[혼공머신] 5-1. 결정 트리
혼공머신

Intro.
신상품으로 캔 와인을 출시하려는 한빛 마켓! 야심차게 와인을 제작했는데...
김 팀장🗣️ "하.. 레드와인인지 화이트와인인지 표시가 누락됐어.. 캔에 인쇄된 알코올 도수, 당도, pH 값으로 와인 종류를 구별할 수 있겠어?"
1. 로지스틱 회귀의 단점
그냥 레드/화이트 이진분류니까, 전에 배운 로지스틱 회귀모델로 분류하면 되겠군! ㅋ
데이터 준비
- 이번에도 pandas로 데이터 불러오고, 몇 가지 살펴보기
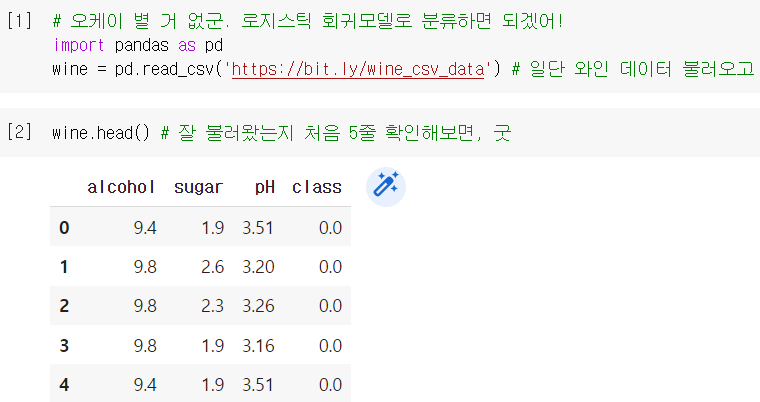
.info(): 데이터 타입, 누락 여부, 메모리 크기 등의 기본 정보를 보여주는 메소드
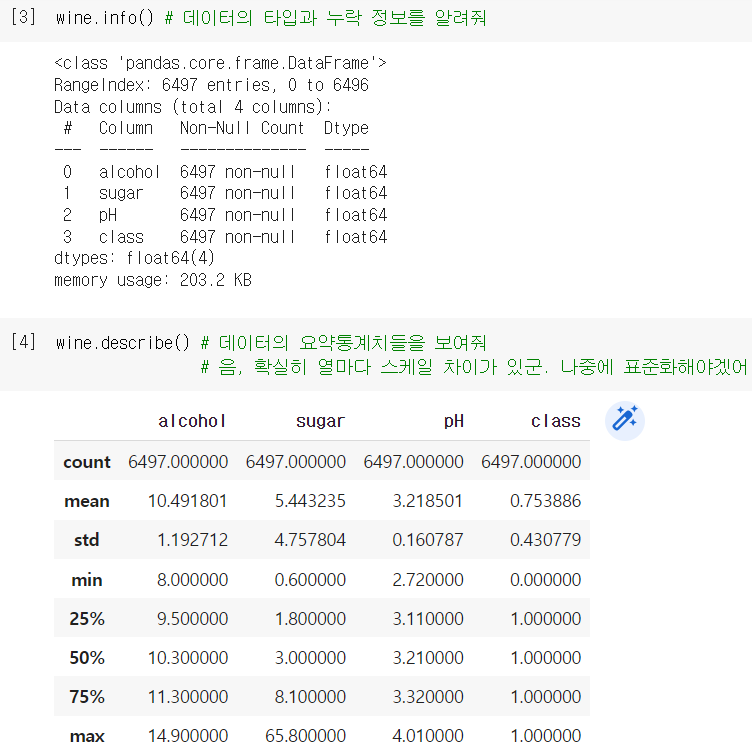
.describe(): 각 열마다 간략한 통계치들을 출력해주는 메소드
- 기본적인 설정 및 전처리 (
test_size: 떼어내는 테스트 세트의 비율 설정)

모델 훈련
- 로지스틱 회귀모델로 와인 이진 분류 수행
 점수가 썩 높진 않네..
점수가 썩 높진 않네.. C를 늘려봐야 하나? 아님slover로 다른 알고리즘 써봐?
일단 회귀방정식을 바탕으로 이사님께 보고드려보자 ...

로지스틱 회귀의 단점
이사님🗣️"저 숫자들이 대체 무슨 의미죠..? 순서도처럼 쉽게 설명해서 다시 가져와요."
- 로지스틱 회귀모델은 계수와 절편을 학습하지만, 그 숫자들이 정확히 어떤 의미인지 설명하기는 쉽지 않음.
ex) "알코올 도수*0.512720274 + 당도*1.6733911 - pH*0.68767781 + 1.81777902를 계산한 값이 0보다 크면 화이트와인입니다..!" 🤷🏻♂️ - 다항 특성을 추가한다면 더 어려워짐. 이를테면, 또는 같은 특성을 뭐라 설명할 것인가...
2. 결정 트리
홍 선배🗣️ "결정트리 알고리즘을 써 봐. 스무고개처럼 질문을 하나씩 던져서 정답을 찾아가는 방식이라서, 이유를 설명하기 훨씬 쉬울 거야!"
결정트리 모델 훈련
DecisionTreeClassifier(): 데이터를 잘 나눌 수 있는 질문을 찾는 알고리즘

plot_tree로 그림도 그려볼 수 있음. (위에서부터 질문따라 아래로 내려감)
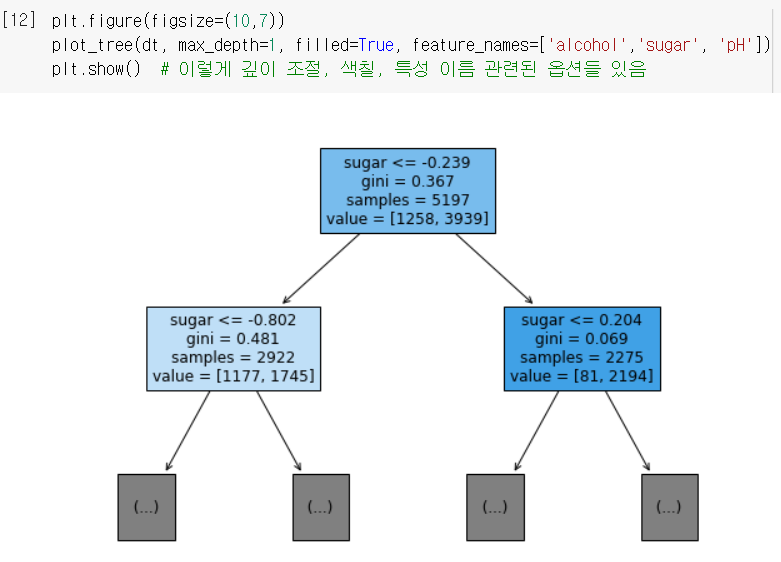
- 너무 복잡하니까 트리의 깊이를 제한해서 다시 그려봄.
max_depth: 루트 노드 밑에 몇 층을 더 그릴지 설정하는 매개변수
filled: 클래스의 비율에 맞게 노드를 색칠해주는 매개변수👍🏻
feature_names: 특성의 이름을 전달하는 매개변수 (없으면 'sugar'가 아니라 'x[1]'로 나옴)
 (트리 그림을 읽는 방법은 아래 '➕플러스 알파' 참조)
(트리 그림을 읽는 방법은 아래 '➕플러스 알파' 참조)
불순도
-
노드를 나누는 기준이 되는 수치로,
criterion매개변수로 설정 가능 (기본값:gini) -
- 불순도가 0.5인 경우 : 두 클래스가 정확히 반반으로 나눠져서 구분의 의미가 없는 최악의 노드
- 불순도가 0인 경우 : 노드에 한 클래스만 있는, 즉 완벽히 구분된 최선의 노드 = '순수 노드'
-
결정트리 모델은, 부모노드와 자식노드의 불순도 차이가 크도록 노드를 나눔.
이 차이를 '정보 이득'이라고 부르며, 노드를 순수하게 나눌수록 정보 이득이 커짐. -
❗물론 이 불순도를 우리가 직접 계산하는 건 아니고, DecisionTreeClassifier에서 불순도 차이가 크도록 알아서 노드를 분할시킨다는 거임!
가지 치기
- 위의 빼곡한 트리처럼 무작정 깊이 훈련시키면, 훈련세트에만 과대적합 되어버림.
(참고) 위의 트리처럼 깊이 제한이 아예 없으면, 리프노드가 순수노드가 될 때까지 하게 됨 - 그래서 '가지 치기'가 필요! → 가장 간단한 방법은
max_depth로 깊이 지정하기.
cf) 결정트리는 선형회귀처럼 가중치가 있는 게 아니라서 L1, L2 규제 같은 건 쓸 수 없음

- 그림으로 그려보니 훨씬 이해도 쉬워짐.
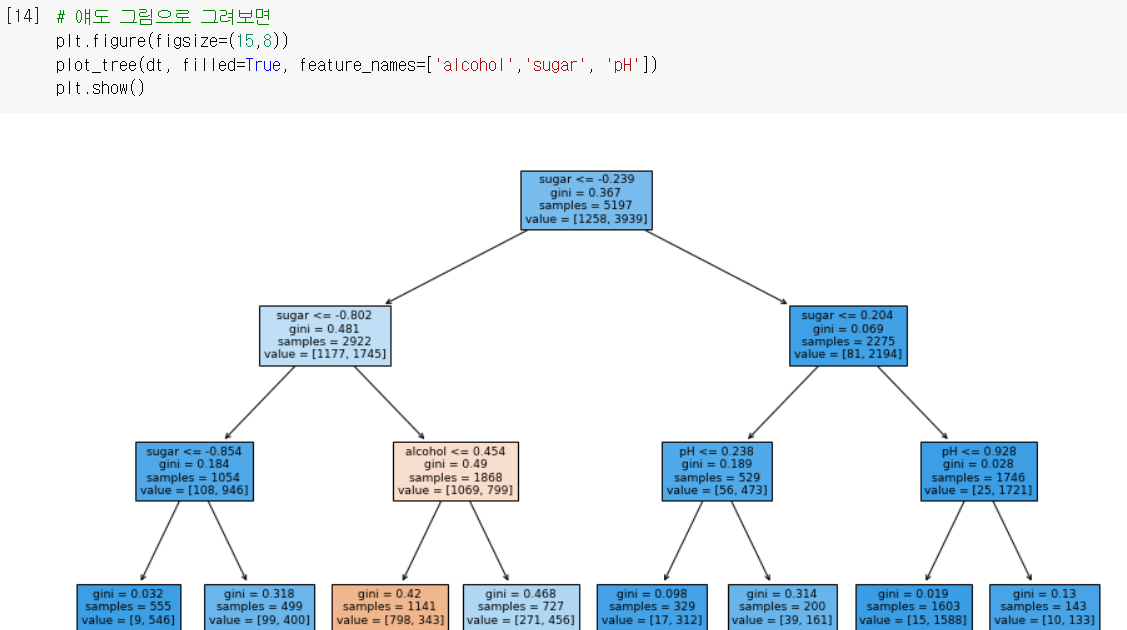 ↪ 왼쪽에서 3번째 노드에 도착하는 경우만 음성 클래스(red)로 예측!
↪ 왼쪽에서 3번째 노드에 도착하는 경우만 음성 클래스(red)로 예측!
↪ " 이면서 인 경우만 red로 분류되고, 나머지 경우는 white로 분류하는 모델이 완성됨!
결정트리의 장점
-
사실, 표준화 전처리가 필요 없음.
: 위의 결과를 보면 당도가 -0.802, 즉 음수로 설명되어있다. 그런데 불순도의 정의를 생각해보면 애초에 클래스별 '비율'을 가지고 계산한 거니까, 특성들의 스케일이 알고리즘에 영향을 미치지 못한다.
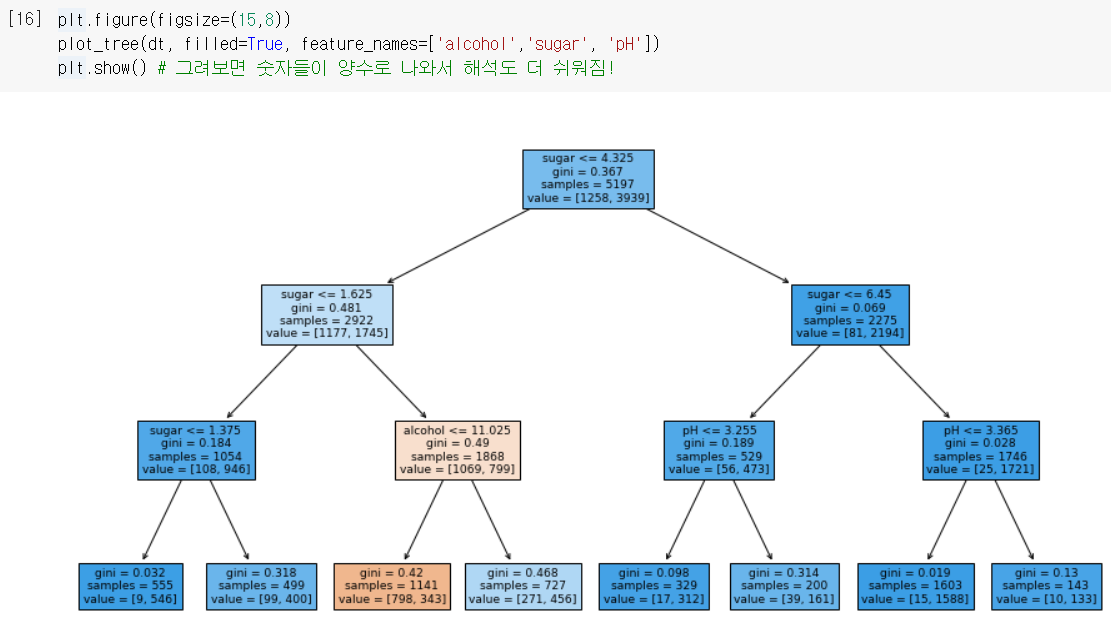
 전처리 안 한
전처리 안 한 train_input으로 다시 훈련해보면, 해석하기 더 쉬워지네!
↪ " 이면서 인 경우만 red로 예측!
-
특성 중요도(어떤 특성이 가장 유용한지)도 계산해줌. →
.feature_importances_
 깊이 0과 1에서 두번이나 sugar를 기준으로 하더니, 역시 sugar의 중요도가 높네!
깊이 0과 1에서 두번이나 sugar를 기준으로 하더니, 역시 sugar의 중요도가 높네! -
그래프를 직관적으로 이해하기 좋음.
: 특정 클래스의 비율이 높아질수록 색깔이 진해져서 어떤 노드가 어떤 클래스인지 한 눈에 보인다. 위의 경우엔 3번째 노드만 주황색으로 칠해져서, 이 노드만 음성 클래스이고 나머지는 양성 클래스라는 것을 쉽게 알아챌 수 있다. -
회귀모델보다 설명하기가 쉬움.
: (앞에서 말했듯이) 어떤 조건이면 어떤 클래스인지가 명확하게 구분되니 해석하기가 쉽다. 다만, 트리의 깊이가 너무 깊어지면 생각만큼 해석이 쉽지 않을 수 있다.
어쨌거나! 성능(score)이 아주 높진 않지만, 이사님께 보고하기 좋은 모델 완성!!
➕플러스 알파
➊ 트리 그림을 읽는 방법
- 새로운 샘플을 예측할 때, 맨 위에서부터 노드의 질문에 따라 내려감 (Y:왼쪽 / N:오른쪽)
→ 쭉 내려가서 마지막 노드(리프 노드)에 도착 → 그 노드(value)에서 다수인 클래스를 예측 클래스로 채택!
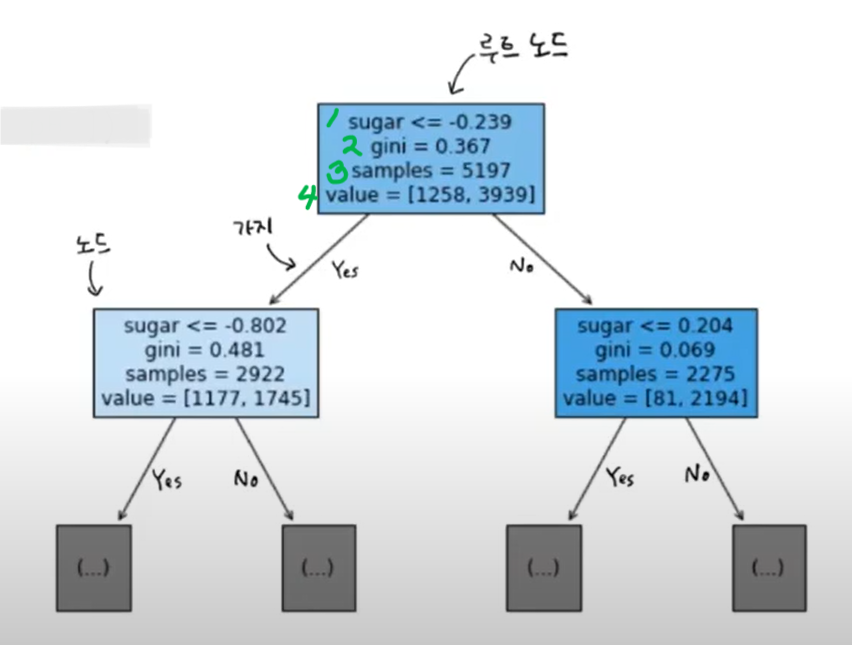 1) 테스트 조건 : sugar<=-0.239 이면 왼쪽으로 내려가고, 아니면 오른쪽으로 내려감.
1) 테스트 조건 : sugar<=-0.239 이면 왼쪽으로 내려가고, 아니면 오른쪽으로 내려감.
2) 불순도 : 본문 내 설명 참조.
3) 총 샘플 수 : 루트 노트에는 현재 5197개의 샘플이 들어있음.
4) 클래스별 샘플 수 [음,양] : 그 중에 1258개가 '레드와인'이고 3939개가 '화이트와인'임.
➋ 엔트로피 불순도
- '지니 불순도'는 (클래스 비율)을 제곱해서 사용했다면, '엔트로피 불순도'는 밑이 2인 로그를 사용한다. 자세한 계산 과정은 231p 참조.
- 보통 기본값인 '지니 불순도'를 더 많이 쓰는데, '엔트로피 불순도'로 만든 결과와 크게 차이나지는 않는다.
➌ 결정트리 모델의 딜레마
- <깊이에 제한을 두지 않고 끝까지 훈련시키면 score 점수가 매우 높게 나온다!
하지만, 훈련세트에 과대적합되는 문제가 생긴다...>⇅ <그래서 과대적합을 규제하기 위해 깊이를 제한하면, 성능(score)이 낮아진다...> - 그럼에도 결정트리가 중요한 건, 아주 강력한 성능의 '앙상블' 알고리즘의 기반이 되기 때문이다 !! (나중에 배울 내용)
➍ 확인문제 3번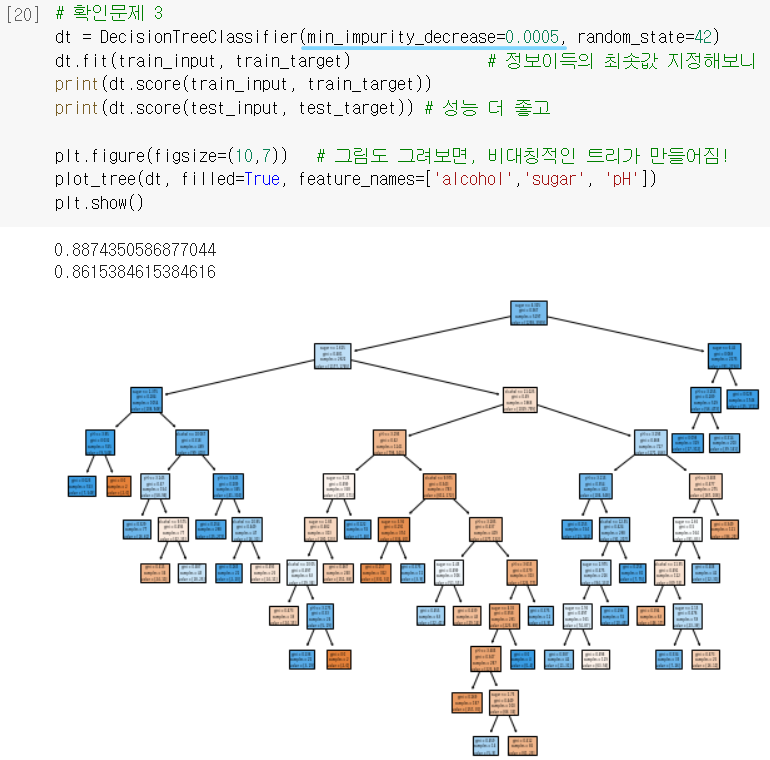
min_impurity_decrease: 어떤 노트의 정보이득이 여기서 설정한 값보다 작으면 더 이상 분할하지 않도록 하는 설정.
↪ 즉, 정보이득이 별로 없는 경우는 굳이 더 성장시키지 않겠다는 말!
= 가지치기의 일환으로 볼 수 있음 ㅇㅇ
🤔 Hmmmm...
239p. 특성중요도 설명을 보면 '불순도를 감소하는 데 기여한 정도'로 판단한다고 되어있는데 그 판단의 과정이 궁금합니다. 가령, 특성1로 해서 불순도 계산해보고 특성2로도 계산해보고 ... 그런 식으로 반복하는 걸까요?
230p. 결정트리를 회귀에 적용하면 DecisionTreeRegressor를 쓰면 된다고 되어있는데, 트리모델에서 회귀를 어떻게 구현할 수 있다는 건지 잘 와닿지 않습니다. 불순도라는 개념 자체가 ‘분류’의 성능을 판단하는 척도인데 어떻게 이걸로 특정 가중치를 예측할 수 있는 거죠..?
이야.. 결국 이것도 최소제곱법이었구나..^^ 알아낸 내용은 여기에 따로 정리해둬야지! 손수 찾아낸 나에게 칭찬을..!👏🏻 🆗
229p. 결정트리 모델이 음/양 분류해주는 건 알겠는데요, 이 경우에 양성클래스가 화이트인지는 어떻게 아나요..? target 값 정해주면 알아서 판단하는 건가.......
❗불순도라는 개념은, 트리가 알아낸 기준대로 분류했을 때 불순물이 얼마나 섞여있는가 = 일종의 분류 오차수준 정도로 생각하면 좋을 듯! → 그러니까 작을수록 좋은 값인 게 당연!🆗
🤓 To wrap up...
처음에 노드 읽는 법과 불순도 계산과정이 복잡해보여서 겁먹었는데, 배우고 보니까 전혀 그렇지 않고 오히려 정말 직관적이고 편리한 모델이었다! 4장에서 고생하다가 간만에 이해 잘 돼서 기분 좋은...ㅎㅎ 추가로 결정트리를 기반으로 한다는 '앙상블' 알고리즘이 엄청나다고 스포해주셨는데, 상당히 기대가 된다..!
신상품 '캔 와인' 출시! 근데 레드/화이트 와인 표시가 누락 → 알콜 농도, 당도, pH 값을 바탕으로 레드/화이트 여부를 분류해야 함 (이진분류) → ① 로지스틱 회귀모델로 분류함! → but 이사님 왈 "뭔 소린지 이해할 수 없어!" → ② 새로운 알고리즘, 결정트리 모델을 사용 → 불순도를 기준으로 노드를 분할하며 아래로 내려가서, 최종 노드를 보고 클래스 예측! → 질문을 통해 클래스를 찾아가는 과정이 직관적으로 그려짐! + 성능(score)도 더 높게 나옴! → 과대적합은 가지치기로 해결!
