Dacon대회 중 multi-label관련 sota에서 Q2L을 보고 읽게 되었습니다.
대부분 내용을 요약했고 실제 논문과 다르게 해석했을 수 있습니다.
Introduce
multi-label classification task는 보통 label imbalance와 roi(region of interests)추출 문제에 대한 벽에 부딪힙니다.
label imbalance는 보통 one-vs-all 전략에서 발생합니다. 논문에 이 전략이 자세히 나오지는 않지만 하나의 모델에서 모든 문제를 해결하려는 전략을 의미하는 것 같습니다. 현실의 데이터 레이블 개수(분류할 클래스 수)가 많아지면 많아질 수록 positive, negative의 샘플 개수의 차이가 커집니다. 이건 파레토 법칙(=long-tail=80:20법칙)을 예시로 이해하면 될 것 같습니다.
roi의 경우에는 물체들이 서로 다른 위치에 분포하고 있기 때문에 발생합니다. GAP(global average pool)을 사용하면 feature들이 희석되어 작은 개체 구분이 힘들어 집니다.
label imbalance 같은 경우는 focal loss, distribution-balanced loss, asymetric loss같은 loss function으로 해결을 할 수 있습니다. roi추출에 대한 문제에도 여러 방법을 사용하고 있지만 label imbalance를 해결하는 정도로 발달하지는 못했습니다.
논문의 저자는 DETR에서 영감을 받아 DETR과 비슷한 (DETR은 class-agnostic, Q2L은 class unique) query를 사용할 것을 제안합니다. 간단하게 구조를 말하면 백본(first stage)에는 CNN, Transformer계열 어떤 것이 와도 상관이 없고, roi를 추측하는 two stage에는 transformer decoder를 활용합니다.
세줄 요약
- 간단한 Transformer기반 two-stage 모델 제안
- Transformer에 내장된 cross-attention module 활용
- 여러 데이터셋에서 성능이 좋게 나옴
Related Work
multi label classification
이 주제는 세 가지 카테고리로 분류될 수 있습니다.
- Improving loss function
여러 방법론들이 존재하지만 논문의 저자는 focal loss에서 positvie, negative sample에 다른 을 사용하는 asymmetric loss를 사용했습니다. - Modeling label correlations
classification에서 어떤 label이 다른 label의 하위 분류일 경우 상관관계가 존재하게 됩니다. 이전에 나온 논문에서는 graph를 활용해 서로간의 category-correlated feature vetor를 배우는 방안(GCN)이 제시 되었습니다. 그러나 이 논문에는 그래프 임베딩을 사용하지 않고 데이터를 통해 네트워크(학습 가능한 레이블 임베딩)가 스스로 학습할 수 있도록 만들어 준다고 합니다. - Locating regions of interest
roi를 구할 때 이전의 방법들에는 spatial transformer layer와 LSTM결합, global-to-local discovery method, 레이블 임베딩과 feature map의 코사인 유사성을 구해 음수값 clip후 attention map도출 하는 방법이 있었습니다. 그러나 각 방법들에 단점이 있었고 논문에서는 Transformer Decoder에 내장된 cross-attention을 이용해서 필요한 feature를 추출하는 방법을 채택했습니다.
Transformer in Vision Tasks
여기는 논문을 이해하는데 크게 중요한 내용이 있지는 않습니다.
ViT와 이후에 object detection framework로 나온 DETR에 대해 설명하며 저자가 DETR에 영감을 받아 이 framework를 만들었다고 말합니다.
Method
Q2L은 multi-label을 위한 two-stage framework입니다.
Framework
전체 구조는 아래의 그림과 같습니다.
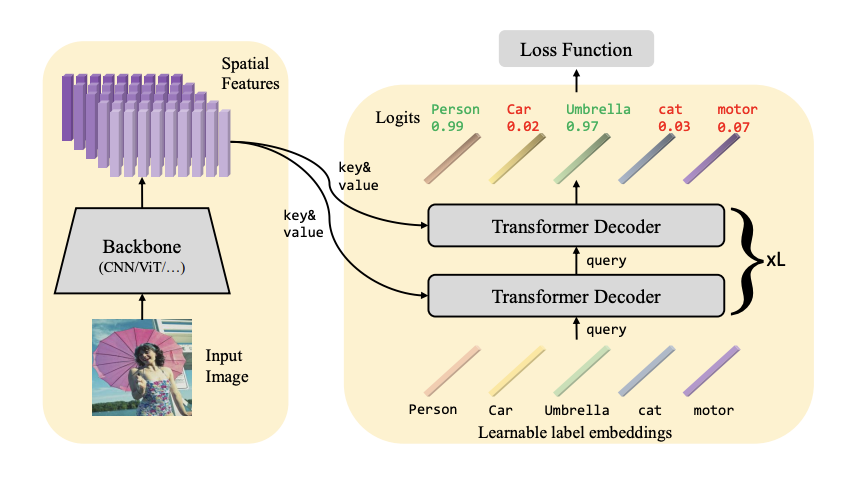
Q2L의 first stage는 backbone model을 통해 spatial features를 추출하고 second stage로 전송합니다.
second stage에는 query update, adaptive featrue pooling을 위한 multi layer Transformer decoder와 각 카테고리의 logit을 계산하기 위한 linear projection layer 두 모듈이 합쳐져 있습니다.
Feature extracting
주어진 이미지가 이고 backbone을 거쳐서 로 나옵니다. 이후 linear projection layer를 통해 로 query 차원(label 개수)과 맞춰줍니다.
Query updating
first stage에서 나온 와 query로 사용하는 label embedding 을 category-related 특성을 합치기 위해 Transformer Decoder를 통해 cross attention을 합니다.(K는 카테고리의 개수입니다)
i 번째 층의 Transformer Decoder는 이전 계층에서 나온 을 아래와 같이 업데이트합니다.
self-attention:
corss-attention:
FFN:
물결표는 position embedding을 더한것을 의미합니다.
위의 self-attention, cross-attention, FFN은 기존 Transformer Decoder에 있던 함수들이고 MultiHead안의 값은(query, key, value)를 의미합니다. Q2L에서는 auto regressive prediction을 사용하지 않으므로 attention mask도 사용하지 않습니다. 그러므로 카테고리들은 각 층에서 병렬적으로 디코딩 될 수 있습니다.
직관적으로 보면 각 label embedding , (k=1,...,K)는 spatial feature인가 어디에 집중할지, 어떤 feature에 합쳐질지 선택한다고 볼 수 있습니다. 그 이후에 각 label embedding은 더 나은 category-reloated feature을 얻을 수 있습니다. 결과적으로 label embedding 는 층마다 업데이트 되며 cross-attention을 통해 input 이미지로 부터 문맥적인 정보(semantic한 정보)가 주입됩니다.
Feature Projection
two-stage의 마지막 층에서 쿼리 벡터는 K가 카테고리 개수라고 하면 K x d차원이됩니다. multi-label classification을 수행하기 위해 각 레이블을 binary classification task로 보고 의 feature를 logit value로 아래 sigmoid 함수를 통해 사영(project)시킵니다.
는 k 카테고리에 대한 확률로 생각할 수 있습니다.
Loss Function
Transformer에 내장된 cross-attention 매커니즘 덕분에 추가적으로 새로운 loss function이 필요하지는 않습니다. BCE loss나 focal loss도 잘 동작합니다. 데이터 불균형 문제를 효과적으로 해결하기위해 논문에서는 asymmetric loss를 도입했습니다. 식은 아래와 같습니다.
논문의 실험에서 는 1이고, 는 0으로 설정했습니다.
Experiments
실험의 대부분은 생략하겠습니다.
- Transformer encoder는 global context를 표현하는데 도움을 주지만 실험에서 계산효율성을 고려해 제거했고, decoder layer만 사용했습니다.
- Q2L을 small, medium, large로 정의한 물체를 잘 잡을 수 있습니다. adaptive feature pooling을 통해 medium 크기에 대한 성능이 크게 올랐지만 작은 객체에 대한 세밀한 성능 향상은 아직 open problem으로 남아 있습니다.
아래는 multi head attention map의 시각화입니다. 각각의 head가 다른 부분에 집중하고 있다는 것을 볼 수 있습니다.

Conclusion
부가적인 기술이 들어가지 않은 간단하고 효율적인 모델입니다. backbone모델에 Transformer Decoder가 결합되었으며 여러 데이터셋에서 높은 성능을 보여줍니다.
더 자세한 내용은 논문에 있습니다.
