
Intro.
농산물 시장까지 진출한 한빛마켓! 이젠 고객이 필요한 과일 사진을 보내면, 그게 어떤 과일인지 구별하는 모델이 필요해졌다. 그런데, 손님들이 어떤 과일 사진을 보낼지 알 수 없으니 사진에 대한 정답(타깃)이 없는 거나 마찬가지인데... 이건 어떡해야할까?
- '타깃이 없다 (=입력 데이터만 있다)' ➡️ 비지도 학습! (플러스알파 참조)
1. 사진 데이터 다루기
데이터 가져오기
- 넘파이 배열로 저장되어있는 파일을 다운로드 함.
!: 파이썬 코드가 아니라 리눅스 Shell 명령으로 이해하도록 바꿔주는 문자.
wget: 웹에서 파일을 다운로드하여 저장하는 명령어 (-O뒤에는 파일 이름)

- 다운받은 파일을 불러오고 배열의 크기를 확인 → 아래와 같은 3차원 데이터
np.load(): npy 파일을 불러오는 메소드

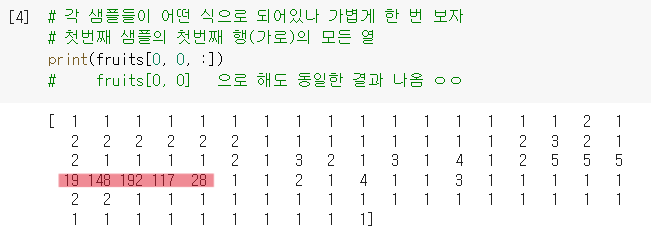
- 각 샘플 어떻게 되어있나 확인차, 첫번째 사진의 첫번째 행을 출력해봄.
참고로 이 배열은 흑백사진을 담고 있어서, 0~255의 정수값을 가짐 (숫자 클수록 밝음)
(.shape결과와 동일한 순서로 인덱싱 = 샘플, 가로, 세로 순)
데이터 그려보기
-
plt.imshow(): 넘파이 배열에 저장된 이미지를 그려줌. (image show)
cmap: 이미지 색상 테마를 지정해줌. (color map)
 ↪ 이 그림의 맨 윗줄이 바로, 아까 [0, 0, :]로 출력했던 100개의 픽셀(첫번째 행)임.
↪ 이 그림의 맨 윗줄이 바로, 아까 [0, 0, :]로 출력했던 100개의 픽셀(첫번째 행)임.
= 아하, 그래서 사과꼭지 부분만 숫자가 갑자기 튀었던 거구나 ~ -
그런데, 우리가 보기에는 사과에 색칠된 게 더 좋으니까 반전시켜서 다시 그림.
gray_r: (원래랑 거꾸로) 낮은 숫자가 밝아지고, 높은 숫자가 어두워짐.

-
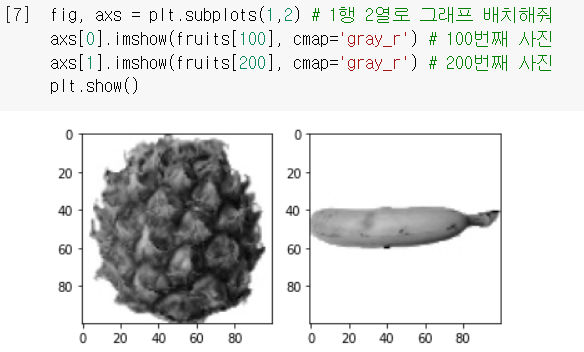
마찬가지로, 파인애플과 바나나 이미지도 그려봄.
plt.subplots(a,b): a행 b열로 그래프 여러 개를 나란히 그려주는 함수.
axs:subplot으로 그린 여러 그래프들을 담고 있는 리스트 배열.
2. 픽셀값 분석하기
김 팀장🗣️ : 사진들을 구별할 때 이 픽셀값을 이용할 수 있지 않을까?
1차원 배열로 변환
- 각 이미지 데이터(100*100)를 계속 2차원으로 다루면 복잡하고 번거로우니까
100*100을 펼쳐서 길이가 10,000인 1차원 배열로 바꿔버림.
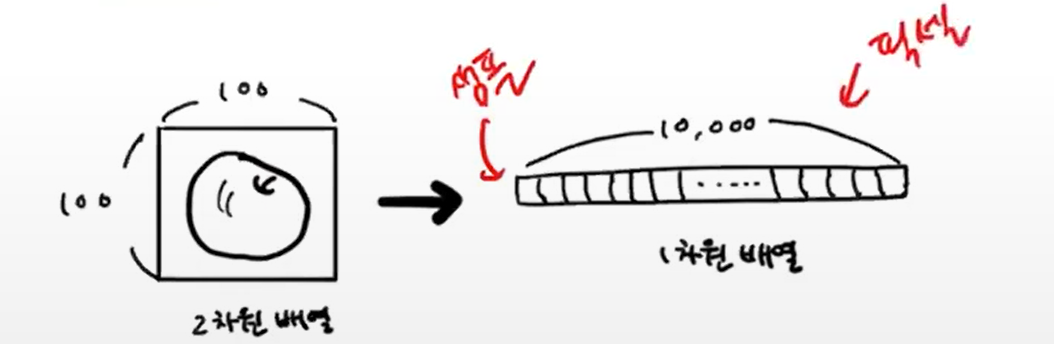
.reshape()를 사용해 (100,100,100)이던 apple / pineapple / banana를
(100, 100*100)으로 펼침 (첫 번째 차원은 샘플 개수)

샘플의 픽셀 평균값
'각 샘플들마다 10,000개의 픽셀이 있는데, 이걸 평균 내보면 뭔가 얻을 수 있지 않을까?'
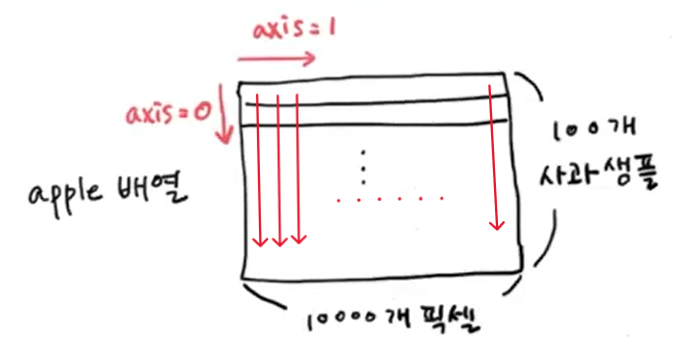
⭐잠깐! 넘파이 배열에서 계산할 때는, 항상 축을 잘 생각해야 하는 거 알지?! (p.74)
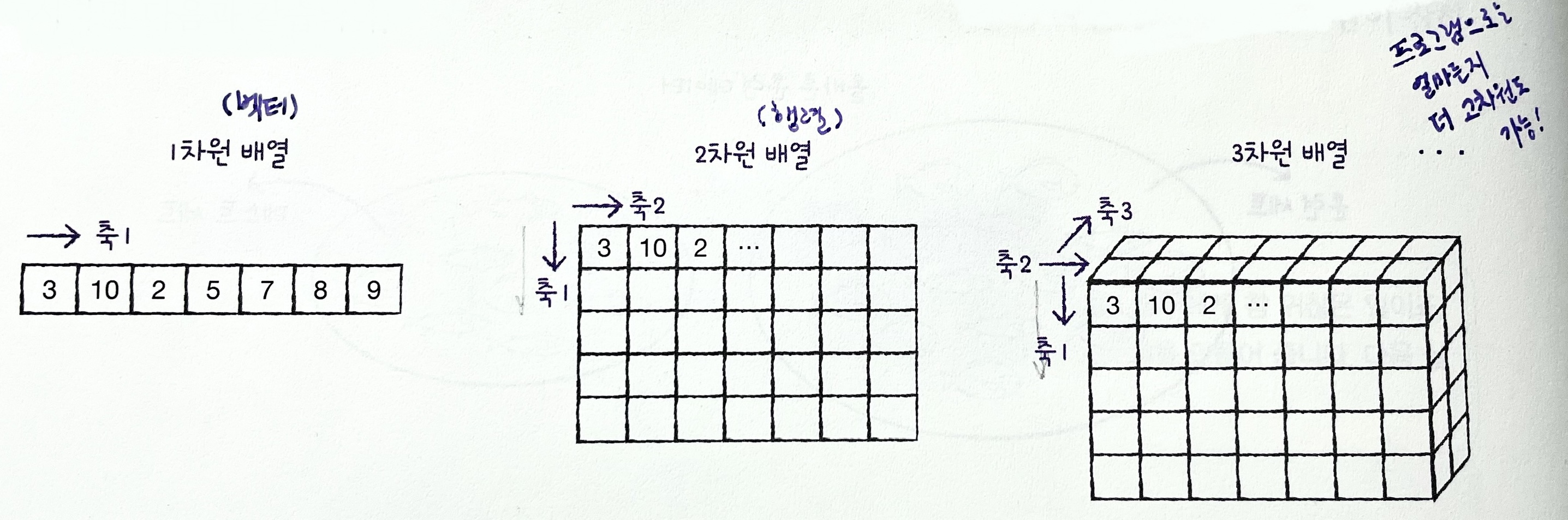
- 각각의 샘플마다 픽셀의 평균값을 계산해야 하므로,
axis=1로 계산해야 함!
.mean()을 사용하여, 일단 사과 샘플 100개에 대한 픽셀 평균값 계산해 봄.
- 이걸 세 과일 모두에 대해서 계산하고, 히스토그램으로 그려서 비교해봤더니 ...
alpha: 그래프 투명도 설정 /plt.legend(): 범례 첨부 설정
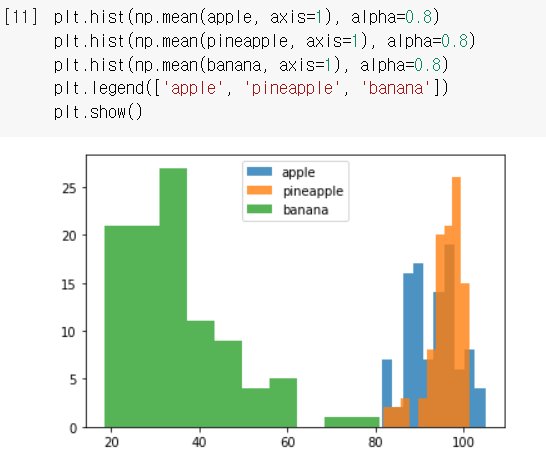
➡️이렇게 보니, 바나나는 확실히 값들이 40 아래에 집중되어있음! 이 픽셀 평균값을 활용하면 바나나를 구분해낼 수 있겠다! 근데, 사과랑 파인애플은 우째...?
픽셀의 샘플 평균값
- 이번엔 축을 반대로
axis=0으로 해서, 각각의 픽셀마다 샘플의 평균값을 계산해보면 어떨까? (=모양이 다르니까 더 자주 차지하는 픽셀들이 다를 거야!)
- 이 샘플 평균값은 과일마다 막대그래프로 그려서 비교해봤더니 ...
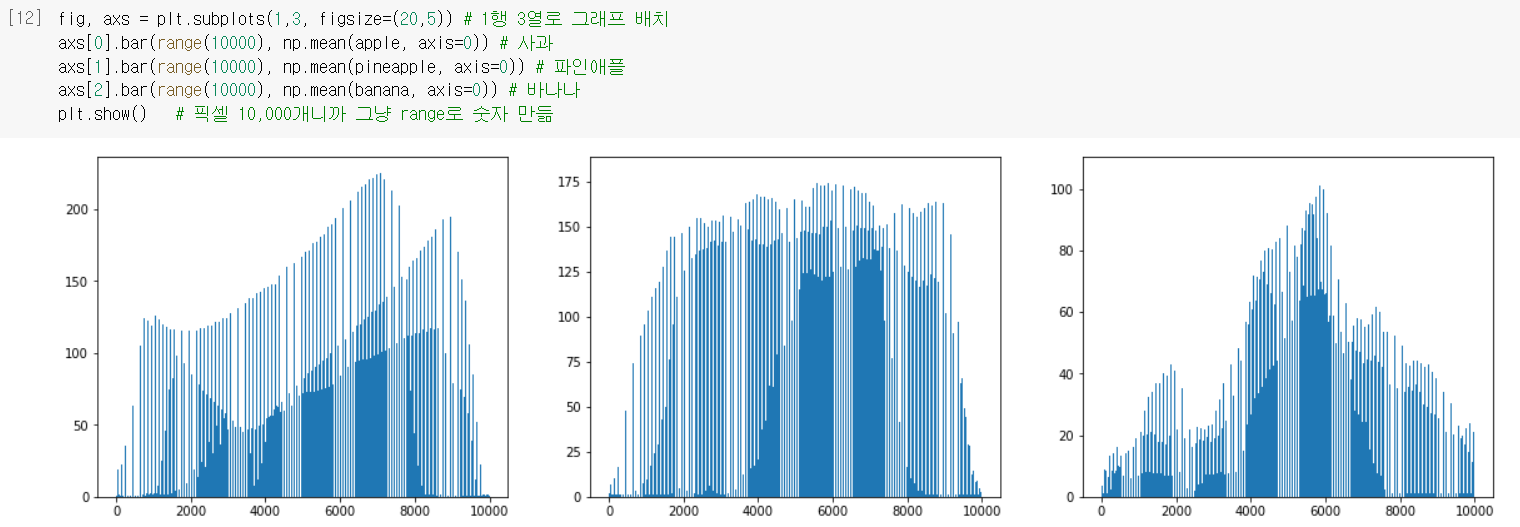
➡️이렇게 보니, 과일마다 값이 높은 구간이 다 다름! 사과는 뒤쪽 픽셀로 갈수록 값이 높아지고(=색이 어두워지고), 파인애플은 비교적 고르게 높고, 바나나는 중앙의 값이 높네! 이렇게 샘플 평균값을 활용하면 사과랑 파인애플까지도 구분할 수 있겠는걸~
3. 평균 이미지 활용하기
평균 이미지와 가까운 사진 고르기
- 이번엔 다시, 이 샘플 평균값
np.mean(apple, axis=0)을
100*100 크기로 (=다시 2차원 배열로) 이미지처럼 출력해봄.
픽셀마다 샘플들이 차지하는 값을 평균 낸 이미지가, 마치 모든 사진을 합쳐놓은
'대표 이미지'처럼 보임 !! (흐릿하게 나오는 게 정상^^)
→ 🧐고객이 올린 사진을 이 '대표 이미지'와 비교하면, 어떤 과일인지 구분할 수 있지 않을까? '대표 이미지'와 가장 차이가 적은 것으로 채택하면 되니까!
- 우리가 가진 300개의 사진들 중에, 사과의 대표이미지와 가장 가까운 사진을 골라보자.
apple_mean: 사과의 대표 이미지 (= 사과 사진 100장의 평균 이미지)
.abs(): 절댓값으로 계산해주는 함수 (absolute)

- 이렇게 구한
abs_mean(차이값 요약한 값)이 가장 작은 샘플이, 가장 사과에 가까운 것일테다!
처음 100개(우린 사과인 거 알고 있지만..^^)에 대해서만, 작은 순으로 나열해보자. np.argsort(): 작은 값부터 순서대로 그 인덱스를 반환하는 함수.
↪ 그리고 그 인덱스 중 번째 것을 [i,j] 위치에 그림으로 그려보자!
= 사과 대표이미지에 가장 가까운 것부터 100개의 그림이 그려짐.

 ↪
↪ abs_mean에서 처음 100개만 했으니, 모두 사과로 나오면 OK!
(이 과정이 다음 시간에 배울 'k-평균 군집 알고리즘'과 굉장히 유사함!)
군집 (clustering)
- 사진들이 갖고 있는 픽셀값을 사용해 과일 사진을 모으는 작업을 해봄.
→ 이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집이라고 하며, 군집 알고리즘을 통해 묶은 그룹들을 클러스터(cluster)라고 부름. (대표적인 비지도학습) - ☝🏻 근데 사실 이번 시간에는, 사과/파인애플/바나나의 평균값을 계산해서 찾은 거니까
사실상 타깃이 있는 셈이었음. (≠비지도 학습)
→ 실제 비지도 학습에서는 이렇게 샘플의 평균값들을 미리 구할 수 없음 ...
➕플러스 알파
➊ 비지도 학습
- 타깃이 없을 때 사용하는 머신러닝 알고리즘으로, 사람이 가르쳐주지 않아도 알고리즘이 스스로 데이터 속의 패턴을 찾아냄. 대표적으로 군집과 차원축소가 있음.
🆚 이전 차시까지 배웠던 '지도학습'에는 입력(input)과 타깃(target)이 모두 있었음.
🤔 Hmmmm...
288p. 근데 샘플 개수가 첫 번째 축에 놓이는 건 누구 맘대로..? 어떤 축에 뭐가 오는지 원래 정해져있는 기준 같은 게 있나요?
👨🏻🏫 축은 정하기 나름입니다. 일반적으로 샘플 축을 먼저 두는 것이 다루기 편하기 때문에 대부분 그렇게 사용하곤 합니다.
그렇다면 축마다 뭘 지정할지 임의로 설정할 수가 있는 건가요? 설정할 수 있다면 그 방법이 궁금합니다..!
👨🏻🏫 넘파이 배열을 만들 때 원하는 축의 순서대로 데이터를 나열하면 됩니다. 넘파이 배열을 만드는 방법은 온라인 문서를 참고해 주세요. 감사합니다. 🆗
297p. axis(1,2)에 대해서 차이값들을 평균내서 abs_mean 만든 것 = 길이가 10,000인 1차원으로 펼치고 axis=0 으로 해도 같은 결과가 나오는 거 맞나요??
👨🏻🏫 그럴 것 같네요. 직접 확인해 보시면 좋을 것 같습니다. 🆗
298p. 그려진 100개의 사과 중에, 좌측 상단에 있는 것이 (사과의 대표이미지와) 가장 차이가 적은 샘플인 거죠?
👨🏻🏫 사과 이미지의 출력 순서는 의미가 없습니다. ⏯️ 헉..?
🤓 To wrap up...
드디어 <비지도학습>의 시작이다! 오늘은 처음으로 텍스트가 아닌 사진 데이터를 다뤄봤다. 픽셀값으로 2차원 데이터를 다룰 수 있는 게 새삼 신기했다. 차원이 올라갈수록 축 개념을 확실히 이해하고 있어야겠다는 생각이 들었다..!!😤
고객들이 올린 과일 사진을 자동으로 분류해야 하는 상황 → 픽셀값을 활용하면 될 것 같다! → 픽셀 평균값과 샘플 평균값을 활용해서 사과/파인애플/바나나를 구분할 수 있는 나름의 방법을 찾아보았다 → 그 샘플 평균값을 다시 이미지 형태로 바꿔보니 마치 과일들의 대표 이미지처럼 나온다 → 그 대표 이미지와의 차이값을 바탕으로 과일 사진을 분류할 수 있었다! (차이가 적을수록 그 과일에 가깝다는 의미) → 하지만 이건 사실상 타깃값이 있는 거나 마찬가지...^^ → 다음 시간에 제대로 된 비지도 학습을 배워보자...!
