[혼공머신] 5-3. 트리의 앙상블
혼공머신

Intro.
이사님🗣️ "베스트 머신러닝 알고리즘을 찾아보게나!"
- 정형 데이터의 끝판왕 = 앙상블 학습 알고리즘
: 더 좋은 결과를 도출하기 위해 여러 개의 모델을 합쳐놓은 알고리즘
0. 앙상블 학습
- 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘으로, 여러 개의 모델을 합쳐서 더 좋은 결과를 도출함.
- 주로 결정 트리를 기반으로 만들어져 있음.
1. 랜덤 포레스트
- 앙상블 학습의 대표주자로, 랜덤한 결정트리의 '숲'이라고 보면 됨.
랜덤포레스트의 기본 원리
: Ⓐ+Ⓑ로 개별 트리에 무작위성을 부여해서 트리의 성능이 너무 강력해지는 것을 막음 (=과대적합 방지) → ⭐물론 개별트리의 성능은 떨어짐 but 그걸 여러 개 묶어서 일반화하면 높은 성능이 나오게 됨!⭐
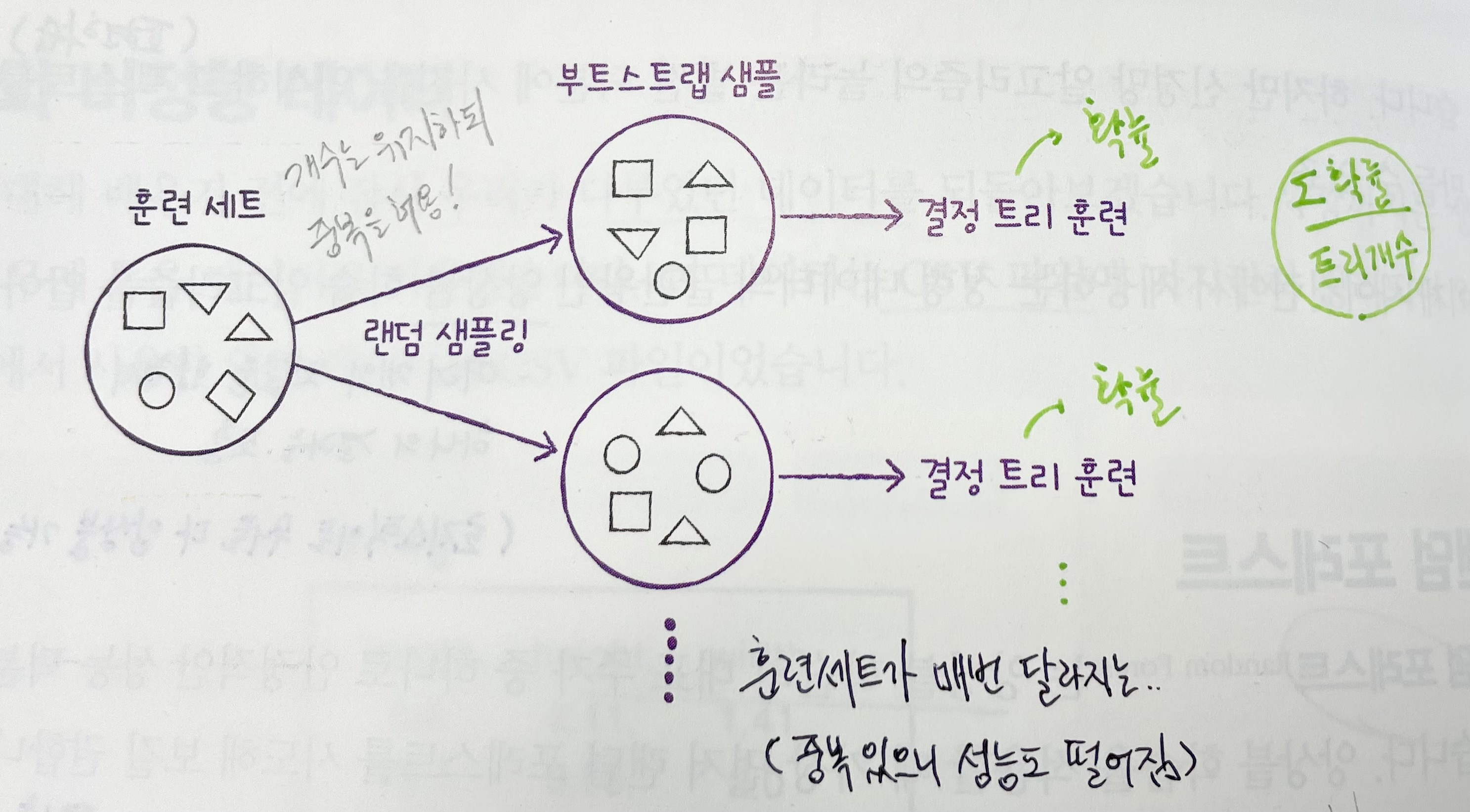
Ⓐ 훈련세트에 무작위성 주입
- 랜덤포레스트 속의 각 트리는 우리가 입력한 훈련데이터를 그대로 학습하지 않고,
훈련세트와 같은 크기의 부트스트랩 샘플(=중복을 허용한 추출)을 만들어 학습함.
Ⓑ 특성 선택에 무작위성 주입
- 노드를 분할할 때도(트리를 성장시킬 때도) 모든 특성을 다 써서 최선의 분할을 하는 게 아니라,
개의 특성만 써서(일부러 특성 개수 줄여서) 분할하게 함.
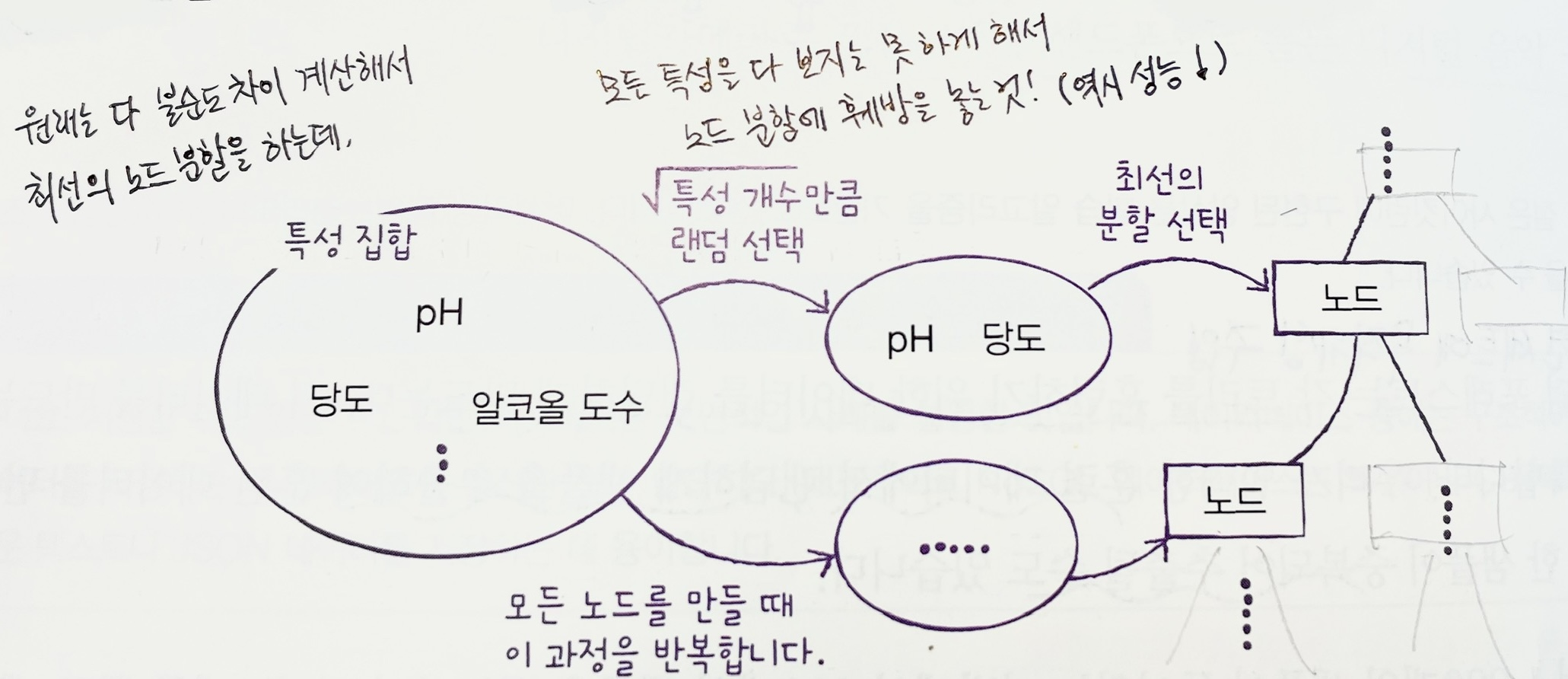
➡️ Ⓐ+Ⓑ의 방식으로 100개(기본값)의 결정트리를 훈련하고, (분류문제인 경우) 각 트리의 클래스별 확률을 평균하여 가장 높은 확률의 클래스를 예측클래스로!
cf. (회귀문제인 경우) '확률' 대신 '예측값(임의의 수치)'을 평균하면 됨!
실제 사용 과정
데이터 준비
모델 훈련 & 교차검증
RandomForestClassifier(): 사이킷런의ensemble패키지에 있음
return_train_score: 훈련세트의 점수도 반환하도록 하는 설정 (for 과대적합 파악)
 결정트리 1개 썼을 때보다 더 나은 점수! (과대적합 약간 있지만, 일단 이 상태가 만족스럽다고 가정하고 그냥 최종모델이라 치고 다음 단계로 ㄱㄱ)
결정트리 1개 썼을 때보다 더 나은 점수! (과대적합 약간 있지만, 일단 이 상태가 만족스럽다고 가정하고 그냥 최종모델이라 치고 다음 단계로 ㄱㄱ)
특성 중요도 확인
- 각 결정트리의
feature_importances_취합 → 랜덤포레스트의feature_importances_
➡️특성 선택에 무작위성을 넣었기 때문에, 단일 결정트리보다 골고루 나옴!!

2. 엑스트라 트리
- 기본 논리는 랜덤포레스트와 매우 비슷한데,(= 개별 트리 성능 억제하지만 많은 트리를 앙상블해서 과대적합 문제와 점수를 동시에 챙기는..!) Ⓐ 대신 Ⓒ를 활용함.
Ⓑ 특성 선택에 무작위성 주입
- 이건 랜덤 포레스트와 동일함.
Ⓒ 노드 분할에 무작위성 주입
- 랜덤 포레스트가 '부트스트랩 샘플(Ⓐ)'을 사용했던 것과 달리, 엑스트라 트리는 우리가 입력한 훈련세트 전체를 그대로 사용함.
- 대신, 노드를 분할할 때 최선의 분할(불순도 차이가 가장 큰 분할)을 찾는 게 아니라
그냥 무작위로 분할함! (랜덤하게 분할한 후보들 중에 그나마 불순도 차이 큰 걸로) - 269p, 262p 참고!
❗ 분할 자체를 무작위로 하다보니 랜덤 포레스트보다 무작위성이 더 크다. 그래서 랜덤포레스트보다는 트리 개수를 더 많이 해야 좋은 성능을 낸다고 알려져있다. 하지만
더 큰 무작위성 때문에 계산속도는 상대적으로 더 빨라진다는 장점도 있다.
실제 사용 과정
데이터 준비
- 앞에서 쓴 거 그대로 사용함.
모델 훈련 & 교차검증
ExtraTreesClassifier(): 역시ensemble패키지에 있음. (Trees 주의^^)

특성 중요도 확인
- 마찬가지로
feature_importances_제공하고, 마찬가지로 비교적 골고루 나옴.
(= 단일 결정트리보다 'sugar(당도)' 특성에 대한 의존성 ↓)

이젠 좀 다른 방식의 앙상블 학습을 알아보자
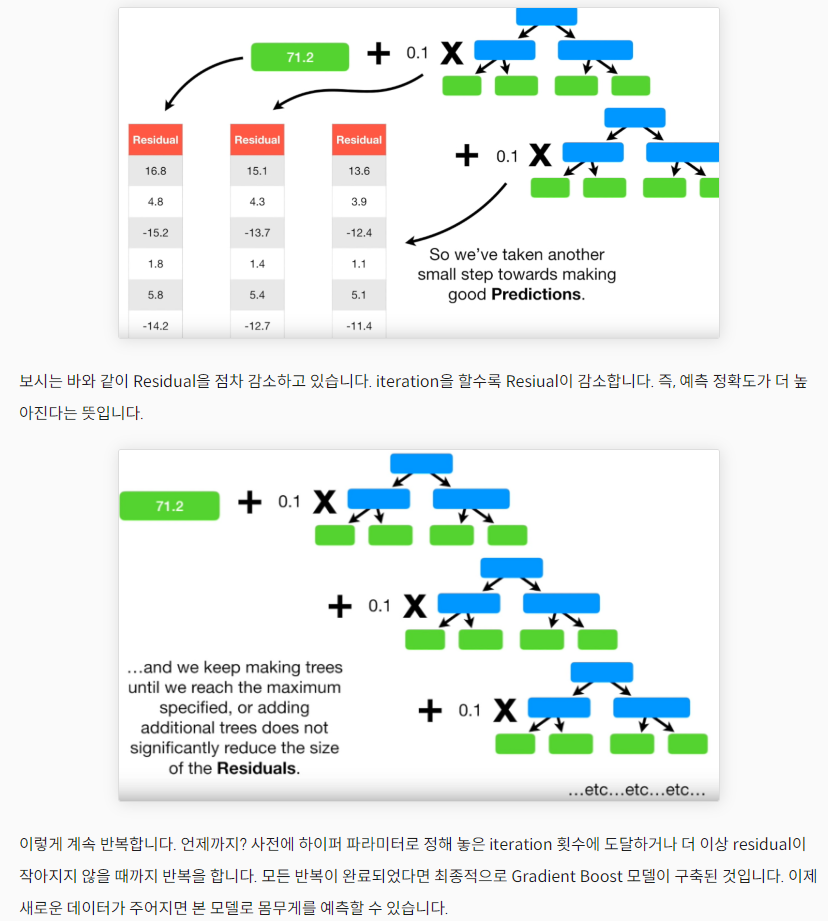
3. 그레이디언트 부스팅(GB)
- 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식의 앙상블 학습.
(기본값=3 / 깊이가 얕으니까 역시 과대적합을 방지할 수 있음.) - 'Gradient'에서 유추할 수 있듯, 경사 하강법을 사용해 트리를 추가하는 거임!
(분류 : 로지스틱 손실함수✔️ / 회귀 : 평균제곱오차 함수)
이전 트리의 손실을 보완하는 방향으로 트리 추가
❗ 경사하강법에서 손실함수의 낮은 곳을 찾아 조금씩 이동했던 것처럼❗
- 깊이가 얕은 트리를 사용해서 트리의 성능이 강력해지는 것을 막음 (=과대적합 방지)
→ 물론 처음에score구해보면 성능이 많이 높지 않음 but 그건 트리 개수 점점 더 넣으면서 높이면 됨! (결정트리 개수 늘려도 과대적합에 강하다는 장점!!) - 조금씩 이동하도록 학습률도 조절함 by
learning_rate(기본값=0.1)
 자료 출처
자료 출처
실제 사용 과정
데이터 준비
- 앞에서 쓴 거 그대로 사용함.
모델 훈련 & 교차검증
GradientBoostClassifier(): 역시ensemble패키지에 있음.
wow! 과대적합이 거의 없음! 성능이 좀 낮긴 하지만 그건 트리 더 넣어서 높이면 됨~

n_estimators: 추가할 트리 개수 설정 /learning_rate: 학습률 설정
성능을 좀 더 높여봅시다 ~

특성 중요도 확인
- 랜덤 포레스트에 비해 덜 골고루 나옴 (일부 특성에 더 집중함)

보통 GB가 RF보다 조금 더 높은 성능을 내지만, 트리를 하나하나 추가하기 때문에 훈련속도가 느리다는 단점이 있음 ㅠ → 그걸 개선한 게 바로...!
4. 히스토그램 기반 GB
- 정형 데이터를 다루는 머신러닝 알고리즘 중 가장 인기가 높음.
- 기본 매개변수에서도 안정적인 성능을 얻을 수 있을 정도로 괜찮은 모델.
입력 특성을 256개의 구간으로 나눔
- 노드를 분할하기 전에, 훈련데이터를 256개의 구간으로 쪼갬 → 특성의 범위가 짧게 끊어져있으니 최적의 분할을 매우 빠르게 찾을 수 있음!
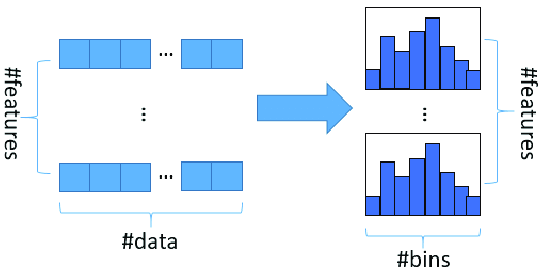 그림 출처
그림 출처 - 또한, 256(255+1)개 중에서 1개는 누락된 데이터를 위한 구간으로 할당함 → 훈련 데이터에 누락된 특성이 있더라도 이를 222p처럼 따로 전처리할 필요 없음!
실제 사용 과정
데이터 준비
- 앞에서 쓴 거 그대로 사용함.
모델 훈련 & 교차검증
HistGradientBoostClassifier(): 역시ensemble패키지에 있음.
🆚추가할 트리 개수 설정 시,'n_estimators' 말고max_iter사용함.
 과대적합도 잘 억제했고, (기본 설정인데도) 그냥 GB보다 더 높은 성능!
과대적합도 잘 억제했고, (기본 설정인데도) 그냥 GB보다 더 높은 성능!
특성 중요도 확인
⭐ 이전과 좀 다르게, permutation_importance() 함수를 사용함
- 특성을 하나씩 랜덤하게 섞으면서 모델의 성능 변화를 관찰 (
n_repeats로 섞을 횟수 지정 가능!) → 많이 변할수록 중요한 특성으로, 별로 안 변할수록 중요하지 않은 특성으로 계산함! - 반환된 객체에는
importances(계산한 개별 특성중요도 모두),importances_mean(그걸 평균 낸 최종 특성중요도),importances_std(특성중요도들 간 표준편차) 가 담겨 있음.

- 이 함수는 훈련세트뿐만 아니라, 테스트세트에서도 특성중요도를 계산할 수 있음!
 'pH'는 실전에서는 더 의미없는 특성일 것으로 예상할 수 있겠네..!
'pH'는 실전에서는 더 의미없는 특성일 것으로 예상할 수 있겠네..!
🚩최종 성능 확인🚩
- 이 모델을 최종모델로 하여, 테스트세트에서의 성능을 최종 확인해보면
단일 결정트리(86%였음)보다 좋은 결과를 얻을 수 있음!

이렇게 하여,, 와인(red/white)을 구분하는 나름의 베스트 모델을 만들었다..!
5. 그 외 라이브러리
사이킷런 외에도 많은 라이브러리에서 그레이디언트 부스팅 알고리즘을 구현하고 있음.
XGBoost
- 다양한 부스팅 알고리즘을 지원하는 라이브러리. (오픈소스/코랩ok)
Kaggle에서 많이 사용하면서 유명해짐.

LightGBM
- 마이크로소프트에서 만든, 그레디언트 부스팅 전용 라이브러리. (오픈소스/코랩ok)
히스토그램 기반 GB를 지원해서 인기가 높아짐.

➕플러스 알파
➊ 정형/비정형 데이터
- 정형 데이터 : csv나 database 혹은 excel처럼 어떤 구조로 가지런히 정리되어있는 데이터. 주로 머신러닝 알고리즘을 통해 다룸.
- 비정형 데이터 : 텍스트, 사진, 음악 등 database나 excel로 표현하기 어려운 데이터.
주로 딥러닝(신경망) 알고리즘을 통해 다룸.
➋ OOB 샘플 (랜덤포레스트 中)
- OOB (Out Of Bag) 샘플 : 랜덤포레스트에서 부트스트랩 샘플을 만들 때, 복원추출 과정에서 선택되지 않고 남은 샘플
➡️이 남은 샘플로 트리를 평가할 수 있음!! (마치 검증세트와 같은 역할) obb_score_:oob_score옵션을 True로 하면 그걸로 평가한 점수가 여기에 저장됨.
 = 정말 교차검증에서 얻은 '검증세트의 점수'와 비슷하게 나오네 wow 이걸 사용하면 교차검증을 대신할 수 있으니, 결국 훈련세트에 더 많은 샘플 사용 가능해짐~
= 정말 교차검증에서 얻은 '검증세트의 점수'와 비슷하게 나오네 wow 이걸 사용하면 교차검증을 대신할 수 있으니, 결국 훈련세트에 더 많은 샘플 사용 가능해짐~
➌ subsample (그레이디언트 부스팅 中)
subsample매개변수를 사용하면 트리 훈련에 쓸 훈련세트의 비율을 정할 수 있음.
↪ 기본값 = 1.0 (훈련세트 전체를 사용)- 그런데 이걸 1보다 작은 값으로 넣으면 훈련세트의 일부만 사용하게 됨.
↪ 즉, 앞에서 배웠던 확률적 경사하강법이나 미니배치 경사하강법처럼 되는 거임!
🤔 Hmmmm...
5주차에는 일반 검증 - 교차 검증 - 앙상블 학습, 이렇게 3가지를 배웠다.
실제 사용 과정에서 헷갈리는 느낌이 들어 개괄하여 적어둔다⭐
.
먼저 가장 기초적인 일반검증은 원래
dt = DecisionTreeClassifier()처럼 모델 객체 만들고
dt.fit(입력, 타깃)해서 가지고 있는 데이터로 훈련한 뒤,
dt.score(입력, 타깃)해서 그 성능을 평가할 수 있었다
.
근데 좀 더 발전된 교차검증으로 오면
dt = DecisionTreeClassifier()해서 모델 객체 만들어 놓은 것에
cross_validate(dt, 입력, 타깃)하면 알아서 fit하고 score까지 한 다음, 그 결과값을 (딕셔너리 형태로) 반환해준다
.
그리고 성능이 가장 뛰어난 앙상블은
처음에dt = ___이 자리에 앙상블 모델만 넣어주면 되는 것이다!!
이후는 똑같이cross_validate해주는 것이 일반적인 듯하다 (당연히 교차검증이 더 효율적이니 교재에서도 그렇게 사용한 듯) 🆗
265p. 근데 기본적으로... 성능 낮춘 모델 여러개를 묶은게 성능 좋은 모델 하나보다 어떻게 더 좋은 모델이 되는거지...?
270p. RF와 ET 모두 2가지 방식으로 무작위성 주입했는데, ET가 더 빠르다는 건, 부트스트랩 샘플 뽑는 과정보다 분할 찾는(불순도 계산하는) 과정이 더 복잡하고 오래걸리는 과정이라서 그런 거라고 이해하면 될까요?
👨🏻🏫 네 맞습니다! 🆗
271p. 근데 GradientBoostingClassifier는 따로 손실함수는 정의 안 해줘도 되나..?
loss매개변수에서 설정할 수 있고, 기본값이deviance(=로지스틱 손실함수)라고 282p에 나와있네..^^ 🆗
272p. GradientBoosting은 무작위성이 덜하니까 특성 중요도가 한 특성에 치우친거죠?
👨🏻🏫 이 예제에 해당하는 경우라서 일반화하기 힘들 것 같습니다. 🆗
272p.
subsample< 1 인 경우가 '확률적 or 미니배치 경사하강법'이면, 원래 기본값은 '배치 경사하강법'이라는 건가요?👨🏻🏫 네 맞습니다! 🆗
273p. 나누는 구간의 개수가 왜 하필 256개인지 특별한 이유가 있나요...? 282p 보니까 그 이상으로 쪼갤 수도 없게 되어있던데 왜 그런지 궁금합니다.
👨🏻🏫 이유를 어디서 본 것 같은데 기억이 안 나네요..^^ ⏯️ 찾게 되면 적어두자
🤓 To wrap up...
그렇게 극찬하셨던 '앙상블' 알고리즘을 드디어 배웠다.. 확실히 더 발전된 느낌이긴한데, 생각보다 성능이 극적으로 좋게 나오거나 그러진 않아서 아직 제대로 와닿진 않는 것 같다. 아마 직접 프로젝트를 해보거나 큰 데이터를 다뤄보면 실감할 수 있겠지? 어쨌거나 <지도학습> 파트는 끝을 냈다고 생각하니 뿌듯 ㅠ 슬슬 프로젝트를 준비할 때다..! 파이팅!
더 강력한 성능의 모델을 만들기 위해 "앙상블 학습"을 도입 → 랜덤 포레스트와 엑스트라 트리는 성능을 낮춘 결정트리들을 앙상블 : 안정적인 성능 + 특성 의존도 줄어듦 → 그레이디언트 부스팅은 경사하강법의 원리로 얕은 트리들을 추가하면서 높은 성능에 다가감 → 이것의 속도와 성능을 더 개선한 것이 히스토그램 기반 그레이디언트 부스팅이고, 훈련 데이터를 256개 구간으로 쪼개서 속도를 높임 + permutation_importance로 특성중요도 계산! → 그 외에도 XGBoost, LightGBM 등 많은 앙상블 알고리즘들이 있음. // 참 다양한 종류의 알고리즘을 배운 하루였다!
