TTA
TTA(Test-Time Augmentation)는 딥러닝 모델을 학습시킬 때 데이터가 부족한 상황에 이미지를 증강 시키는 것과 비슷하게
모델을 test할 때도 data augmentation을 해서 모델의 예측을 개선하는 기법이다.
증가시키는 방식은 train할때 나 test할때 둘다 같다.
구체적으로는 TTA는 입력 이미지나 데이터를 여러 번 변형하여 각각에 댛 모델이 예측한 결과들을 모아서 최종 예측을 산출하는 방식으로 작동한다.
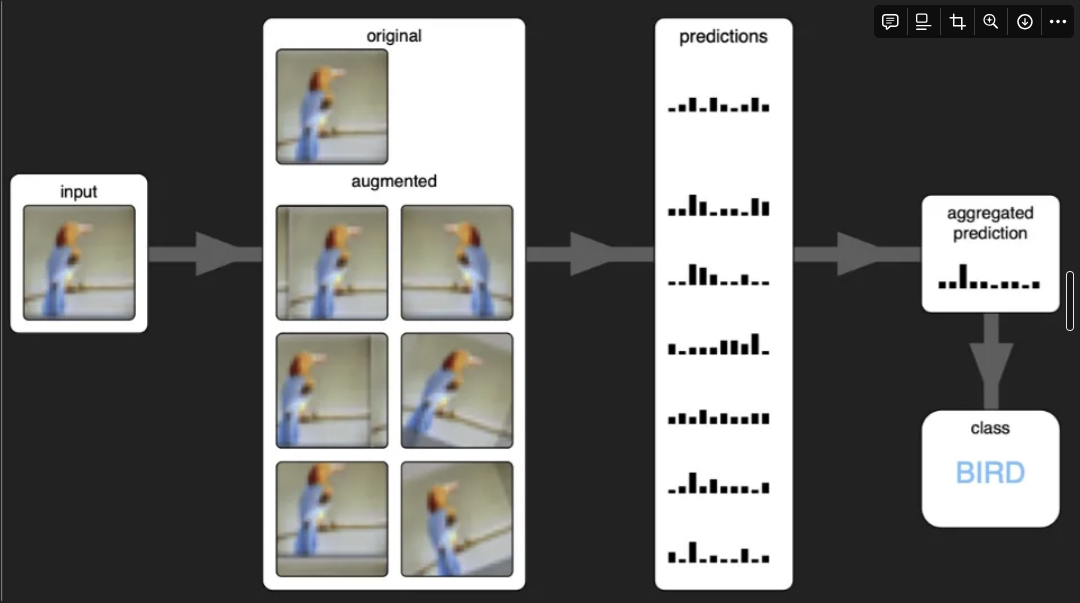
모델에 한가지 이미지를 주는 것보다 여러가지 변형된 이미지를 주어 평가함으로써 발생하는 오차를 줄이는 것이다.
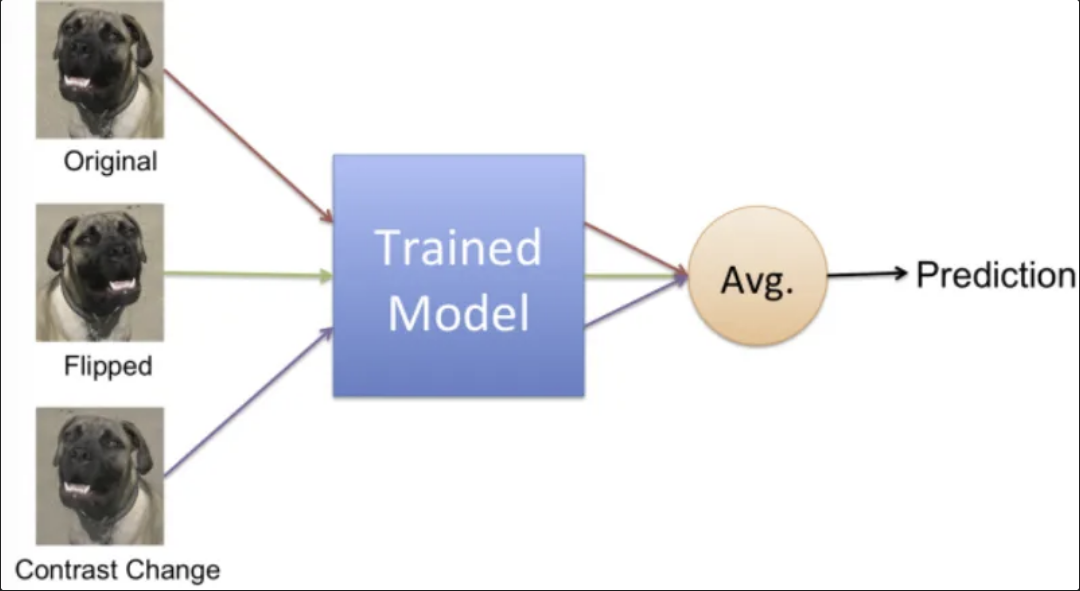
- TTA 특징
- 이미지에 다양한 변형을 주어 모델이 특정 변형에 너무 민감하게 반응하지 않도록 하여, 변동성을 줄이고 안정적인 일반화 성능을 얻는데 도움을 준다.
- 한 이미지에 대한 여러 예측을 평균 또는 투표 방식으로 결합하여 최종 예측을 생성하기 때문에 앙상블 효과를 얻을 수 있고, 모델의 robust를 향상시킨다.
-
단점
모델의 성능, 일반화 능력 측면에서는 좋은 모습들을 보인다는 것을 알 수 있지만 TTA는 여러번의 이미지를 모델에 입력해 다중 예측 및 앙상블해야 하기 때문에 추가적인 계산 비용과 시간이 든다.
또한 모델이 이미 훈련데이터가 많아 과적합되었다면 TTA를 적용해도 성능이 개선되지 않을 수 있다.
-
object detection에서의 적용
Object detection에서 TTA를 적용하는 과정은 다음과 같다.
-
이미지 증강: 테스트 이미지에 여러 변형(증강)을 적용합니다. 예를 들어, 좌우 반전, 회전, 크기 조정 등을 사용할 수 있습니다.
-
예측: 각 변형된 이미지에 대해 모델이 예측한 bounding box와 confidence score를 얻습니다.
-
원본 이미지로의 역변환: 변형된 이미지에 대한 예측 결과를 원본 이미지 기준으로 되돌립니다. 예를 들어, 좌우 반전된 이미지에 대해 예측한 박스는 다시 좌우 반전되어 원본 좌표에 맞춰야 합니다.
-
NMS(Non-Maximum Suppression): 원본 이미지로 역변환된 여러 예측 박스들 중에서 겹치는 박스들을 제거하고, 가장 신뢰도가 높은 박스를 선택합니다.
이때 NMS말고도 WBF, softnms등 다양한 앙상블 방법으로 적용할 수 있다.
다양한 모델에 적용할 수 있지만 real time을 중시하는 object detection 모델이라면 시간적인 문제에 단점이 있어서 사용하기는 어려워 보인다.
NMS & soft NMS
NMS(Non-Maximum Suppression)와 Soft-NMS는 객체 탐지(Object Detection) 분야에서 널리 사용되는 기법으로
다중 중복된 바운딩 박스(bounding boxes)를 제거하여 최종적으로 객체에 대해 하나의 박스만 남기는 방법이다.
앙상블 할 때도 쓰이고 추론할 때나 학습할 때도 사용된다.
NMS(Non maximum Suppression)

이 알고리즘은 하나의 객체에 대해 겹치는 박스들이 많을텐데 겹치는 박스들중에 젤 score가 높은 박스만 남겨놓는 알고리즘이다.
이를 통해 모델의 출력을 간결하게 하고 중복된 결과를 제거함으로써 정확한 객체 감지를 할 수 있게 된다.
- NMS 알고리즘의 단계
-
박스 정렬: 모델이 예측한 바운딩 박스들을 각 박스의 신뢰도(score)에 따라 내림차순으로 정렬합니다.
-
최고 신뢰도 박스 선택: 가장 높은 신뢰도를 가진 바운딩 박스를 선택하고, 나머지 박스와의 겹침 정도(Intersection over Union, IoU)를 계산합니다.
-
중복 박스 제거: IoU가 특정 임계값(일반적으로 0.5)을 넘는 박스들은 중복된 것으로 간주되어 제거합니다.
-
반복: 남아 있는 박스들 중에서 다시 신뢰도가 가장 높은 박스를 선택하여 위 과정을 반복합니다.

- NMS의 사용
모델 학습 시에 사용되지는 않고 추론할 때 사용되는 모델이 있고 EX) fast rcnn
두 과정에서 모두 NMS를 사용하는 모델도 있다. EX) faster rcnn
- 장단점
구현이 간단하고 직관적이다. 또한 중복된 박스를 제거하기 때문에 효율적인 예측이 가능하도록 한다.
하지만 임계 값이 너무 낮으면 동일한 클래스의 객체들이 근접해 있는 경우, 하나의 객체만 남고 나머지는 누락될 수 있습니다.
soft NMS

NMS에서 발생하는 문제점을 해결하기 위해 나온 NMS의 변형 기법이다.
Soft-NMS는 바운딩 박스를 억제하는 것이 아니라, confidence를 감소시킨다. 기존의 NMS에서 억제되었던 바운딩 박스가 Soft-NMS를 적용하면 낮은 confidence로 검출되는 것이다.
이 방법은 객체가 가까이 위치해 있는 경우에도 유용하게 작동하며, 더 많은 정보를 보존하면서 중복된 예측을 처리합니다.
- Soft-NMS 알고리즘의 단계
- 박스 정렬: NMS와 마찬가지로, 신뢰도가 높은 박스부터 정렬합니다.
- IoU 계산 및 점수 조정: 각 박스에 대해 나머지 박스와의 IoU를 계산하고, 일정한 임계값 이상 겹치는 박스들의 신뢰도를 완전히 제거하지 않고, 겹침 정도에 따라 점진적으로 낮춥니다.
- 이때, 점수 감소는 특정 함수(예: 선형 또는 가우시안 함수)를 사용하여 결정됩니다.
- 겹침이 클수록(즉, IoU가 높을수록) 더 큰 신뢰도 감소가 발생하고, 겹침이 적을수록 변화가 적습니다.
- 점수가 낮은 박스 제거: 모든 박스의 신뢰도를 조정한 후, 사전에 정의한 confidence 임계값보다 낮은 박스는 제거됩니다.
- 반복: NMS처럼 이 과정을 반복하여 최종 바운딩 박스를 남깁니다.

- 박스 누락 가능성이 줄어들고 유연해지는 장점은 이지만 그만큼의 계산 비용이 더 들어간다.
WBF
WBF(Weighted Box Fusion)는 객체 탐지(Object Detection) 결과를 후처리(Post-processing)하는 기법이다.
WBF는 특히 앙상블(ensemble) 모델에서 각기 다른 모델이 예측한 bounding 박스를 통합할 때 유용하게 사용된다. 이 기법은 Non-Maximum Suppression(NMS)이나 Soft-NMS와 같은 전통적인 방법보다 더 정교하게 박스를 결합하여 성능을 개선한다.
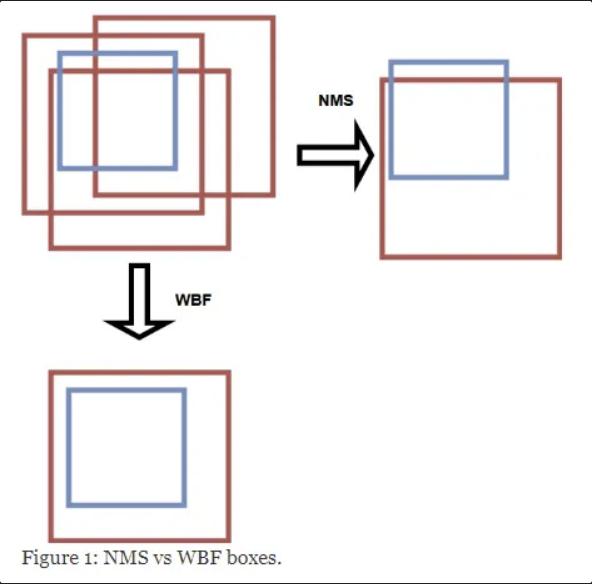
- 특징 WBF는 여러 bounding 박스가 동일한 객체를 가리키는 경우 이들을 단순히 제거하는 대신 가중 평균(weighted average)을 통해 하나의 최종 박스로 통합한다. 이를 통해 단일 박스의 정확성을 높이고, 여러 예측에서 얻은 정보를 최대한 활용할 수 있다.
- WBF 알고리즘의 단계
-
바운딩 박스 정렬
모든 예측된 바운딩 박스를 신뢰도 점수에 따라 내림차순으로 정렬합니다.
-
클러스터링
높은 신뢰도 박스부터 시작하여, 특정 IoU(Intersection over Union) 임계값 이상으로 겹치는 박스들을 동일한 클러스터로 묶습니다.
클러스터링을 할 때는 클러스터링 알고리즘(ex DBSCAN)을 사용하여 수행됩니다.
-
가중 평균 계산
각 클러스터 내의 박스들의 좌표(중앙점, 너비, 높이 등)를 신뢰도 점수를 가중치로 하여 평균을 냅니다.
이 과정을 통해 하나의 대표 박스가 생성됩니다.
-
최종 박스 생성
각 클러스터에서 계산된 대표 박스를 최종 예측으로 채택합니다.
-
- NMS/Soft-NMS와의 비교
inaccurate한 box들이 많이 예측되었을 경우, NMS나 soft-NMS는 그나마 나은 하나의 box를 예측함
그에 반해 WBF는 모든 inacurate한 box들을 잘 종합하여 ground truth에 근접한 box를 예측함
- 모델의 장단점 NMS와 달리, WBF는 근접한 객체를 보다 잘 구분할 수 있고, 높은 정확도를 보인다. 하지만 클러스터링과 가중 평균 계산 등의 추가 연산이 필요하므로, 처리 속도가 느리고, 여러 하이퍼파라미터를 설정해야 해서 복잡하다.
- 사용
서로 다른 모델들의 앙상블 기법으로 사용한다면 좋은 성능 보장
하지만 싱글 모델에서 NMS를 대체하는 용도로 WBF를 사용한 결과 성능이 하락함
저자들은 성능 하락의 원인이 낮은 점수의 box가 너무 많기 때문이라고 생각함
