Epoch?
에폭(epoch)은 모델이 전체 데이터셋을 1번 완전히 학습하는 과정을 의미
만약 전체 데이터가 10개이고 1epoch이면, 모델은 10개의 데이터를 한번 학습했다는 의미이다.
epoch의 장점은 동일한 데이터 셋을 여러번 반복 학습이 가능하다는 점이다. 각 에폭마다 가중치가 업데이트 되기 때문에 여러번 epoch을 하면 성능이 향상될 수 있다.
하지만 너무 많은 epoch은 과적합을 발생시킬 수 있다.
과적합이란?
모델이 train data에 너무 맞춰져 새로운 데이터에 대한 일반화 능력이 떨어지는 것을 의미num_epochs=1000 # 에폭 수를 설정
for epoch in num_epochs: # epoch을 반복하며 예측값과 손실함수 계산하는 코드
y=model(x_tensor)
loss=loss_function(y,t_tensor)normalization?
우리가 학습을 시킨 후 손실값을 plt로 그려 보면 손실값이 매우 클 때가 있다.
이유가 다양하게 있게지만 크게 3가지 이유가 있다.
- 학습률이 너무 크면 최적의 가중치로 수렴하지 못함으로써 손실값이 클 수 있다.
해결책-학습률을 낮춰보기 - 데이터에 노이즈가 많거나 이상치가 존재한다면 학습이 어려울 수 있다.
해결책-시각화하여 이상치 제거하기 - epoch수가 충분하지 않다면 모델이 수렴할 수 없다.
해결책-epoch 수를 늘려보기
하지만 이렇게 3가지 방법을 써도 해결되지 않을 때가 있다 그 때는 어떻게 해결해야할까?
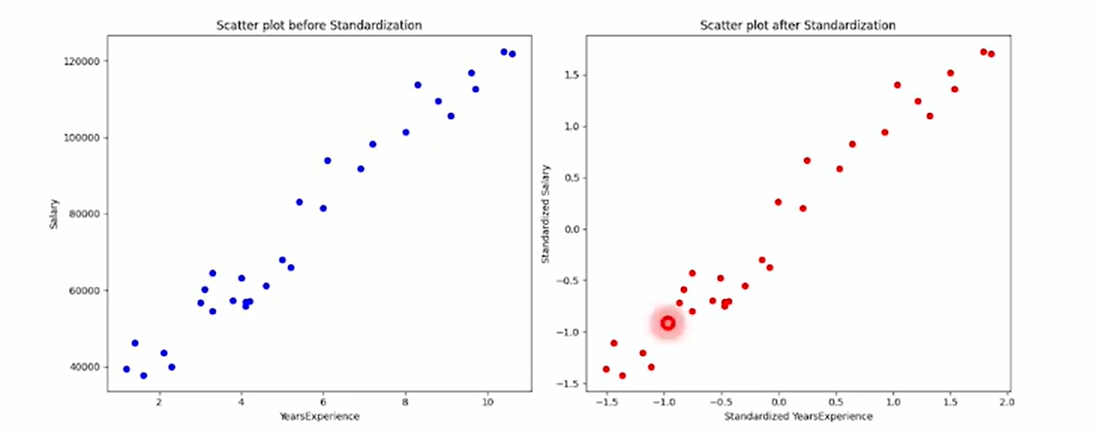
바로 표준화이다!!!
데이터 표준화는 손실값을 줄이는 방법으로써 모델 구축전에 데이터를 전처리하는 것이다. 방법은 여러가지 있지만
예시로 목표변수와 설명변수 값의 차이가 클 때 두 변수의 평균을 0, 분산 1로 맞추어 표준화하는 것이 좋다.
표준화하면 데이터가 변질될까? 아니다! 분포는 동일하고 값만 변하게 되는 것이다.
#표준화 코드
from sklearn.preprocessing import StandardScaler
scaler_x=StandardScaler()
X_scaled=scaler_x.fit.transform(x.reshape(-1,1))
## 1차원배열을 굳이 2차원으로 reshape하는 이유는 scaler가 2차원 배열을 받아들이기 때문