Sequential Models - RNN
-
가장 기본적인 sequence model (ex) language model
-
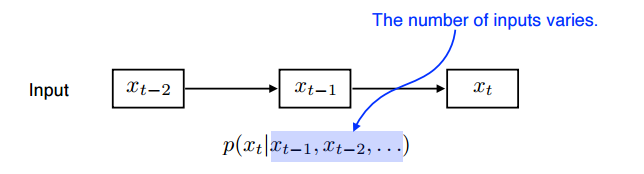
과거의 일부만 확인하는 Autogressive model
-
Markov model (first-order autoregressive model)
내가 가정을 하기에 내 현재는 과거에만 dependent
-
Latent autoregressive model
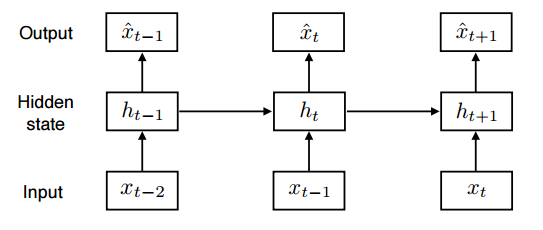
hidden state가 과거의 정보를 들고 있음
-
RNN
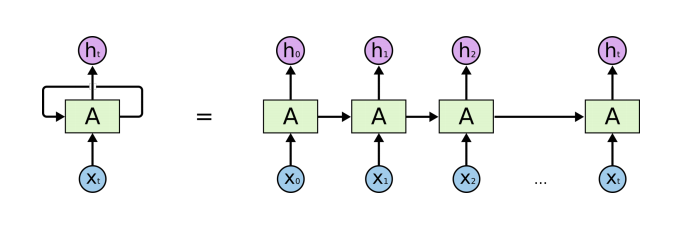
자기 자신으로 되돌아오는 구조
RNN의 단점 = 과거의 정보들이 미래에 고려되어야 하는데, RNN 모델은 정보를 계속 취합하기 때문에 이전의 정보가 미래까지 살아남기 힘들다.
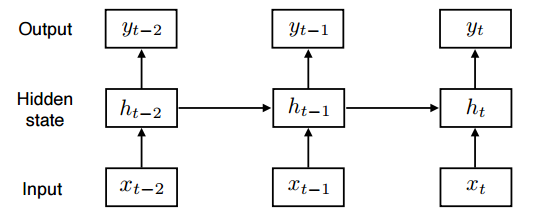
hidden state가 진행될 수록 이전의 hidden state가 중첩되기 때문에, 활성함수를 거치면서 계속 줄거나 계속 커지기 때문이다( ex) 활성함수가 tanh 함수일 경우 hidden state를 거칠 수록 계속 줄어듬, ReLU 함수일 경우 hidden state를 거칠 수록 계속 커짐)
ex) 몇 초전에 한 말을 기계가 기억할 수 있음 등
LSTM(Long Short Term Memory)
LSTM은 이러한 Long-term dependencies를 방지하고자 등장하였다.
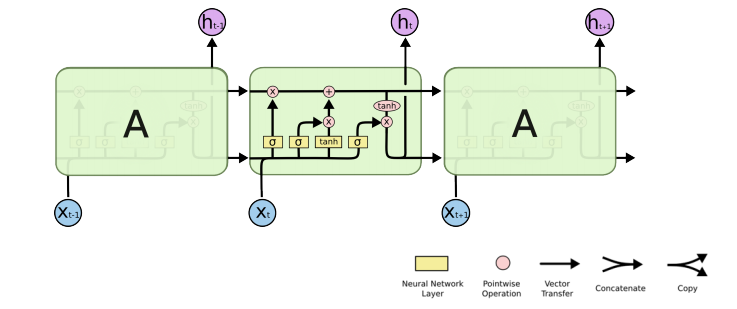
previous cell state : 0 부터 t까지의 t+1개의 정보를 취합함
previous hidden state : LSTM이 입력으로 들어가는 것 + previous hidden state를 이용
LSTM은 3개의 gate로 이루어져 있다.
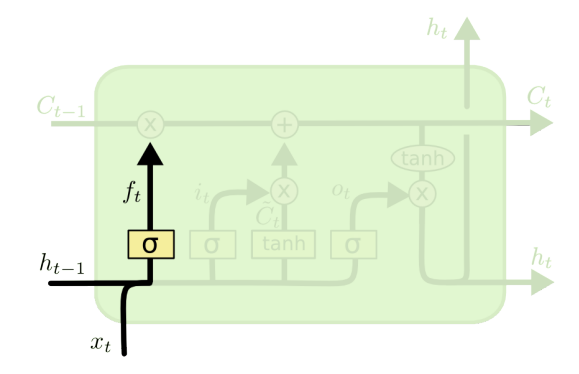
- Forget gate : input값과 previous hidden state를 받아, 어떤 정보를 조작할지 결정하는 gate
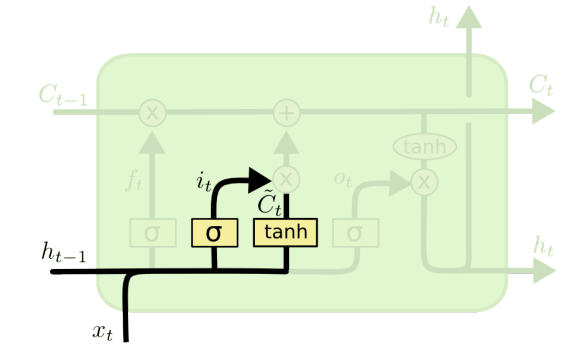
- Input gate : input값과 previous hidden state를 받아, 어떤 정보를 cell state로 추가할지 결정하는 gate
- cell을 업데이트하는 과정
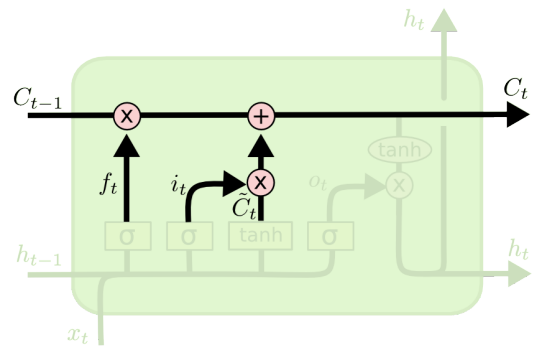
Output Gate : 어떤 값을 output gate로 내보낼지 결정하는 gate
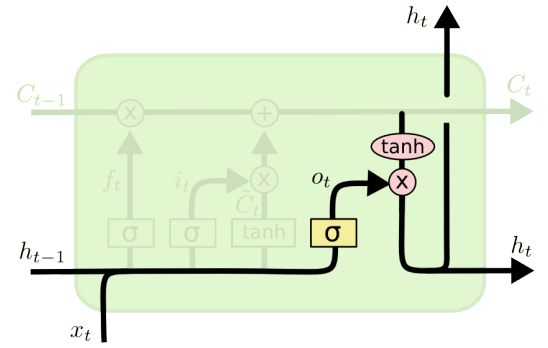
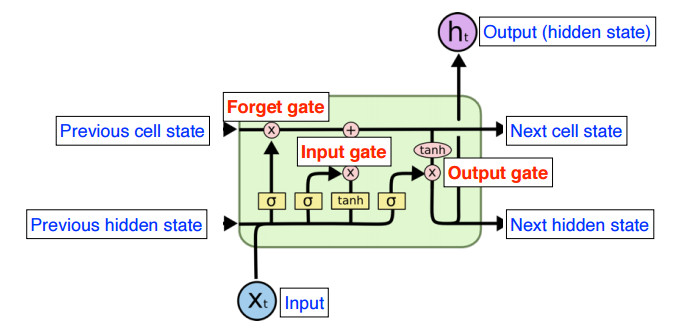
이를 합친 LSTM의 구조는 다음과 같다.
GRU(Gated Recurrent Unit)
- gate가 reset gate와 update gate로 이루어져 있고, cell state가 존재하지 않고 오직 hidden state만 존재한다. LSTM보다 파라미터가 적다.
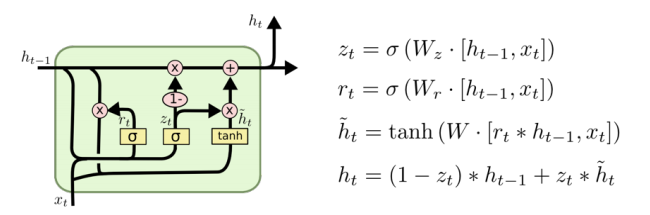
LSTM보다 GRU를 사용할때 성능이 올라가는 경우가 꽤 존재한다.
하지만 요즘은 이 둘은 많이 사용하지 않는데...
Transformer
Transformer는 재귀적은 구조가 없고, attention이라는 구조를 활용한 sequence를 다루는 모델이다.
기계어 번역 뿐만아닌, 이미지 분류등에도 사용된다.
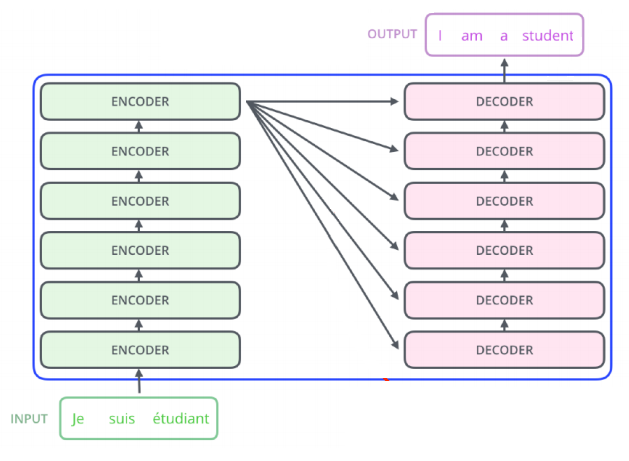
다음 예시의 input 과 output을 보면 다음과 같은 것을 알 수 있다.
1. 입력과 출력의 단어의 개수가 다를 수 있다
2. 입력 sequence의 domain과 출력 sequence의 domain이 다를 수 있다.
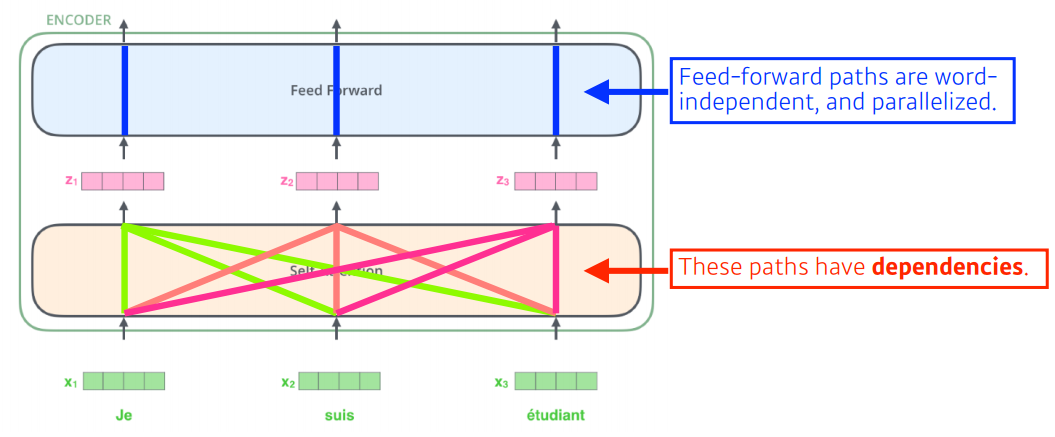
이를 유추하면 RNN과 달리 Transformer는 재귀적으로 작동하지 않음을 알 수 있다. 또한 단어를 몇개 받는지와 상관없이 동일한 구조를 갖지만, 네트워크마다 다르게 학습되며, n개의 단어를 한번에 처리할 수 있다.
A. 어떻게 인코더에서 n개의 단어를 한번에 처리할 수 있는가?
B. 인코더와 디코더 사이에 어떤 정보를 주고 받는가?
C. 디코더가 어떻게 gereration을 하는지?
A. 어떻게 인코더에서 n개의 단어를 한번에 처리할 수 있는가?
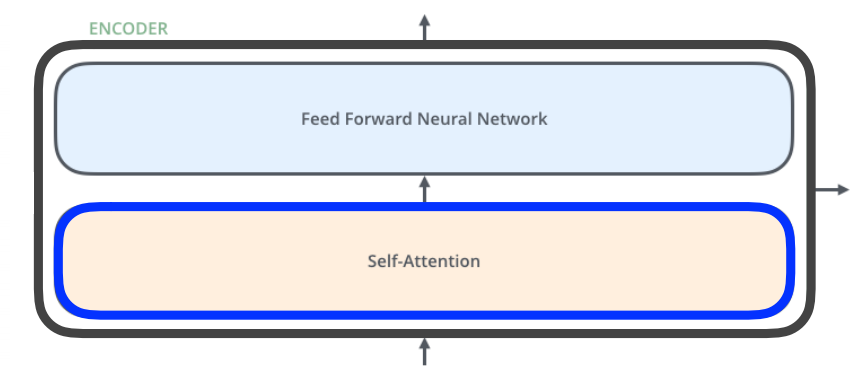
인코더의 구조는 다음과 같다.
feed forward Neural Network = MLP와 동일하다.
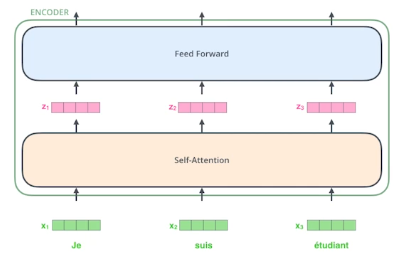
z1을 구하는데에 x1 뿐만 아닌 모든 단어를 고려한다.
- Self - Attention
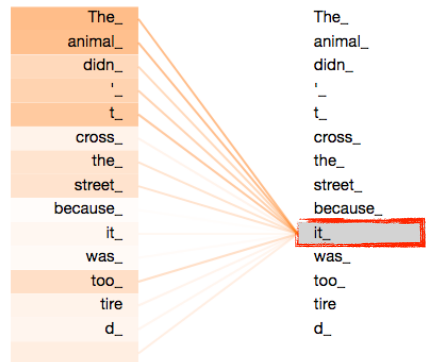
The animal didn't cross the street because it was too tired
이 문장을 이해하려면 it이 어떤 단어에 dependent한지 알아야 한다. 즉, 단어 자체를 이해하는 것만이 아닌, 문장 속에서의 단어들과 어떤 interaction이 있는지 확인하여야 한다.
- self-Attention의 작동 방법
-
하나의 단어마다, 각각의 neural network를 이용해 queries, keys, values 세 개의 vector를 만들게 된다.
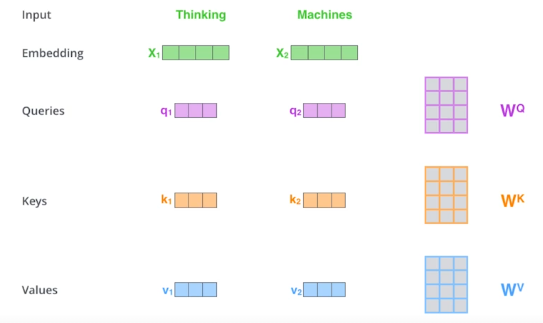
-
encoding을 하고자하는 단어의 queries vector와, 나머지 모든 n개에 대한 key vector를 구해 내적을 수행해 Score vector를 만든다. 이를 이용하면 단어마다의 interaction을 구할 수 있다.
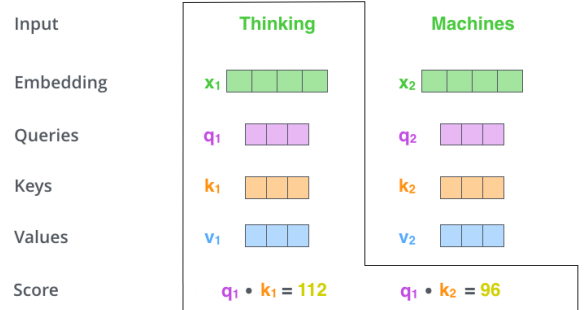
-
그 후 attention weight를 구한다.
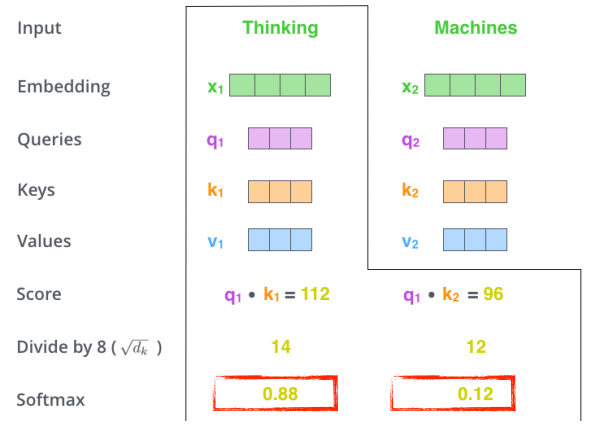
-
그 후 value vector와 가중합(weigthed sum)을 수행한 후 합한 값이 self-Attention을 이용한 encoding vector가 된다.
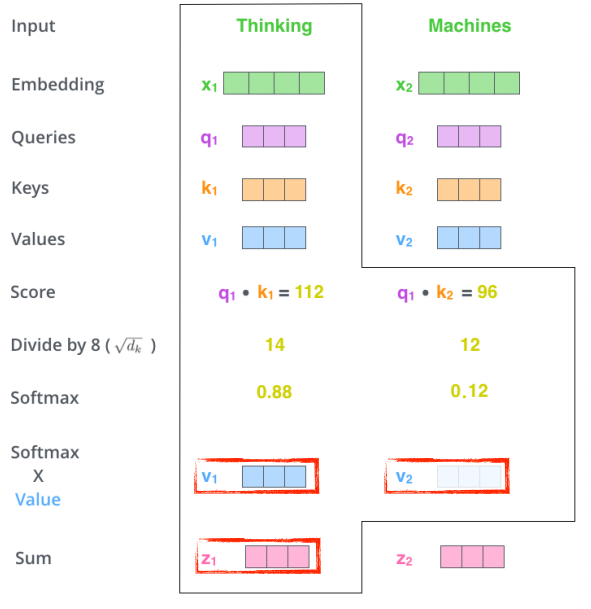
- 왜 이게 잘될까?
이미지 하나가 주어졌을 때, 입력이 고정되어 있을때, CNN, RNN등으로 수행하면 output이 고정된다. convolution filter나 weight가 고정되어 있기 때문이다. Transformer는 입력이 고정되어 있다고 하더라도, 내가 encoding하려는 단어와, 다른 단어들에 따라서 encoding된 값이 달라지게 된다. 즉 MLP보다 더 flexible한 모델이다. 훨씬 더 많은 표현을 할 수 있다.
하지만 이것은 attention map을 만들어야 한다. 즉, 한번에 처리하고자 하는 단어가 1000개라면, 1000 X 1000의 입력을 처리해야한다는 뜻이다. 따라서 문장의 길이에 따라서 transformer는 한계가 있다.
- Multi-headed attention은 attention을 여러번 하는 것이다. query, key, value vector를 여러개 만드는 것이다.
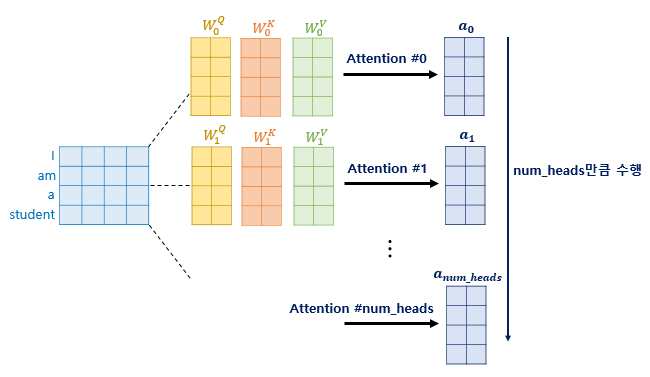
이것을 하면 n개의 encoding된 vector가 나오게 된다. 이를 모두 연결한다.
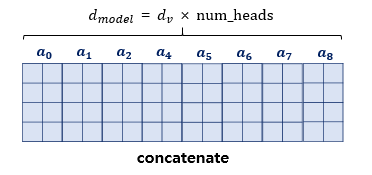
이를 와 곱해 차원을 줄일 수 있다.

- positional encoding
A,B,C,D라는 단어를 넣거나 D,A,C,D 단어를 넣거나 순서를 바꾸어 넣어도 각각의 A, B, C, D단어의 encoding된 값은 모두 같게 나온다. 그렇기 때문에 문장을 만들 때는 positional encoding을 수행하게 된다.
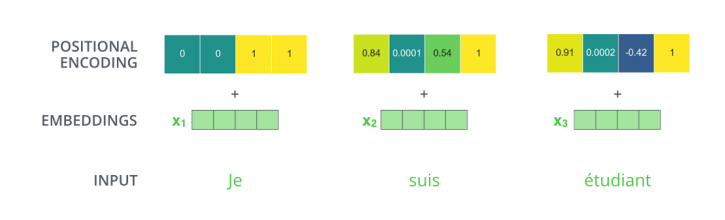
- 2020년 7월 기준 positional encoding
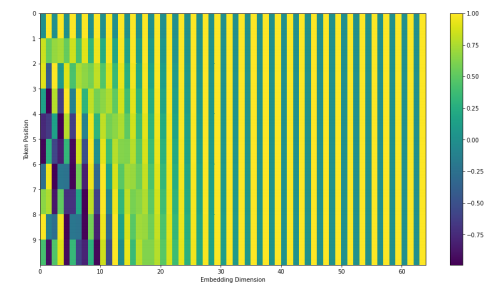
- 2020년 7월 기준 positional encoding
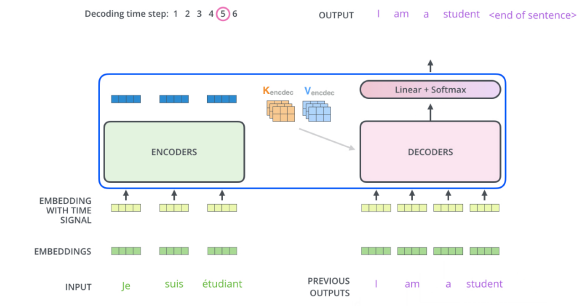
transformer는 key vector, value vector를 보내게 된다. decoders에서는 하나의 단어씩 autoregressive하게 출력하게 된다
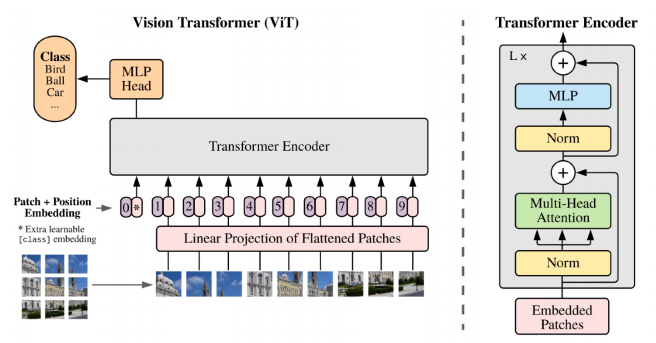
Transformer는 이미지 domain에도 많이 활용하고 있다. 이미지 분류를 하게 될때 encoder를 활용하게 된다.
DALL-E는 문장이 주어지면 이미지를 만들어내는 엄청난 기술이다.
GPT-3를 사용하였다고 한다.

