리뷰할 논문은 2019년 ICLR에 게재된 IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE입니다.
Introduction
기본적으로 2014년에 나온 Visualizing and Understanding Convolutional Networks논문에서 CNN은 input layer와 가까운 층은 작은 영역의 특징(Low level feature)을 탐색하고 ouput layer와 가까운 층은 작은 영역들을 모은 더 상위의 복잡한 특징(shape)들을 보는 것으로 얘기합니다. 이 가설을 shape hypothesis라고 합니다.
이 실험적 결과들은 다른 논문에서도 나왔고 암시적으로 CNN이 인간이 모양을 보고 물체를 인식하는 것처럼(인지과학논문에서 밝혀진 사실) 모양을 본다라고 주장합니다.
반면 이 실험적 결과와는 다른 주장의 내용도 존재합니다. 모양은 존재하지만 질감이 없는 스케치를 구분 못하는 것, 형태가 파괴되서 다른 것으로 바뀌어도 잘 분류하는 두 경우가 있습니다. 그리고 CNN 계층 마지막에 있는 linear layer는 성능에 크게 영향을 미치지 않는 점과 Patch를 쪼개 receptive field를 쪼개면서 실험(Bag-Net)해도 성능에 큰 영향이 없는 것 를 실험적으로 발견했고 이를 통해 shape보다는 texture가 더 큰 영향이 있을 것이라 생각할 수 있습니다. 이 가설은 texture hypothesis라고 합니다.
 실제로 고양이에 코끼리의 질감을 씌우면 사람은 고양이로 분류하는 반면 CNN 모델은 코끼리로 판단합니다.
실제로 고양이에 코끼리의 질감을 씌우면 사람은 고양이로 분류하는 반면 CNN 모델은 코끼리로 판단합니다.
이 논문에서는 충돌하는 두 가정에 대해 비교적 간단한 실험을 통해 밝혀내고자 하며 texture bias를 shape bias로 바꾸는 방법을 보여줍니다.(shape bias가 높으면 여러 왜곡에 대해 robust한 특징을 가집니다)
Method
Experiments
실험 세팅은 논문을 다 자세히 쓸 수 없으니 간단하게 얘기하고 넘어가겠습니다.
- 97명의 참가자로부터 48560번 실험
- AlextNet, GoogLeNet, VGG-16, ResNet-50 사용
original에 사람이 도대체 왜 고양이를 틀렸는지 이해가 안 갔는데 논문의 실험을 자세히 보면 알 수 있습니다. 참가자가 정답을 고르는 방법은 아래와 같습니다.
1. 300ms 아무것도 없는 사각형 제시
2. 200ms 맞춰야할 이미지 제시
3. 200ms pink noise 제시 (CNN과 비교를 가능한 공정하게 하기 위해서라고 합니다)
4. 1500ms 동안 4 x 4 grid image에 나오는 정답 선택
가장 위의 그림을 보면 코끼리 질감으로 덧 씌운 고양이 대한 정답은 두개로 볼 수 있는데 단일 클래스를 선택하도록 했고 온전히 참가자의 주관적 해석에 맡겼다고 합니다.
Stylized-ImageNet
ImageNet의 sytle을 바꾸는 코드는github repo에 있습니다.
Result
Texture vs Shape bias in Human and ImageNet-trained CNN
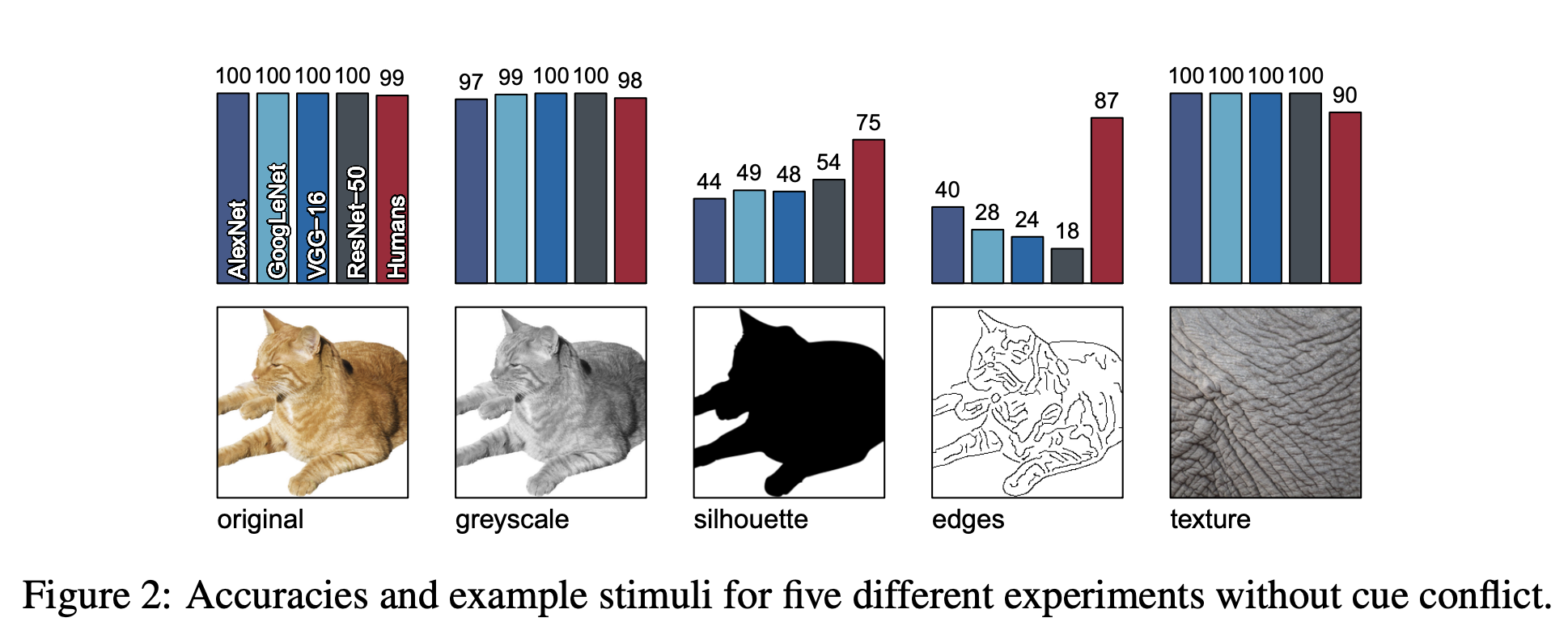 위의 실험결과를 보면 인간이 실루엣이나 윤곽선(edge)에 대해 더 잘 맞추는 경향이 있습니다.
위의 실험결과를 보면 인간이 실루엣이나 윤곽선(edge)에 대해 더 잘 맞추는 경향이 있습니다.
여기서 CNN이 이미지 통계의 큰 변화(domain shift)에 잘 대응하지 못하는 것을 발견했습니다. 그래서 cue conflict 방법으로 이미지 변환을 하여 실험을 진행했습니다.(아래 두줄의 이미지와 같은 방법)

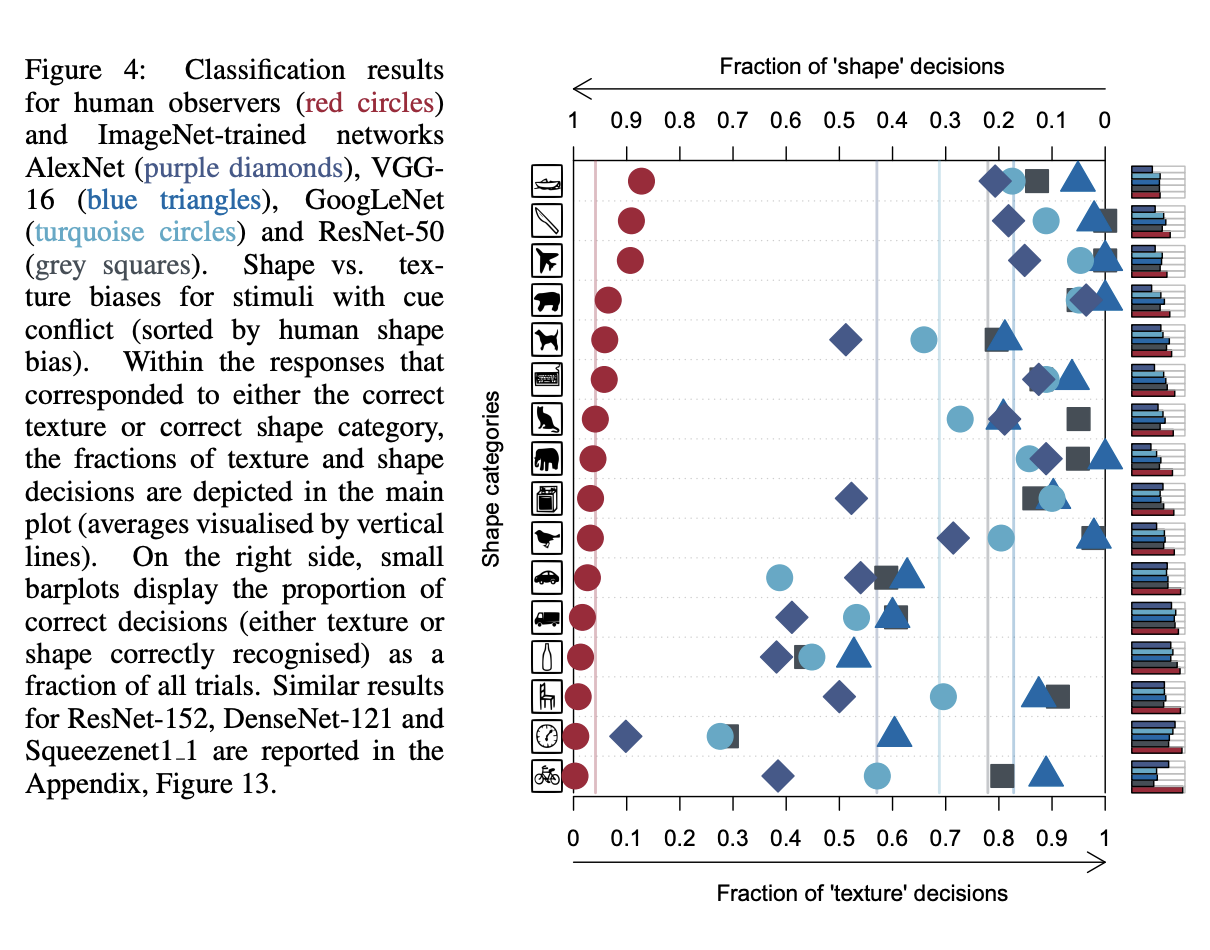 이미지와 texture를 합쳐 texture의 label로 판단하면 texture decisions로 shape의 label로 판단하면 shape decisions로 점수를 매겼습니다. 인간은 모양에 집중하는 반면 CNN계열은 질감에 초점을 두고 판단함을 알 수 있습니다.
이미지와 texture를 합쳐 texture의 label로 판단하면 texture decisions로 shape의 label로 판단하면 shape decisions로 점수를 매겼습니다. 인간은 모양에 집중하는 반면 CNN계열은 질감에 초점을 두고 판단함을 알 수 있습니다.
Overcoming The Texture bias of CNN
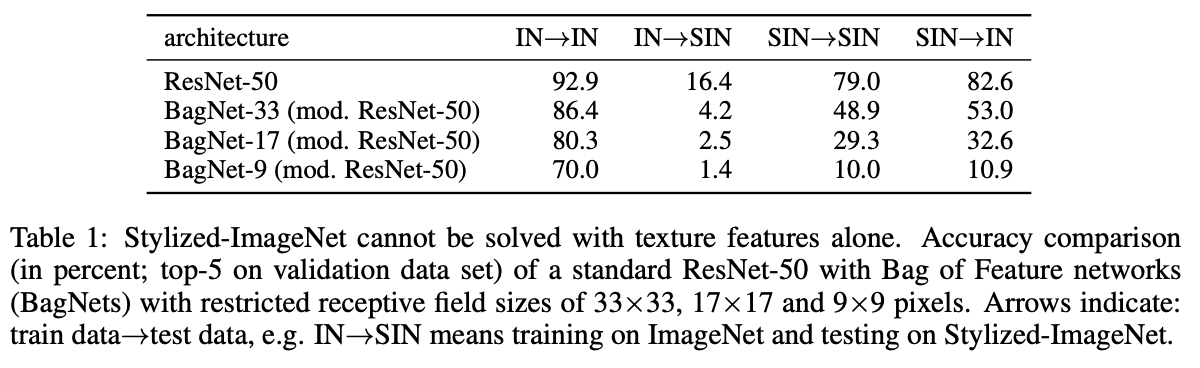
Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet
(Bag-Net)논문에서 CNN은 local 정보만으로 물체를 잘 파악할 수 있음을 알았습니다. 그래서 저자는 SIN(Stylized ImageNet)데이터 셋을 이용해 훈련시켜 IN과 SIN 데이터셋의 평가를 시도했습니다.
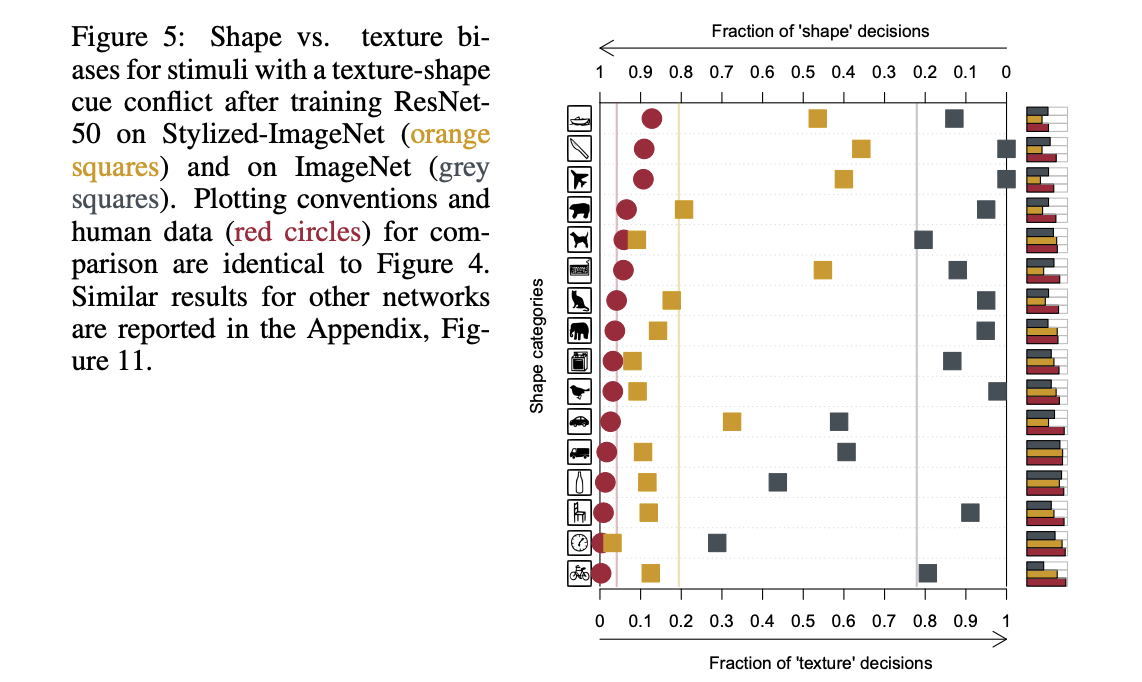
 SIN 데이터셋을 통해 학습한 모델의 shape bias이 늘어난 것을 아래 그림을 통해 확인 할 수 있습니다.
SIN 데이터셋을 통해 학습한 모델의 shape bias이 늘어난 것을 아래 그림을 통해 확인 할 수 있습니다.
Robustness And Accuracy of Shape-based Representations
이 부분의 내용은 아래 그림을 보는 것으로 충분히 이해가 됩니다.
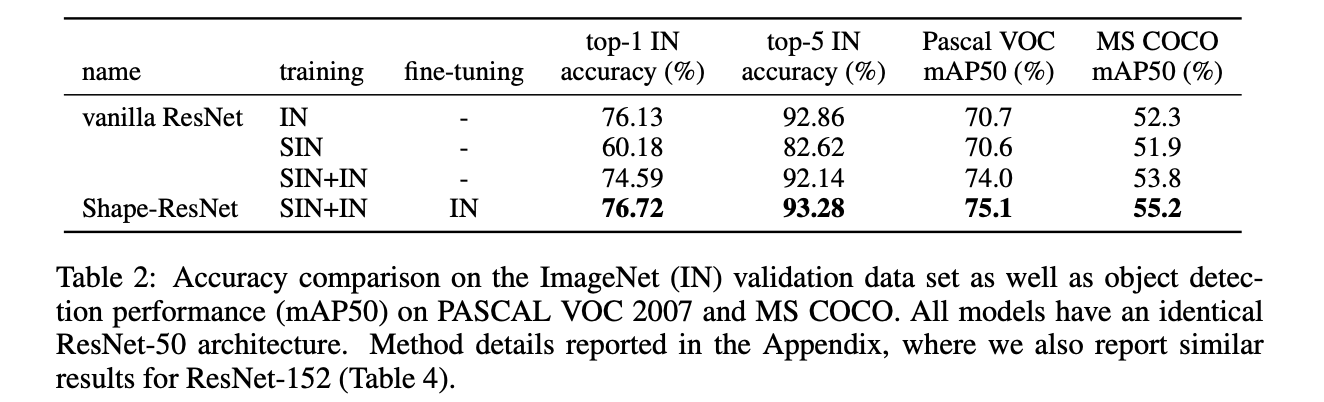
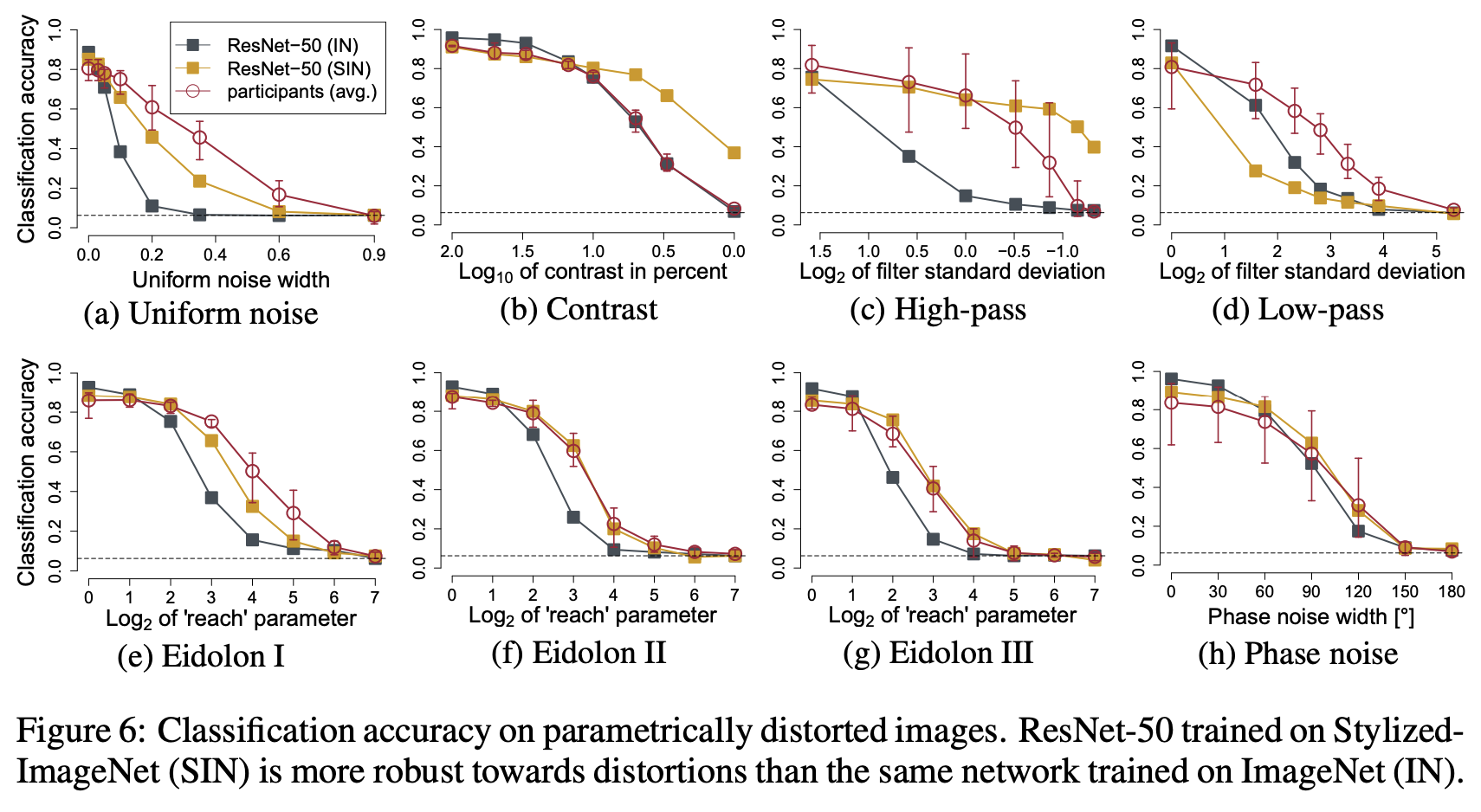 전체적으로 robustness가 좋다고 할 순 없지만 평균적으로 shape bias를 가지는 모델이 더 좋은 일반화 성능을 보입니다.
전체적으로 robustness가 좋다고 할 순 없지만 평균적으로 shape bias를 가지는 모델이 더 좋은 일반화 성능을 보입니다.
Discussion & Conculsion
- 인간과 달리 ImageNet으로 학습된 CNN모델은 global object shape이 아닌 local texture에 초점을 맞춰 판단합니다.
- texture bias는 CNN구조의 문제가 아닌 ImageNet 데이터셋에 의한 것 입니다. ill-posed problem에서 local texture를 보고 판단하는게 shortcut이었다고 생각됩니다.(오컴의 면도날)
- shape 기반으로 판단하는 것은 local texture로 판단하는 것 보다 많은 robustness를 가집니다.
Texture Bias와 연관된 논문
- Deep Neural Networks as a Computational Model for Human Shape Sensitivity
- Cognitive Psychology for Deep Neural Networks:
A Shape Bias Case Study - Texture and art with deep neural networks
- On the Performance of GoogLeNet and AlexNet Applied to Sketches
- The Origins and Prevalence of Texture Bias in Convolutional Neural Networks
- Are Convolutional Neural Networks or Transformers more like human vision?
이미 논문리뷰를 깔끔하게 한 영상도 있었습니다.
의문점
- CNN이 texture bias를 가지도록 하는 구조인가? 아니면 전적으로 데이터 셋의 문제인가?
- 인간 인지와 비슷하게 shape bias를 따라가는게 더 좋은 방법인가?
- shape와 texture둘다 보는 방법은 없나?(Image Captioning을 보면 이미 존재할 것 같음)
