1. introduction
본 게시물은 dacon에서 주관하는 “도배 하자 유형 분류 AI 경진대회”에 참가한 나의 후기이자 대회를 진행하면서 수행한 것들을 정리한 글이다.
본 대회의 주최자인 한솔데코는 주택 내 실내 마감재 공사를 수행하는 회사로 시트와 마루, 벽면, 도배 등 건축에서 핵심적인 자재를 유통하고 있다. 실내 마감재는 건축물 내부 공간의 인테리어와 쾌적한 생활을 좌우하는 만큼, 제품 결함에 대한 꼼꼼한 관리 역시 매우 중요하다. 이를 위해 한솔데코에서는 AI 기술을 활용하여 하자를 판단하고 빠르게 대처할 수 있는 방안을 모색하고자 한다. 총 19 가지의 도배 하자 유형을 정확하게 분류해 낼 수 있는 AI 모델을 개발하는 것이 본 대회의 목적이다. 대회는 2023/04/10 부터 2023/05/22 까지 진행했으며 총 1025 팀이 참가했다.
2. dataset
대회에서 제공한 데이터셋은 학습 폴더와 평가 폴더로 나뉜다. 학습 폴더에는 “훼손, 오염, 걸레받이수정, 꼬임, 터짐, 곰팡이, 오타공, 몰딩수정, 면불량, 석고, 수정, 들뜸, 피스, 창틀, 문틀수정, 울음, 이음부불량, 녹오염, 가구수정, 틈새과다, 반점”의 19 가지 도배 하자 유형으로 나뉘어진 이미지 데이터가 존재한다, 평가 폴더는 792 개의 이미지 데이터가 레이블 없이 존재한다. 학습 폴더의 데이터로 모델을 학습시킨 후 평가 폴더의 데이터를 추론한 파일을 제출하면 대회의 평가 방식에 따라 점수가 산출된다. 평가 방식은 전체 평가 폴더 데이터에 대한 Weighted F1 Score 로 샘플 수의 비중에 따라 가중평균한 점수이다.

3. baseline
대회에서 제공한 baseline model 은 EfficientNet B0 이다. Optimizer 는 Adam, batch size 는 32, Epoch 은 10, Learning Rate Schedular는 ReduceLROnPlateau, Loss function은 Cross Entropy Loss를 사용했다. Baseline score 는 49.57 으로 우리는 성능 개선을 위해 모델, hyper-parameter, 학습 프로세스 등을 바꿔가며 실험을 진행했다.
4. method
4.1 model
Baseline 으로 사용되었던 Efficient B0 는 EfficientNet 버전 1 으로 Image Classification Task 에 대해 기존보다 훨씬 적은 파라미터 수로 SOTA 를 달성한 모델이다. channel width, depth, resolution Scaling 을 높이는 최적의 조합을 AutoML 을 통해 찾아내, 효율적인 compound scaling 방법을 제안했다. 하지만 버전 1 은 기본 단위인 MBConv 블록에 포함된 depthwise convolution 연산이 병목을 발생시키고, compound scaling 과정에서 불필요하게 모델을 키운다는 단점이 존재한다.
버전 1 의 단점을 개선한 EfficientNet 버전 2 는 dropout, RandAugment, Mixup 의 세가지 adaptive regularization 만을 적절하게 사용하여 정확도를 보정했다. 또한 Depthwise convolution 대신 일반 convolution 을 사용하는 Fused-MBConv 블록을 제안하며 연산의 효율성을 높였다. EfficientNet v2 는 파라미터 수에 따라 S, M, L, XL 로 나뉘는데 우리가 사용하는 데이터셋은 크기가 작으므로 small model 을 사용했다. 최종적으로 우리가 사용한 모델은 EfficientNet v2 s 로 timm 에서 pretrained model 을 가져와 사용했다.

4.2 stratified k-fold
대회에서 주어진 학습 데이터셋에는 클래스 간 불균형이 있었는데 “훼손” 유형은 1404개인 반면, “반점” 유형은 3개밖에 존재하지 않았다. 이렇게 일부 클래스에 데이터가 몰려있고 대부분의 클래스에는 데이터가 적게 분포한 데이터셋을 “long tailed dataset”이라고 한다.
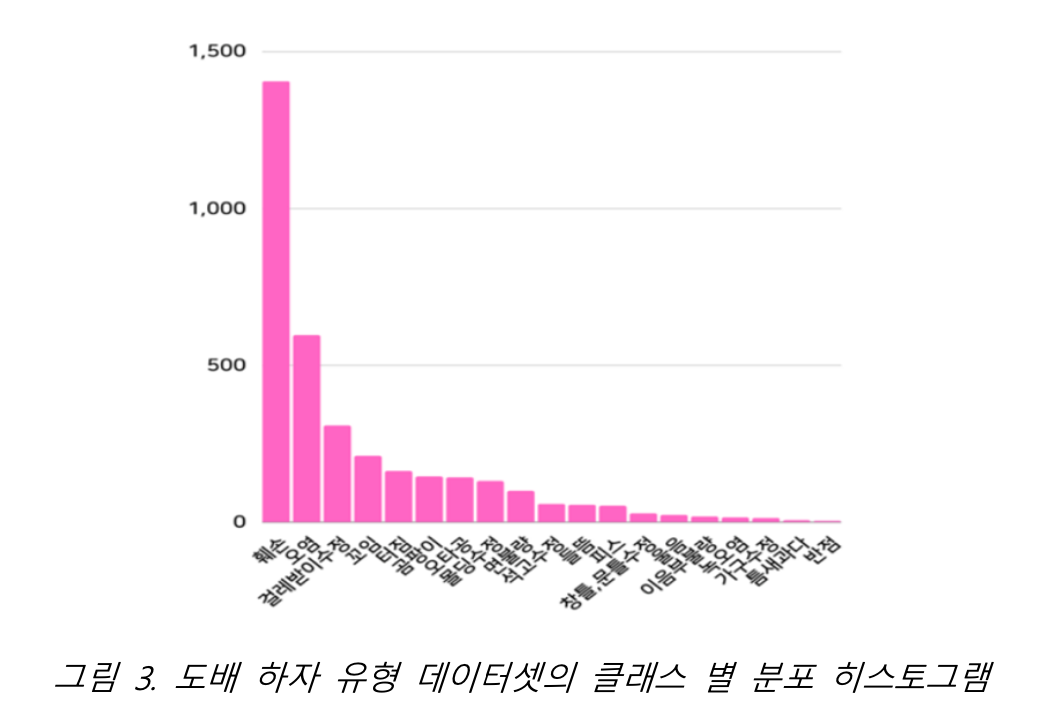
클래스 불균형이 심한 데이터셋을 학습할 때, train dataset에서 training set과 validation set을
일반적으로 나누는 것처럼 나누게 되면 적은 데이터를 가진 클래스를 잘 학습하지 못하는 상황이 종종 발생한다.
이를 해결하기 위해 자주 쓰이는 학습법인 k-fold는 train dataset의 모든 데이터를 학습에 이용할 수 있다. k-fold는 train dataset에서 각각 다른 데이터를 validation set으로 가지는 k개의 foldsets를 만들고 k번만큼 각 sets에 학습과 검증 평가를 수행한다. 하지만 k-fold 역시 하나의 fold를 구성할 때, 클래스의 비율을 고려하여 training set과 validation set를 구성하지 않기 때문에 클래스 불균형이 있는 데이터셋을 효과적으로 학습시키지는 못한다.
그래서 우리는 k-fold에서 발전한 stratified k-fold 방식을 채택해서 학습을 진행했다. Stratified k-fold는 클래스 비율을 고려하여 training set과 validation set을 나누어 foldsets을 만들기 때문에 클래스 불균형을 해소하고 모든 train dataset을 학습에 이용할 수 있다는 장점이 있다.
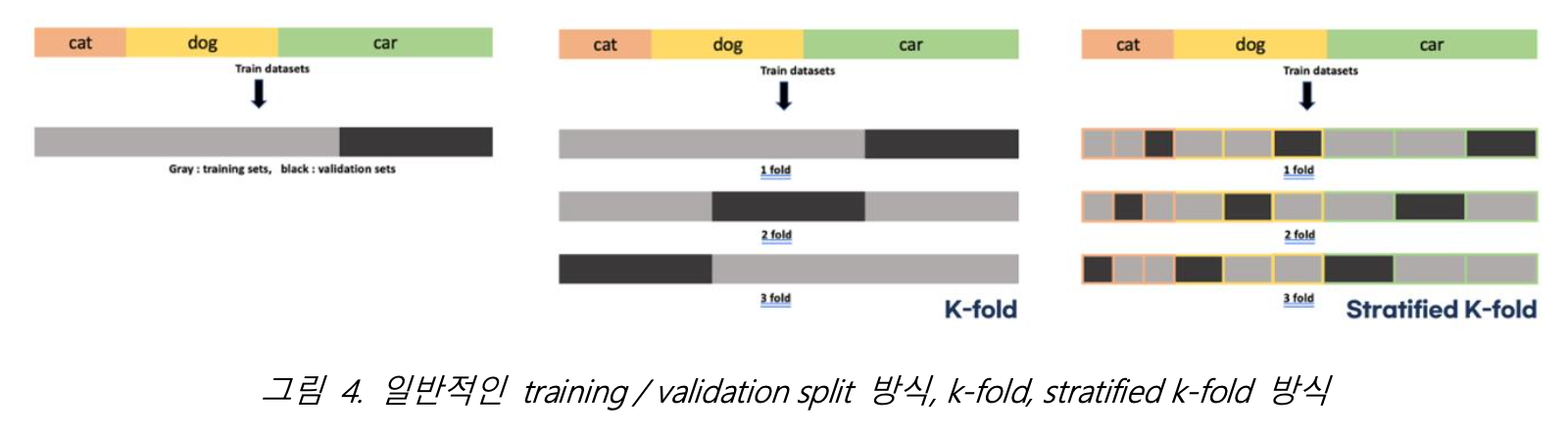
Stratified k-fold 방식으로 모델을 학습시킨 후에는 각 foldsets에서 학습한 모델들의 예측 결과를 평균내어 최종 예측으로 채택하는 앙상블 방식을 사용했다. Stratified k-fold 방식을 사용하면 계산량이 k배 증가하지만 우리의 목적은 더 좋은 예측을 얻는 것이므로 해당 기법을 사용해 학습을 진행했다.
4.3 hyper-parameter
Data augmentation은 딥러닝 모델의 과적합을 방지하기 위한 용도로 종종 사용된다. 학습 시 사용한 augmentation은 HorizontalFlip과 VetricalFlip, RandomRotate와 Color Jitter, ShiftScaleRotate이다. Training과 Test에 모두 적용한 Augmentation은 Resize와 Normalize가 있다.
Learning rate는 모델의 성능에 가장 중요한 영향을 끼친다고 알려져 있다. 이전에는 learning rate를 고정값을 사용했지만 요즘 추세는 학습 과정에서 learning rate를 조정하는 learning rate scheduler를 사용하는 것이다. 우리는 그 중에서도 learning rate가 cosine 모양으로 다이나믹하게 변화하는 cosine annealing을 사용했다.
추가로 학습에 사용된 hyper-parameter는 batch size 16, epoch 10, Adam optimizer, cross entropy loss function이다.
5. result
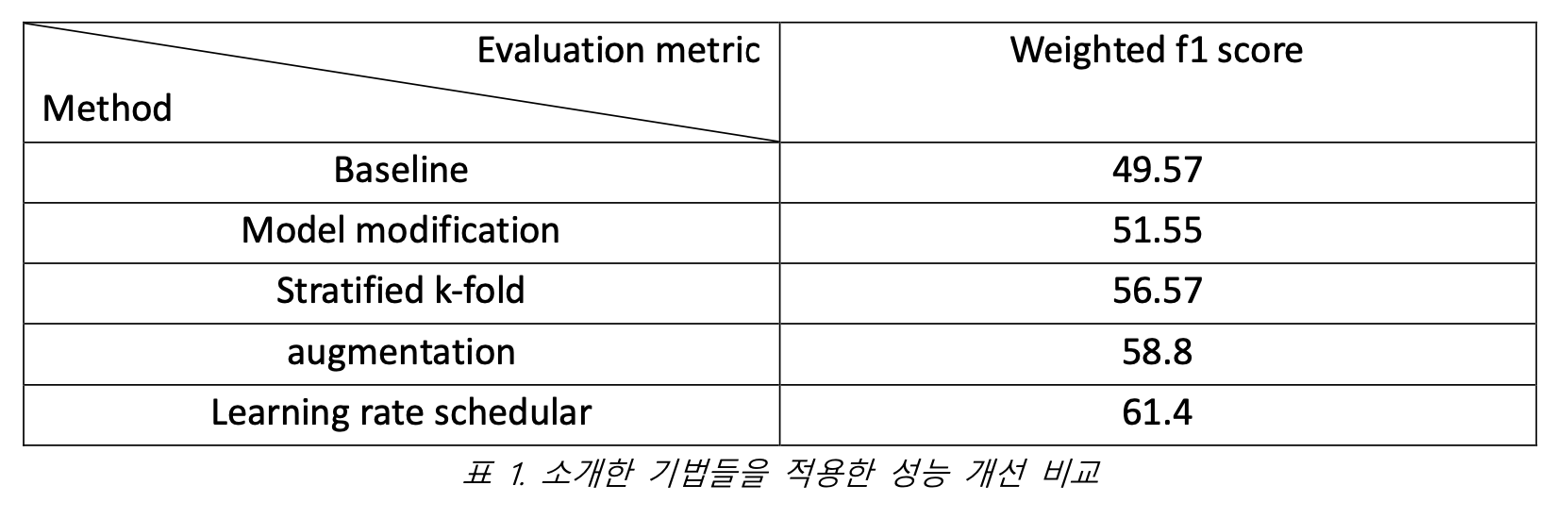
대회에서 주어진 baseline model로 학습을 진행한 후 테스트 데이터를 추론한 결과를 제출했을 때의 점수는 49.57이다. 앞에서 소개한 다양한 기법들을 적용하여 학습하고 추론한 점수는 61.4로 전체 1025개 팀 중 130등이라는 성적을 거두었다. 소개한 기법들을 적용했을 때 개선된 성능 점수는 표 1에 정리되어 있다.
A. appendix
해당 section에서는 성능이 개선되지 않아 최종 결과에 채택되지 않은 기법들에 대해 설명한다.
A.1 weighted random sampling
클래스 불균형을 해소하기 위해 균형있게 배치를 구성하는 방식을 Re-sampling이라고 한다. 그 중에서도 각 클래스 이미지가 뽑힐 확률을 동일하게 설정하는 weighted random sampling 방식을 사용했다. Weighted random sampling은 각각의 이미지 데이터 한 장이 뽑힐 확률을 계산한다. 이후 확률값이 작은 이미지를 가진 클래스는 더 많이 뽑히고, 확률값이 큰 이미지를 가진 클래스는 더 적게 뽑히도록 배치를 구성한다. 그러므로 전체적으로 각 클래스 이미지가 뽑힐 확률이 동일하게 된다. 하지만 데이터가 중복으로 뽑히는 단점이 있기 때문에 헤당 기법을 적용했을 때 오히려 모델 성능이 떨어졌다.
A.2 class-balanced loss
샘플링으로 클래스 불균형을 해소하는 방식은 위에서 설명한 것 같은 단점때문에 잘 사용되지는 않는다. 그러므로 Minor class에 더 큰 가중치를 주는 Re-weighting 방식을 사용해 실험을 진행해봤다. Minor class는 다양한 관점에서 해석될 수 있는데 weighted cross entropy는 샘플의 개수로 minor 정도를 판별하는 반면, focal loss는 샘플의 난이도로 minor 정도를 판별한다. 하지만 샘플의 개수와 샘플의 난이도는 서로 관계가 있지 않으므로 두 방식 중 하나를 사용하는 것은 좋지 않다. 예를 들어 모델이 어려워하는 샘플이 반드시 적은 개수의 클래스인 것은 아니다.
Class-Balanced Loss (이하 CB loss)는 이와 같은 문제를 해결하기 위해 Effective Number라는 개념을 도입했다. Effective Number는 데이터 간 overlap하는 정보의 양을 의미한다. CB loss는 기존 loss function에 effective number의 역수를 곱해준 loss function이다. CB loss의 장점은 모든 loss function에 effective number의 역수만 곱해주면 적용할 수 있다는 점이다. CB loss를 적용해 실험을 진행한 결과 모델 성능이 떨어져 해당 기법은 사용하지 않았다.
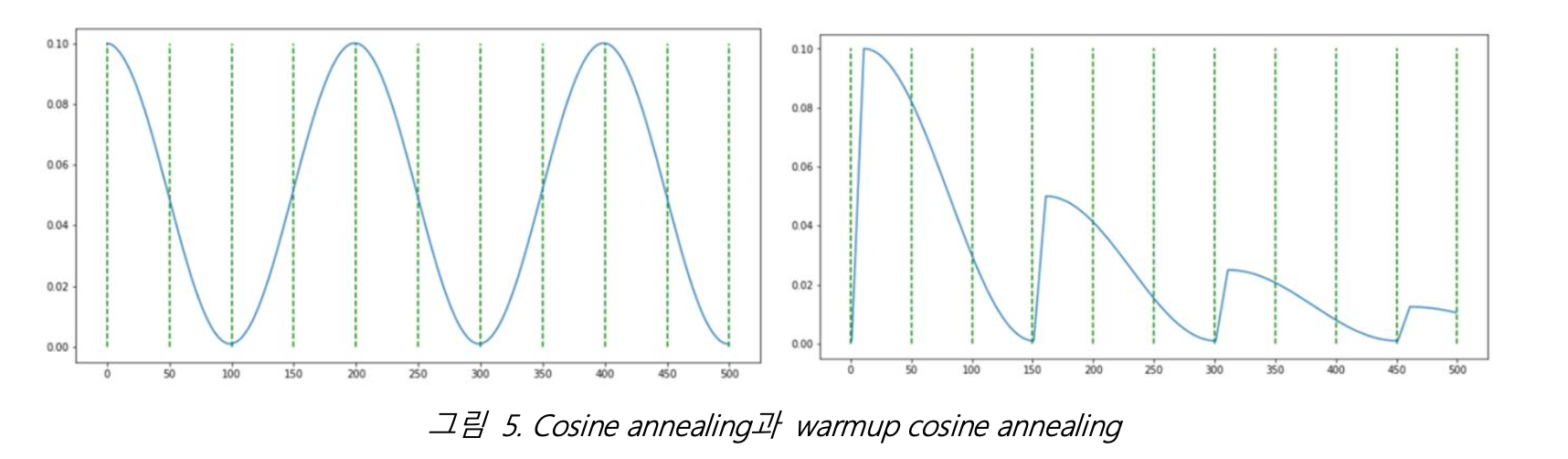
A.3 warmup cosine annealing
Hyper-parameter tuning 과정에서 통상적으로 배치 크기를 2배 키운다면 learning rate를 2배 키워야 성능이 떨어지지 않고 학습이 잘 이루어진다. 하지만 초반에 너무 큰 learning rate는 loss를 발산하게 할 가능성이 있다. 그렇기 때문에 학습 초반에는 learning rate를 0부터 설정한 수치만큼 올린 후 이후 scheduler에 맞게 조정하는 warmup 방식이 사용된다. 그래서 4.3절에서 채택한 cosine annealing의 warmup이 추가된 scheduler를 사용해 학습을 진행해보았다. Warmup cosine annealing은 learning rate가 감소 후 급격하게 증가하게 함으로써 local optima에 빠지는 것과 overfitting을 방지하는 효과가 있다.
reference
[1] Baseline
https://dacon.io/competitions/official/236082/codeshare/7887
[2] Weighted Random sampler
https://www.maskaravivek.com/post/pytorch-weighted-random-sampler/
[3] stratified k-fold
https://dacon.io/en/codeshare/4546
[4] Albumentation
https://gaussian37.github.io/dl-pytorch-albumentation/
