CAM-loss
Cam-loss 구현코드가 없어서 직접구현을 해봤습니다.
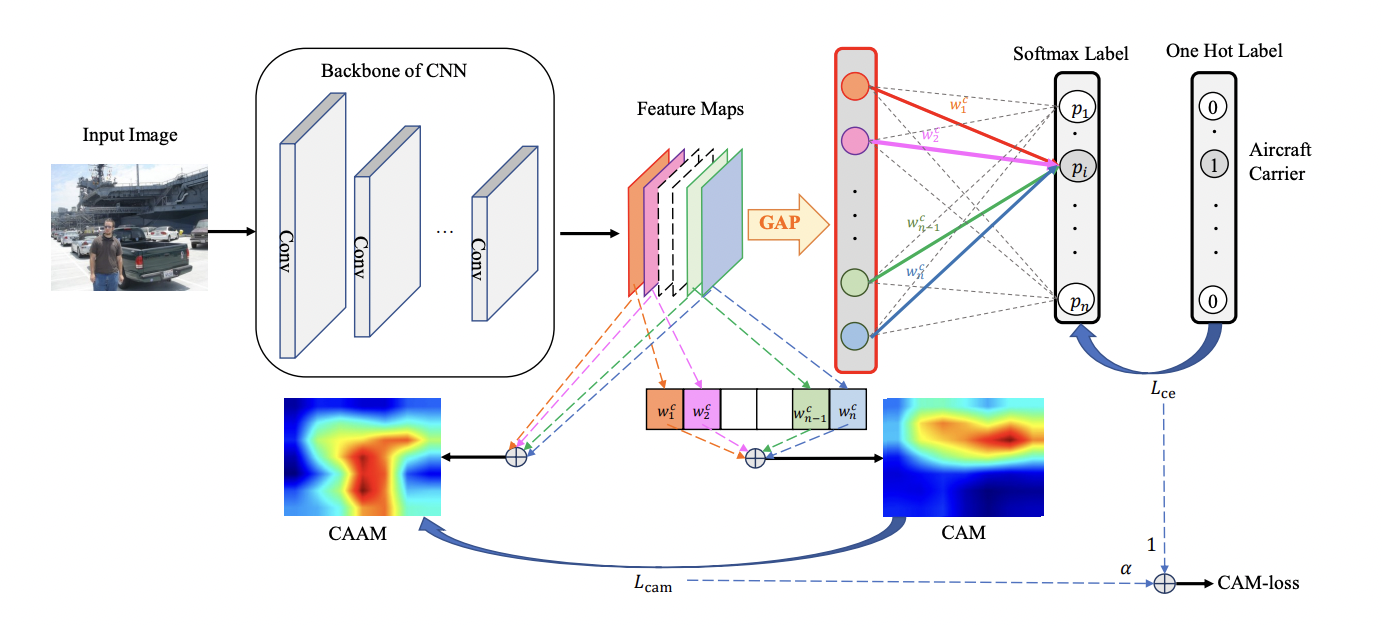
논문에 나와있는 위 그림이 전체 구조입니다.
Global Average Pooling(GAP)를 하기 전 계층의 Feature Map을 가져와 모두 더한 CAAM과 다음 계층의 가중치를 곱하고 더한 CAM의 차이(정확히는 label에 연결된 가중치)와 보통 사용하는 CrossEntropy를 가중합해서 만든 것이 CAM-loss입니다
간단하게 적용해보기 위해서 데이터 셋은 MNIST를 사용했습니다.
Model
모델은 Resnet backbone모델과 간단한 Custom모델을 사용했습니다.
class ResnetBackBone(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.feature_map = None
self.backbone = models.resnet18(weights='DEFAULT')
self.backbone.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
self.backbone.fc = nn.Linear(512, num_classes)
self.backbone.layer4.register_forward_hook(self.getFeatureMap)
def getFeatureMap(self, module, inputs, outputs):
self.feature_map = outputs
def forward(self, x):
x = self.backbone(x)
return x, self.feature_mapbackbone model을 사용하면 hook을 통해 layer에 접근하여 gap층 전의 feature map을 직접 가져와야 합니다.
class TestModel(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 256, 3, 1, 1),
)
self.gap = nn.AdaptiveMaxPool2d((1, 1))
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
feature_map = self.conv(x)
x = self.gap(feature_map)
x = torch.flatten(x, 1)
x = self.fc(x)
return x, feature_map
Train

위의 알고리즘은 CAM-loss 최적화 알고리즘입니다. 신기하게 Lce는 fc layer의 W만 업데이트하고 CAM-loss는 fc layer를 제외한 conv(or backbone lyaer)계층을 업데이트 합니다.
저렇게 분리해서 업데이트 하는 이유는 Lcam과 W간의 correlation을 제거하기 위한 목적이라고 합니다. 분리하지 않으면 두 경우 모두 W에 영향을 주어 너무 빠른 가중치 감소를 초래합니다.
아래의 코드는 Custom model을 train 하는 경우입니다.
추가적으로 alpha의 선택은 open problem이라 따로 설명은 안했지만 데이터에 따라서 달라질 수 있기 때문에 실험적으로 어떤 값이 가장 좋은지 알아내야 한다고 합니다.
model = TestModel(10).to(device)
# optim 두 개 사용
optm_theta = optim.Adam(model.conv.parameters(),lr=1e-3)
optm_w = optim.Adam(model.fc.parameters(), lr=1e-3)
l_cam = nn.L1Loss()
l_ce = nn.CrossEntropyLoss()
model.train()
EPOCHS = 20
alpha = 0
for epoch in range(1, EPOCHS+1):
loss_sum = 0
L_cam_sum = 0
L_ce_sum = 0
for batch_in, batch_out in tqdm(train_iter):
inputs = batch_in.to(device)
labels = batch_out.to(device)
y_pred, feature_map = model.forward(inputs)
if epoch >= 10:
alpha = 3
# CAAM, CAM
CAAM = torch.sum(feature_map, dim=1) # B H W
CAM = madeCAM(feature_map, labels, model.fc.weight.data.T) # B H W
CAAM_normalize = minMaxNormalize(CAAM)
CAM_noramlize = minMaxNormalize(CAM)
L_cam_loss = l_cam(CAAM_normalize, CAM_noramlize)
L_ce_loss = l_ce(y_pred, labels)
CAM_loss = alpha*L_cam_loss + L_ce_loss
optm_theta.zero_grad()
optm_w.zero_grad()
CAM_loss.backward()
optm_theta.step()
optm_w.step()
loss_sum += CAM_loss
L_cam_sum += L_cam_loss
L_ce_sum += L_ce_loss
loss_avg = loss_sum/len(train_iter)
cam_avg = L_cam_sum/len(train_iter)
ce_avg = L_ce_sum/len(train_iter)
if (epoch%2) == 0:
train_accr = func_eval(model,train_iter,device)
test_accr = func_eval(model,test_iter,device)
print (f"epoch: {epoch} CAM_loss:{loss_avg:.3f}(L_cam: {cam_avg:.3f}, L_ce: {ce_avg:.3f}) train_accr: {train_accr:.3%} test_accr:{test_accr:.3%}.")
print ("Done") backbone모델의 경우도 코드는 비슷합니다. 전체코드는 깃허브 링크에 올려놓았습니다
