reference
https://github.com/taehojo/deeplearning
CH13 모델 성능 검증하기
13장에서는 음파 탐지기를 광석과 일반 암석에 쏜 후 만든 데이터셋을 이용하여 광석인지 일반 암석인지를 구분하는 모델을 텐서플로로 재현해보고
실험 정확도를 평가하는 방법과 성능을 향상시키는 머신 러닝 기법들에 대해 알아볼 것이다.
1) 데이터의 확인과 예측 실행
pandas 라이브러리를 부르고 github에 있는 데이터를 불러와서 데이터를 만들어준다.
이후 결과를 실행하면 accuracy가 100%가 나오는 것을 확인할 수 있다. 이러한 형태를 과적합이라고 한다.
2) 과적합 이해하기
과적합(overfitting)이란 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는 것을 의미한다.
과적합은 층이 많거나 변수가 복잡해서 또는 테슷트셋과 학습셋이 중복될 때 생기기도 한다.
3) 학습셋과 테스트셋
과적합을 방지하는 방법
1) 학습용 데이터셋과 테스트할 데이터셋을 구분한 후 학습과 동시에 테스트를 병행하기
지금까지는 테스트셋을 만들지 않고 학습을 하였다. 이는 에포크 값을 늘리거나 층을 더하면 정확도가 오를 수 있지만, 학습 데이터셋만으로는 테스트셋에서도 그 결과가 그대로 나타나지는 않는다.
그렇기 때문에 학습을 진행했는데 테스트 결과가 더 이상 좋아지지 않는 지점에서 학습을 멈추는 것이 가장 적절하다고 한다.
그렇다면 새로운 데이터에 대해 높은 정확도를 안정되게 보여 주는 모델을 만들기 위한 방법은 크게 데이터를 보강하는 방법과 알고리즘을 최적화하는 방법이 있다.
a) 데이터를 보강하는 방법
사진의 경우 사진 크기를 확대/축소하거나 또는 위 아래로 움직이는 방법 등으로 조절하는 등 가지고 있는 데이터를 적절히 보완해 주는 방법이다.
b) 알고리즘 최적화하는 방법
은닉층의 개수 들어가는 노드의 수 최적화 함수의 종류를 바꾸는 방법 등이 있다. 자신의 데이터에 맞는 구조를 사용하여 테스트하는 것이다.
4) 모델 저장과 재사용
model.save()를 통해 모델을 저장하고 load_model()을 사용해 재사용한다.
5) k겹 교차 검증
k겹 교차 검증(k-fold cross validation)이란 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 합쳐 학습셋으로 사용하는 방법이다.
이는KFold()를 활용하여 사용한다.
이 챕터에서는 가지고 있는 데이터를 모두 사용해 학습과 테스트를 하였는데 이 다음 장에서는 학습과정을 시각화 하는 방법과 학습을 몇 번 반복할지(epochs) 스스로 판단하게 하는 방법 등을 알아볼 것이다.
CH14 모델 성능 향상시키기
1) 데이터의 확인과 검증셋
이 챕터에서는 학습셋 데이터셋 이외에 검증셋이라는 데이터셋을 더해서 한다. 검증셋은 최적의 학습 파라미터를 찾기 위해 학습 과정에서 사용한다.
검증셋은 model.fit() 함수 안에 validation_split이라는 옵션을 주면 만들어진다.
2) 모델 업데이트하기
에포크를 적절히 정해주는 것은 중요하다. 여기서는 epoch마다 모델의 정확도를 함께 기록하면서 저장을 하는 방법을 알아보고 각 에포크마다의 정확도를 체크해서 가장 높은 정확도를 찾는다.
3) 그래프로 과적합 확인하기
예제에서는 역전파를 50번 반복하여 실행하였는데 이 수가 적절한지 확인할 것이다.
코드에서는 history라는 변수에 model.fit()을 실행할 때마다 결과를 저장하였는데 여기서 생긴 결과들을 판다스 라이브러리에 불러와서 살필 수 있다. 이제 그래프에 적용하여 학습셋에서 얻은 오차는 파란색, 검증셋에서 얻은 오차는 빨간색으로 표시할 것이다.

그래프를 보면 알겠지만 학습셋이 오래 진행될수록 학습셋의 오차는 줄지만 검증셋의 오차는 커진다. 이는 과적합이 발생하였기 때문이다. 이를 해결하기 위해 검증셋의 오차가 커지기 전에 학습을 자동으로 중단시키고, 그때의 모델을 저장해야 한다.
4) 학습의 자동중단
텐서플로의 EarlyStopping() 함수를 이용하여 테스트 오차가 줄어들지 않으면 학습을 자동으로 멈추게 할 수 있다.
예제에서는 에포크를 2,000번으로 하였지만 394번에서 멈추었다. 이를 적용하면 모델 성능이 98.84%로 나오는데 앞에보다 성능이 대폭 향상된 것을 볼 수 있다.
CH15 실제 데이터로 만들어 보는 모델
이번에는 실제 현장에서 만나게 되는 데이터를 어떻게 다루는지 다룬다.
1) 데이터 파악하기
80개의 속성과 1460개의 샘플로 이루어져 있다.
각 데이터가 어떤 유형으로 되어 있는지 알아보겠다.
df.dtypes를 통해 각 데이터가 어떤 유형으로 되어 있는지 알아볼 수 있다.
이 데이터는 정수형, 실수형, 오브젝트형 등의 유형으로 되어있는 것을 알 수 있다.
2) 결측치, 카테고리 변수 처리하기
이 데이터는 전처리가 끝나지 않았기 때문에 측정값이 없는 결측치가 있다. 이를 확인하기 위해 isnull() 함수를 이용하여 결측치가 몇 개인지 확인한다.
#속성별로 결측치가 몇 개인지 확인합니다.
df.isnull().sum().sort_values(ascending=False).head(20)이제 데이터를 12.3절에서 배운 방식으로 0과 1로 이루어진 변수로 바꿔주고 결축차룰 채워준다.
이는 판다스의 fillna()를 이용하여 채워줄 수 있다
#카테고리형 변수를 0과 1로 이루어진 변수로 바꾸어 줍니다.(12장 3절)
df = pd.get_dummies(df)
#결측치를 전체 칼럼의 평균으로 대체하여 채워줍니다.
df = df.fillna(df.mean())
#업데이트된 데이터프레임을 출력해 봅니다.
df3) 속성별 관련도 추출하기
데이터 사이의 상관관계를 df_corr변수에 저장하고 집 값과 관련이 큰 것부터 순서대로 정렬해 df_corr_sort 변수에 저장한다. 이후 집 값과 관련도가 가장 큰 열 개의 속성들을 출력한다.

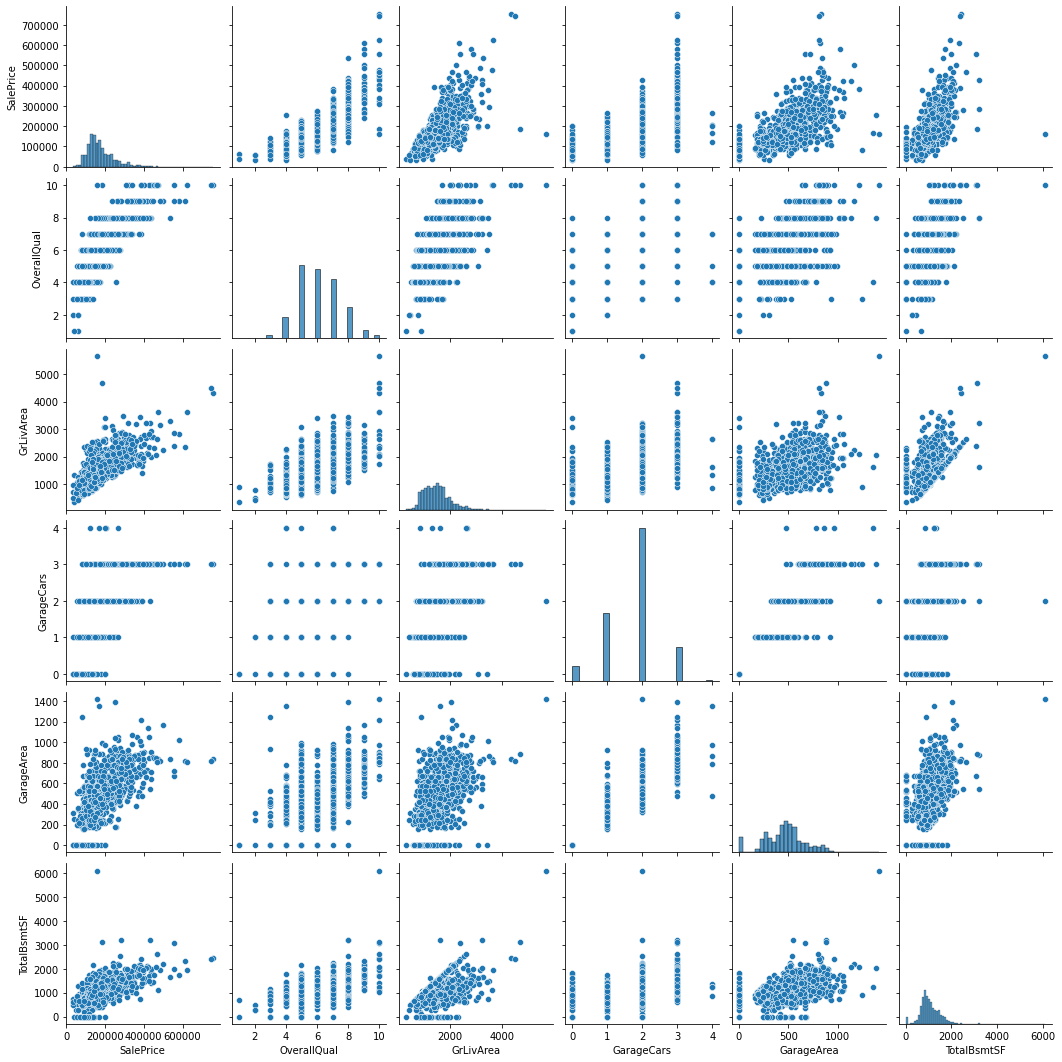
추출된 속성들과 집 값의 관련도를 시각적으로 확인하는 상관도 그래프이다.
여기서 집 값(SalePrice)과 양의 상관관계가 있음을 확인할 수 있다.
3) 주택가격 예측 모델
여기서는 집 값을 y로 나머지 열을 X_train_pre로 저장하여 80%는 학습셋, 20%는 테스트셋으로 지정한다.
선형 회귀이므로 평균 제곱 오차를 적는다. 20번 이상 결과가 향상되지 않으면 자동으로 중단이 된다.

최종 결과를 보면 예측 집 값 곡선과 실제 집값의 곡선과 유사하게 움직인다는 것을 볼 수 있다.
