reference
https://github.com/taehojo/deeplearning
다섯째 마당 : 딥러닝 활용하기
이 파트에서는 딥러닝의 가장 대표적인 활용법인 CNN과 RNN을 비롯해 자연어 처리, GAN, 오토인코더, 전이학습 등을 실습해 볼 것이다.
CH 16 이미지 인식의 꽃, 컨볼루션 신경망(CNN)
이번 챕터에서는 손글씨를 어떻게 판단하는지 알아보는 방법에 대해 배워봄으로 CNN에 대해서 배워볼 것이다.
데이터셋은 MNIST라는 7만 개의 데이터셋을 사용할 것이다.
1) 이미지를 인식하는 원리
MNIST 데이터를 케라스 API를 통해 불러 온다.
from tensorflow.keras.datasets import mnist
불러온 이미지 데이터: X, 위 데이터에 0~9를 붙인 이름표를 y로 구분해 명하고, 학습에 사용될 데이터는 train으로. 테스트에 사용될 부분은 test로 불러온다.
#MNIST 데이터셋을 불러와 학습셋과 테스트셋으로 저장합니다.
(X_train, y_train), (X_test, y_test) = mnist.load_data()실행하면 아래와 같은 그림이 출력된다.
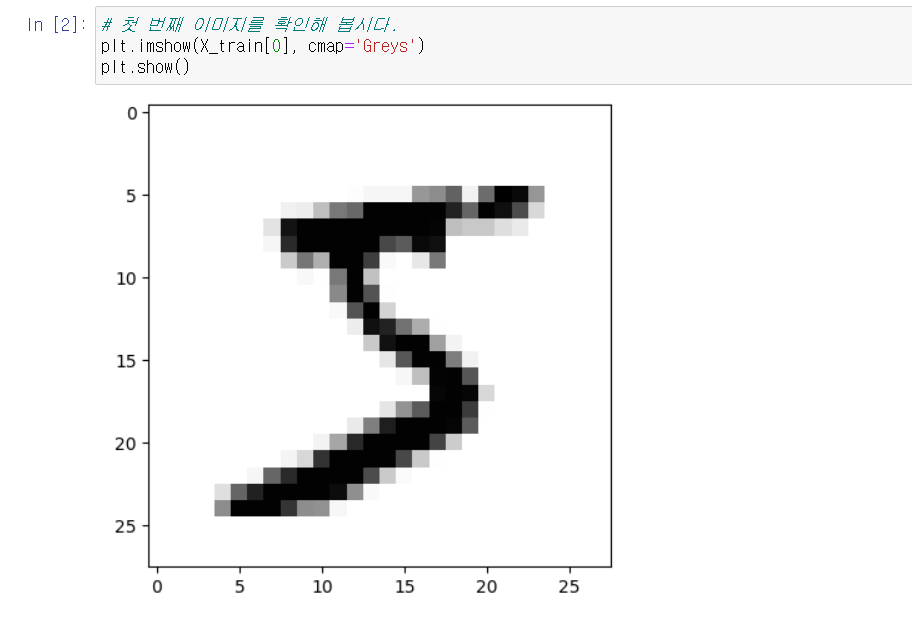
이 이미지를 컴퓨터는 28 X 28 = 784의 픽셀로 인식을 한다.
흰색은 0 나머지는 1~255의 숫자로 인식하여 채워진다.

이 이미지는 숫자의 집합으로 바뀌어 학습셋으로 사용된다.
이제 reshape() 함수를 사용하여 2차원 배열을 1차원 배열로 만들고
255로 숫자를 나눠서 0~1사이의 값으로 만든 후 숫자의 class를 출력하면 이 숫자 5가 출력이 되는 것을 볼 수 있다.
이 때, 12장에서 배운 원-핫 인코딩 방식을 적용하여 0~9의 정수형 값을 0과 1로 이루어진 벡터로 수정하여
[0,0,0,0,0,0,1,0,0,0,0]으로 바꾸려면 np+utils.to_categorical() 함수를 사용한다.
2) 딥러닝 기본 프레임 만들기
여기서는 불러온 데이터를 실행할 것이다. 6만 개의 학습셋, 1만 개의 테스트셋을 불러올 것이다.
입력 값이 784개, 은닉층이 512개, 출력이 10개인 모델이다. 활성화 함수로 은닉층은 relu, 출력층에서는 softmax 함수를 사용하였다.
또한 최적화 단계에서는 10번 이상 모델 성능이 향상되지 않을 시, 학습을 중단하게 하여 과적합을 방지하였다.
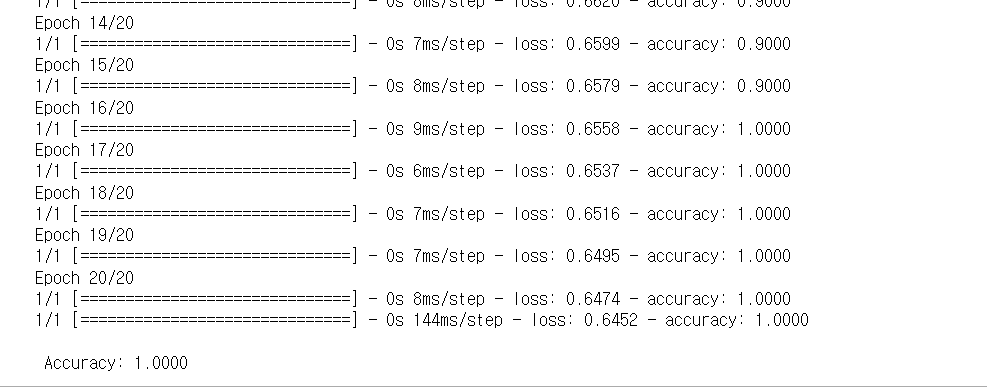
샘플 200개룰 30번 실행하여, 테스트셋으로 최종 모델의 성과를 측정해 그 값을 출력한다.

실행하면 23번째 실행에서 멈춘다. 베스트 모델은 13번째 에포크이며, 이 모델에 대한 정확도는 98.16%다.
딥러닝은 기본 모데레서 옵션을 더하거나 어떤 층을 추가함으로 성능이 좋아질 수 있다. 여기서는 컨볼루션 신경망(Convloution Neural Network)를 다룰 것이다.
3) 컨볼루션 신경망(CNN)
컨볼루션 신경망은 입력된 이미지에서 특징을 추출하기 위해 커널(슬라이딩 윈도)를 도입하는 기법이다.
1 0 1 0
0 1 1 0
0 0 1 1
0 0 1 0
여기에 2x2 커널을
x1 x0
x0 x1
을 적용시키면
다음과 같이 정리 된다.
2 1 1
0 2 2
0 1 1
이를 컨볼루션(합성곱) 층이라고 한다. CNN은 입력 데이터가 가진 특징을 추출해서 학습을 진행한다. 이러한 커널을 여러 개 만들 경우 여러 개의 컨볼루션 층이 만들어진다.
케라스에서는 컨볼루션 층을 Conv2D() 함수를 이용하여 사용한다.
model.add(Conv2D(32, kernel_size=(3, 3), input_shape=(28, 28, 1), activation='relu'))32는 32 개의 커널을, 커널의 크기는 3x3의 행렬을, input_shape는 28x28의 이미지를 흑백으로 사용한다. relu함수를 활성화 함수를 쓴다.
이어서 컨볼루션 층을 추가한다.
model.add(Conv2D(64, (3, 3), activation='relu'))4) 맥스 풀링, 드롭아웃, 플래튼
컨볼루션의 크기가 크고 복잡하니 이를 축소하기 위해 풀링(pooling)또는 서브 샘플링(sub sampling)을 사용한다.
맥스 풀링(max pooling) : 정해진 구역 안에서 최댓값을 뽑아내는 풀링
평균 풀링(average pooling) : 평균값을 뽑아내는 풀링
과적합을 피하기 위한 방법
드롭아웃(drop out) : 은닉층에 배치된 노드 중 일부를 임의로 꺼 준다.
이러한 드롭아웃까지 적용했지만 컨볼루션 층이나 맥스풀링은 2차원 배열이므로 Flatten() 함수를 이용해 2차원 배열을 1차원 배열로 바꿔준다.
5) 컨볼루션 신경망 실행하기
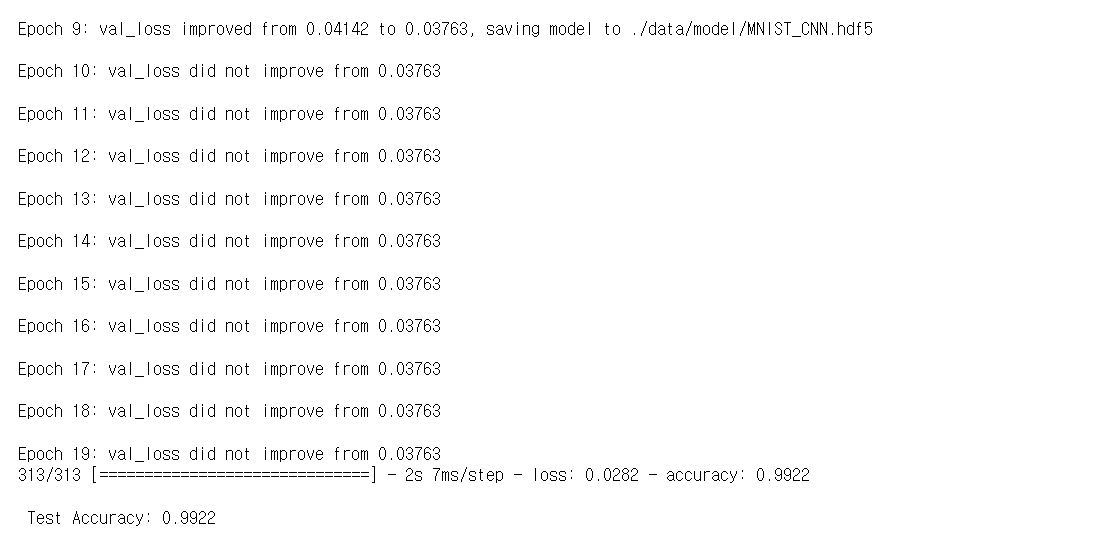
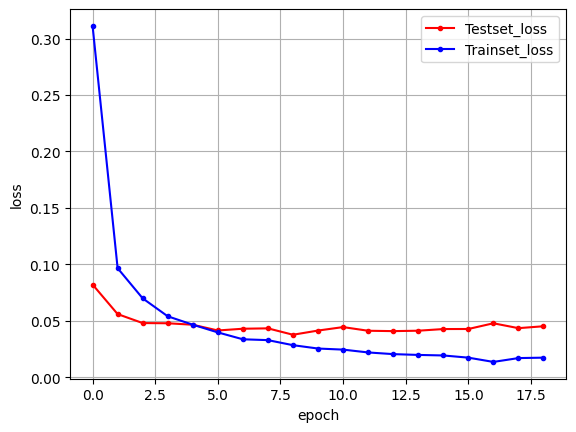
이제 코드를 실행해보면 99.22 %의 정확도를 가지고 오차가 작아진 것을 확인하였다.
CH 17 딥러닝을 이용한 자연어 처리
이번 장에서는 자연어 처리(Natural Language Processing, NLP)에 대해서 배울 것이다.
현재 다양한 대화형 인공지능(ex. Siri, assistant, alexa)등에 사용되고 있다.
자연어란 평상시에 하는 음성이나 텍스트 등을 의미하는데 자연어 처리는 이러한 음성과 텍스트를 인식하고 처리하는 것을 의미한다.
딥러닝은 대용량 데이터를 학습할 수 있는 특성 상, 비교적 쉽게 얻을 수 있는 자연어 데이터를 입력해 끊임없이 학습하는 것이 가능하다.
여기서는 텍스트를 전처리하는 과정에 대해서 알아볼 것이다.
1) 텍스트의 토큰화
텍스트를 단어별, 문장별, 형태소 별로 잘게 나눠야 한다. 이렇게 잘게 나눠진 단위를 토큰(token)이라고 한다.
토큰화 (tokenization) : 입력된 텍스트를 잘게 나누는 과정
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Embedding
from tensorflow.keras.utils import to_categorical
from numpy import array
#케라스의 텍스트 전처리와 관련한 함수중 text_to_word_sequence 함수를 불러옵니다.
from tensorflow.keras.preprocessing.text import text_to_word_sequence다음의 문장을 예제에서는 토큰화를 하였다.
'해보지 않으면 해낼 수 없다'
케라스의 text 모듈의 text_to_word_sequence() 함수를 사용하여 문장을 단어 단위로 나눌 수 있다.
실행 결과 :
쪼개진 단어로 빈도수를 파악하여 텍스트에서 중요한 단어를 파악할 수 있다.
단어 단위로 쪼개는 것은 가장 많이 쓰이는 전처리 과정이다.
Bag-of-words : 같은 단어끼리 따로따로 가방에 담은 후 각 가방에 몇 개의 단어가 들어 있는지 세는 기법
케라스의 Tokenizer()를 사용하여 단어의 빈도수를 쉽게 계산할 수 있다.
2) 단어의 원-핫 인코딩
단어의 빈도수로는 단어가 문장의 어디에서 왔는지, 순서 등에 대한 정보는 얻을 수 없으니, 단어가 문장의 다른 요소들과 어떤 관계를 가지는지 알기 위해
원-핫 인코딩이라는 방법이 필요하다.
원-핫 인코딩(one-hot encoding) : 여기서는 각 단어를 모두 0으로 바꾸고 원하는 단어만 1로 바꾼다
3) 단어 임베딩
원-핫 인코딩을 그대로 사용하면 벡터의 길이가 길어진다.이를 해결하기 위해 단어 임베딩이라는 방법을 쓴다.
단어 임베딩(word embedding) : 주어진 배열을 정해진 길이로 압축시킨다.
각 단어 간의 유사도를 파악하여 계산하였기 때문에 밀집된 정보와 공간 낭비가 적게 만드는 것이다.
4) 텍스트를 읽고 긍정, 부정 예측하기
여기서는 영화 리뷰를 딥러닝 모델로 학습해서 각 리뷰가 긍정적인지 부정적인지 예측한다.
짧은 리뷰 10개를 불러와 긍정이면 1, 부정이면 0이라는 클래스로 지정한다.
이를 실행하면 다음과 같은 배열로 바뀐다.
리뷰 텍스트, 토큰화 결과:
[[1, 2], [3], [4, 5, 6, 7], [8, 9, 10], [11, 12, 13], [14], [15], [16, 17], [18, 19], [20]]
각 단어가 1부터 20까지의 숫자로 토큰화되었다는 것을 알 수 있다. 하지만 리뷰된 데이터의 토큰 수가 각각 다르므로 학습 데이터의 길이를 동일하게 만들 필요가 있다.
패딩(padding) : 학습 데이터의 길이를 동일하게 맞추는 작업, 여기서는 토큰의 수를 똑같이 맞추어 준다.
패딩은 GAN에서도 중요한 역할을 한다.
출력 결과 :