DL Basic
Convolution
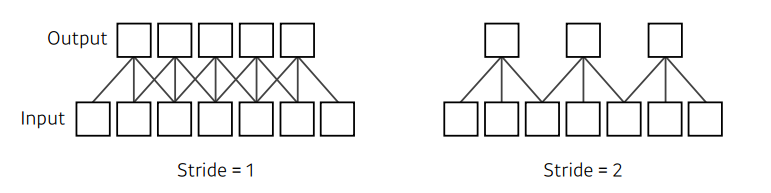
Stride
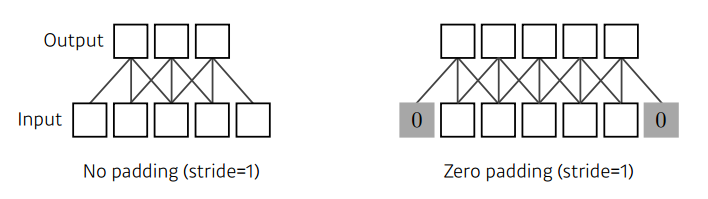
Padding
파라미터 수 구하는 법
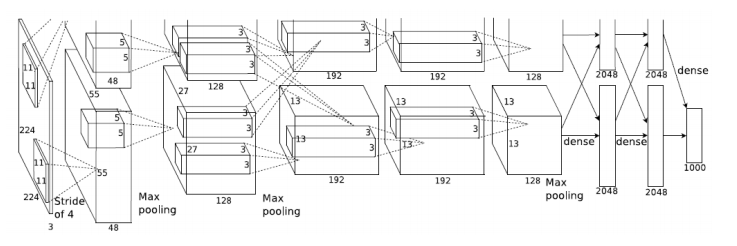
1) 11 X 11 X 3 X 48 X 2 = 34,848개
2) 5 X 5 X 48 X 128 X 2 = 307,200개
3) 3 X 3 X 128 X 2 X 192 X 2 = 884,736개
4) 3 X 3 X 192 X 192 X 2 = 663,552개
5) 3 X 3 X 192 X 128 X 2 = 442,368개
network가 input에서 output 갈 때 Dense layer가 convolution layer보다 파라미터 수가 많은 이유는, convolution operator가 각각의 하나의 커널이 모든 위치에 대해서 동일하게 적용되기 때문이다.
6) 13 X 13 X 128 X 2 X 2048 X 2 = 177,209,344개
7) 2048 X 2 X 2048 X 2 = 16,777,216개
8) 2048 X 2 X 1000 = 4,096,000개
CNN - 1x1 convolution
ILSVRC = ImageNetLarge-ScaleVisualRecognitionChallenge
Classification/Detection/Localization/Segmentation

성능이 2010년 Error Rate가 28.2%에서 2015년은 3.5%로 줄었다.
AlexNet - ILSVRC 2012 1위
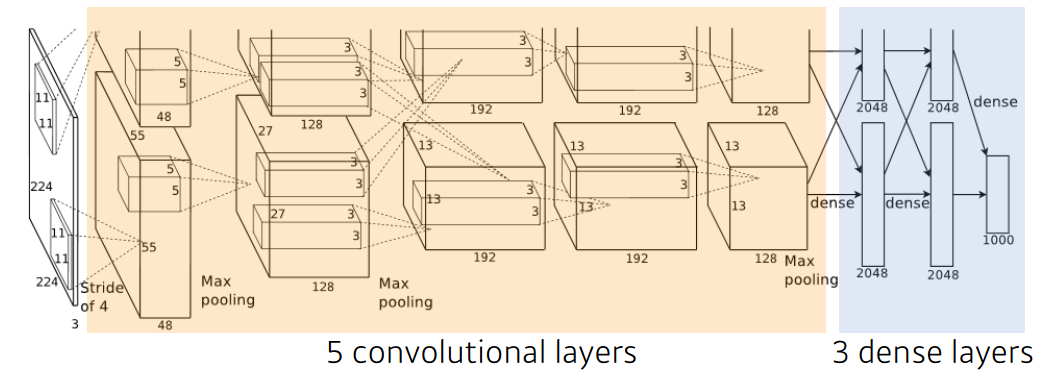
5개의 convolutional layers 와 3개의 dense layers로 이루어져 있다.
특징
- activation function = ReLU
- 2개의 GPU 활용
- Data augmentation 활용
- Dropout 사용
2021년의 지금에서는 많이 사용하는 구조였지만, 2011년에는 딥러닝 모델이 많지 않아서 ImageNet Large Scale Visual Recognition Challenge에서 수상한 작품이다.
ReLU Activation
- linear의 좋은 성질을 그대로 가지고 있다.
- sigmoid, tanh 같은 경우에는 뉴런의 값이 0에서 많이 벗어나면, slope 자체가 0에 가까워져 vanishing gradient problem을 겪는데 이걸 방지해준다.
VGGNet - ILSVRC 2014 2위
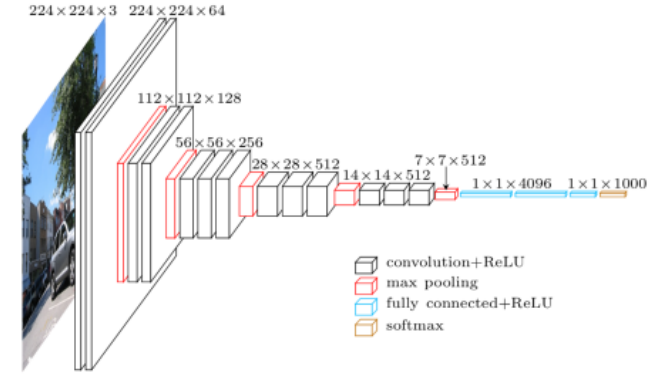
특징
- 3X3 convolution을 활용하였다.
- Dropout
3X3 convolution을 사용한 이유?
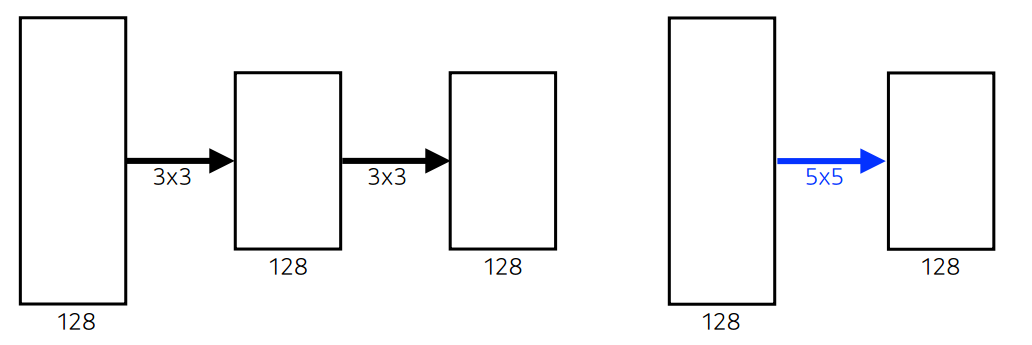
3x3x128x128+3x3x128x128 = 294,912, shape = (5, 5)
55128*128 = 409,600, shape = (5, 5)
3X3 convolution을 두번 사용하는 것과 5X5 convolution 한번 사용하는 것을 비교하면, 차원이 같은 것에 비해 파라미터 수가 크게 줄기 때문에 3X3 convolution을 두번 사용한다.
GoogLeNet - ILSVRC 2014 우승
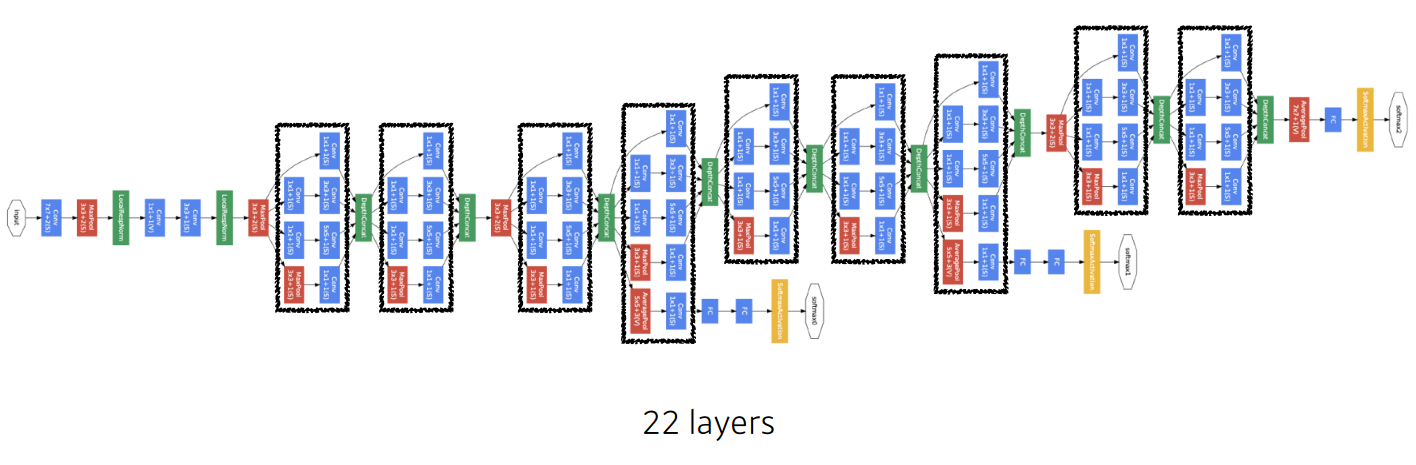
비슷하게 보이는 네트워크가 여러번 반복되는 것을 볼 수 있다.
특징
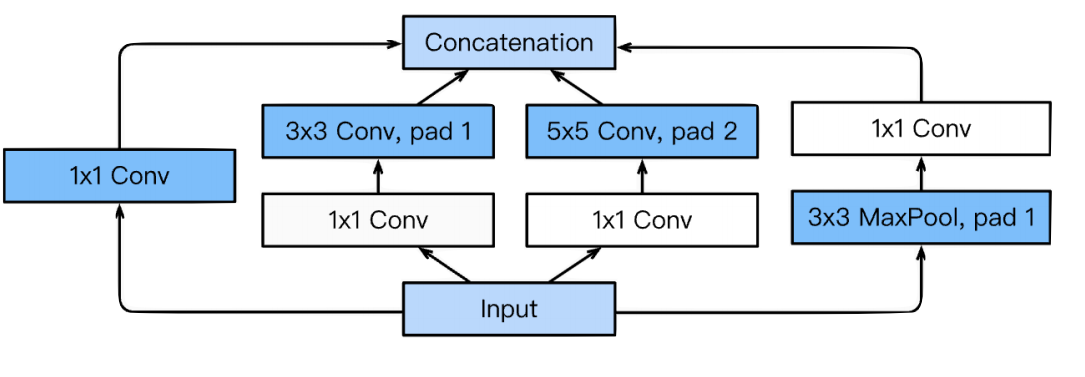
3 X 3 , 5 X 5 convolution을 사용하기 전에 1 X 1 convolution을 사용하는 것을 확인 할 수 있다.
1 X 1 convolution을 사용하면 파라미터 수가 줄어드는 이유
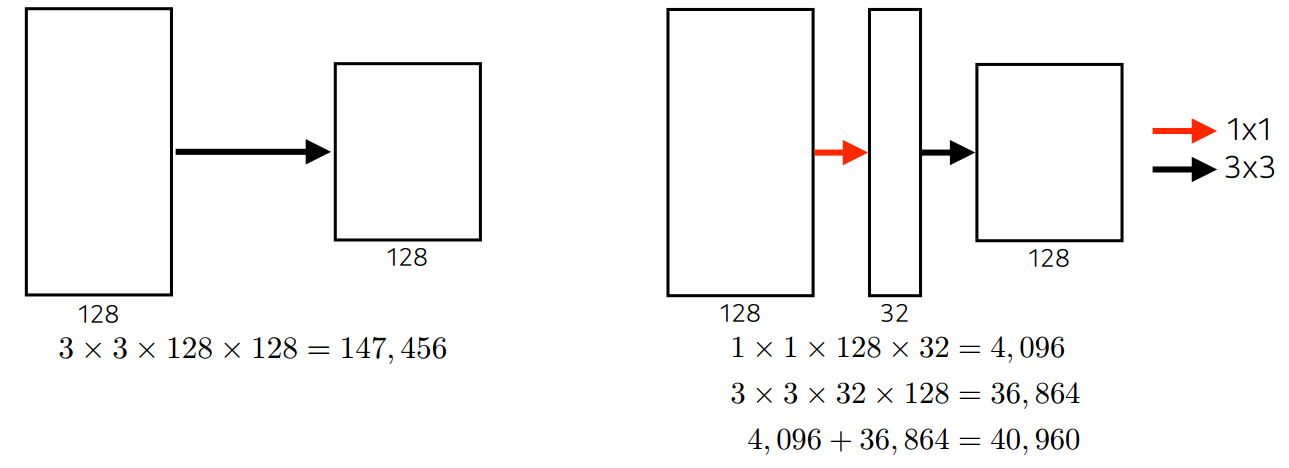
중간에 1X1 convolution을 통해 채널의 수를 줄임으로써 파라미터 수를 줄일 수 있다/
ResNet - ILSVRC 2015 우승
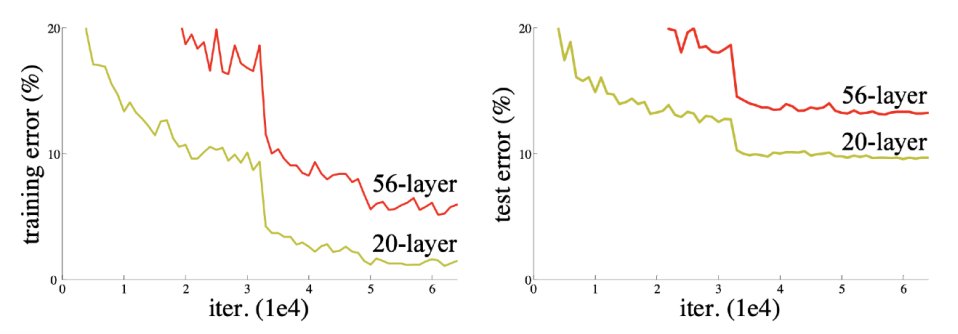
파라미터 수가 많으면 두가지 문제가 발생한다
- overfitting
- 학습을 못시킬 수 있음
특징
ResNet은 이걸 방지하고자 identity map을 만들었다.
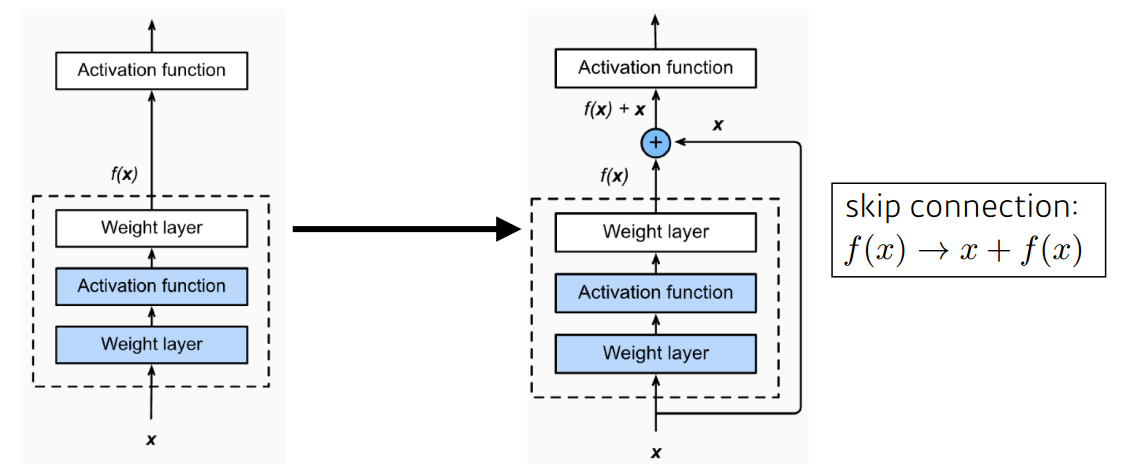
이것은 더 layer를 깊게 쌓아도 학습시킬 수 있는 이점이 있다.
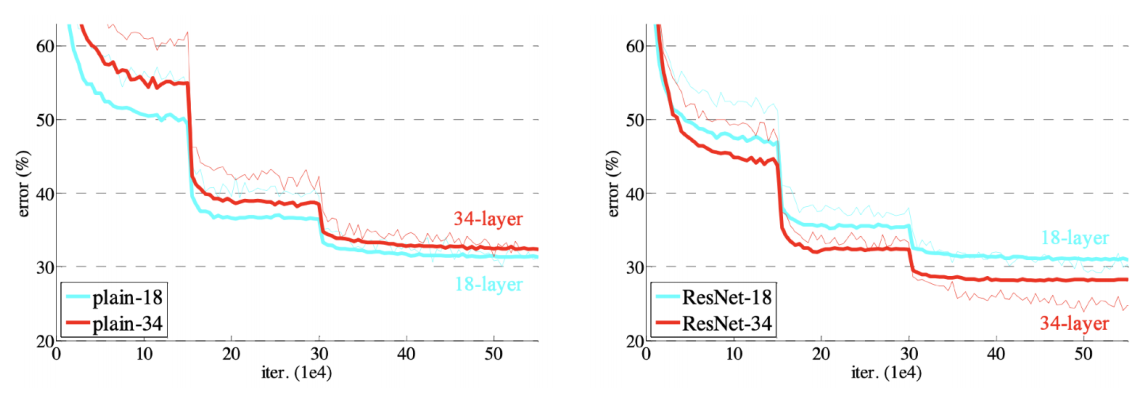
projected shortcut의 경우에는 차원이 다른 경우에 차원을 맞추기 위해 1X1 convolution을 사용한다. 일반적으로 Simple Shortcut을 사용한다.
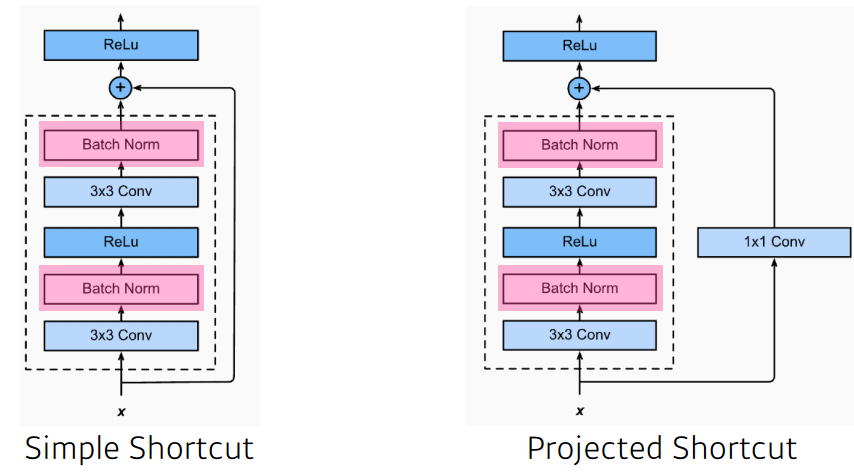
ResNet은 Batch Normalization이 Convolution 다음에 일어나게 된다.
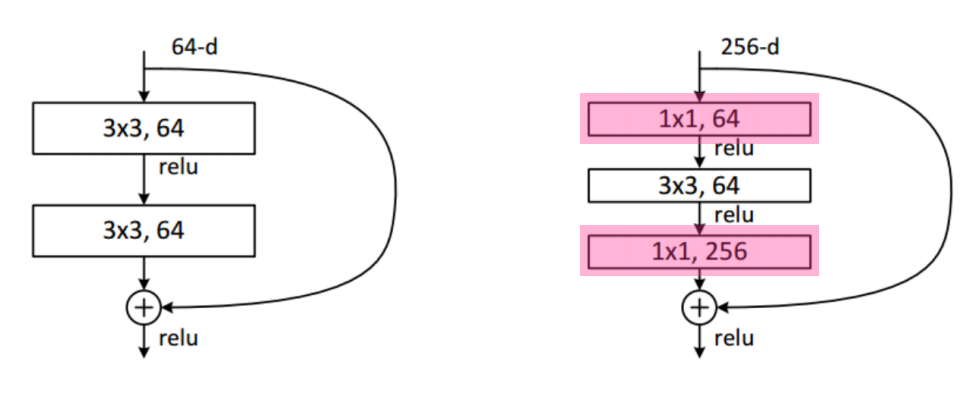
파라미터 숫자를 줄이기 위해 3X3 convolution을 하기 전에 1X1 convolution으로 input 파라미터 수를 줄이고, 3X3 convolution을 한 후에 1X1 convolution으로 input 파라미터 수를 다시 늘려주는 방법을 수행한다.
DenseNet
DenseNet은 ResNet과 달리 더하지 않고 연결하는 방식을 사용한다.
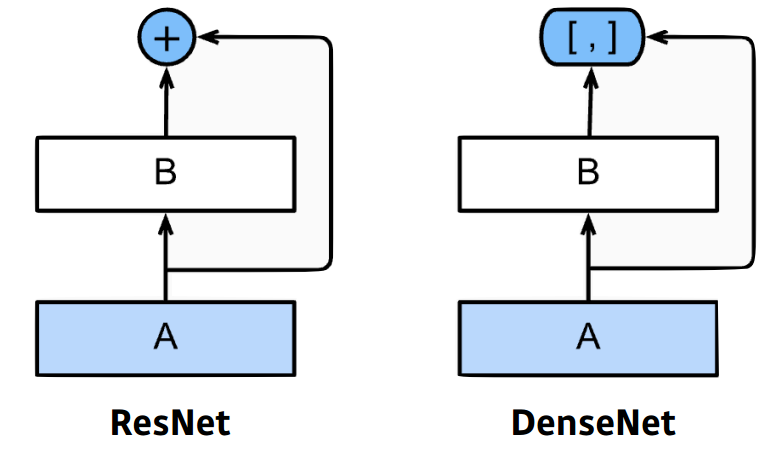
다만, 연결하는 방식을 사용하면, 채널이 기하급수적으로 커지는 문제가 발생하고, 파라미터 수 또한 기하급수적으로 커지는 문제가 발생한다.따라서, 중간에 X1 convolution을 이용하여 파라미터 수를 줄인다.

Computer Vision Applications
Semantic Segmentation
- 이미지의 모든 pixel에 대해 모두 분류하는 것
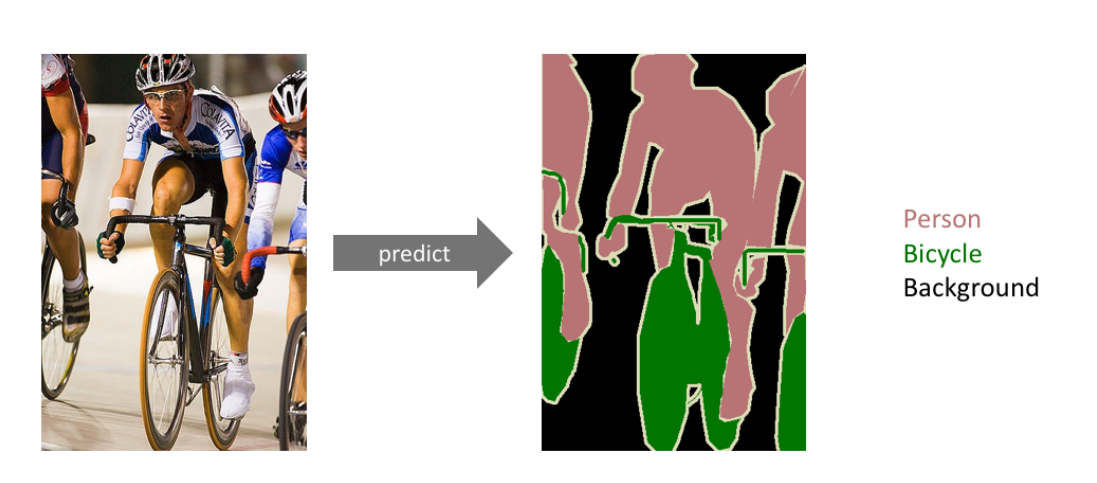
ex) 자율주행 등에 많이 활용된다.
일반적인 CNN
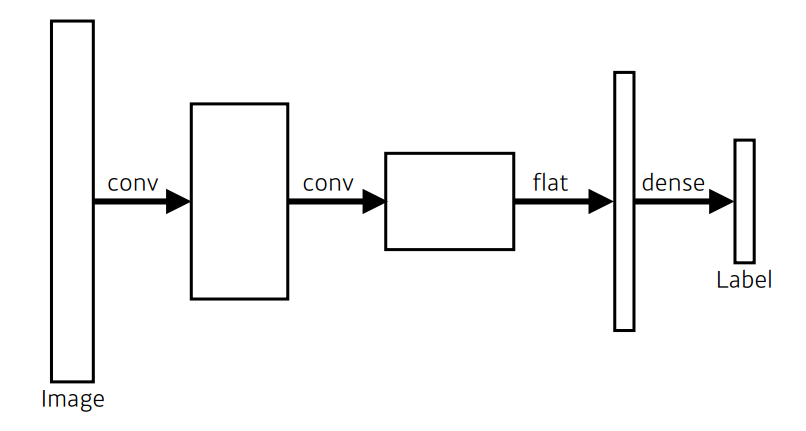
Fully Convolutional
- Dense layer를 없애는 것
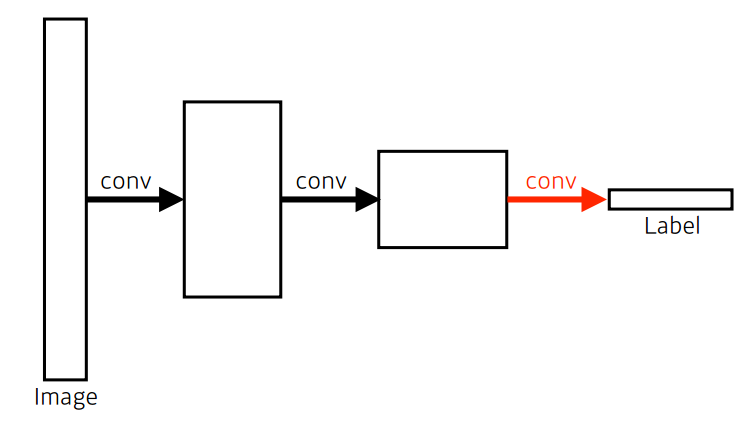
Semantic Segmentation 관점에서 Fully Convolutional를 사용하는 이유 :
input layer와 상관없이 네트워크를 작동시킬 수 있다.
Convolution은 input의 크기와 상관없이 커널이 작동하기 때문에 spacial dimension만 커지기 때문이다. 하지만, input 크기와 상관없이 작동할 수 있지만, output dimension 또한 줄어들 수 있기 때문에, 이것을 늘리는 방법이 필요하다.
- Deconvolution
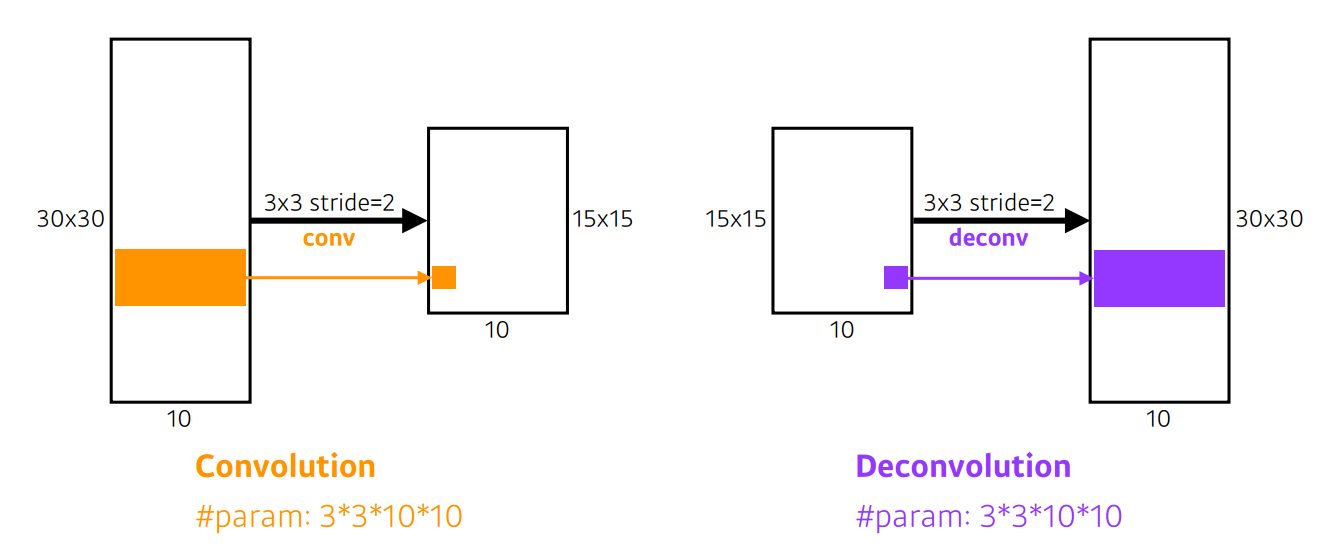
convolution의 역 연산은 존재할수 없다, convolution이 동작하는 방식은, 커널의 범위의 모든 pixel을 모두 더하기 때문에 복원이 불가능하기 때문이다. 하지만 Deconvolution은 convolution의 역이라고 생각하면 계산이 편해진다.
Detection
R-CNN
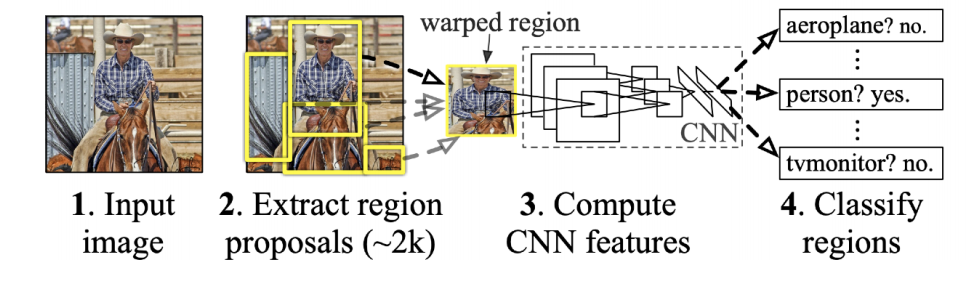
Detection을 간단하게 하는 방법
이미지 안에서 물체가 있을 만한 bounding box를 여러개 뽑고, 크기와 같도록 warp을 수행한 뒤에 AlexNet 등을 이용해 각각 결과를 얻은 다음 SVM 을 이용해 분류하는 기법
SPPNet
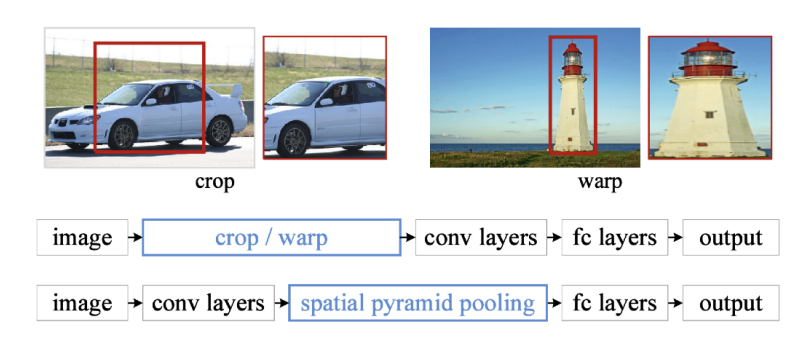
R-cnn은 1개의 이미지에서 여러개로 나온 모든 이미지를 동일한 크기로 맞추어주기 위해 warp를 수행한다.
SPPNet은 이를 개선하여, crop/warp을 수행하는 대신 이미지에서 bounding box에서 뽑고, 전체 이미지를 convolution을 통해 feature map을 만든 후, Feature map에서의 bounding box에 해당하는 위치만 뽑아서 classification을 수행한다.
실제 CNN을 수행하는 횟수가 1번이기 때문에 즉, R-CNN보다 훨씬 빠르다.
하지만 SPPNet 또한 bounding box를 몇천개나 만들고, 이에 대해 분류를 하기 때문에 역시 느리다.
Fast R-CNN
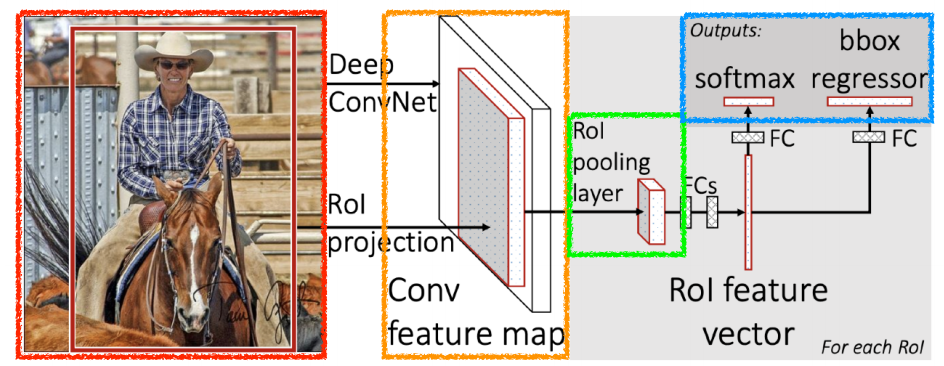
SPPNet과 비슷한 컨셉이다. SPPNet의 Feature map에서의 bounding box에 해당하는 위치만 뽑는 과정을 ROI Pooling을 이용해 사용한다.
Faster R-CNN
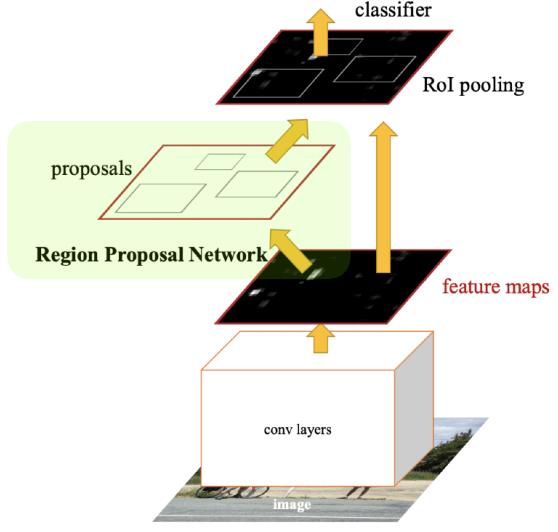
이미지를 통해 bounding box를 뽑아내는 과정도 학습을 하는 모델이다.
내가 bounding box를 학습을 통해 뽑는 과정을 Region Proposal Network라고 한다.
이와 Fast R-CNN이 합쳐진 것이 Faster R-CNN이라고 한다.
Region Proposal Network(RPN)
이미지가 있으면 이미지에서 특정 영역이 bounding box가 쓸모가 있는지 판별하는 것
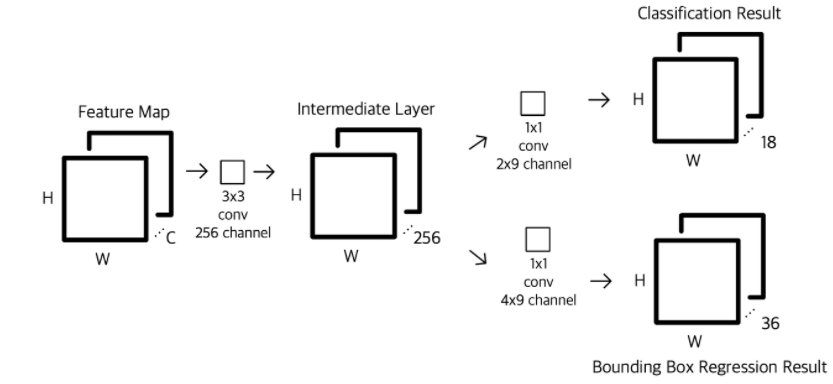
입력 : Feature map
1. 3X3 convolution 수행
2. 두 번의 1 X 1 convolution을 수행하여 object가 있을 지 판별하는 classification ,크기를 판별하는 Bounding Box 크기 예측값을 계산한다.
Fully convolution을 수행한다.
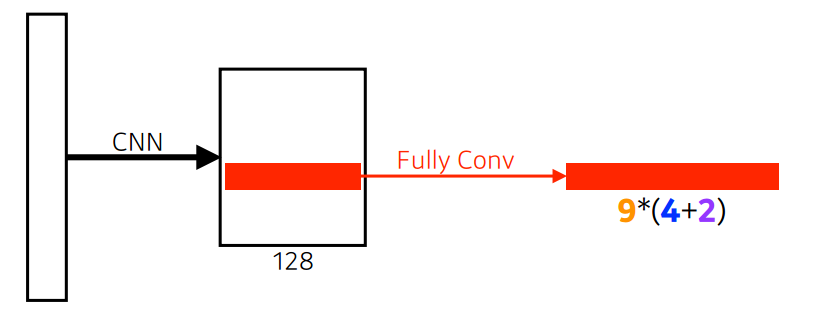
9 = 3개의 region size(128, 256, 512), 3개의 ratios(1:1, 1:2 , 2: 1) = 3 X 3
4 = bounding box의 크기(4개의 파라미터, x, y, weight, height)
2 = 해당 bounding box가 쓸모가 있는지의 유무
해당하는 영역의 이미지에 물체가 들어있는지 유무
YOLO(v1)
이미지 한장에서
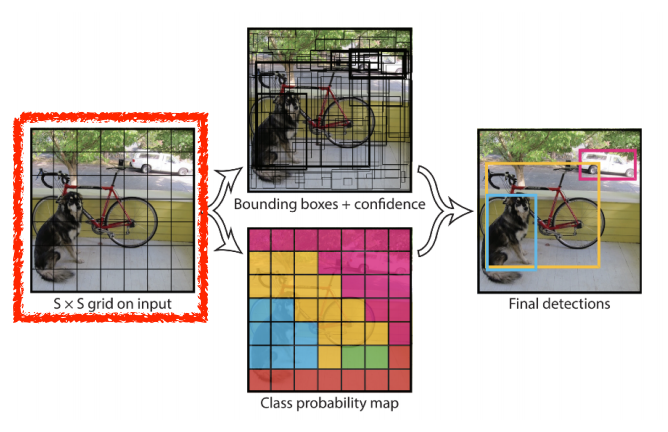
1. B(사진에선 5)개의 bounding box에 x/ y/ w/ h를 찾게 되고, 쓸모 있는지 없는지 찾게된다.
2. 그와 동시에 bounding box의 classification을 수행한다.
Tensor의 사이즈는 S X S(B * 5 + C)와같다.
