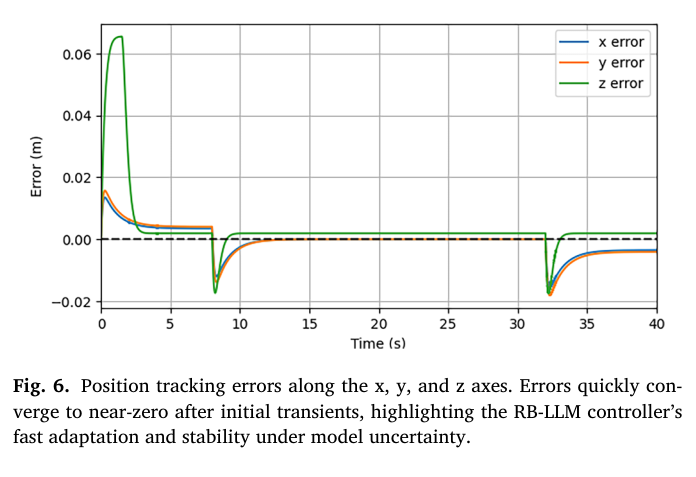
Fig.6는 x,y,z 오차의 시간 응답을 보여준다.
논문 요지:
- 초기 transient 이후 오차가 빠르게 ±0.02m 내로 수렴
- 큰 진동 없이 매끈하게 안정화됨
해석:
- LLM 기반 적응이 과도하게 동작하면 오히려 진동을 유발할 수 있는데,
Rule-Based Prompting + API 제한이
“안정적인 적응”을 만들었다는 정성적 근거가 된다.
📌 Fig.7 — payload mismatch + RB-LLM 없음: 큰 이탈
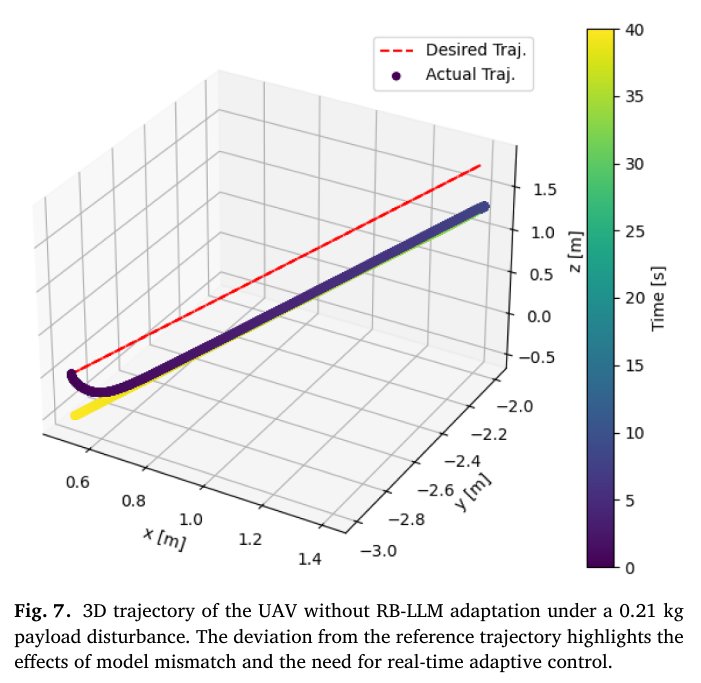
Fig.7은 Fig.5/6과 동일한 payload mismatch 조건에서
적응 없이 수행했을 때 결과다.
관찰:
- 전이 구간에서 특히 큰 편차 발생
- 모델 mismatch가 큰 상황에서는 nominal LQR만으로 회복 불가
즉, Fig.7은 “실제 운용에서 mismatch가 생기면 LQR만으로 부족”함을 강조한다.
📌 Fig.8 — 질량 변화 + 고주파 외란: RB-LLM이 emergency landing 수행
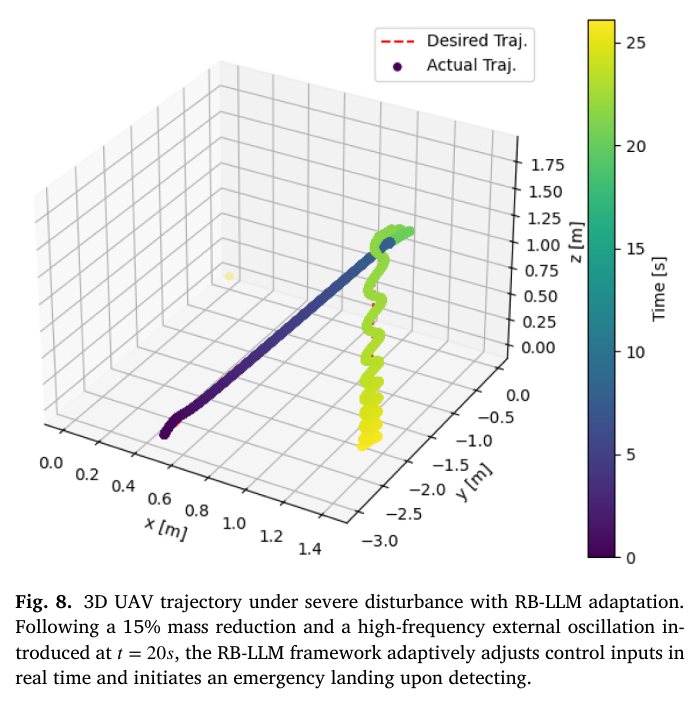
Fig.8은 가장 중요한 “미션-크리티컬” 시나리오다.
조건:
- 질량 15% 감소(모델 파라미터 급변)
- t = 20s에서 고주파 외란(진동/풍)을 추가
결과:
- 초기에는 참조 궤적을 잘 추종
- 외란이 시작되면 RB-LLM이 불안정(oscillation)을 감지
- “emergency landing” API를 호출해 미션 중단 + 안전 착륙
해석:
- 여기서 목표는 “끝까지 추종”이 아니라,
안전이 깨지는 조건에서 “자율적으로 abort하는 것” - 제어 프레임워크가 ‘안전 의사결정’을 포함한다는 점을 입증한다.
📌 Fig.9 — 동일 외란 조건 + RB-LLM 없음: 안정성 붕괴
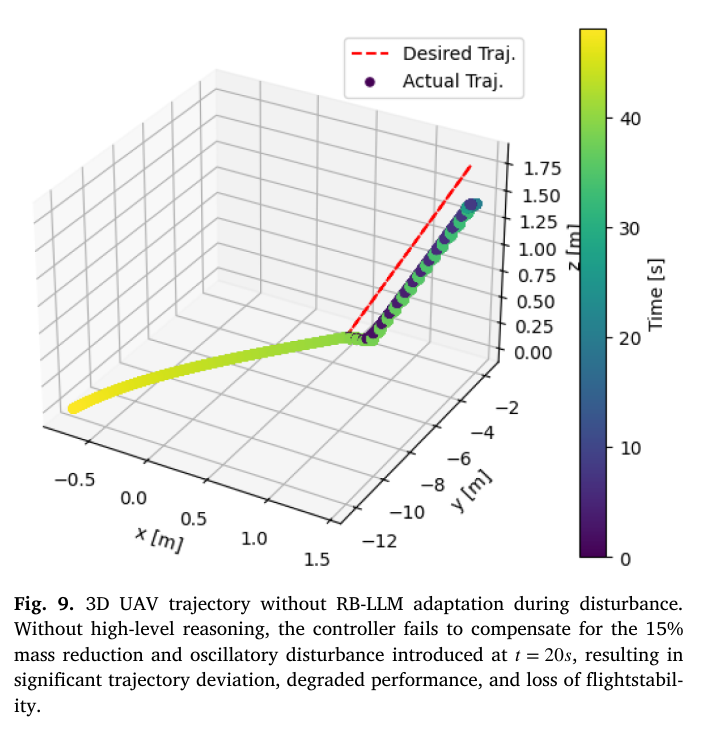
Fig.9는 Fig.8의 조건에서 적응이 없는 경우다.
관찰:
- 궤적이 크게 무너지고,
- 비상 대응이 없으므로 안정성이 지속적으로 악화
결론:
- RB-LLM이 단지 성능 향상이 아니라,
안전/회복성(resilience) 측면에서 역할이 있음을 보여준다.
Table 2 (Markdown)
| Method | Max Error (m) | RMSE (m) | Avg Time (ms) |
|---|---|---|---|
| LQR | 0.7573 | 0.4201 | 0 |
| MPC | 0.3389 | 0.1918 | 131.4 |
| REAL | 0.1229 | 0.0584 | 18.3 |
| Naive LLM | 0.137 | 0.0651 | 12.5 |
| RB-LLM | 0.0776 | 0.0365 | 14.2 |
(1) 성능 지표 의미
- Max error: worst-case 안전/추종 품질(최악 순간의 오차)
- RMSE: 전체 시간 평균 추종 정확도(일반적 품질)
- Avg time: 실시간 가능성을 좌우(계산 지연)
(2) 핵심 관찰
- LQR은 계산은 빠르지만(0ms), 오차가 매우 큼 → mismatch에 취약
- MPC는 오차는 줄이지만 131ms로 매우 느림 → 실시간성 부담
- REAL과 Naïve LLM은 중간 지점
- RB-LLM은 Max error, RMSE 모두 최저이며 시간도 14.2ms 수준
(3) 논문 주장(정량적 결론)
논문은 RB-LLM이 기존 대비
- Max error 36%~89% 감소
- RMSE 37%~91% 감소
를 달성한다고 보고한다.
Table 3 (Markdown)
| Feature | LQR | MPC | REAL | Naive LLM | RB-LLM |
|---|---|---|---|---|---|
| Robustness | × | × | ◦ | ◦ | ● |
| Reasoning | × | × | ◦ | ◦ | ● |
| Emergency | × | × | ◦ | ◦ | ● |
| Stability | ● | ● | ◦ | × | ● |
| Real-time | ● | ◦ | ● | ● | ● |
- Robust to uncertainty: 모델 mismatch에 강한가?
- Adaptation via reasoning: 상태/로그 기반 추론 적응이 가능한가?
- Emergency handling: 비상 절차가 있는가?
- Controller tuning: Q/R 등 튜닝을 온라인으로 하는가?
- Stability guarantees: 안정성 보장이 있는가?
- Real-time feasibility: 실시간 운용이 가능한가?
RB-LLM은 거의 모든 항목에서 fully supported(●)이며,
특히 “추론 기반 적응 + 안정성 보장”을 동시에 만족하는 점이 강조된다.
- Limitations and Future Work (Detailed)
논문은 RB-LLM의 성능에도 불구하고 명확한 한계를 인정한다.
4.1 LLM Latency & Low-Frequency Decision Making
- LLM 질의는 오프보드(offboard)로 수행
- 일반적으로 0.1~1 Hz 수준만 가능
→ 고대역(bandwidth) 제어에는 부적합
4.2 Network Dependence
- 인터넷 기반 통신은 지연/패킷 손실/서비스 불가 등의 위험
→ 미션 신뢰성에 취약점
4.3 Limited Evaluation Scope
- 단일 UAV, 단일 에이전트, 제한된 시나리오
→ 다중 에이전트/장기 미션/복잡 환경 확장 필요
4.4 Future Work Directions
- 온보드 LLM(경량화 모델) 탑재로 지연 감소
- hybrid: onboard reasoning + cloud augmentation
- multi-agent 협력/분산 의사결정 확장
- 더 다양한 외란/센서 노이즈/실세계 실험으로 검증
- Conclusions (Detailed)
본 논문은 RB-LLM 기반 지능형 제어 프레임워크를 제안하고,
UAV 시뮬레이션을 통해 다음을 입증한다.
1) 안정성: 기본 제어(LQR)가 유지되어 안정성 기반을 제공
2) 적응성: RB-LLM이 제한된 API와 규칙으로
모델 mismatch 및 외란에 대응
3) 안전성: 불안정 조건에서 emergency landing을 자율 결정
정량적으로,
RB-LLM은 Max error와 RMSE에서 가장 우수한 결과를 보이며,
MPC 대비 계산 비용이 매우 낮아
실시간 적용 가능성 측면에서도 의미가 있다.
결론적으로,
RB-LLM은 “LLM을 제어기로 대체”하는 접근이 아니라,
전통 제어의 안정성 위에 LLM 기반 고수준 의사결정(적응/안전)을 얹는 방식으로
LLM의 장점을 안전하게 통합하는 하나의 실용적 설계 패턴을 제시한다.