[혼공머신] 5-2. 교차 검증과 그리드 서치
혼공머신

Intro.
결정트리 모델로 와인 구분하는 모델 완성! max_depth 바꿔가면서 성능 테스트 여러 번 해서 최적의 모델을 찾아야지 ㅎㅎ 그런데...
이사님🗣️ "최적의 모델을 찾는 건 좋은데, 그 과정에서 자꾸 테스트 세트로 평가를 하면 테스트 세트에만 잘 맞는 모델이 되어버리는 거 아닌가요?" ㅇ ㅠㅇ
1. 검증세트와 교차검증
해결책은 생각보다 간단했다. 테스트세트 말고, 따로 검증용 세트를 또 준비하면 된다!
검증세트
- 원래는 훈련/테스트만 나눴지만, 이젠 훈련/검증/테스트 3개로 나눔. (보통 20%)
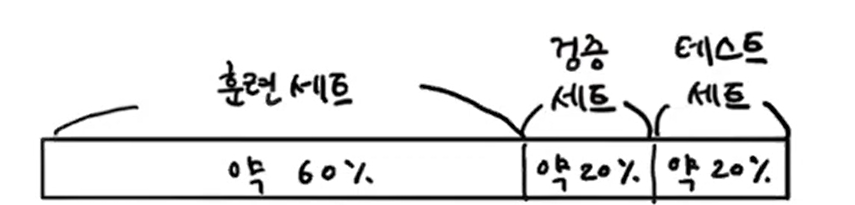
- ☝🏻일반적인 활용 과정
1) 모델을 훈련세트로 훈련(fit)하고, 검증세트로 평가(score)한다
2) 매개변수 바꿔가며 score 점수 가장 좋은 모델을 고른다
3) 최적의 매개변수로, 훈련세트+검증세트 합친 걸 다시 훈련(fit)한다
4) 그리고 맨 마지막에 테스트세트로 최종 점수(score)를 평가한다
검증세트를 활용한 모델 평가
- 항상 하던대로 훈련/테스트세트 분할까지 하고 나서

- 여기서 한 번 더
train_test_split을 사용 = 검증세트 분할

- 그러고 나서 모델 평가할 때 이렇게 (
test말고)val로 하면 되는 거임!

검증세트의 문제점
- 보통 많은 데이터를 훈련할수록 좋은 모델이 만들어지는데, 테스트세트에 이어 검증세트까지 떼어내면 훈련할 세트가 줄어듦..
- 그렇다고 검증세트를 조금만 떼어내자니, 너무 작은 표본으로 평가한 검증 점수라 신뢰성이 떨어짐..
↪ 그래서 나온 것이 바로 ...!
교차 검증
- 훈련세트에서 검증세트를 한번만 떼어내는 게 아니라, 훈련세트를 조각내놓고
그 조각들이 번갈아가면서 검증세트가 되도록 하는 방식. - 그 조각을 '폴드'라고 하며, 보통 5-폴드 혹은 10-폴드 교차검증을 많이 사용함.
- 이러면 데이터의 8-90%까지 충분하게 훈련을 돌릴 수 있고(문제점1 해결), 검증점수도 모든 폴드 경우의 평균으로 구하니까 비교적 안정된 점수로 생각 가능!(문제점2 해결)
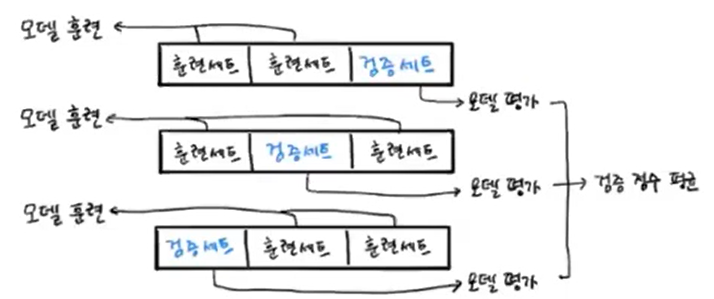
교차검증을 활용한 모델 평가
cross_validate(): 사이킷런에서 제공하는 교차검증 함수!
직접 검증세트 떼어낼 필요 없이, 1차로 떼어낸 훈련세트를 전달만 하면,
알아서 검증세트 떼어내고 그걸 폴드마다 바꿔가면서 모델을 평가까지함!cv: 이 매개변수로 폴드 수를 지정할 수도 있음. (기본값 = 5)

- 각 폴드별 검증 점수는 'test_score'에 반환되어 있고, 그 점수들을 평균 내면 교차검증의 최종 점수가 되는 거임! (※ test라고 적혀있지만 테스트세트의 점수가 아니니 주의 ※)
 ➕ 참고로, 교차검증은
➕ 참고로, 교차검증은 train_test_split처럼 알아서 훈련세트를 섞어주지는 않음.
훈련세트를 섞으려면 따로 '분할기'를 지정해줘야 함. (플러스알파 참고)
2. 하이퍼파라미터 튜닝
지금까지의 학습 내용
- 모델이 학습하는 변수를 '모델 파라미터'라고 하고, 모델이 학습하는 게 아니라 사용자가 지정해줘야 하는 변수를 '하이퍼파라미터(=매개변수)'라고 함.
- 매개변수(ex.
alpha)를 바꿔가면서 score 보면서 최적의 매개변수를 찾으면 되고, 이 과정은 테스트세트가 아닌 검증세트로 해야 함.
✌🏻그런데 여기서 짚고 넘어가야 할 포인트가 두 가지 있다.
Point① 그럼 우리가 매개변수 바꿔가면서 일일이cross_validate하고 있어야 하나?
Point② 사실, 매개변수들의 최적값은 순차적으로 찾을 수 없게 되어있다. 이를테면, max_depth 최적값 찾아서 고정해놓고 그 다음으로 min_samples_split을 바꿔가면서 찾는 것이 불가능하다. 매개변수 상호 간에 영향을 끼치기 때문이다.
그렇다면,
동시에 매개변수를 바꿔가며 최적의 값을 찾는 이 복잡한 과정을 어찌할 것인가?
그리드 서치(Grid Search)
- 사이킷런은 친절하게도, 하이퍼파라미터 탐색(최적의 매개변수 탐색)과 교차검증을 한 번에 수행해주는 클래스를 제공한다! =
GridSearchCV() params: 딕셔너리 형태로 탐색할 매개변수 후보들을 전달하기 위해 사용한 변수
(꼭 'params'일 필요는 없고 이름은 자기 정하기 나름)
n_jobs: 작업에 사용할 CPU 코어 수를 지정하는 매개변수 (기본값=1)
(-1로 하면 모든 코어를 사용 → 아무래도 컴퓨터 좀 느려짐..^^)

.best_params_: 찾아낸 최적의 매개변수가 저장된 곳
.best_estimator_: 최적의 매개변수 조합으로 훈련시킨 최적의 모델이 저장된 곳

- 각 매개변수 후보들에서 수행한 교차검증의 평균 점수는
.cv_results_딕셔너리의 'mean_test_score' 키에 저장되어있음.
↪ 그 중에 제일 큰 값의 인덱스를.argmax()로 꺼내고, 'params' 키를 거쳐서, 최적의 매개변수를 뽑아볼 수도 있음. ([14]의 값을 좀 돌아 돌아 얻어낸 느낌..!😅)

더 많은 매개변수를 탐색해보고 싶다면?
- 넘파이의
np.arange()함수와 파이썬의range()함수를 활용

- 역시 그리드서치가 최적의 매개변수 조합 & 검증점수를 구해줌.

✌🏻그런데, 여기서 또 한 번 아쉬운 점이 두 가지 있다.
Point① 위에서 매개변수 후보 간격들을 0.001, 1, 10으로 했었는데, 굳이 이렇게 간격을 둔 것에 대한 특별한 근거가 없다.
Point② 또, [17] 직접 해보면 알겠지만, 너무 많은 매개변수 조합이 있어서 그리드서치 수행 시간이 오래 걸릴 수 있다. (위 예시는 무려 9*15*10*5=6,750 가지나 있었다)
랜덤 서치(Random Search)
- 매개변수의 범위나 간격을 미리 정하기 어려우니, 그냥 넓은 범위를 던져주고 "이 안에서 랜덤하게 매개변수들 뽑아서 해보고, 최적인 걸 찾아줘!" =
RandomizedSearchCV()
➕사이파이 라이브러리의uniform과randint클래스를 활용하면 됨. (플러스알파 참조)

- 대부분의 구성은 그리드서치와 동일한데,
n_iter로 샘플링 횟수 지정해줘야 함.

- 그리드서치보다 더 넓은 영역을 무작위로 탐색하면서, 교차검증 수는 줄였음!
(최적의 매개변수 조합 & 검증 점수도 그리드서치와 동일하게 계산)

- 이렇게, 검증세트로 필요한 검증 다 하고 나면, 마지막에 딱 한 번만!!! 테스트세트 확인!

점수(score)가 아주 만족스럽진 않지만 어쨌든 다양한 매개변수 테스트해냈다..! 앞으로는 일일이 매개변수 안 바꾸고 그리드서치나 랜덤서치 쓰면 되겠어~!
➕플러스 알파
➊ 교차검증 분할기
- 위에서 말했듯이 (폴드 나눌 때) 훈련세트를 섞기 위해서는 분할기가 필요함.
cross_validate()는 기본적으로 회귀모델일 경우KFold()분할기를 사용하고,
분류모델일 경우StratifiedKFold()분할기를 사용함.

- 만약 더 디테일하게 훈련세트를 섞고 교차검증을 수행하고 싶다면,
아래처럼 분할기 객체를 아예 따로 만들고 그걸cross_validate안에 넣어줘도 됨!
n_splits: 몇(k) 폴드 교차검증을 할지 설정하는 매개변수

➋ 균등분포 샘플링 (=난수 발생기)
- 사이파이 stats 패키지에 있는 클래스로, 주어진 범위 내에서 랜덤+균등하게 숫자를 뽑음!

randint(a,b): a 부터 b-1 중에 랜덤한 정수값을 뽑음.
.rvs(n): n개를 샘플링 해줌(뽑아줌).

uniform(a,b): a~b 사이에서 랜덤한 실수값을 뽑음.

🤔 Hmmmm...
254p. 랜덤서치에서
n_iter=100이라는 건, 매개변수 각각을 100개씩 뽑아서 조합해본다는 게 아니라, 랜덤하게 100가지의 조합을 구해본다고 보면 되나요? 그래서 그리드서치보다 검증 수가 줄어든 거라고 보는 거죠? ⏯️(맞을듯)
🤓 To wrap up...
자꾸 문제상황들이 연이어 제시되면서(검증세트 단점 있음 - 교차검증! - 근데 교차검증도 단점 있음 - 그리드 서치! - 근데 그리드서치도••• 이런 식..^^) 처음엔 되게 복잡하게 느껴졌는데, 다시 큰 줄기를 잡으면서 복습하니까 괜찮네! 새로운 도구들을 알아갈수록 어떻게 한참 전에 이미 이런 생각들을 하고 이미 라이브러리로 구현까지 해놨는지 놀라울 따름이다... 지금은 돈방석에 앉아계시겠지..? 열심히 하자 흑흑
와인 구분하는 결정트리 모델 만들었지만, '테스트 세트에만 맞춰진 거 아니냐'는 이사님의 일침 → 검증 세트 추가 → but 검증세트까지 떼어내는 부담 있음 → 교차검증으로 극복! → 근데 매개변수를 바꿔가면서 평가하는 과정이 지루하고 복잡해짐ㅠ → 그 과정을 자동화한 그리드서치 활용! → but 간격 설정에 관한 한계가 있고, 시간이 오래 걸림 → 넓은 범위 속을 무작위로 탐색하여 효율적인 랜덤서치로 극복! 휴 험난한 하루였다...
