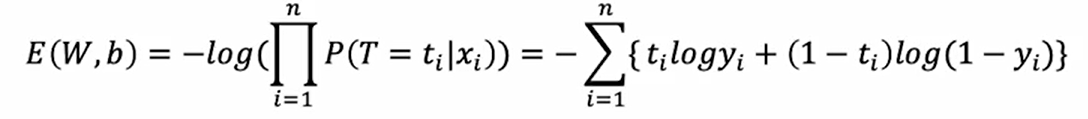이진 교차 엔트로피란?
BCE(Binary Cross Entropy)라고도 부르며, 이진 분류 문제에서 예측 변수와 목표 변수간의 차이를 측정하기 위해 사용되는 손실 함수이다.
아래와 같은 함수식을 사용한다.
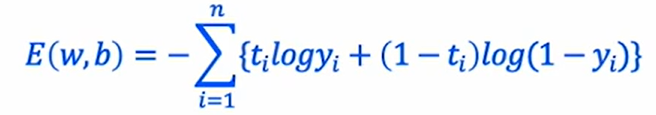
이런 식은 어떻게 도출된 것일까?
기본 개념
식을 유도하기 위해서는 조건부 확률과 로그가능도,최대 가능도 추정에 대해 알고 있어야 한다.
-
조건부 확률

-
최대가능도 추정(MLE)
최대 가능도 추정이란 간단히 말해서 어떤 특정 주어진 데이터셋이 있을 때 그 데이터를 가장 잘 설명할 수 있는 파라미터(모수) 찾는 것이다.
즉, MLE는 데이터의 분포에 따라 모수의 값을 추정하는 과정 전체를 가리킨다.
이 방법을 통해 최대가능도 추청치를 찾는다.어떻게 그 파라미터를 찾을까?
데이터 셋을 가장 잘 설명하는 모수를 찾기 위해 가능도 함수(likelihood)를 최대화하는 과정을 거친다.
Estimation은 관찰된 데이터를 사용하여 모수의 값을 추정하는 과정을 의미한다. -
모수
모수는 모집단으로부터 얻을 수 있는 통계치를 말하며 예시로 정규분포의 평균 분산이 있다.모수를 추정하는 이유는 모수가 주어진 데이터를 가장 잘 설명하며, 추정된 모수를 통해 최적의 모델을 선택할 수 있기 때문이다.
-
가능도
기계학습에서 중요한 개념으로 주어진 데이터가 특정 모수값 하에서 나올 관찰될 확률을 뜻한다.모수를 추정하기 위해 실험 결과가 가정한 확률분포에 따라 특정 모수가 설명될 가능도를 최대화 하는 방법을 사용한다.
아래의 수식은 데이터가 여러개가 독립적으로 추출되었을 때, 가능도 함수의 수식이다.
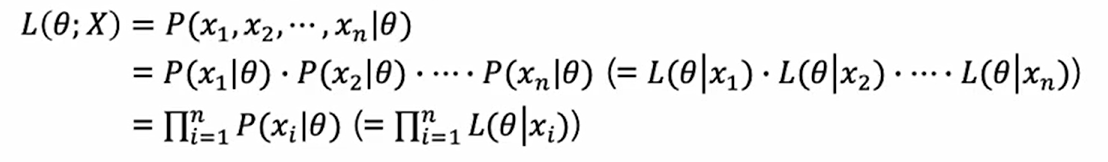
-
최대 가능도 함수
데이터에 가장 적합한 모수를 찾기 위해 최대 가능도 추정을 하기 때문에 가능도 함수가 최댓값이 되어야 한다.
아래와 같이 수식 표현이 되며 최대값을 찾는 방법은 로그를 취한 후 미분계수가 0이 되는 지점을 찾는 것이다.(로그함수가 위로 볼록함수 이기 때문)
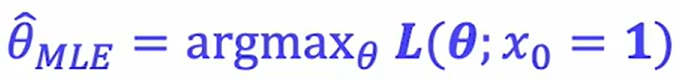
로그를 취하는 이유
- 숫자 단위가 줄어든다.
- 데이터가 독립이면 곱셈 나눗셈을 덧셈 뺄셈으로 바꿔줄 수 있다.
- 확률 값의 범위를 확장해 데이터 비교에 용이 [0,1]->(-inf,0]
BCE 수식 유도
입력 값 x에 대하여 출력값에 따른 확률을 y로 표현할 수 있다.
P(T=1|x)=y=sigmoid(Wx+b)
P(T=0|x)=1-P(T=1|x)=1-y위에 두 수식을 통합하여 아래와 같이 표현할 수 있다.
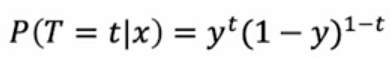
여러개의 데이터 일때 다 곱해준 후 로그를 취해주면 로그 가능도 함수가 된다.
최댓값을 구하는 것은 최솟값으로 표현해 주기 위해 앞에 - 를 붙인다.
이 식이 이진 교차 엔트로피 함수이다.