target 키를 사용하여 모델, 데이터 로더, 변환 등을 정의하는 방식을 사용한다.
!!python/object와 같은 YAML 문법을 사용하여 Python의 특정 객체나 함수 호출을 정의하는 방식이고
LazyConfig에서는 중복되는 설정을 ${...} 형태로 참조하여 간결하게 표현할 수 있다는 점도 LazyConfig의 특징입니다.
__target__
target은 LazyConfig의 핵심 키워드로, 호출하려는 클래스나 함수를 지정하는 데 사용된다.
LazyConfig에서 모든 객체는 Python의 클래스나 함수를 동적으로 생성하는 방식으로 설정되며, 이때 "_target" 필드를 사용하여 어떤 객체나 함수가 호출될지를 정의한다.
아래와 같이 detectron2.data.build_detection_train_loader를 호출하여 데이터 로더 객체를 생성한다.
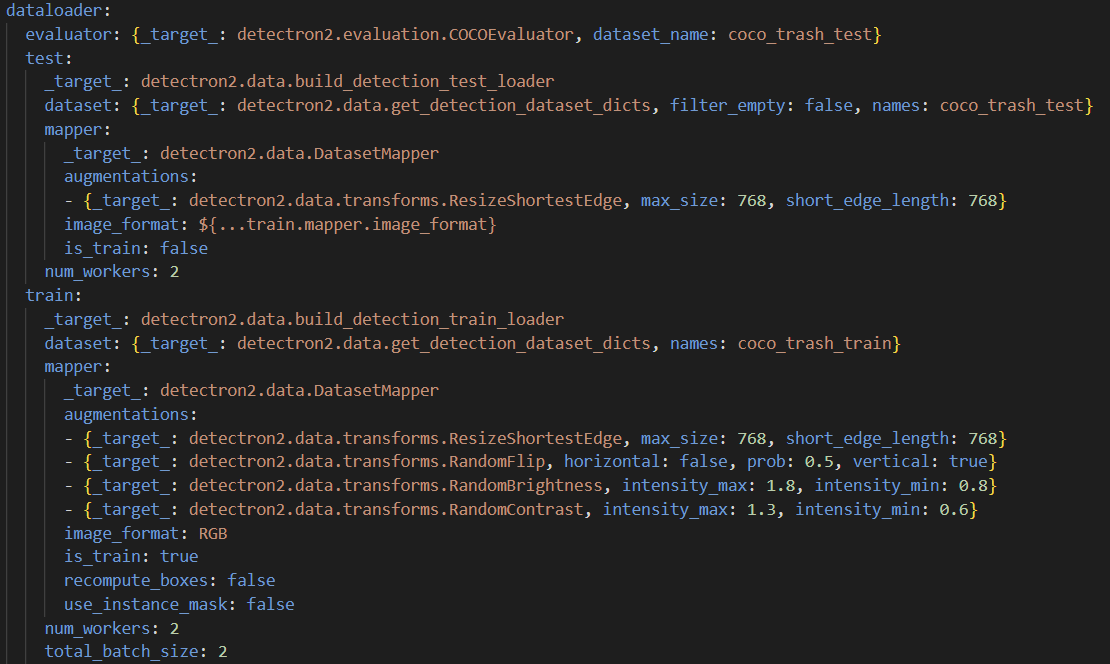
dataloader:
train:
_target_: detectron2.data.build_detection_train_loaderdata loader
dataloader는 학습 데이터와 테스트 데이터를 로드하는 설정이다. train과 test 섹션을 구분하여 데이터 로더 설정을 정의한다.
-
dataloader.test.dataset.names
우리가 사용할 test 데이터를 정하는 곳 -
dataloader.train.dataset.names
우리가 사용할 train 데이터를 정하는 곳 -
dataloader.train.mapper
이미지에 적용할 데이터 변환(augmentation) 설정을 정의한다.
이 설정을 통해 내가 이미지를 변환시키고 싶은대로 변환시킬 수 있다.
dataloader.train.mapper.augmentations을 이용해서 설정한다. -
dataloader.train.num_worker
num_workers는 데이터 로더에서 사용되는 스레드(worker) 수를 설정하는 옵션이다. 이 값은 데이터셋을 로드할 때 몇 개의 CPU 스레드를 사용할지를 결정한다. -
dataloader.train.total_batch_size
데이터 로더에서 배치를 꺼내올때 데이터를 몇개씩 꺼내올 것인지 정하는 것이다. 많이 꺼낼수록 사용하는 메모리가 늘어난다. -
dataloader.train.mapper.image_format
모델에 입력할 이미지의 색상 포맷을 지정한다. 일반적인 값은 RGB 또는 BGR이다.
RGB: 이미지의 색상 순서가 빨강(R), 초록(G), 파랑(B)으로 되어 있는 형식.(transformer에서는 RGB사용)
BGR: 반대로 파랑(B), 초록(G), 빨강(R) 순으로 배열된 형식. 일부 딥러닝 프레임워크나 모델(특히 OpenCV 사용 시)은 BGR을 사용합니다. -
dataloader.train.mapper.is_train
이미지 증강시 train 전용 증강기법을 사용할 건지 테스틑 전용 증강기법을 사용할 것인지 정하는 설정이다. -
dataloader.train.mapper.recompute_boxes
데이터 증강 후 바운딩 박스(bounding box)를 다시 계산할지 여부를 결정한다.
만약 이미지를 축소/확대 했다면 true로 설정하여 box를 크기와 위치를 조정해야한다. -
dataloader.train.mapper.use_instance_mask
인스턴스 마스크(instance mask)를 사용할지 여부를 설정한다. 객체 검출(task)이 단순한 바운딩 박스(bounding box)를 사용하는 경우, 이 옵션을 false로 설정한다.
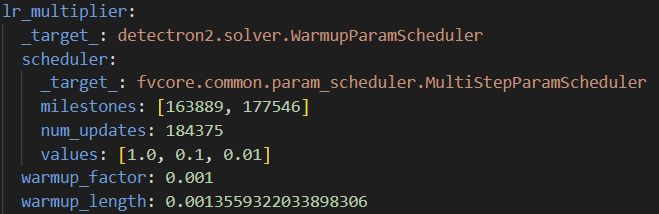
lr_multiplier
-
lr_multiplier
학습률에 곱해지는 스케줄러를 정의하는 곳이다.
__target__을 이용해서 정한다.
즉 학습률을 추가 조정하는 역할을 한다. -
lr_multiplier.scheduler
학습률의 변화를 결정하는 구체적인 방식(스케줄)을 정의한다.
학습 중 학습률이 변화하는 방식을 정의하는 것이다. -
lr_multiplier.scheduler.milestones
여기서 지정한 step만큼 모델이 학습할 때 학습률을 변경한다. -
lr_multiplier.scheduler.num_updates
학습 과정에서 몇번의 업데이트(배치 처리)가 있는지 정하는 것 -
lr_multiplier.shceduler.values
milestones에서 정한 step에서 얼만큼 학습률을 감소시킬건지 정하는 것이다. -
lr_multiplier.warmup_factor
학습 초기에 워밍업 단계에서 사용할 학습률 배율이다.
이 배율만큼 천천히 학습률을 증가시킨다. -
lr_multiplier.warmup_length
warmup_factor배율 만큼 증가시킬때 warmup_length 동안 증가 시키는 것이다.
model
모델에는 내가 어떤 백본으로 설정하고 어떻게 roi head를 쓰며, cascade를 사용여부에 따라 정말 다양한 설정을 할 수 있기 때문에 기본적인 설정들 위주로만 살펴보자
-
target
모델의 주요 구조를 정하는 것이다.
rcnn 계열 모델을 쓰고 싶을 때는 GeneralizedRCNN로 정한다. -
model.backbone
이미지에서 특징을 추출하는 역할을 하는 백본을 정한다. -
model.backbone.net
모델의 백본 구조를 정하는 것으로 vit,cnn기반 pretrained된 모델로 선정할 수 있다.(_target_으로 설정한다.) -
model.backbone.net.depth
백본의 layer의 개수를 정하는 것이다. 개수를 늘릴수록 더 깊은 backbone을 형성할 수 있다. -
model.backbone.net.img_size
백본에 들어갈 input img size를 정할 수 있다. -
model.backbone.out_channels
백본에서 출력되는 특징 맵의 채널수를 정하는 곳 -
model.pixel_mean/pixel_std
이미지를 표준화할때 사용하는 값들이다. -
model.proposal_generator
RPN(Region Proposal Network)을 사용하여 관심 영역을 제안하는 부분이다. -
model.proposal_generator.anchor_generator
앵커 박스를 생성하는 방법을 제안하는 부분이다.
aspect ratio를 이용해서 앵커박스의 가로세로 비율을 설정하고,
sizes를 통해 사이즈를 정하고,
stride를 통해 pixel간의 거리를 정한다.
-
model.proposal_generator.anchor_matcher
앵커박스와 실제 객체를 매핑시키는 방법을 정의한다.
예를 들어
thresholds: [0.3, 0.7]: IoU(Intersection over Union)가 0.3 미만이면 negative(배경), 0.7 이상이면 positive(객체), 그 사이값이면 무시하도록 설정한다. -
model.proposal_generator.batch_size_per_image
이미지당 제안할 박스의 개수를 설정하는 곳 -
model.proposal_generator.box2box_transform
RPN에서 예측된 박스를 실제 좌표로 변환하기 위한 변환 계수를 정의
좌표 변환에 사용될 가중치를 설정한다. -
model.proposal_generator.head
RPN의 헤드를 설정하며, in_channels과 num_anchor를 이용해 입력 채널과 앵커를 설정합니다. -
model.roi_heads
탐지된 객체의 경계 박스를 더 정확하게 조정하는 역할을 한다. -
model.roi_heads.box_heads
conv_dims: Convolution 레이어의 채널 수를 정한다.
fc_dims: Fully connected layer의 채널 수를 정한다. -
model.roi_heads.box_in_features
FPN에서 사용될 특징 맵의 레벨을 정의 -
model.roi_heads.num_classes
데이터의 클래스 수를 정의 -
model.roi_heads.box_predictors
예측하는 단계에서 사용하는 Fast R-CNN 출력을 정의합니다. 세 단계의 박스 예측기 각각에서 좌표 변환 및 클래스별 예측을 수행 -
model.roi_heads.positive_fraction
만약 0.25로 정하면 이미지당 25%의 박스는 객체로, 75%는 배경으로 처리합니다.
optimizer
모델을 학습하기 위한 최적화 기법을 정의
target으로 설정한다.
- __target__
adamw, adam, sgd, momentum중 설정할 수 있다. - optimizer.lr
학습률을 설정 - optimizer.weight_decay
전체 파라미터에 대해 0.1의 weight decay를 적용한다.
가중치 감쇠를 통해 모델의 복잡도를 줄이고, 오버피팅을 방지하는 데 도움을 준다.
train
델 학습 과정에서 다양한 설정을 지정하는 부분이다.
학습 중의 장치, 학습 반복 횟수, 자동 혼합 정밀도(AMP), 체크포인트 저장 주기, DDP(Distributed Data Parallel) 등 다양한 요소를 관리하는 역할을 한다
-
train.amp
AMP는 훈련 속도를 높이고 메모리 사용량을 줄이기 위해 혼합 정밀도(FP16과 FP32의 혼합)를 사용하는 방법이다.
true로 설정 시 성능이 향상될 수 있다. -
train.checkpointer.max_to_keep
학습 도중 모델 상태를 저장하는 방법을 설정하는 것으로 마지막 몇개의 체크포인트만 유지할 것인지 정한다. -
train.checkpointer.period
몇번의 iteration마다 저장할 것인지를 설정한다. -
train.ddp
DDP는 여러 GPU에서 병렬로 학습을 수행할 때 필요한 설정이다.
ddp: {broadcast_buffers: false, find_unused_parameters: false, fp16_compression: true}이런식으로 설정하여 비용을 줄인다.
-
train.device
cuda로 설정하여 gpu로 학습하게 한다. -
train.init_checkpointer
초기 체크포인트로 사용할 모델을 지정한다.
대부분은 사전학습된 모델을 들고 온다. -
train.log_period
20번의 iteration마다 로그를 기록한다.
로그에는 학습 중 발생하는 손실(loss) 값, 학습률, 시간 등 중요한 학습 정보를 기록하여 모니터링할 수 있다. -
train.max_iter
학습이 몇 번의 iteration 후 종료될지를 결정하며, 학습이 해당 iteration에 도달하면 종료한다. -
train.output_dir
모델의 출력 파일(체크포인트, 로그, 평가 결과 등)을 저장할 디렉터리 경로를 정한다.
