개요
- naver map api는 마커가 200개 이상 찍힐 때 지도가 버벅일 정도로 성능이 저하됨을 체감한다.
- 일정 수준 이상으로 축소하는 경우, 군집되어 부분의 마커만을 표시할 필요가 있었다.
문제점
- 솔직히 naver map api에서 제공하는 마커 클러스터링을 최대한 활용해보려고 했으나, 내 수준에는.. api 예제가 너무 복잡하게 나와 있어서 여러방면으로 시도해봤으나, 잘 적용되지 않았다. 그래서 직접 마커 클러스터링을 구현해보기로 했다.
마커 클러스터링 구현 과정
- myLocation 전역 상태 변경 시, 현재 위치와 줌 레벨 확인.
- zoom이 10 이하일 경우, 야영장 전체 데이터 가져오기.
- 야영장 데이터를 시/도 단위로 객체화({서울시 : ..., 강원도:...})한 뒤,
Object.values를 통해 값을 추출하여 배열화시키기. - 3의 배열의 요소에는 서울시 전체 야영장 데이터(위치 포함)가 들어있으므로, 위경도를 각각 더하고 length만큼 나눠서 평균 위치값 추출하기. 앞의 연산 과정을 3의 배열에 map을 적용하여 반환값으로 평균 위치값 return하기.
- 4의 배열(지역 단위로 나뉜 야영장의 평균 위치값이 모인 배열)에 반복문으로 마커 찍어주기.
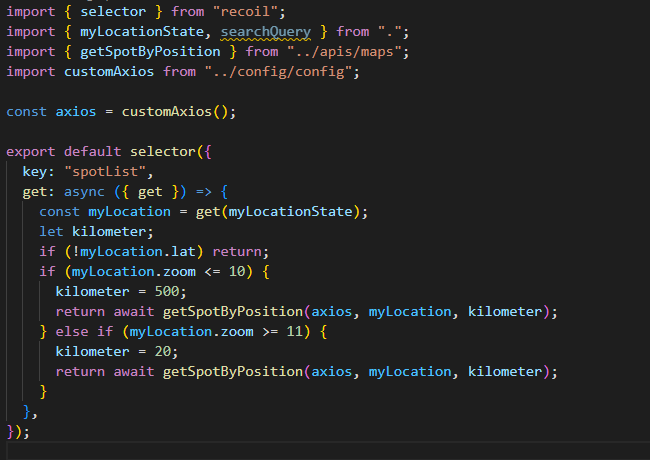
1. 현재 위치와 줌 레벨 확인 후 야영장 전체 데이터 가져오기.
- recoil의 selector를 통해 myLocation(현재 지도 상태) state를 구독하고, 값이 바뀔 때(지도를 드래그하거나 줌을 확대/축소)마다 zoom을 체크한다.
- zoom level이 10 이하인 경우, 야영장 전체 데이터를 받아온다.
getSpotByPositionapi는 위치 정보를 기반으로 지정한 반경 n km 야영장 데이터를 받아옴.- 지도를 최대로 축소해도 500km는 안 넘어가기 때문에 지도 중심 위치를 기준으로 500km 반경 야영장 데이터를 가져옴.
2. 야영장 데이터 가공
-
데이터가 반환되면 마커를 찍는 함수가 호출되며, list 매개변수로 야영장 데이터를 보내게 된다.
-
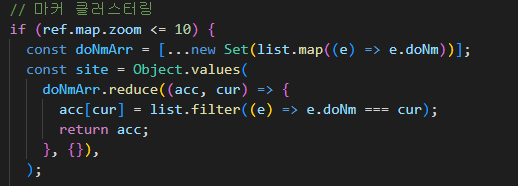
줌 레벨이 10 이하인 경우, 야영장 배열에 map을 사용하여, 요소를 시/도로 반환한 배열에 Set을 활용하여 중복값을 없앤다. >
doNmArr- 이렇게 하면 시/도가 하나씩만 남게 되어 깔끔하게 객체의 key가 되는 배열을 준비할 수 있다.
ex)
[서울시,서울시, 강원도, 전라남도,전라북도,경상남도,경상남도]
->
[서울시,강원도,전라남도,전라북도,경상남도]
- 이렇게 하면 시/도가 하나씩만 남게 되어 깔끔하게 객체의 key가 되는 배열을 준비할 수 있다.
-
doNmArr배열에 reduce를 활용하여 객체의 key로doNmArr의 요소를 활용하고 그 value로 매개변수로 전달받은 전체 야영장 데이터에 filter 메서드를 활용하여 시/도를 비교하여 넣어준다. -
reduce를 활용하여 생성한 객체에 Object.values를 적용하여 얻은 배열에는 시/도 단위로 구분된 데이터로 각 요소가 구성된다.
3. 가공된 데이터 활용하여 시/도 단위 평균 위치 구하기.
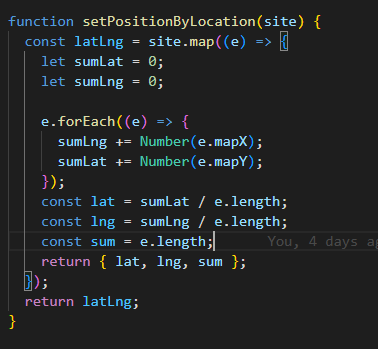
- 2에서 얻은 시/도 단위로 데이터를 구분한 배열에 map을 사용하여 각 요소의 요소, 즉 야영장 하나하나의 위경도를 더해준 뒤 평균 값을 구한다.
- 그리고 마커에 표시할 야영장 갯수를 위해 배열 length값도 함께 반환한다.
4. 클러스터링된 마커 찍기
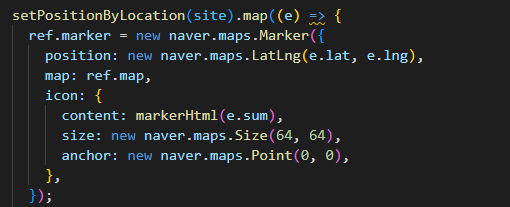
- 3에서 반환된 배열(시/도 단위 평균 위치와 요소의 갯수)에 map을 다시 사용하여, 마커를 찍어준다.
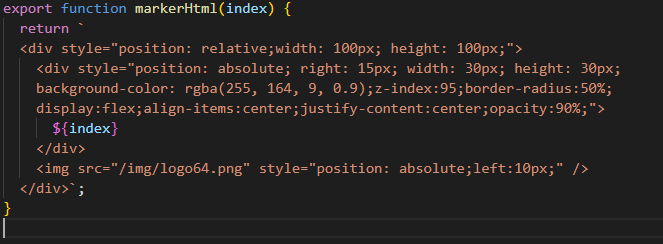
+ 함수로 마커 html 생성하기
- 4의 이미지를 보면 icon, content에
markerHtml함수가 있는 걸 볼 수 있다. - naver map api의 마커는 정적 이미지뿐만 아니라, html / html을 반환하는 함수로도 생성이 가능하다.
- 스타일링한 html에 요소의 갯수를 매개변수로 받아 마커에 띄워주면 된다.
+ 클러스터링한 마커 클릭 이벤트 등록
- 클러스터링 마커를 클릭할 경우, 해당 마커가 지도의 중심으로 오고 그 지역의 야영장을 마커로 찍기 위해 줌을 확대해야 했다.
- naver map api 포스팅에서 사용한 것과 동일한
morph메서드를 활용한다.

결과물
- 마커 클러스터링과 클릭 이벤트(클릭한 마커를 중심으로 확대)
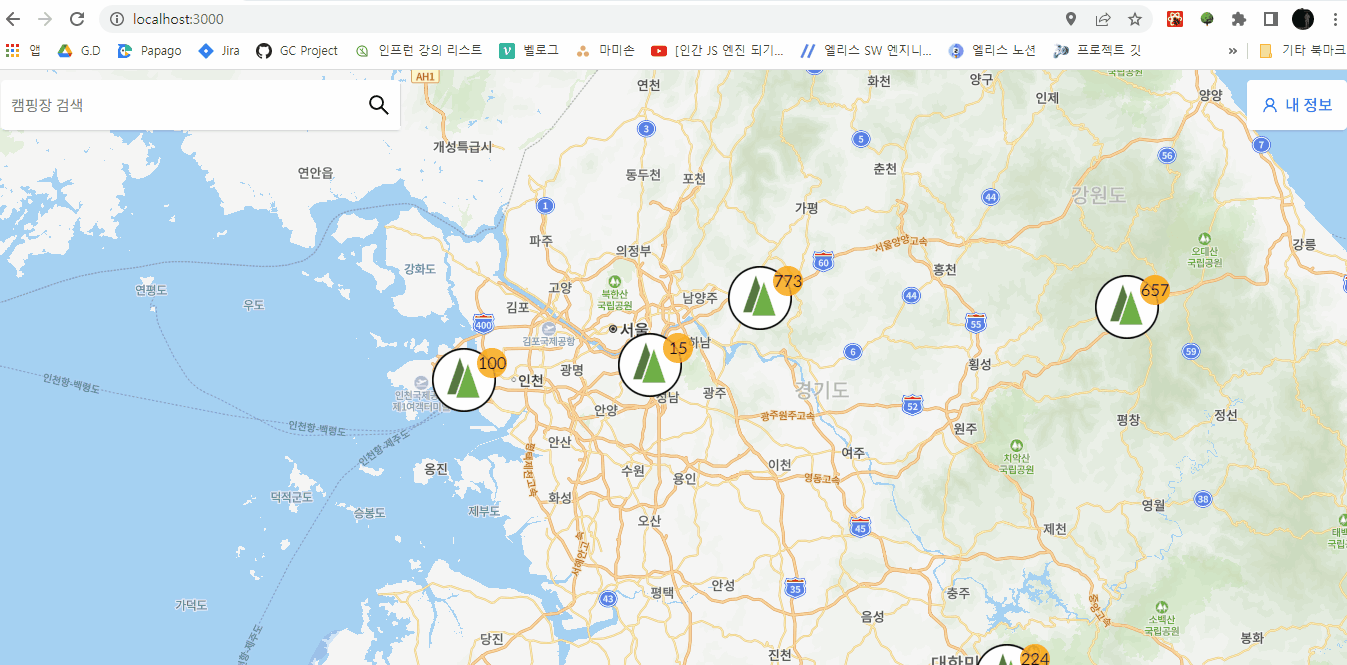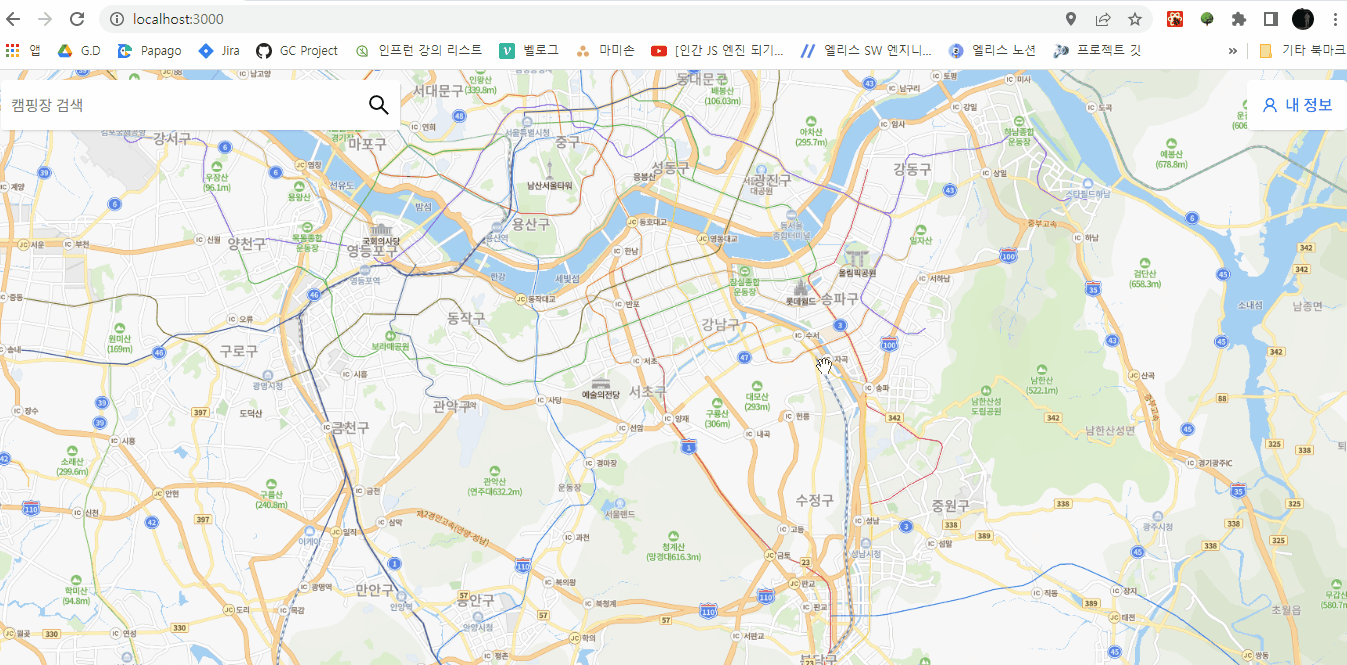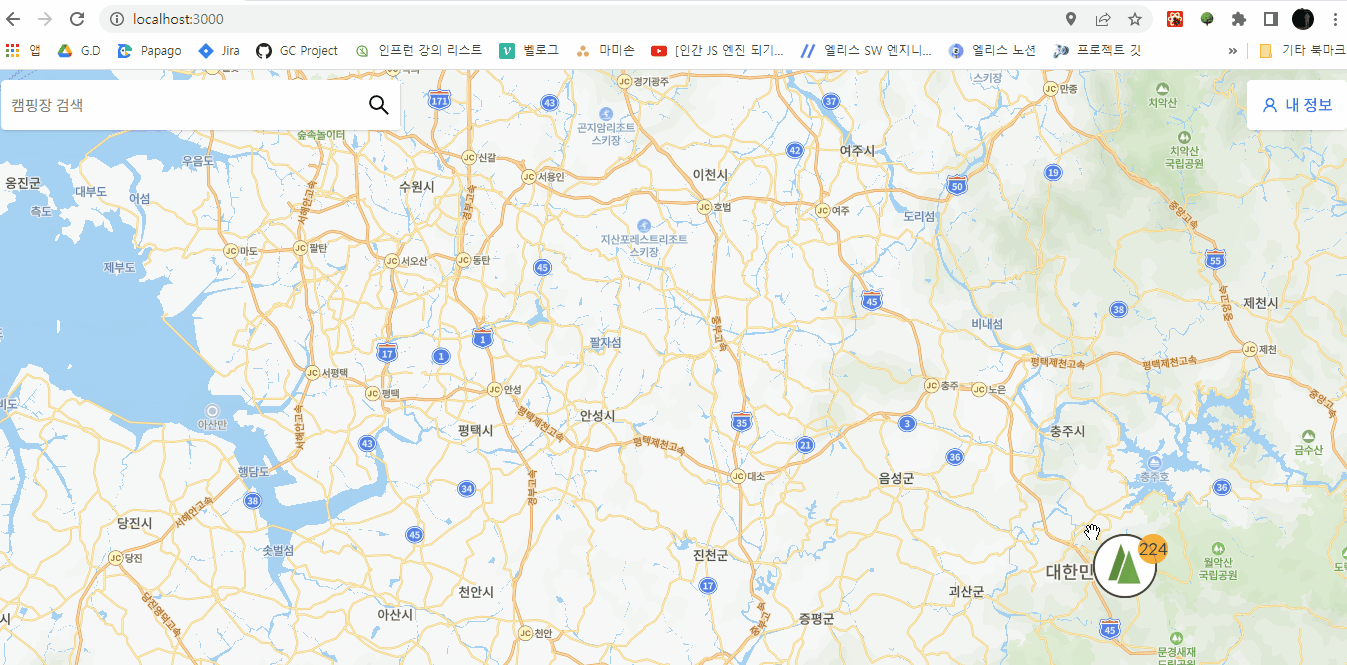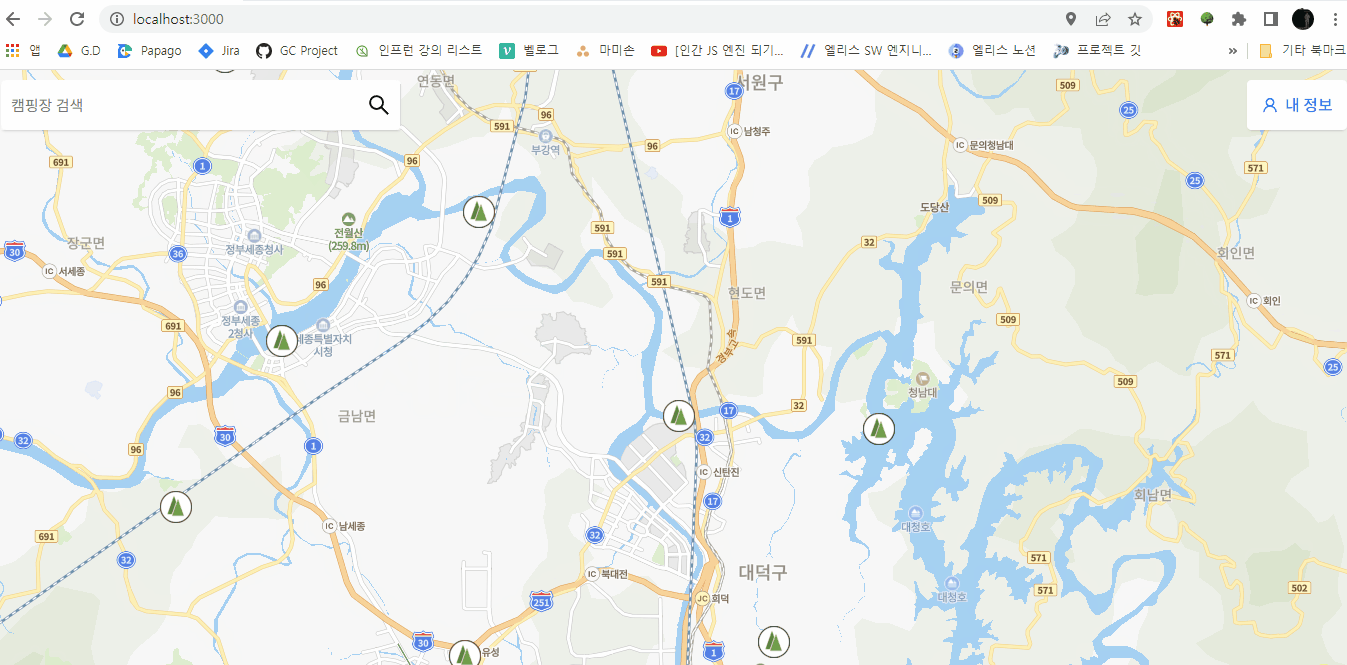
아쉬운 점
-
직관적인 표현을 위해 마커 클러스팅이라고 했지만, 단순히 데이터를 바꿔서 띄우는 것과 다를 바가 없는 알고리즘인 것이 아쉽다. naver map api를 활용하면 마커 배열을 활용하여 자동적으로 클러스터링이 되는 것을 확인할 수 있는데, 이 부분을 한번 다시 고려해보고 싶다.
-
과도한 서버 통신. 지금 구현된 코드는 줌이 10이하인 걸 감지하면 위의 연산을 모두 실행하게 되는데 zoom level이 11>10은 문제가 없지만 10>10,10>9 같이 연산을 다시할 필요가 없는 경우에도 내 위치 상태가 변경되면 무조건 연산을 실행하기 때문에 쓸데없이 데이터를 받아온다.
-
또한, 지금 전국 야영장 총 데이터가 3천개 정도로 많지 않은 양이기 때문에 위의 연산이 빠른 속도로 되는 것 뿐이지 예를 들어 범죄율, 구매량 등 데이터의 규모가 커질수록 위에서 적용한 방식은 효율적이지 못하다.
